
下载掌阅APP,畅读海量书库
立即打开




Oracle RAC故障主要集中在集群、实例、性能等方面,如果缺乏底层的理论基础,就会很难找到根本原因。本节不在于讲解基础的集群体系架构,而将以实际的集群故障案例展开分析,通过简单的案例,掌握常规的诊断方法,从而加深对集群整体架构的理解。
甲:快!快!快!数据库重启后起不来了。
我:大哥,大白天的为什么要重启数据库?
甲:因为要导数据嘛,报错说权限不足,我就按网上的步骤修改了权限,然后重启数据库。
我:啥权限?!!命令是?
甲:chown -R oracle:oinstall /oracle。
我:没事,你们RAC另一个节点不动就行。
甲:另一个节点也改了,还没重启。
对于运维人员来说,虽然日常工作就是处理各种问题和四处救急,但还是最怕处理一遇到问题就照着网上一通操作的情况。
在众多数据库软件中,Oracle的权限相对比较复杂,安装完之后,目录下会有上千个文件,用户有oracle、grid、root之分,组也细分为oinstall、dba、oper、asmadmin,当集群和数据库软件都意外地被chown -R命令误操作时,由于权限问题,集群和数据库都将无法启动,遇到此类问题,如果仅靠人工比对和修改,至少也需要一天的时间,成本非常高。
那么,有没有简便又高效的方法呢?下面就来介绍几种快速恢复的方法,首先关闭问题节点集群和数据库,然后使用下面任意一种方法进行恢复即可。
1.使用Oracle官方方法
正确安装完集群软件后,系统会在$GRID_HOME/crs/utl目录下生成两个文件:crsconfig_dirs和crsconfig_fileperms,这两个文件记录了核心文件及文件夹的权限,要想恢复也很方便。
root用户执行命令如下。
Oracle 11.2版本:
shell> cd <GRID_HOME>/crs/install/ shell> ./rootcrs.pl -init
Oracle 12c及以上版本:
shell> cd <GRID_HOME>/crs/install/ shell> ./rootcrs.sh -init
2.使用操作系统权限命令
找到一套运行正常的环境,进入/oracle目录,使用getfacl收集当前目录下所有文件的权限:
shell> getfacl -pR ./ > backup.txt
替换backup.txt中的主机名、ASM名和数据库名。这里介绍一个快速替换的小技巧,“1,$s/rac1/rac2/g”命令可用于将文件中的rac1替换为rac2,将替换后的文件复制至当前需要恢复的环境/oracle目录下执行恢复操作:
shell> setfacl --restore=backup.txt
getfacl、setfacl的使用方法较为简单,这里就不做展开了,如有兴趣深入探讨,可以自行查询官方使用手册。
上述两种方法都能实现恢复,不过笔者更推荐使用第二种方法(getfacl),因为第一种方法的限制及Bug较多,成功率不高。当然还有第三种方法,结合操作系统命令find -uid和chown来实现恢复,具体使用这里不做展开。
至此,软件权限已经基本修复完成,集群可以正常启动,但启动数据库时还是会报如下错误信息:
WARNING:failed to register ASMB0 with ASM instance ORA-01034:ORACLE not available ORA-27121:unable to determine size of shared memory segments Linux-x86_64 Error:13:Permission denied
经常打补丁的读者对以上报错信息一定不会感到陌生,对于存在asmadmin的组,在打补丁的过程中,Oracle执行文件的权限发生了改变,与ASM磁盘组的权限不一致。此案例需要考虑的两个关键文件如下:
shell> ls -tlr $ORACLE_HOME/bin/oracle -rwsr-s--x 1 oracle dba /oracle/app/product/12.2.0/db_1/bin/oracle shell> ls -tlr $GRID_HOME/bin/oracle -rwsr-s--x 1 grid oinstall /oracle/gi/bin/oracle
处理方法如下:
<!--grid用户执行--> shell> cd $GRID_HOME/bin shell> ./setasmgidwrap o=$ORACLE_HOME/bin/oracle shell> chmod u+s $GRID_HOME/bin/oracle shell> chmod g+s $GRID_HOME/bin/oracle
至此,整个恢复就完成了,数据库可以正常打开。
 第一,遇到问题请不要盲目照搬网上的搜索结果,无法判断命令的危险性时,一定不要在生产环境中尝试操作,有条件的可以咨询专业人员。
第一,遇到问题请不要盲目照搬网上的搜索结果,无法判断命令的危险性时,一定不要在生产环境中尝试操作,有条件的可以咨询专业人员。
第二,规范操作行为,操作生产库和操作测试库的窗口尽量不要同时开启,以避免误切(不要抱有侥幸心理,就算再熟练也会有百密一疏的时候)。
节点驱逐是RAC故障中比较常见的一类问题,其中比较普遍的问题就是“IPC Send timeout”(进程间通信发送超时),导致数据库实例异常终止。在RAC中,LMON(Lock Monitor,锁监视器)、LMD(Lock Manager Deamon,锁管理器守护)和LMS(Lock Manager Server,锁管理器服务器)进程主要负责实例间的进程通信。LMS0进程主要负责GES(Global Enqueue Server,全局队列服务)资源管理,LMS进程则负责GCS(Global Cache Server,全局缓存服务)工作,以完成数据块在实例之间的传递,以及实例间消息的发送与接收。正常情况下,实例间消息的发送与确认接收是很快的,但是如果确认消息没有在指定的时间内收到,发送进程就会认为消息没有得到接收进程反馈,此时就会出现“IPC Send timeout”错误。
接下来,我们分析一下由“IPC Send timeout”所引起的节点驱逐案例。
故障时间段节点1数据库告警日志输出如下:
<!--实例日志提示-->
Wed May 25 02:40:18 2016
IPC Send timeout detected. Receiver ospid 120737
Wed May 25 02:40:18 2016
Errors in file /oracle/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_lms1_120737.trc:
IPC Send timeout detected. Receiver ospid 121032
Wed May 25 02:40:19 2016
Errors in file /oracle/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_pz99_121032.trc:
Wed May 25 02:41:09 2016
Wed May 25 02:41:09 2016
Received an instance abort message from instance 3Received an instance abort
message from instance 3
<!--提示节点3需要中断节点1-->
Please check instance 3 alert and LMON trace files for detail.
