
下载掌阅APP,畅读海量书库
立即打开




数据库连接类问题最为常见,很多因素都会导致连接异常,主要有:网络限制、部分平台监听日志大于4GB的限制、防火墙、客户端自身问题、数据库自身故障、服务器主机资源不足,等等。万变不离其宗,我们只需要掌握基本的排查思路,使用合适的工具,找出原因自然就能水到渠成。本节将以常见的连接问题为例,与大家分享此类问题的排查思路。
在本节开始之前,我们不妨先了解一下数据库的连接过程。
监听存在于数据库服务器端,是连接客户端与数据库的桥梁。如图2-1所示,在启动数据库实例时,LREG(Listener Registration,监听器注册)进程(Oracle 12c之前是PMON进程)会将实例名、数据库服务名及服务处理程序的类型和地址注册到监听中,以监听客户端的连接请求。
当客户端发起连接请求,请求到达服务器端后,监听会进行认证,并将请求转发至数据库。数据库端会分配新的服务器进程(专用服务器模式)或共享原有的服务器进程(共享服务器模式),与客户端进程直接通信。建立连接后,监听的使命就结束了,建立连接的过程如图2-2所示。
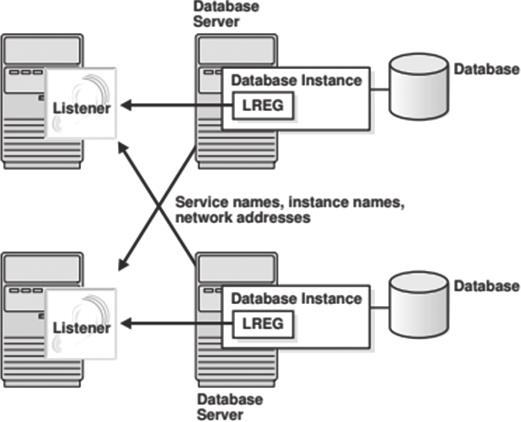
图2-1 监听注册
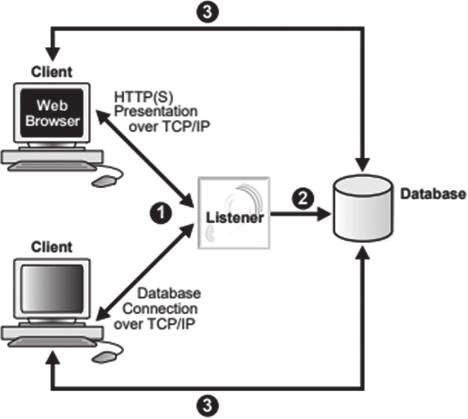
图2-2 连接建立过程
下面列举几种连接异常的现象。
·之前连接正常,在无任何改动的情况下,所有客户端都无法连接,如果网络是正常的,则很有可能是服务器端的问题。
·若连接大部分都是正常的,只有个别或新添加的客户端无法连接,则很有可能是客户端自身的问题。
·若与服务器同网段的连接是正常的,而跨网段的连接出现异常,则很有可能是网络限制(如没有正确添加路由等)的问题。
·连接缓慢或间接性无法连接,排除监听日志4GB的限制和资源不足的情况,在网络正常的情况下需要开启跟踪,以便有更多信息进行具体分析。
在开始讲解具体案例之前,这里先介绍下笔者常用的排查思路,如果是全局性访问故障,那么数据库服务器端的检查可直接跳至步骤5。
1)客户端ping连接地址,以确定是否存在较大的延迟或丢包。建议使用ping大包的形式“ping -l 65500 IP地址”,示例代码如下:
C:\Users\yehua>ping -l 65500 192.168.239.236
如出现大量延迟或丢包,则进一步排查网络。
2)检查客户端和服务器端的防火墙是否关闭。在Windows系统中,具体操作方法为:依次选择“控制面板”→“Windows防火墙”→“启动或关闭Windows防火墙”→“关闭Windows防火墙”。
在Linux系统中,查看防火墙状态,命令如下:
shell> service iptables status <!--Linux 6及以下--> shell> systemctl status firewalld <!--Linux 7及以上-->
关闭防火墙,命令如下:
shell> service iptables stop <!--Linux 6及以下--> shell> chkconfig iptables off shell> systemctl stop firewalld <!--Linux 7及以上--> shell> systemctl disable firewalld
3)在相同网段内,检查其他客户端使用sqlplus是否会出现相同的报错信息。命令格式为“sqlplus username/password@连接串或IP地址:端口号/数据库服务名”,示例代码如下:
SQL> sqlplus system/oracle@192.168.239.236:1521/jason
4)在客户端使用tnsping,检查网络和监听端口是否正常。命令格式为“tnsping IP地址:端口号 检测次数”,示例代码如下:
shell> tnsping 192.168.239.236:1521 10
5)tnsping内容解析,例如:
shell> tnsping 192.168.239.236:1521 10
TNS Ping Utility for Linux: Version 11.2.0.4.0 - Production on 02-FEB-2020 19:41:15
Copyright (c) 1997, 2013, Oracle. All rights reserved.
