
下载掌阅APP,畅读海量书库
立即打开



20世纪90年代,随着数据库系统的广泛应用和网络技术的高速发展,数据库技术也进入一个全新的阶段,即从过去仅管理一些简单数据发展到管理由各种计算机所产生的图形、图像、音频、视频、电子档案、Web页面等多种类型的复杂数据,并且数据量也越来越大。数据库在给我们提供丰富信息的同时,也体现出明显的拥有海量信息的特征。信息爆炸时代,海量信息给人们带来许多负面影响,最主要的就是有效信息难以提炼,过多无用的信息必然会产生信息距离
 和有用知识的丢失。这也就是约翰·内斯伯特(John Nalsbert)所说的“信息丰富而知识贫乏”窘境。因此,人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息,以更好地利用这些数据。但仅以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势,更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生
。
和有用知识的丢失。这也就是约翰·内斯伯特(John Nalsbert)所说的“信息丰富而知识贫乏”窘境。因此,人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息,以更好地利用这些数据。但仅以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势,更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生
。
数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析数据,作出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整策略、减少风险、作出正确的决策①。例如,在对读者的阅读记录等信息进行一定程度的挖掘后,可以掌握用户的阅读行为习惯、学习习惯、阅读爱好等信息,可以帮助用户发现并组织信息,满足其对知识获取的需求,提高信息获取的质量。数据挖掘的对象可以是任何类型的数据源,既可以是关系数据库,此类是包含结构化数据的数据源;也可以是数据仓库、文本、多媒体数据、空间数据、时序数据、Web数据,此类是包含半结构化数据甚至异构性数据的数据源。数据的类型可以是结构化的、半结构化的,甚至是异构型的。在图书馆界,图书馆原生数据主要概括为图书馆业务数据、文献数据和用户数据三大类型。图书馆业务数据是各个业务部门及图书馆人员在日常工作中产生的数据,是工作状态数据,如业务部门的工作日志、每个馆员的业务量。文献数据是简单的结构化数据,包括图书馆历年来所馆藏的各类纸质或数字资源,如馆藏资源产生的书目信息、书目数据库。用户数据是图书馆的用户产生的半结构化数据,如每天读者服务活动所产生的读者流通数据,射频器、传感器感知数据;还有时刻成指数递增的复杂数据,如网站点击数据、电子资源阅读、下载等大数据信息。无论是在数量上,还是类型上,这些途径产生的原生数据极大地丰富了高校图书馆的数据资源。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。数据挖掘利用了来自如下一些领域的思想:①来自统计学的抽样、估计和假设检验;②人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论。数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化计算、信息论、信号处理、可视化和信息检索。一些其他领域也起到重要的支撑作用,特别是需要数据库系统提供有效的存储、索引和查询处理支持。源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。分布式技术也能帮助处理海量数据,并且在数据不能集中到一起处理时更是至关重要。