Please check instance 3 alert and LMON trace files for detail.
LMD0 (ospid: 120730): terminating the instance due to error 481
Wed May 25 02:41:09 2016
System state dump requested by (instance=1, osid=120730 (LMD0)), summary=
[abnormal instance termination].
Wed May 25 02:41:09 2016
opiodr aborting process unknown ospid (98457) as a result of ORA-1092
System State dumped to trace file /oracle/app/oracle/diag/rdbms/orcl/orcl1/trace/
orcl1_diag_120714_20160525024109.trc
Wed May 25 02:41:09 2016
ORA-1092 : opitsk aborting process
Instance terminated by LMD0, pid = 120730
至此,节点1数据库实例被异常中断(此时节点1的ASM实例还在正常运行)
而节点2和节点3执行reconfiguration之后还将继续运行,直到4:36,节点1 CRS检测到心跳错误开始驱逐节点2和节点3。
故障时间段节点1 ocssd日志,输出如下:
2016-05-25 04:36:07.704:
[cssd(112876)]CRS-1612:Network communication with node hisrac02 (2) missing for
50% of timeout interval. Removal of this node from cluster
in 14.740 seconds
2016-05-25 04:36:15.709:
[cssd(112876)]CRS-1611:Network communication with node hisrac02 (2) missing for
75% of timeout interval. Removal of this node from cluster
in 6.730 seconds
2016-05-25 04:36:19.712:
[cssd(112876)]CRS-1610:Network communication with node hisrac02 (2) missing for
90% of timeout interval. Removal of this node from cluster
in 2.730 seconds
2016-05-25 04:36:22.447:
[cssd(112876)]CRS-1607:Node hisrac02 is being evicted in cluster incarnation
340253561; details at (:CSSNM00007:) in /oracle/11.2.0/grid/log
/hisrac01/cssd/ocssd.log.
2016-05-25 04:37:02.455:
[cssd(112876)]CRS-1612:Network communication with node hisrac03 (3) missing for
50% of timeout interval. Removal of this node from cluster
in 14.040 seconds
2016-05-25 04:37:09.457:
[cssd(112876)]CRS-1611:Network communication with node hisrac03 (3) missing for
75% of timeout interval. Removal of this node from cluster
in 7.040 seconds
2016-05-25 04:37:14.460:
[cssd(112876)]CRS-1610:Network communication with node hisrac03 (3) missing for
90% of timeout interval. Removal of this node from cluster
in 2.030 seconds
根据以上日志我们可以初步断定,网络层出现问题的可能性更大一些,进一步排查OSWatch操作系统网络监控日志,可以发现在故障时间节点期间,“packet reassembles failed”出现了大幅度增长,具体如下:
1021989 packet reassembles failed
1022238 packet reassembles failed
1022381 packet reassembles failed
1022541 packet reassembles failed
1022654 packet reassembles failed
1022733 packet reassembles failed
1022841 packet reassembles failed