Used parameter files:
Used HOSTNAME adapter to resolve the alias
Attempting to contact (DESCRIPTION=(CONNECT_DATA=(SERVICE_NAME=orcl))
(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.239.236)(PORT=1521)))
OK (10 msec)
以上测试结果显示解析成功。请求通过TCP网络协议(PROTOCOL=TCP),连接到IP地址为192.168.239.236的服务器(也可以是主机名),希望连接的端口为1521,服务名为orcl(SERVICE_NAME=orcl),连接10毫秒是网络传输往返一次的时间。
如果步骤5返回错误,则可以进一步在客户端开启tnsping跟踪,在sqlnet.ora文件中加入以下参数:
TNSPING.TRACE_LEVEL=SUPPORT TNSPING.TRACE_DIRECTORY=d:\oracle\trace
其中,TNSPING.TRACE_LEVEL表示跟踪的级别,SUPPORT为最高级别,该参数可选的级别包括off、user、admin、support,建议使用SUPPORT,因为输出的信息越详细越有助于分析。
TNSPING.TRACE_DIRECTORY指的是用于存放跟踪所产生的trace文件的位置。
 tnsping只检查TCP和服务器上的监听是否正常,不会检查服务器上的数据库是否正常。也就是说无论数据库是否正常运行,只要监听正常运行,就可以成功解析。
tnsping只检查TCP和服务器上的监听是否正常,不会检查服务器上的数据库是否正常。也就是说无论数据库是否正常运行,只要监听正常运行,就可以成功解析。
接下来检查服务器端数据库的状态,使用有效的用户名和密码登录数据库进行连接测试。
数据库用户执行命令如下:
shell> ps -ef | grep smon|grep -v grep
oracle 30465 1 0 Feb02 ? 00:00:16 ora_smon_SID
shell> export ORACLE_SID=SID
shell> sqlplus / as sysdba
SQL> select inst_id,open_mode from gv$database;
INST_ID OPEN_MODE
---------- --------------------
1 READ WRITE
若返回的内容不是读写模式,则表示数据库异常,不在本节讨论范围之内。
6)检查服务器端的监听和服务注册情况。数据库用户执行如下命令,检查监听状态:
shell> lsnrctl status <!--……省略部分版本信息--> (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=192.168.238.29)(PORT=1521)))
上述结果说明主机地址为192.168.238.29,开启的监听端口为1521。
Services Summary... Service "cdb19c" has 2 instance(s). Instance "cdb19c", status UNKNOWN, has 1 handler(s) for this service... Instance "cdb19c", status READY, has 1 handler(s) for this service...
上述结果说明服务名和数据库的实例名均为cdb19c,状态值分别为UNKNOWN和READY,说明目前有一个静态注册和一个动态注册。
Service "pdb1" has 1 instance(s). Instance "cdb19c", status READY, has 1 handler(s) for this service...
上述结果说明服务名为pdb1,数据库实例名为cdb19c,状态值为READY,说明是动态注册。
The command completed successfully
当监听的状态是动态注册时,服务名和实例名分别来自数据库参数service_names和instance_name;而当监听的状态是静态注册时,服务名和实例名则取决于监听文件listener.ora中GLOBAL_DBNAME和SID_NAME的配置。
监听中的实例状态主要分为以下四种。
·UNKNOWN:表示静态注册。
·READY:表示数据库处于mount或open状态,可以对外提供服务。
·BLOCKED:表示数据库处于nomount状态,不接受客户端连接。
·RESTRICTED:表示数据库处于受限模式,只有拥有RESTRICTED SESSION权限的用户才可以登入。
查看监听服务信息,输出如下:
shell> lsnrctl services
LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 05-FEB-2020 21:23:11
Copyright (c) 1991, 2019, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=192.168.238.29)(PORT=1521)))
Services Summary...
Service "cdb19c" has 2 instance(s).
Instance "cdb19c", status UNKNOWN, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:13542 refused:0
LOCAL SERVER
Instance "cdb19c", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:289 refused:0 state:ready
LOCAL SERVER
Service "pdb1" has 1 instance(s).
Instance "cdb19c", status READY, has 1 handler(s) for this service...
