
下载掌阅APP,畅读海量书库
立即打开




在本章中,我们将展示第一个具有多个稠密层的神经网络示例。由于历史原因,感知器专指具有单个线性层的模型,因此,如果模型中含有多个线性层,则称之为 多层感知器(MLP) 。需要注意,输入层或输出层从外部可见,而所有其他中间层都是隐藏的,统称为隐藏层。在这种情况下,每个线性层对应一个线性函数,而多层感知器将多个线性层依次堆叠,如图1-4所示。
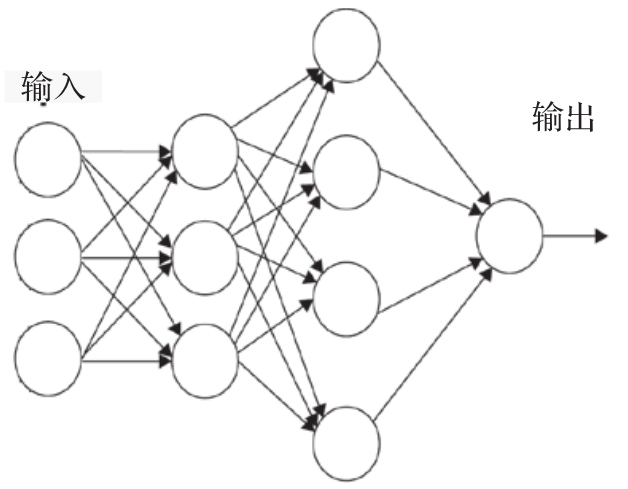
图1-4 多层感知器示例
在图1-4中,第一个隐藏层中的每个节点接收输入,并根据其关联线性函数的计算值“发射”(0,1)信号。然后,第一个隐藏层的输出传递到第二层,在第二层应用另一个线性函数,其结果传递到由单个神经元组成的输出层。有趣的是,这个分层的组织结构很像我们前面讨论的人类视觉系统。
考虑一个神经元:权重 w 和偏差 b 的最佳选择是什么?理想情况下,我们希望提供一组训练示例,在计算机保证输出误差最小的前提下调整权重和偏差。
再具体一点,假设有一组猫的图片和另一组不包含猫的图片。同时,假设每个神经元的输入为图片中每个像素的值。那么,当计算机处理这些图像时,我们希望每个神经元都能调整其权重和偏差,以使错误识别的图片越来越少。
这种方法乍看起来非常直观,但是要求权重(或偏差)的小幅度改变只会导致期望输出产生细微变化。想想看:如果我们的期望输出是阶跃式的,那就无法实现渐进式学习。当然,孩子是可以一点一点地学习的。但感知器还没有学会这种“点滴积累”的办法。例如,感知器的输出非0即1,这就是一个阶跃,对学习没有帮助(见图1-5)。