1022985 packet reassembles failed
1023066 packet reassembles failed
1023201 packet reassembles failed
1023335 packet reassembles failed
1023444 packet reassembles failed
1023528 packet reassembles failed
1023629 packet reassembles failed
1023748 packet reassembles failed
1023825 packet reassembles failed
从以上信息中,我们可以确认网络层存在大量的IP包重组失败(packet reassembles failed)其数量一般应控制在6万左右。
网络通信中,MTU(Maximum Transmission Unit,最大传输单元)限制了每次传输的IP包的大小。当发送的UDP(User Datagram Protocol,用户数据报协议)报文长度大于MTU时,IP层会对报文进行分片,接收端收到分片后,会对分片进行重组,生成一个完整的UDP报文。分片重组的过程是由内核协议栈完成的,协议栈需要一个缓存区来存储已经到达的分片,等待所有分片到达,再进行重组。其中,Linux内核协议栈使用重组缓存区(reassemble buffer)来缓存IP fragment(片段),协议栈默认重组的大小为4MB,该值相对来说比较小,当接收端收到大量经过IP分片的报文时,很容易导致缓存区空间不够的问题。
此次故障中,我们通过Linux调整ipfrag_low_thresh和ipfrag_high_thresh参数,以增大缓存区的大小来解决故障问题,命令如下:
shell> vi /etc/sysctl.conf net.ipv4.ipfrag_high_thresh = 16M net.ipv4.ipfrag_low_thresh = 15M
对于节点驱逐,我们可以从以下几个方面进行排查。
1)检查所有节点的网络层是否存在丢包或UDP之类的通信错误。
2)检查所有节点的网络参数配置是否合理,例如,内核参数/etc/sysctl.conf中网络相关的参数,所有节点MTU的设置必须是一致的,如果使用Jumbo Frame(巨型帧)的话,需要保证交换机可以支持的MTU大小为9000字节。
3)检查故障时间段主机的资源,包括CPU和内存的使用率是否过高。
4)检查集群核心进程LMON、LMS、LMD进程的日志信息。
5)检查数据库故障时间段的负载情况。
6)通过Oracle自带的CHM(Cluster Health Monitor,集群健康监控)的输出来检查当时的资源和网络使用情况。CHM只在某些平台和版本上存在。
7)部署OSWatch,开启网络和主机资源监控。
某银行客户集群的节点1出现异常重启的问题,希望我们找出问题所在。开始本次故障排查之前,我们先来了解下DRM(动态资源管理)的原理。
假设某集群数据库包含3个节点,根据RAC内存融合的原理,每个实例会保存数据库1/3的主节点信息,同时这也意味着,每个节点访问数据时会有2/3的概率需要从远程节点获取数据块的锁信息,从而造成更多节点间的消息通信。在实际应用中更有可能出现的情况是,一些数据块在非主节点上被访问了很多次,而主节点却很少访问。这种情况就意味着会产生大量的资源访问节点和资源主节点的消息,从而增加了私网的工作负载,甚至可能还会影响到数据库的性能。所以,Oracle从10g开始,推出了DRM特性,使资源的主节点信息可以被动态修改。当然,决定这种修改的依据是每个节点对资源的访问频率。DRM的移动过程主要可分为如下几个步骤。
1)静默节点(Quiesce)。
2)冻结阶段(Freeze)。
3)清除阶段(Cleanup)。
4)重建节点(Rebuild)。
5)解冻节点(Unfreeze)。
下面先来看看数据库的告警日志,如图2-47所示。
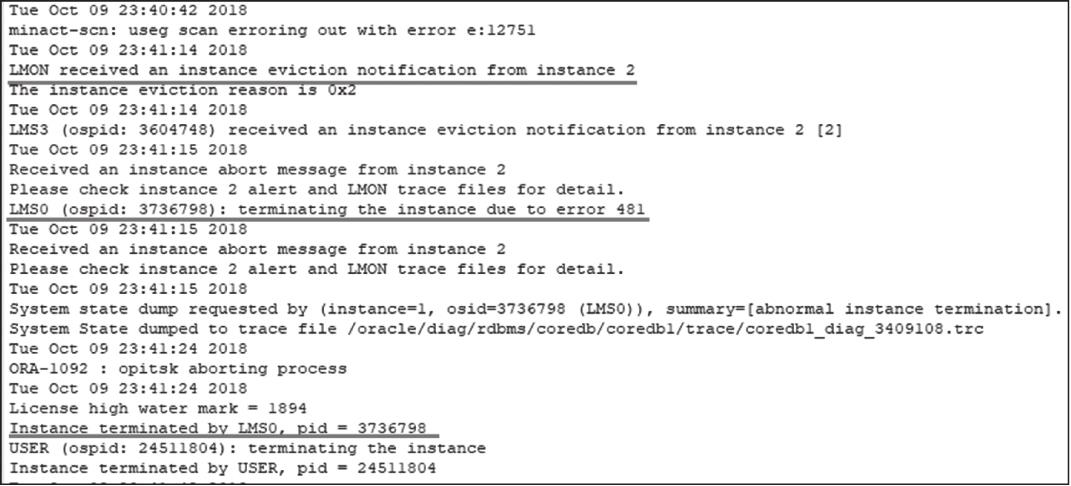
图2-47 告警日志
不难看出,2018年10月9日23:41:14,由于数据库的后台进程LMON和LMS节点间存在通信异常,LMS0进程终止了数据库实例。因此,我们继续检查数据库LMON和LMS日志,以便查看是否因为进程出现了问题,才导致数据库宕机。接下来查看LMON跟踪日志,输出如下:
*** 2018-10-09 23:34:18.405
* DRM RCFG called (swin 0)
CGS recovery timeout = 85 sec
Begin DRM(139949) (swin 0)
* drm quiesce
*** 2018-10-09 23:34:18.759
2018-10-09 23:34:18.759522 : DRM(139949) resources quiesced [0-65535], rescount 588987
2018-10-09 23:34:18.759882 : DRM(139949) local converts quiesced [0-65535],
lockcount 0, bucket 0
* drm sync 1
* drm freeze
* drm cleanup
* drm sync 2
* drm replay
* drm sync 3
* drm fix writes
* drm sync 4
* drm end