Handler(s):
"DEDICATED" established:289 refused:0 state:ready
LOCAL SERVER
The command completed successfully
除了服务名、实例名和状态之外,监听服务信息还包括服务模式(专用DEDICATED和共享SHARED)、连接(established)次数、拒绝(refused)次数和服务器属性(本地LOCAL和远程REMOTE)。
查看监听状态和服务的目的是确保客户端连接的数据库名和实例名已经成功注册为ready。
数据库正常,但监听无法注册的解决办法如下。
方法一:通过静态注册快速解决,需要重启监听。
方法二:排查动态注册出现异常的原因。
动态注册排查方法的具体步骤如下。
1)检查数据库参数local_listener和remote_listener的配置。默认情况下,单机使用1521端口,两个参数均为空。
·local_listener
RAC使用当前节点的VIP地址,例如:
SQL> alter system set local_listener='(ADDRESS=(PROTOCOL=TCP)(HOST= node1-vip)
(PORT=1521))' sid='orcl1';
·remote_listener
Oracle 10g为对方节点的VIP地址,例如:
SQL> alter system set remote_listener='(ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)
(HOST = node 1-vip)(PORT = 1521))(ADDRESS = (PROTOCOL = TCP)(HOST = node 2-vip)
(PORT = 1521)))';
Oracle 11g及以上为SCAN地址,例如:
SQL> alter system set remote_listener='rac-scan:1521';
需要注意的是,HOST使用别名的,需要确保/etc/hosts或DNS已进行了解析。
2)检查/etc/hosts对应的IP和主机名解析,检查sqlnet.ora是否设置了限制。
Windows默认情况下如下:
SQLNET.AUTHENTICATION_SERVICES= (NTS)
说明允许本地操作系统用户认证。
Linux默认情况下如下:
NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
其中,TNSNAMES和EZCONNECT表示允许支持的连接格式,具体如下:
shell> sqlplus system/oracle@orcl <!-- orcl为tnsnames.ora中的连接串 --> shell> sqlplus system/oracle@hostname:port/service_name <!--以上表示简易连接方式-->
在不清楚参数的情况下,建议还原默认。
 sqlnet是Oracle提供的用于网络层面交互的一个工具,比如,解析客户端发起的连接、对连接进行辨别、特定连接的阻隔限制、启用日志跟踪等一系列的功能。
sqlnet是Oracle提供的用于网络层面交互的一个工具,比如,解析客户端发起的连接、对连接进行辨别、特定连接的阻隔限制、启用日志跟踪等一系列的功能。
下面就来介绍sqlnet.ora的常用参数。
客户端限制(默认为no),格式如下:
TCP.VALIDNODE_CHECKING
示例代码如下:
TCP.VALIDNODE_CHECKING=yes
指定不允许访问的客户端,可以使用主机名或IP地址,以逗号分隔,格式如下:
TCP.EXCLUDED_NODES=(hostname | ip_address, hostname | ip_address, ...)
示例代码如下:
TCP.EXCLUDED_NODES=(192.168.238.102, 192.168.238.102)
指定允许访问的客户端,优先级高于TCP.EXCLUDED_NODES,格式如下:
TCP.INVITED_NODES=(hostname | ip_address, hostname | ip_address, ...)
示例代码如下:
TCP.INVITED_NODES=(192.168.238.102, 192.168.238.102)
客户端建立连接超时时间(单位为秒),超时之后连接会被中断,同时报错,示例代码如下:
SQLNET.INBOUND_CONNECT_TIMEOUT=10
限制可以连接到数据库服务器上的最小客户端版本,格式如下:
SQLNET_ALLOWED_LOGON_VERSIONS=n
该参数在Oracle 12c及以上版本中的格式如下:
SQLNET.ALLOWED_LOGON_VERSION_SERVER=n SQLNET.ALLOWED_LOGON_VERSION_CLIENT=n
手动注册命令如下:
shell> sqlplus / as sysdba SQL> alter system register; System altered.