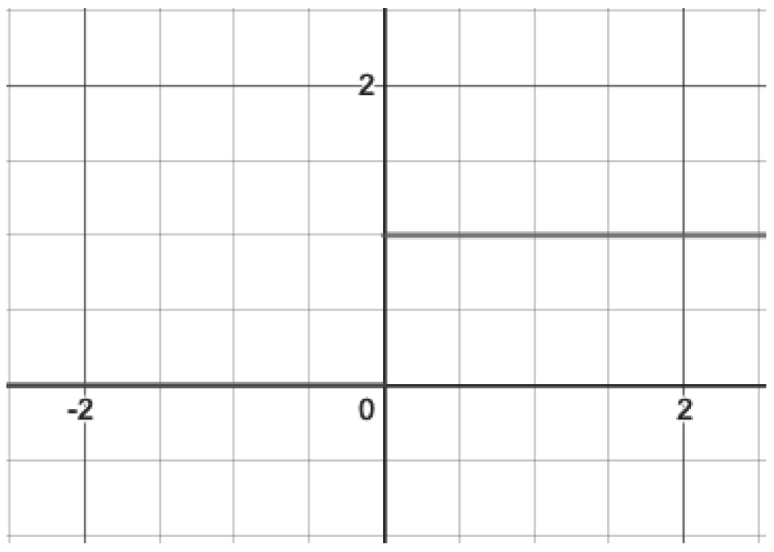
图1-5 感知器示例——非0即1
我们需要一个能够不间断地从0到1渐变的函数。从数学上讲,这意味着需要一个可求导的连续函数。导数是函数在给定点的改变量。对输入为实数的函数而言,导数是图上某点的切线斜率。在本章的后面谈论梯度下降时,将再次讨论导数。
sigmoid函数(也称为S型函数)定义为
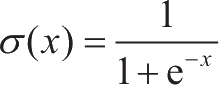 ,当输入在范围(-∞,∞)变化时,它的输出在区间(0, 1)内微小改变。在数学上,该函数是连续的。典型的sigmoid函数如图1-6所示。
,当输入在范围(-∞,∞)变化时,它的输出在区间(0, 1)内微小改变。在数学上,该函数是连续的。典型的sigmoid函数如图1-6所示。
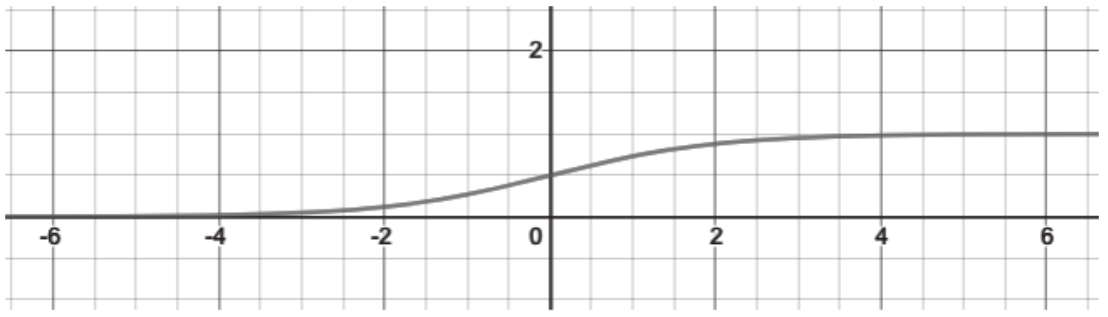
图1-6 输出范围为(0, 1)的sigmoid函数
神经元可用sigmoid函数计算非线性函数 σ ( z = wx + b )。注意,如果 z = wx + b 非常大且为正,则e - z →0,所以 σ ( z )→1;如果 z = wx + b 非常大且为负,则e - z →∞,所以 σ ( z )→0。换言之,具有sigmoid激活函数的神经元的表现行为与感知器类似,但其变化是渐进的,输出值(例如0.553 9或0.123 191)也是完全符合要求的。从这个意义上讲,sigmoid函数神经元可以回答“也许”。
另一个实用的激活函数是tanh函数(也称为双曲正切函数)。它的定义为