* DRM RCFG called (swin 0)
CGS recovery timeout = 85 sec
* drm quiesce
<!--……省略部分-->
*** 2018-10-09 23:34:20.780
2018-10-09 23:34:20.780063 : DRM(139949) resources quiesced [131072-196607],
rescount 589078
2018-10-09 23:34:20.780437 : DRM(139949) local converts quiesced [131072-196607],
lockcount 1, bucket 228
* drm sync 1
* drm freeze
kjxgm_Notify_Eviction: Received an instance eviction notification from instance 2
*** 2018-10-09 23:41:14.147
kjxgm_Notify_Eviction: eviction member count 1 reason 0x2
kjxgm_Notify_Eviction: eviction map 1
2018年10月9日23:34:18.405,LMON进程就已经接收到了来自节点2的驱逐信息。此时数据库正在发生DRM,但直到实例宕机(23:41),DRM也没有结束的迹象。也就是说一个DRM竟持续了7分钟都没结束。
下面进一步查看LMD跟踪日志DRM的启动信息,内容如下:
*** 2018-10-09 23:34:18.359 * received DRM start msg from 2 (cnt 1, last 1, rmno 139949) Rcvd DRM(139949) AFFINITY Transfer pkey 5999817.0 from 1 to 2 oscan 1.1 ftd (30) received from node 2 (76 0.30/0.0) all ftds received * kjxftdn: break from kjxftdn, post lmon later *** 2018-10-09 23:34:18.812 ftd (33) received from node 2 (76 0.33/0.0) all ftds received * kjxftdn: break from kjxftdn, post lmon later ftd (35) received from node 2 (76 0.36/0.0) all ftds received ftd (37) received from node 2 (76 0.38/0.0) all ftds received ftd (30) received from node 2 (76 0.30/0.0) all ftds received * kjxftdn: break from kjxftdn, post lmon later *** 2018-10-09 23:34:20.830 ftd (33) received from node 2 (76 0.32/0.0) all ftds received * kjxftdn: break from kjxftdn, post lmon later *** 2018-10-09 23:34:34.002 kjddt2vb: valblk [0.4e693] > local ts [0.4e692] *** 2018-10-09 23:34:35.173 kjddt2vb: valblk [0.4e699] > local ts [0.4e698] <!--......省略大量kjddt2vb: valblk信息--> *** 2018-10-09 23:41:12.133 kjddt2vb: valblk [0.504e9] > local ts [0.504e8]
2018年10月9日23:34:18,LMS进程开始启动DRM,直到实例宕机都没有结束,结合LMON的信息,我们可以猜测当时节点间通信的私网流量较大。
客户端Zabbix监控故障时间段系统的心跳网络流量,也印证了上面的判断。此时基本上可以判定是DRM引起了此次宕机。为了进一步明确宕机的原因,我们再来查看23点34分左右数据库的会话信息,如图2-48所示。
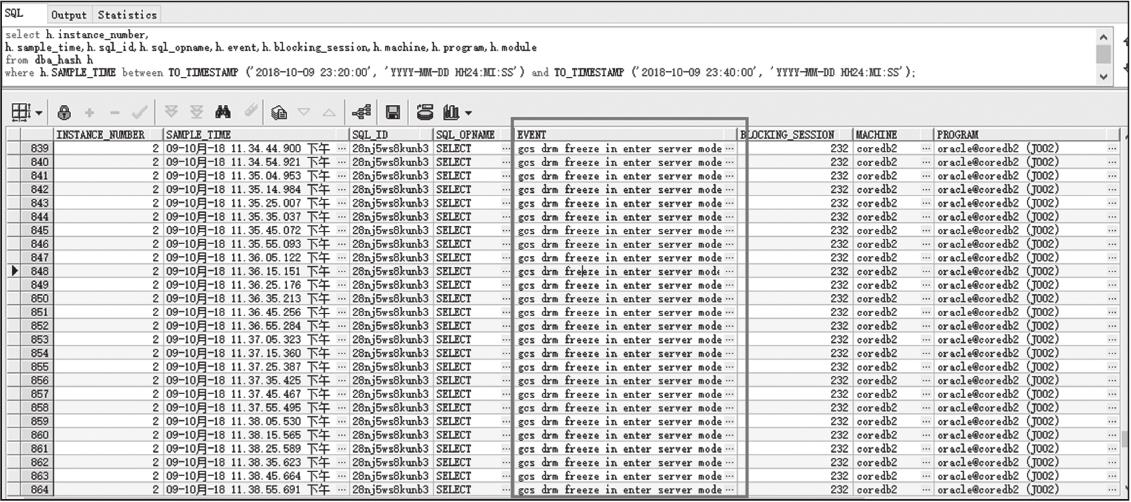
图2-48 故障时间点会话信息
“gcs drm freeze in enter server mode”正是DRM期间用户需要操作相同数据块时数据库发生的等待事件,如图2-49所示。
从会话等待及锁信息也能看出,故障发生前正在进行DRM操作,但最终锁的源头LMS0却处于空闲等待的状态。进一步查看LMS0及节点2的跟踪文件信息(ges2 LMON to wake up LMD-mrcvr,2018-10-09 23:41:13.048015 : * kjfcdrmrcfg: waited 413 secs for lmd to receive all ftdones, requesting memberkill of instances w/o ftdones:),内容与Bug 13399435/ Bug13732226相匹配,MOS Oracle官方参考文档为LMON received an instance eviction notification from instance n (Doc ID: 1440892.1)。