感兴趣的读者可以进一步设置数据库10257事件,跟踪LREG进程(Oracle 12c之前为PMON进程)动态注册的过程。
本节先简单介绍一下数据库的两种连接模式,专用服务器模式和共享服务器模式。
(1)专用服务器模式
当客户端登入数据库时,Oracle监听会创建一个新进程,这个新进程通常是专用服务器进程,继承了监听建立的连接,可与客户端进程直接通信,这种一对一的模式称为专用服务器模式,如图2-3所示。
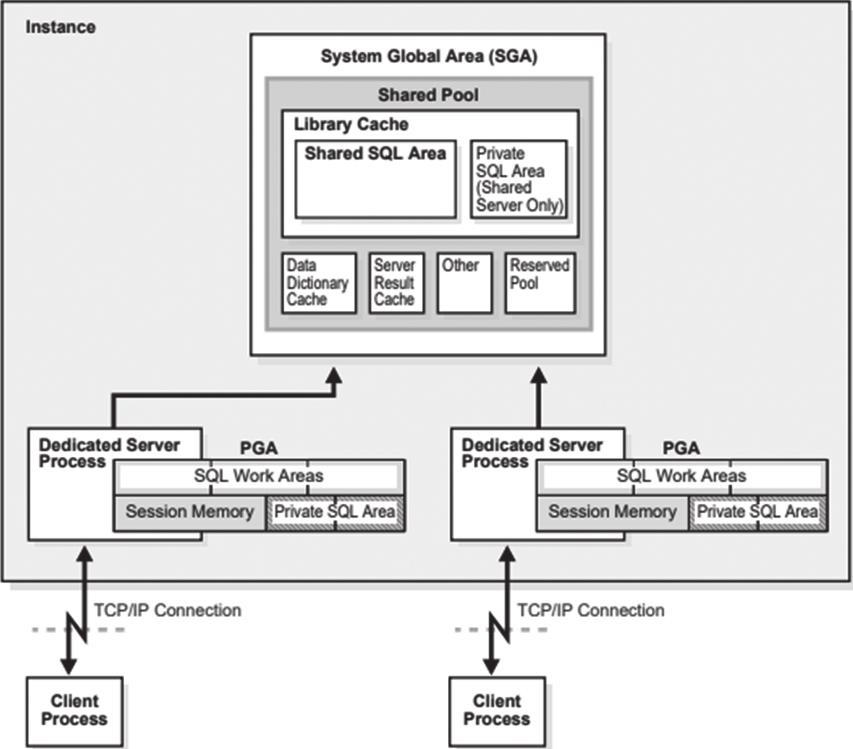
图2-3 专用服务器模式
(2)共享服务器模式
客户端的所有连接均使用限定数量的服务器进程,类似于连接池,可通过资源调度dispatcher进程来动态管理会话,与实例建立连接,连接信息供所有的会话共享,这种连接方式可以有效地减少资源负载,如图2-4所示。
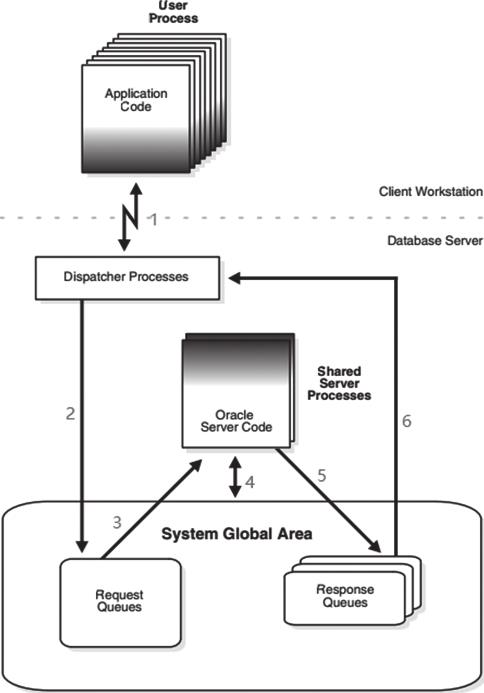
图2-4 共享服务器模式
共享服务器的连接模式的工作原理主要可分为如下6个步骤。
1)用户发起连接请求。
2)监听监测到请求,返回调度进程地址,此时用户进程与空闲调度进程直接连接。
3)用户发起操作请求(如DML),调度进程负责把请求放入请求队列中。
4)空闲的共享服务进程从请求队列中接过请求,转为后台处理。
5)共享服务进程处理完请求之后,把结果放入相应的队列中。
6)对应的调度进程从相应的队列中把结果返回给前端用户。
了解了专用服务器模式和共享服务器模式之后,接下来我们通过具体的故障案例进行分析。
某客户医院前台操作人员反应,程序正常登入后,业务响应出现延迟,并且延迟呈现逐渐增大的趋势。检查后台服务器和数据库的状态发现它们都很空闲,尝试重启数据库之后,业务卡顿消失了,但过了十几分钟后问题依旧。排除了网络和业务程序自身的问题之后,考虑到事态的紧急性,该医院希望我们给予帮助。
从客户的描述中,我们可以获得两个重要的信息。
第一,在后台服务器和数据库都很空闲的情况下,前台业务却出现了卡顿甚至瘫痪的现象。
第二,尝试重启数据库之后,起初十几分钟运行正常,随后又出现了卡顿的现象。
综合上面的背景知识就是:后台空闲,程序可以正常登入,每当发出请求时会出现卡顿。我们很容易联想到这种情况与共享模式(多个客户端进程对应于同一个服务器进程)类似,因为在连接正常的情况下,用户发起了操作请求,对应的调度进程会将这个请求放入一个请求队列中,后台空闲的共享服务进程会处理队列中的请求。
调度进程接受请求,并将其放入请求队列中,这一步理论上很快就能完成,不需要额外的处理。因此更有可能是在对请求的处理上出现了问题,没有空闲的共享服务进程可用于处理队列中的请求。而在独占模式中,一个客户端进程对应于一个服务器进程,理论上是不可能存在处理不过来的情况。如果在这种模式下出现了问题,那么表象不太可能为后台空闲,更有可能是数据库整体负载较高,可以通过查询后台数据库的等待事件来进行确认。
由于已经初步判定是共享模式引起的问题,因此处理就变得很简单了,只需要查看下服务进程的繁忙程度即可,笔者进行排查及处理的过程如下。
1)查看客户端的连接配置,命令如下:
HIS =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.172.16.51)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = SHARED)
(SERVICE_NAME = his)
)
)
从客户端的连接配置上可以看出是共享连接模式(SERVER=SHARED),如为DEDICATED则是独占模式。
2)查看数据库共享模式的参数配置,命令如下:
SQL> show parameter shared_server NAME TYPE VALUE -------------------- ----------- -------- max_shared_servers integer 15 shared_servers integer 5 SQL> show parameter dispatchers NAME TYPE VALUE ----------------- ----------- ---------------------- dispatchers string (protocol=TCP)(disp=5) max_dispatchers integer 15
当前数据库配置了5个共享服务进程,最大可以增加到15个,此外还有15个调度进程,可以通过DBA_HIST_RESOURCE_LIMIT、v$shared_server来查询相关线索,查询结果具体如下:
SQL> select to_char(dhs.begin_interval_time,'yyyy-mm-dd hh24:mi:ss') begin_time, 2 to_char(dhs.end_interval_time,'yyyy-mm-dd hh24:mi:ss') end_time, 3 dhs.error_count, 4 dhr.current_utilization, 5 dhr.max_utilization, 6 dhr.initial_allocation, 7 dhr.limit_value 8 from DBA_HIST_SNAPSHOT dhs, dBA_HIST_RESOURCE_LIMIT dhr 9 where dhs.snap_id = dhr.snap_id 10 and dhr.resource_name = 'max_shared_servers' 11 and dhs.begin_interval_time >= sysdate - 3 12 order by dhs.begin_interval_time 13 ; BEGIN_TIME END_TIME ERROR_COUNT CURRENT_UTILIZATION MAX_UTILIZATION INITIAL_AL LIMIT_VALU ------------------- ------------------- ----------- ------------------- --------------- --------- ---------- 2018-08-05 00:00:50 2018-08-05 01:00:51 0 5 15 15 15 2018-08-05 01:00:51 2018-08-05 02:00:53 0 5 15 15 15 2018-08-05 12:00:11 2018-08-05 13:00:12 0 5 15 15 15 2018-08-05 13:00:12 2018-08-05 14:00:14 0 5 15 15 15 2018-08-05 14:00:14 2018-08-05 15:00:16 0 5 15 15 15 2018-08-05 15:00:16 2018-08-05 16:00:18 0 5 15 15 15 ......... 2018-08-06 15:00:28 2018-08-06 16:00:31 0 10 15 15 15 2018-08-06 16:00:31 2018-08-06 17:00:34 0 5 15 15 15 2018-08-06 17:00:34 2018-08-06 18:00:36 0 15 15 15 15 SQL> select name,paddr,status from v$shared_server; NAME PADDR STATUS ---- ---------------- ------- S000 0000000555643BC0 EXEC S001 000000055F626AA0 EXEC ………… S013 000000055F628258 EXEC S014 0000000554633BC0 EXEC
从以上的查询结果中,我们可以看出max_shared_servers已经达到了阈值,没有空闲进程。
3)获取AWR报告中的Resource limit stats(资源限制统计)信息,如图2-5所示。
从图2-5所示的信息中,我们可以确定共享服务进程无法及时处理队列中的用户请求。这也很好地解释了数据库刚重启时,少量连接请求可以得到及时处理,随后大量短连接请求的涌入,导致共享服务进程的处理达到阈值,真正进行处理的只有15个,大量的请求需要等待,没有更多的空闲进程可以及时响应,从而最终导致前台业务卡顿,甚至瘫痪,而后台却在有条不紊地处理着,完全不受影响。
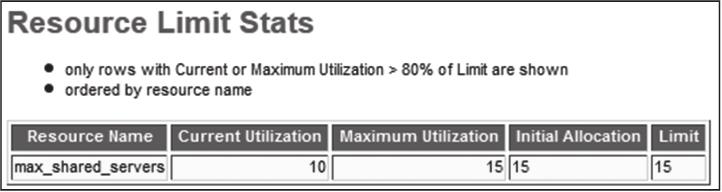
图2-5 资源限制统计信息
4)尝试增大共享服务进程的数量,命令如下:
SQL> alter system set shared_servers=25 scope=both; SQL> alter system set max_shared_servers=64 scope=both;
建议将客户端的连接方式改为独占模式,调整后前端业务的响应恢复正常,部分报表的响应速度甚至提升了十几倍,高峰期部分指标如下:
SQL> show parameter shared
NAME TYPE VALUE
-------------------- ----------- -------
max_shared_servers integer 64
shared_servers integer 25
SQL> select * from v$shared_server;
NAME PADDR STATUS MESSAGES BYTES BREAKS CIRCUIT IDLE BUSY REQUESTS
---- ---------------- ------------ -------- ---------- ------ ---------------- ------- ------- -------
S000 0000000555643BC0 EXEC 11454818 2105059612 42 000000053E1E3200 4529569 938843 5194393
S001 000000055F626AA0 EXEC 12063877 -2.051E+09 44 000000053E1C72E0 4604522 880297 5467012
S002 0000000554632408 WAIT(COMMON) 5726827 1044253633 14 00 5012629 425267 2634644
S003 00000005536189E8 EXEC 4145671 696887819 14 000000053E25AE40 5069606 331440 1927876
S004 000000055261B6C0 WAIT(COMMON) 3212409 534293834 8 00 5140040 229041 1500560