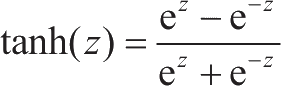 ,形状如图1-7所示,其输出范围为-1~1。
,形状如图1-7所示,其输出范围为-1~1。
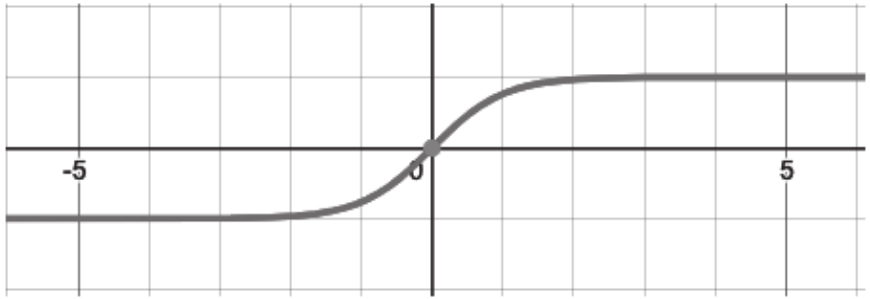
图1-7 tanh激活函数
sigmoid函数不是唯一一个用于神经网络的平滑激活函数。近年来, ReLU函数 (Rectified Linear Unit,线性整流函数,又称修正线性单元)变得非常流行,因为它有助于解决使用sigmoid函数观察到的一些优化问题。在第9章中谈到梯度消失(vanishing gradient)时,将更详细地讨论这些问题。ReLU函数可由 f ( x ) = max(0, x )简洁地定义,非线性函数如图1-8所示。正如你看到的,函数对负值取零,对正值按线性增长。ReLU函数的实现也非常简单(通常,三条指令就足够了),而sigmoid函数则要高几个数量级。这有助于将神经网络应用到一些早期的GPU上。
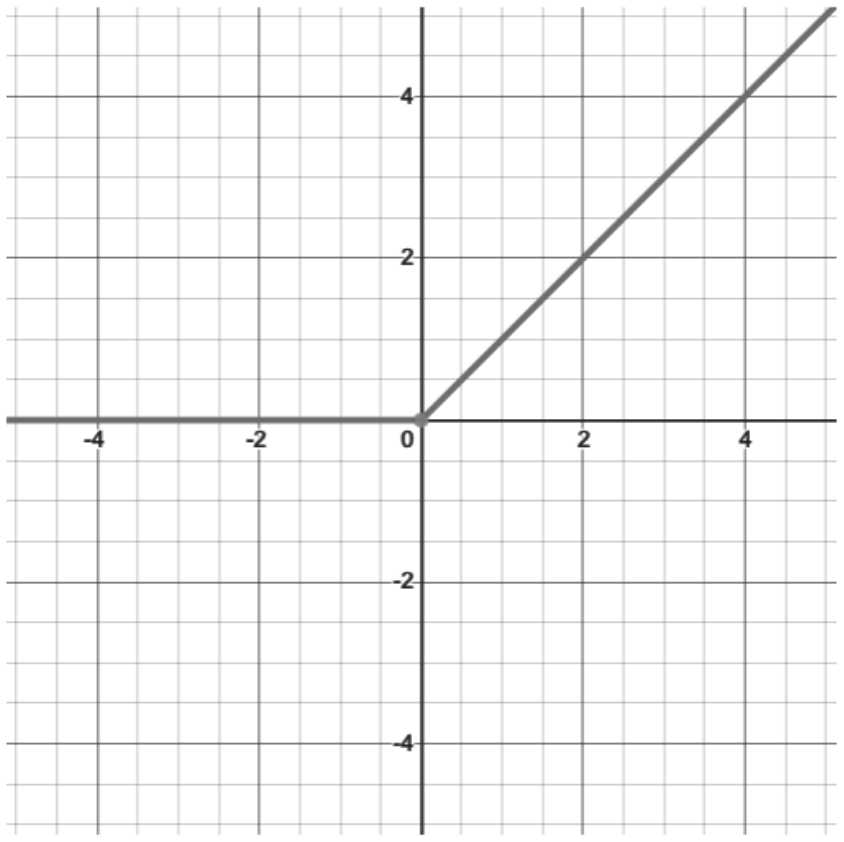
图1-8 ReLU函数
除了sigmoid函数和ReLU函数之外,还有其他可用于学习的激活函数。
ELU函数定义为
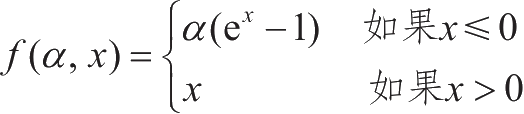 ,其中
α
>0。它的图形表示如图1-9所示。
,其中
α
>0。它的图形表示如图1-9所示。
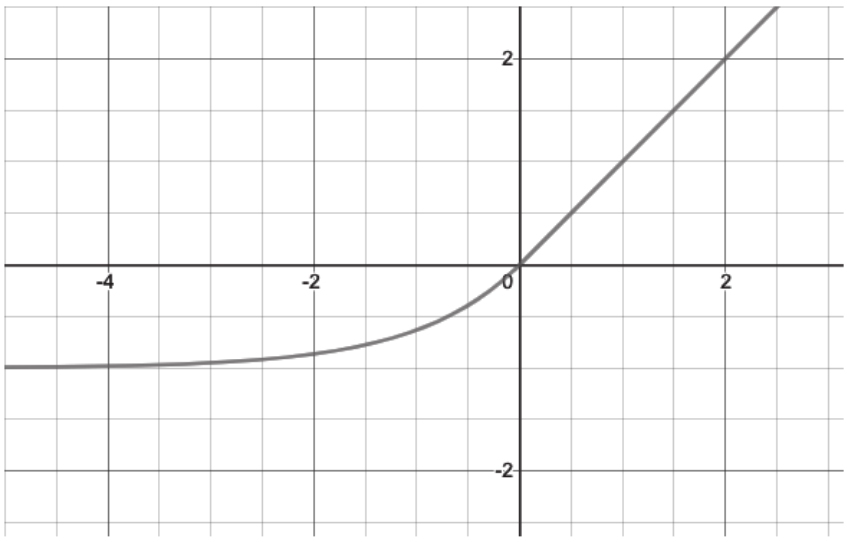
图1-9 ELU函数示例
LeakyReLU函数定义为