最终,我们可以确认此次宕机是因为节点间产生了大量的DRM触发了Bug,从而导致节点1数据库宕机。
分析到这里,宕机的原因已经很明确了,但是为什么会产生大量的DRM,使得节点间的通信加剧,这也是我们需要进一步排查的。由于数据库故障时间段丢失了部分快照点及自重启信息,因此我们只能尽可能地对现有日志进行分析,下面就来介绍排查的过程。首先,查看宕机前数据库的会话信息,如图2-50所示。
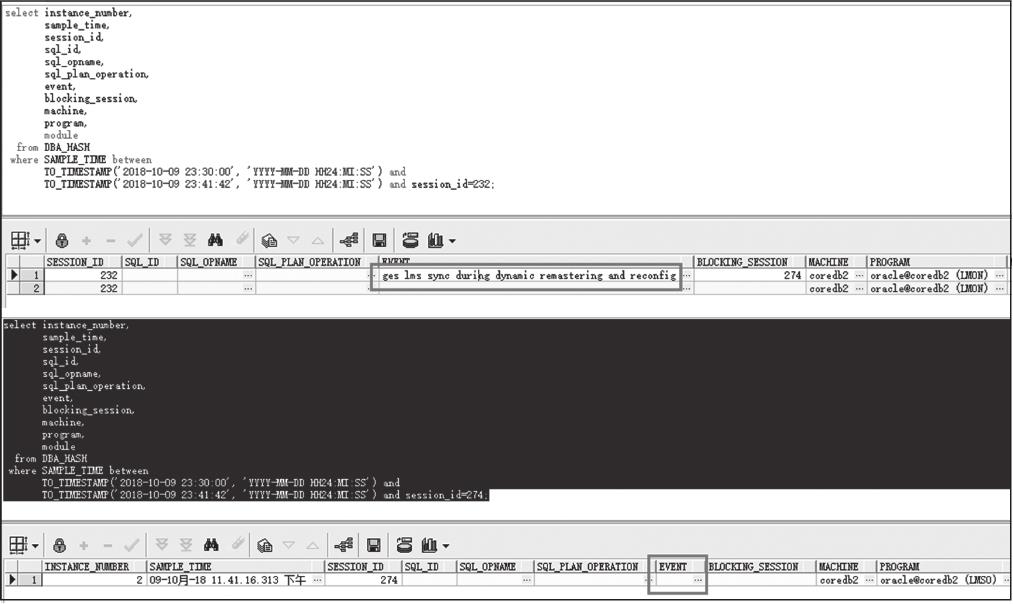
图2-49 等待事件信息
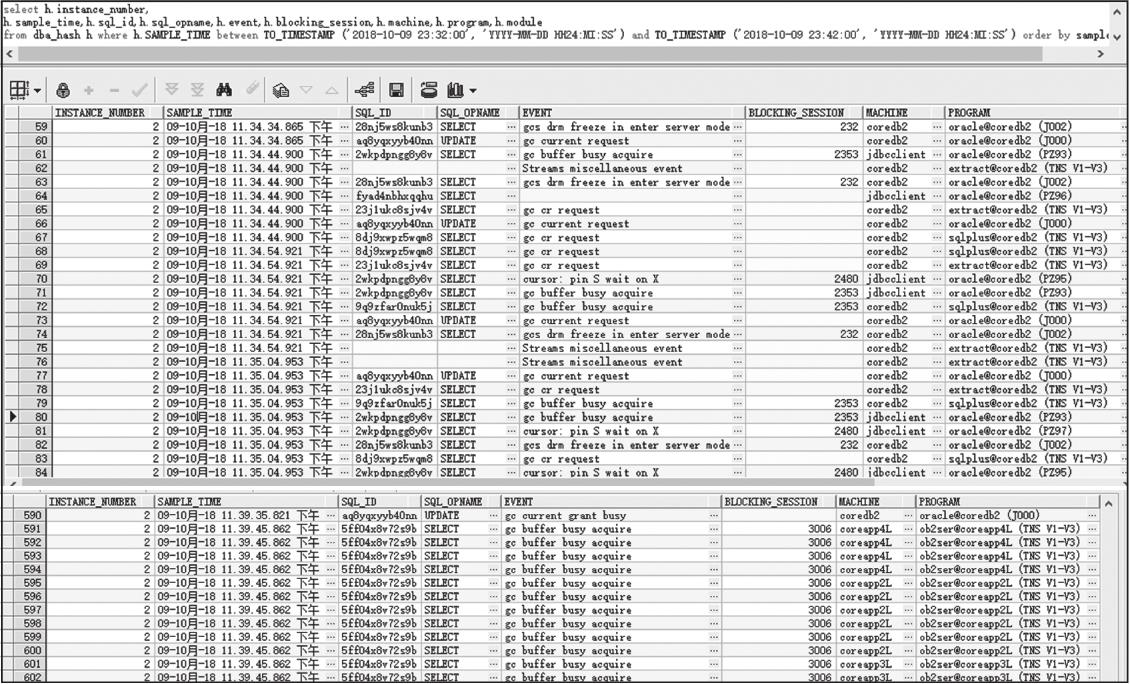
图2-50 宕机前数据库的会话信息
2018年10月9日23:34,节点间有大量的GC类等待。堵塞的会话几乎都是来自2480和2353的会话,下面分别看下2480和2353会话,如图2-51所示。
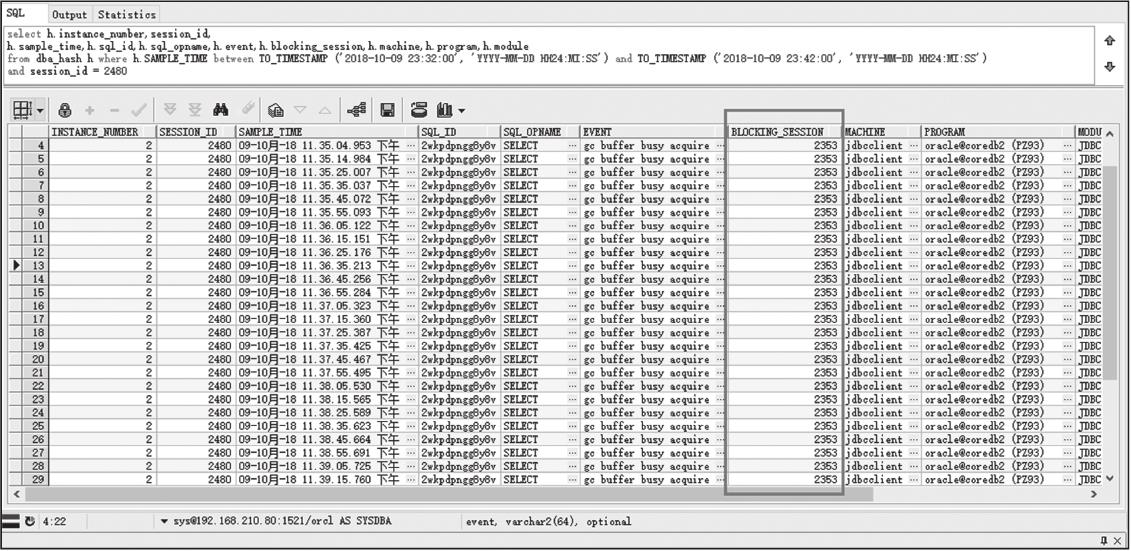
图2-51 2480会话信息
由图2-51可以看出,2480会话也被2353会话堵塞,以相同的方式查看别的blocking_session,可以发现它们都是来自同一个2353会话,如图2-52所示。
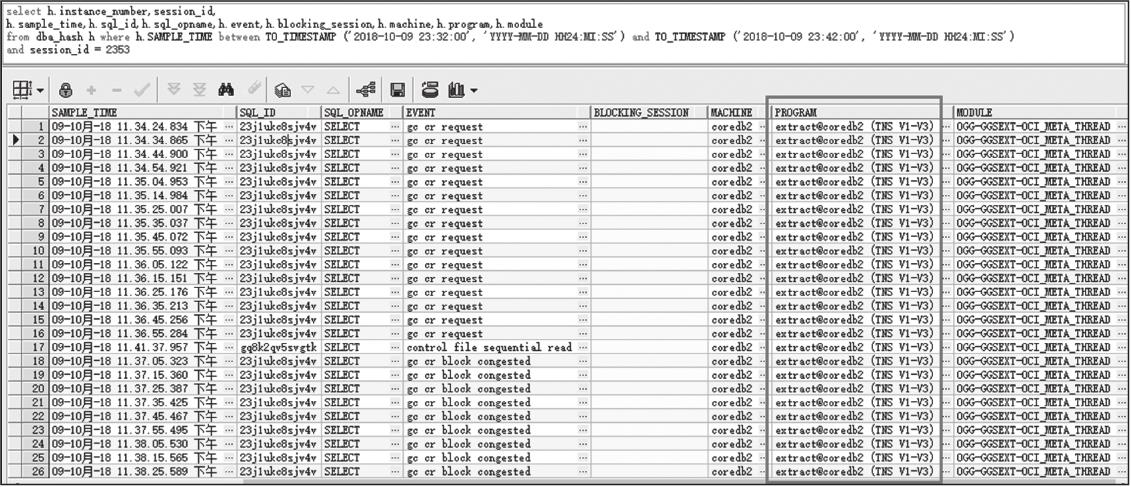
图2-52 2353会话信息
从以上会话信息中我们可以看出,最终锁的源头来自2353号会话,它没有被任何会话堵塞,经排查,此会话是OGG(Oracle GoldenGate)挖掘进程,在执行SQL 23j1ukc8sjv4v时构建了大量的全局CR块。分析到这里,触发的条件也已经很明确了,是OGG抽取进程引起的。
OGG是本次故障的导火索,OGG抽取导致了大量节点间的GC类等待,造成大量会话阻塞,引起节点间的DRM,触发Oracle Bug,最终导致宕机。
由于DRM触发了Oracle Bug,因此建议关闭DRM。
在Oracle 11g中,可以使用如下方式禁用DRM:
SQL> alter system set "_gc_policy_time"=0 scope=spfile;
然后,同时重启所有实例生效。如果不想完全禁用DRM,但是需要禁用read-mostly locking或reader bypass的机制。可以使用如下命令:
SQL> alter system set "_gc_read_mostly_locking"=false scope=spfile; SQL> alter system set "_gc_bypass_readers"=false scope=spfile;
某客户每月定期批量上传数据的时候,都会导致所有数据库节点挂起,临时处理方式较为简单粗暴,只要关闭节点2,业务就能恢复正常,数据库为Oracle 11.2.0.3的两节点集群。从整个故障的表面现象来看,高峰期节点上的通信存在问题。由于故障需要紧急处理,客户向Oracle SR(Service Request,服务请求)提交支持请求,按SR的要求上传故障时间段的AWR、OSWatch、告警日志及Hanganalyze信息。其中,AWR top 5的信息如图2-53所示。
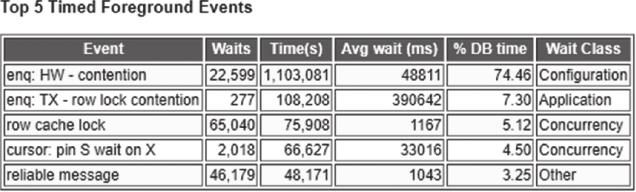
图2-53 AWR top 5信息图
SR根据提交的信息把问题定位在“enq: HW-contention”上,认为是当前数据文件自动扩展,高峰期无法及时扩展足够的空间,从而导致整体性能降低。SR提供的解决办法为:添加足够的数据文件,不要让业务在插入数据的同时还要等待空间的扩展。客户按照SR的建议及时做了调整,但并没有效果,在下个窗口期时又出现了同样的问题。此时已经过去了一个多月,问题陷入了僵局。客户找到我们以寻求帮助。
根据客户的描述及AWR Top 5的信息,笔者的第一反应是,SR把关注点放在“enq: HW-contention”上是错误的判断,这只是一个表象,真正的问题应该集中到“row cache lock”上。因为高水位更新势必要访问数据字典,且需要更新数据字典的信息,整个过程还会涉及集群间资源的通信。
为了验证猜想,笔者的排查过程具体如下。
查询故障时间段历史会话视图DBA_HIST_ACTIVE_SESS_HISTORY,根据等待事件分类统计,结果如下:
TRUNC(SAMPLE_TIME,' EVENT COUNT(1) ------------------- ------------------------------------------------- 2020-04-13 08:30:00 db file sequential read 3 2020-04-13 09:34:00 gc current request 4 2020-04-13 09:34:00 enq: WF - contention 4 2020-04-13 09:34:00 rdbms ipc reply 4 2020-04-13 09:34:00 PX Deq: Slave Session Stats 4 2020-04-13 09:34:00 gc buffer busy acquire 8 2020-04-13 09:34:00 db file sequential read 10 2020-04-13 09:34:00 enq: TX - index contention 22 2020-04-13 09:34:00 DFS lock handle 72 2020-04-13 09:34:00 cursor: pin S wait on X 80 2020-04-13 09:34:00 reliable message 120 2020-04-13 09:34:00 row cache lock 156 2020-04-13 09:34:00 enq: TX - row lock contention 316 2020-04-13 09:34:00 enq: HW - contention 2670 2020-04-13 09:35:00 db file sequential read 5 2020-04-13 09:35:00 gc current request 6 2020-04-13 09:35:00 PX Deq: Slave Session Stats 6 2020-04-13 09:35:00 enq: WF - contention 6 2020-04-13 09:35:00 rdbms ipc reply 6 2020-04-13 09:35:00 gc buffer busy acquire 12 2020-04-13 09:35:00 enq: TX - index contention 40 2020-04-13 09:35:00 DFS lock handle 108 2020-04-13 09:35:00 cursor: pin S wait on X 130 2020-04-13 09:35:00 reliable message 180 2020-04-13 09:35:00 row cache lock 250 2020-04-13 09:35:00 enq: TX - row lock contention 489 2020-04-13 09:35:00 enq: HW - contention 4177 ……
从历史视图统计信息来看,前几位与AWR报告中的Top 5相吻合,进一步排查相关等待事件的blocking_session,结果如下:
20200413 093432 571 ,1412 ,cursor: pin S wait on X 20200413 093432 6511 ,1436 ,enq: TX - row lock contention 20200413 093432 1993 ,1556 ,enq: TX - row lock contention 20200413 093432 1993 ,1570 ,enq: TX - row lock contention 20200413 093432 851 ,1700 ,cursor: pin S wait on X 20200413 093432 5359 ,1708 ,DFS lock handle 20200413 093432 1993 ,1710 ,enq: TX - row lock contention 20200413 093432 5359 ,1839 ,DFS lock handle 20200413 093432 6084 ,1851 ,enq: TX - row lock contention 20200413 093432 5359 ,1984 ,DFS lock handle 20200413 093432 2553 ,2131 ,cursor: pin S wait on X 20200413 093442 7777 ,7492 ,enq: TX - row lock contention 20200413 093442 5359 ,1984 ,DFS lock handle 20200413 093442 8485 ,8063 ,enq: TX - index contention 20200413 093442 8051 ,8184 ,enq: TX - row lock contention 20200413 093442 5359 ,8320 ,DFS lock handle 20200413 093442 8485 ,8488 ,enq: TX - index contention 20200413 093442 5359 ,8602 ,DFS lock handle 20200413 093442 2842 ,8627 ,enq: TX - row lock contention 20200413 093442 5363 ,8766 ,cursor: pin S wait on X 20200413 093442 857 ,8886 ,cursor: pin S wait on X 20200413 093442 6084 ,8896 ,enq: TX - row lock contention 20200413 093442 1836 ,5096 ,enq: TX - row lock contention 20200413 093442 8051 ,5377 ,enq: TX - row lock contention 20200413 093442 2553 ,5515 ,cursor: pin S wait on X 20200413 093442 7335 ,5807 ,gc buffer busy acquire 20200413 093442 6223 ,5937 ,cursor: pin S wait on X 20200413 093442 5359 ,6206 ,DFS lock handle 20200413 093442 6511 ,6507 ,enq: TX - row lock contention 20200413 093442 5359 ,6644 ,DFS lock handle 20200413 093442 857 ,6925 ,cursor: pin S wait on X 20200413 093442 5501 ,7055 ,cursor: pin S wait on X 20200413 093442 6633 ,7060 ,cursor: pin S wait on X 20200413 093442 6633 ,7076 ,cursor: pin S wait on X 20200413 093442 6633 ,7192 ,cursor: pin S wait on X …………
从中抽查相关等待事件的blocking_session,可以发现以上等待事件对应的blocking_session都为“row cache lock”,以下是部分内容:
blocking_session 571:
SQL> select SESSION_ID,SQL_ID,BLOCKING_SESSION,EVENT,MACHINE from dba_hist_active_
sess_history
2 where
3 sample_time > to_date('20200413 08:00:00', 'yyyymmdd hh24:mi:ss')
4 and sample_time < to_date('20200413 09:40:00', 'yyyymmdd hh24:mi:ss') and
SESSION_ID=571;
SESSION_ID SQL_ID BLOCKING_SESSION EVENT MACHINE
---------- ------------- ---------------- -------------- -------------------
571 4rtapbcm564s4 row cache lock zj140.localdomain
571 4rtapbcm564s4 row cache lock zj140.localdomain
571 4rtapbcm564s4 row cache lock zj140.localdomain
571 4rtapbcm564s4 row cache lock zj140.localdomain
......
blocking_session 6511:
SQL> select SESSION_ID,SQL_ID,BLOCKING_SESSION,EVENT,MACHINE from dba_hist_active_
sess_history
2 where
3 sample_time > to_date('20200413 08:00:00', 'yyyymmdd hh24:mi:ss')
4 and sample_time < to_date('20200413 09:40:00', 'yyyymmdd hh24:mi:ss') and
SESSION_ID=6511;
SESSION_ID SQL_ID BLOCKING_SESSION EVENT MACHINE
---------- ------------- ---------------- -------------- -------------------
6511 8z6rubny1tcnc row cache lock zj149.localdomain
6511 8z6rubny1tcnc row cache lock zj149.localdomain
6511 8z6rubny1tcnc row cache lock zj149.localdomain
6511 8z6rubny1tcnc row cache lock zj149.localdomain
6511 8z6rubny1tcnc row cache lock zj149.localdomain
......
blocking_session 6633:
SQL> select SESSION_ID,SQL_ID,BLOCKING_SESSION,EVENT,MACHINE from dba_hist_
active_sess_history
2 where
3 sample_time > to_date('20200413 09:34:00', 'yyyymmdd hh24:mi:ss')
4 and sample_time < to_date('20200413 09:40:00', 'yyyymmdd hh24:mi:ss') and
SESSION_ID=6633;
SESSION_ID SQL_ID BLOCKING_SESSION EVENT MACHINE
---------- ------------- ---------------- -------------- ------------------
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
6633 fjmp42y06f4j8 row cache lock zj137.localdomain
.......