S005 0000000555644B90 WAIT(COMMON) 2267115 383516856 4 00 5173062 155117 1058536
S006 000000055F627A70 WAIT(COMMON) 1430568 234844847 3 00 5203964 90458 669769
S007 00000005546333D8 WAIT(COMMON) 749779 121237513 1 00 5217578 49578 353141
S008 00000005536199B8 WAIT(COMMON) 356894 59909704 1 00 5231489 19591 167091
S009 000000055261C690 WAIT(COMMON) 134519 25200690 0 00 5233794 8315 61989
S010 000000055761B7D0 WAIT(COMMON) 61101 8078338 0 00 5233823 5026 29240
S011 0000000556646A30 WAIT(COMMON) 18756 4338037 0 00 5235550 1835 8276
S012 0000000555645378 WAIT(COMMON) 10120 1346641 0 00 5236590 528 4943
S013 000000055F628258 WAIT(COMMON) 14003 2832678 0 00 5235432 1596 6356
S014 0000000554633BC0 WAIT(COMMON) 9596 1976491 0 00 5236730 285 4334
S015 000000055361A1A0 WAIT(COMMON) 10549 1776995 0 00 5236130 872 4839
S016 000000055261CE78 WAIT(COMMON) 8448 924735 0 00 5236742 240 4056
S017 000000055761BFB8 WAIT(COMMON) 17170 3229260 0 00 5235749 1239 7621
S018 0000000556647218 WAIT(COMMON) 11933 4485784 0 00 5236318 662 4593
S019 0000000555645B60 WAIT(COMMON) 11296 1849918 0 00 5236091 896 5246
S020 000000055F628A40 WAIT(COMMON) 12539 2496767 0 00 5236195 790 5428
S021 00000005546343A8 WAIT(COMMON) 15769 3493024 0 00 5235557 1443 6780
S022 000000055361A988 WAIT(COMMON) 19642 3658632 0 00 5235996 973 9055
S023 000000055261D660 WAIT(COMMON) 13758 1690192 0 00 5236196 762 6423
S024 000000055761C7A0 WAIT(COMMON) 12112 1505727 0 00 5236111 847 5815
SQL> select * from v$shared_server_monitor;
MAXIMUM_CONNECTIONS MAXIMUM_SESSIONS SERVERS_STARTED SERVERS_TERMINATED SERVERS_HIGHWATER
------------------- ---------------- --------------- ------------------ -----------------
318 318 20 0 25
从高峰期的返回结果来看,大部分服务进程仍处于空闲等待状态,进程数也一直维持在初始值25上,没有上升。持续观察一周,问题不再复现。
从本次故障的处理实践中,我们可以总结出共享模式的几个优缺点,具体如下。
共享模式具有如下优点。
·减少了实例中的进程数。
·减少了空闲服务器中进程的数量。
·减少了PGA(Program Global Area,程序全局区域)的内存使用。
共享模式具有如下缺点。
·同一个共享进程上的会话,事物是串行处理的,因此只要有一个会话阻塞,该服务进程上的所有会话都会被阻塞。
·存在独占事务的现象,如果某个请求事务运行时间过长,独占了共享资源,那么其他用户就只能等待,而对于专用服务器,每个客户端对应于一个服务进程。
然而,如今内存资源充足,进程上的资源消耗几乎可以忽略不计,所以建议改用独占的连接模式。
某客户利用物理备份和异机恢复的方式搭建测试环境,由于测试环境与生产同属于一个网段,因此搭建完后,客户端连接间接性报错,而指定实例名的连接则是正常的。
从客户的描述中,我们可以获取到如下两个重要的信息。
第一,此问题是在测试库搭建完之后开始出现的。
第二,间接性连接问题,连接时好时坏。
尝试让客户关闭测试环境,上述现象消失,这说明基本上可以排除网络问题,因此问题所在就指向了测试库,那么到底是什么原因影响了生产的连接(大家可以查看笔者在2.2节提到的连接问题排查思路,第6步就能找到答案),这里我们继续使用sqlnet开启连接跟踪。设置如下:
TRACE_LEVEL_CLIENT=16 TRACE_FILE_CLIENT=CLIENT TRACE_TIMESTAMP_CLIENT=ON TRACE_DIRECTORY_CLIENT=D:\oracle\product\10.2.0\db_1\network\ADMIN
·TRACE_LEVEL_CLIENT:开启客户端跟踪级别,取值范围为0~16,当然级别越高,收集的信息相对就会越全面,系统默认是0,即不生成跟踪信息。
·TRACE_FILE_CLIENT:设置是客户端还是服务器端。
·TRACE_TIMESTAMP_CLIENT:是否记录每条日志的时间戳。
·TRACE_DIRECTORY_CLIENT:设置trace文件的产生目录。
尝试模拟客户端连接,命令如下:
C:\Documents and Settings\Administrator>sqlplus system/abc123@orcl ERROR: ORA-12545: 因目标主机或对象不存在, 连接失败 请输入用户名:
收集sqlnet跟踪信息,输出内容如下:
[02-12月-2014 14:10:32:968] nsmfr: normal exit
[02-12月-2014 14:10:32:968] nsmfr: entry
[02-12月-2014 14:10:32:968] nsmfr: 736 bytes at 0xe4b9d8
[02-12月-2014 14:10:32:968] nsmfr: normal exit
[02-12月-2014 14:10:32:968] nsclose: normal exit
[02-12月-2014 14:10:32:968] nscall: connecting...
[02-12月-2014 14:10:32:968] nsc2addr: entry
[02-12月-2014 14:10:32:968] nsc2addr: (ADDRESS=(PROTOCOL=tcp)(HOST=hp)(PORT=3554))
[02-12月-2014 14:10:32:968] nttbnd2addr: entry
[02-12月-2014 14:10:32:968] snlinGetAddrInfo: entry
[02-12月-2014 14:10:32:968] snlinGetAddrInfo: Invalid IP address string hp
[02-12月-2014 14:10:32:968] snlinFreeAddrInfo: entry
[02-12月-2014 14:10:32:968] snlinFreeAddrInfo: exit
[02-12月-2014 14:10:32:968] snlinGetAddrInfo: exit
[02-12月-2014 14:10:32:968] nttbnd2addr: looking up IP addr for host: hp
[02-12月-2014 14:10:32:968] snlinGetAddrInfo: entry
[02-12月-2014 14:10:35:218] snlinGetAddrInfo: Name resolution failed for hp
[02-12月-2014 14:10:35:218] snlinFreeAddrInfo: entry
[02-12月-2014 14:10:35:218] snlinFreeAddrInfo: exit
[02-12月-2014 14:10:35:218] snlinGetAddrInfo: exit
[02-12月-2014 14:10:35:218] nttbnd2addr: *** hostname lookup failure! ***
[02-12月-2014 14:10:35:218] nttbnd2addr: exit
[02-12月-2014 14:10:35:218] nserror: entry
[02-12月-2014 14:10:35:218] nserror: nsres: id=0, op=77, ns=12545, ns2=12560;
nt[0]=515, nt[1]=1001, nt[2]=0; ora[0]=0, ora[1]=0, ora[2]=0
[02-12月-2014 14:10:35:218] nsc2addr: error exit
从以上的跟踪信息中我们可以得知,如果尝试使用orcl连接串进行连接,就会被路由到HP主机上,可是tnsnames.ora连接串里面根本没有配置相关的信息。接下来进一步确认HP主机是否为测试环境,命令如下:
C:\Documents and Settings\Administrator>ping hp Pinging hp [192.168.0.80] with 32 bytes of data: Reply from 192.168.0.80: bytes=32 time<1ms TTL=128
由上述代码可知,HP主机正是刚恢复的测试环境。
下面进一步查看生产库的监听状态,命令如下:
C:\Documents and Settings\Administrator>lsnrctl status 正在连接到 (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) LISTENER 的 STATUS ------------------------ 监听端点概要... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=svr01)(PORT=1521))) 服务摘要.. 服务 "+ASM" 包含 1 个例程。 例程 "+asm2", 状态 BLOCKED, 包含此服务的 1 个处理程序... 服务 "+ASM_XPT" 包含 1 个例程。 例程 "+asm2", 状态 BLOCKED, 包含此服务的 1 个处理程序... 服务 "orcl" 包含 3 个例程。 例程 "orcl1", 状态 READY, 包含此服务的 31 个处理程序... 例程 "orcl2", 状态 READY, 包含此服务的 32 个处理程序... 例程 "orclstd", 状态 READY, 包含此服务的 2 个处理程序... 服务 "orcl_XPT" 包含 3 个例程。 例程 "orcl1", 状态 READY, 包含此服务的 31 个处理程序... 例程 "orcl2", 状态 READY, 包含此服务的 32 个处理程序... 例程 "orclstd", 状态 READY, 包含此服务的 2 个处理程序... 命令执行成功
其中,orclstd正是本次故障的元凶,是测试库的实例名。测试库通过remote_listener将自己的实例信息注册到远端生产的监听中。下面再来进一步确认一下,命令如下:
C:\Documents and Settings\Administrator>sqlplus system/abc123@orcl
SQL> select instance_name from v$instance;
INSTANCE_NAME
----------------
orclstd
SQL> show parameter remote
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
remote_listener string LISTENERS_ORCL
C:\Documents and Settings\Administrator>tnsping listeners_orcl
D:\oracle\product\10g\network\admin\sqlnet.ora
Attempting to contact (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST =
svr02-vip)(PORT = 1521)) (ADDRESS = (
PROTOCOL = TCP)(HOST = svr01-vip)(PORT = 1521)))
OK (20 毫秒)
以上内容已经很明显了,当客户端使用orcl服务名连接数据库时,监听会根据服务名将连接分配到orcl1、orcl2和orclstd其中的一个例程上,每当路由到orclstd时就会报错。
处理方式也很简单,只需要将测试库的remote_listener置空即可。
此类问题笔者几乎每年都会碰到,主要还是由于某些DBA为了省事,忽略了基本参数的检查所导致的。
很多攻击者会利用远程注册这一特性,在监听下远程注册同名数据库实例。新登入的用户,在TNS(透明网络底层)负载均衡的策略下,有可能会登录到伪造的监听服务上,攻击者会监控用户的登入过程,并将相关数据流量转发到真实的数据库上。利用CVE-2012-3137获得通信过程中的认证相关信息,并对认证相关信息进行离线的暴力破解,获得登入密码,最后完成对生产数据的访问。这就是Oracle TNS监听远程注册投毒原理。
下面就来介绍上述问题的处理方法。在Oracle 11g 11.2.0.4及以上版本的所有节点的listener.ora文件中进行如下操作。
对于单实例,添加以下命令:
VALID_NODE_CHECKING_REGISTRATION_LISTENER=1
对于RAC集群,添加以下命令:
VALID_NODE_CHECKING_REGISTRATION_LISTENER=1 VALID_NODE_CHECKING_REGISTRATION_LISTENER_SCAN1=1 REGISTRATION_INVITED_NODES_LISTENER_SCAN1=(<list of public ip's of all nodes>)
例如,对于拥有两个SCAN监听的RAC环境,先设置如下命令:
VALID_NODE_CHECKING_REGISTRATION_LISTENER=1 VALID_NODE_CHECKING_REGISTRATION_LISTENER_SCAN1=1 REGISTRATION_INVITED_NODES_LISTENER_SCAN1=(192.168.238.190,192.168.238.191) VALID_NODE_CHECKING_REGISTRATION_LISTENER_SCAN2=1 REGISTRATION_INVITED_NODES_LISTENER_SCAN2=(192.168.238.190,192.168.238.191)
最后,重新加载上述配置信息,使之生效,命令如下:
shell> lsnrctl reload shell> lsnrctl reload listener_scan1 shell> lsnrctl reload listener_scan2