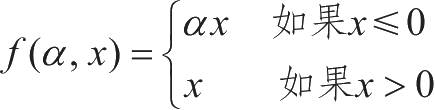 ,其中
α
>0。它的图形表示如图1-10所示。
,其中
α
>0。它的图形表示如图1-10所示。
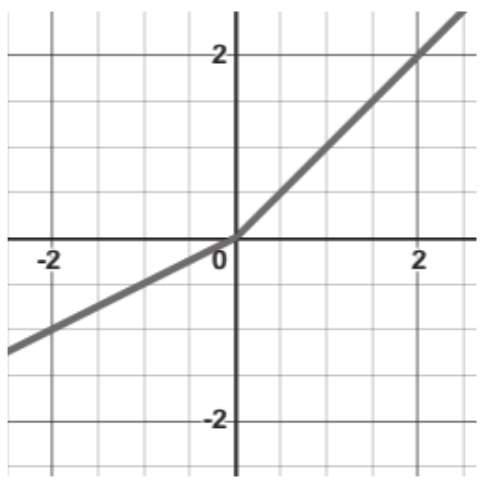
图1-10 LeakyReLU函数示例
如果 x 为负,上述两个函数都允许进行小幅度更新,这在特定情况下可能是有用的。
sigmoid、tanh、ELU、LeakyReLU和ReLU在神经网络术语中统称为激活函数。在梯度下降部分中,你将看到sigmoid函数和ReLU函数的典型渐进变化是开发一个学习算法的基础构建模块,该学习算法通过逐步减少网络所犯的错误来一点一点地适应。图1-11给出了使用激活函数的示例,涵盖它的输入向量( x 1 , x 2 , …, x m )、权重向量( w 1 , w 2 , …, w m )、偏差 b 以及求和运算∑。值得一提的是,TensorFlow 2.0支持多种激活函数,完整的列表可参考线上文档。
图1-11 在线性函数之后应用激活函数的示例
用一句话来概括,机器学习模型是指一种计算函数(该函数将某些输入映射到对应的输出)的方法。该函数仅涉及一些加法和乘法运算,但是,当它与一个非线性激活函数结合,并堆叠成多层后,这些函数几乎可以学习任何东西 [8] 。另外,你还需要用来捕获待优化内容(这是稍后将介绍的损失函数)的有效的度量指标、足够的可用学习数据以及充足的计算能力。
现在,停下来思考一下,“学习”的真正本质是什么?从我们自身的目的出发,学习本质上是一个旨在概括已建立的观察结果 [9] 以便预测未来结果的过程。简而言之,这正是我们要通过神经网络实现的目标。