从以上查询结果来看,几乎90%的会话其堵塞源头都为“row cache lock”,涉及的SQL为业务语句,且没有被任何会话堵塞,那么是什么使得此类会话一直处于“row cache lock”等待事件中呢?进一步查看当前业务序列是否存在cache较小,且为order的sequence,结果如下:
SQL> SELECT * FROM DBA_SEQUENCES where SEQUENCE_OWNER='YJBSDATA0215' and ORDER_FLAG=
'Y' and CACHE_SIZE=20 by 6,7,8;
SEQUENCE_OWNER SEQUENCE_NAME MIN_VALUE MAX_VALUE INCREMENT_BY C O CACHE_SIZE.LAST_NUMBER
-------------- -------------------- --------- ---------- ------------ - - ---------- ----------
YJBSDATA0215 SEQ_MESSAGEATTACH 1 1.0000E+27 1 N N 20000 22649428
YJBSDATA0215 SEQ_MESSAGESOURCE 1 1.0000E+27 1 N N 20000 33591129
YJBSDATA0215 SEQ_MOBILESOURCE 1 1.0000E+27 1 N N 20000 36428141
YJBSDATA0215 SEQ_QUERY_TEMP_CAT_ID 1 1.0000E+28 1 N N 20000 10180020
…………
从查询结果来看并不存在此类sequence,问题再一次陷入僵局。
再回到原点,既然“enq: HW-contention”高水位更新需要访问数据字典,且对其进行变更,那么我们就可以定位具体访问的基表,并进一步确认基表是否存在性能问题。数据库的最小扩展单元为区,访问视图为DBA_EXTENTS,下面就来统计当前数据库区的数据量:
SQL> SELECT COUNT(*) FROM DBA_EXTENTS;
半小时过去了,以上查询依然没有返回结果,后台数据库等待事件同为“row cache lock”。笔者感觉问题似乎有了眉目。DBA_EXTENTS只是Oracle提供给我们查询的视图,底层访问的对象还是基表。尝试收集数据库基表和字典统计信息,依然没有好转。进一步通过10046跟踪上述查询,结果显示一直卡在x$ktfbue基表访问上。Oracle对该表的官方解释如下:
x$ktfbue:kernel transaction, file bitmap used extent,used extent bitmap in file header for LMT (equivalent to uet$ in DMT); check dba_extents view definition,ktfb –space/spcmgmt support for bitmapped space manipulation of files/tablespaces KTFBUE means K[Kernel] T[Transaction] F[File] B[Bitmap] U[Used] E[Extents]。
从字面意义上我们可以知道,对区的任何操作都需要访问x$ktfbue,至此问题终于明朗了,是对x$ktfbue的访问出现了性能问题,既然收集统计信息也无法规避,那就查询MOS:Query Against DBA_EXTENTS Performs Slowly After Upgrade to 11.2.0.3 (Doc ID: 1453425.1)。
官方对该问题的解释如图2-54所示。
由于x$ktfbue缺乏统计信息,因此当该表中存在大量的对象时,会产生严重的性能问题。正常情况下,GATHER_FIXED_OBJECTS_STATS不会对该表进行收集。收集需要我们手动完成,命令如下:
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS('SYS', 'X$KTFBUE');
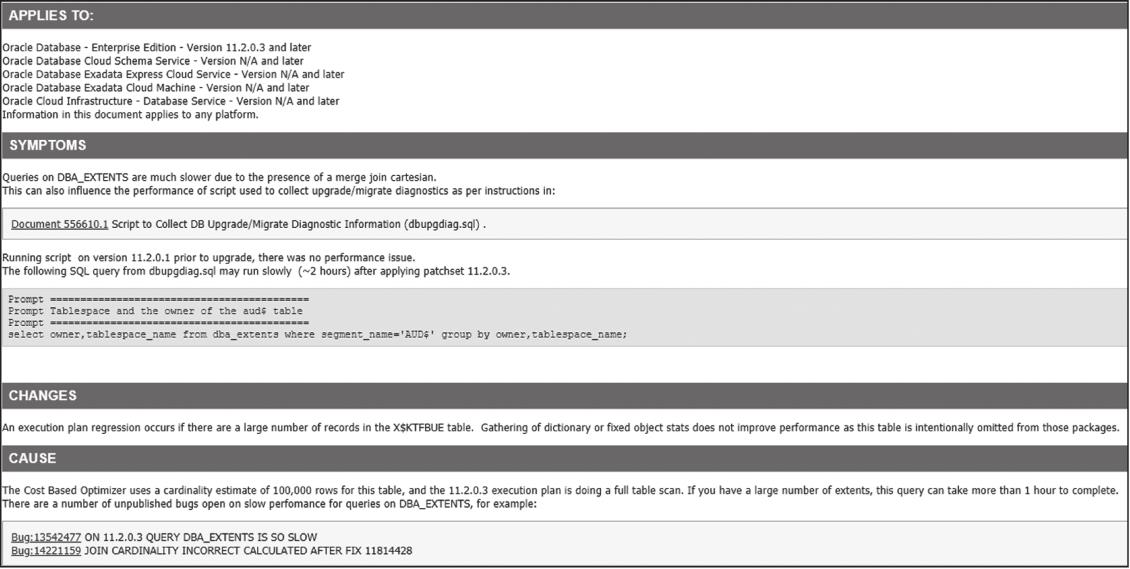
图2-54 官方文档信息
查询当前业务用户的表格数据量,发现居然多达三四百万个。正常情况下,省级单位运营商的CRM库对象数也就几十万。于是我们进一步了解到该业务厂商存在缺陷,即每上一个新功能,都无法复用原来的表格,需要重新建表,所以导致单库的表格数量剧增,并最终引发了此问题。
至此,整个故障得到了顺利解决,客户再也不用为每月数据上传而头痛。
纵观整个故障的解决过程,我们不应被AWR报告中的Top 5所迷惑,从而形成思维定势,扎实的理论基础有助于我们拨开层层迷雾,找到真正的根本原因。此案例中的“enq: HW-contention”只是一个表象,高水位线操作需要访问数据字典,且需要更新数据字典的信息,由于涉及的基表x$ktfbue数据量巨大,而且整个过程还会涉及集群间资源的通信,因此很容易陷入复杂的表象而无法找到真正的问题所在。