数据挖掘是数据库中知识发现( Knowledge Discovery in Data base,KDD )不可缺少的一部分。知识发现过程是将未加工的数据转换为有用信息的整个过程,由以下 3 个阶段组成:①数据准备;②数据挖掘;③结果表达和解释。如图 3-1 所示。该过程包括一系列转换步骤,从数据预处理到数据挖掘结果的后处理。输入数据可以是各种形式的数据,如平面文件、电子表格或关系表等,且可以存储在集中式数据库中,或分布在多个数据站点上。数据预处理的目的是将原始输入数据转换为适当的格式,以便进行后续分析。数据预处理涉及的步骤包括融合来自多个数据源的数据,清洗数据以消除噪声和重复的观测值,选择与当前数据挖掘任务相关的记录和特征等。由于收集和存储数据的方式多种多样,数据预处理可能是整个知识发现过程中最费力、最耗时的步骤。后处理通常指将数据挖掘结果集成到决策支持系统的过程,是数据挖掘后期结果表达与解释的重要步骤,能够确保只将那些有效的和有用的结果集成到决策支持系统中。后处理的一个例子是可视化,它使得数据分析者可以从各种不同的视角探查数据和数据挖掘结果。在后处理阶段,还能使用统计度量或假设检验,删除虚假的数据挖掘结果。
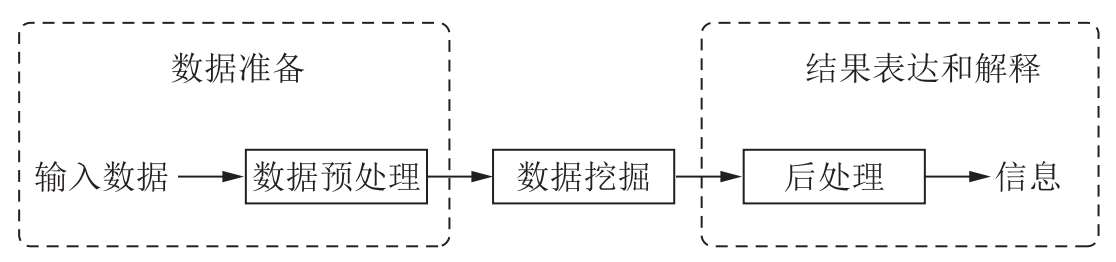
图 3-1 数据挖掘中的知识发现过程
图书馆的数据挖掘是以大数据为基础,借助于大数据技术通过捕捉、挖掘、处理等手段,经过多次深加工而形成的一种知识关联性较高的资源,在传统书刊借阅和虚拟资源检索服务的基础上,拓展高校图书馆新服务。高校图书馆的数据挖掘与分析包括读者利用馆藏文献资源、读者对图书馆空间资源和各种设施的利用、读者到馆情况的统计分析等。通常,图书馆与读者之间存在一道无形的隔阂,图书馆很难了解读者行为的背后含义,读者也不清楚图书馆除了查找资料外还提供何种服务。大数据时代的图书馆,打破图书馆与读者之间的隔阂,通过高速捕捉、深度挖掘和组织分析,从大容量、多类型的数据中获取有价值的、潜在的信息,为本校读者主动提供专业化的、个性化的数据服务
。如“通过对读者借阅书刊的数据进行挖掘分析,优化馆藏发布,为读者提供有特色的个性化服务”。
通过对高校图书馆的借阅情况、使用日志等进行数据挖掘与分析,能够为图书馆馆藏发展、藏书布局、流通借阅规则设置、服务人员配置提供参考,为读者提供更好的服务,更好地满足读者的需求。同时,利用数据挖掘与分析能够展示读者的阅读倾向,为读者的阅读选择及图书馆决策支持提供有价值的参考。本章将以华东师范大学图书馆的馆内资源利用数据挖掘为例,介绍数据挖掘在高校图书馆的利用与实现。
华东师范大学图书馆是国家教育部直属重点大学图书馆,创建于 1951 年 10 月,现由闵行校区图书馆和中山北路校区图书馆所组成。图书馆拥有丰富的馆藏资源,包括古今中外各类印刷型文献和数字文献。馆藏文献的学科范围涵盖人文科学、社会科学、自然科学与应用技术等学科领域,尤以教育学、地理学、文史哲等学校重点学科领域的文献见长,为教学与科研提供了较为完备的文献信息保障,逐渐形成综合性、研究型大学图书馆馆藏特色。从 1999 年起,图书馆启用 INNOPAC 自动化集成管理系统(以下简称“自动化系统”),并逐步升级图书馆服务器,扩容图书馆局域网,通过校园网实现两个校区的网络连接和集中式管理。以下章节中所用数据主要来自图书馆自动化系统中的读者记录、书目记录、馆藏记录、流通日志、馆藏统计报告、流通活动报表等,以及电子阅览室上机日志、研究室管理系统日志、自助文印系统日志、图书馆通道机日志、微信刷卡日志等。