
下载掌阅APP,畅读海量书库
立即打开



推荐算法是整个推荐系统的核心部分,直接影响到推荐结果的准确性。一直以来,推荐算法受到大多数研究者的关注。现在应用到推荐系统中的算法有很多,本节主要介绍受研究者关注较多的几种算法。
基于人口统计学的推荐机制(Demographic-based Recommendation)是推荐算法中最容易实现的一种推荐方法。它的主要思想是根据用户提供的个人基本信息,包括性别、年龄等人口统计学信息,计算用户间的相关程度,据此确定最相似用户(相似用户是指两个用户间在性别、年龄等属性信息上相同或相差不远),然后将相似用户(也可以说成是“邻居用户”)喜爱的物品推荐给当前用户。基于人口统计学的推荐原理如表2-1所示。
表 2-1 基于人口统计学的推荐
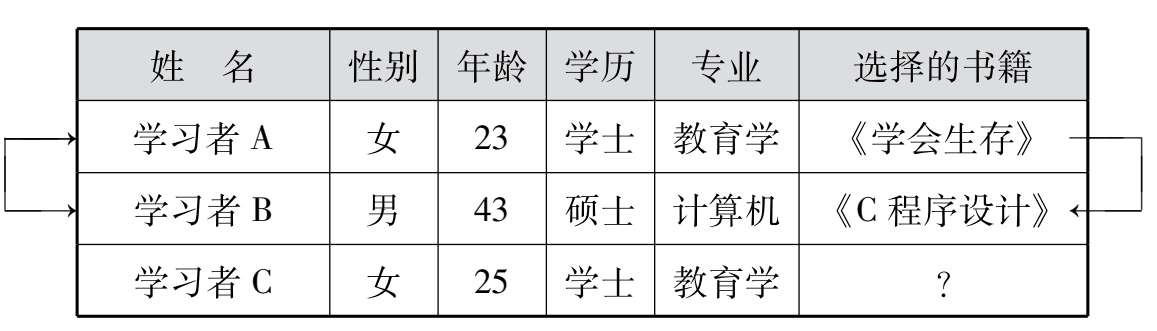
系统会给学习者C推荐什么书籍呢?根据基于人口统计学推荐的原理,首先系统计算学习者C与学习者A、B之间的相似程度。计算机发现在性别、年龄、学历以及专业等4个维度上,学习者C与学习者A更相似,学习者A是学习者C的“邻居”,系统就会将学习者A选择的书籍《学会生存》推荐给学习者C。
基于内容的推荐方法的主要思想是计算物品间的相似性,根据用户之前的选择,将与用户之前选择的物品最相似的推荐给用户。例如,在电子商务中,如果用户之前买了科幻小说,那么推荐系统会将新上架的科幻小说推荐给用户。图2-2给出了基于内容推荐的基本原理。
图2-2中给出的是基于内容推荐中的一个非常典型的例子,首先我们需要对学习资源的元数据有一个建模,这里只简单地描述一下学习资源的类型;然后通过学习资源的元数据发现资源间的相似度,因为类型都是“视频、英语”,学习资源A和C被认为是相似的学习资源;对于学习者A,他喜欢学习资源A,那么系统就可以给他推荐类似的学习资源C;同理对于学习者B,系统向他推荐学习资源D。
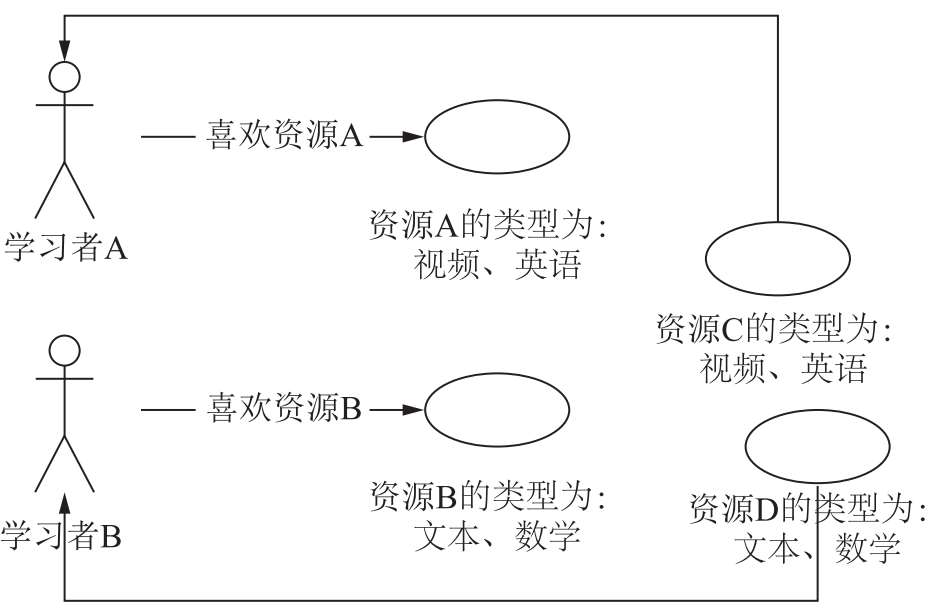
图 2-2 基于内容推荐机制的基本原理
不管是基于人口统计学的推荐还是基于内容的推荐,其优点是推荐方法简单、方便,缺点是推荐方法略显粗糙,结果可能不是很准确。
基于协同过滤的推荐得益于Web2.0 的出现,协同过滤推荐需要用户参与。基于协同过滤推荐机制的原理比较简单。首先,它需要存储用户对物品或者信息的历史偏好信息,然后通过历史偏好数据发现物品或者是用户间的相关性,最后基于关联性,推荐系统推荐相似物品。在基于协同过滤的推荐中,基于用户的推荐(User-based Recommendation)和基于项目的推荐(Itembased Recommendation)是最为常用的两种推荐方法。下面我们详细地介绍这两种协同过滤的推荐机制。
(1)基于用户的协同过滤推荐
基于用户的协同过滤推荐主要是根据用户对物品的偏好信息发现相似用户,但是如何发现相似用户呢?一般的做法是采用“K-邻居”的算法算出最近的K个邻居,即根据用户的历史偏好信息,发现与指定用户最相近的K个邻居,发现了K个邻居后,就可以将这K个邻居的历史偏好信息推荐给指定的用户。
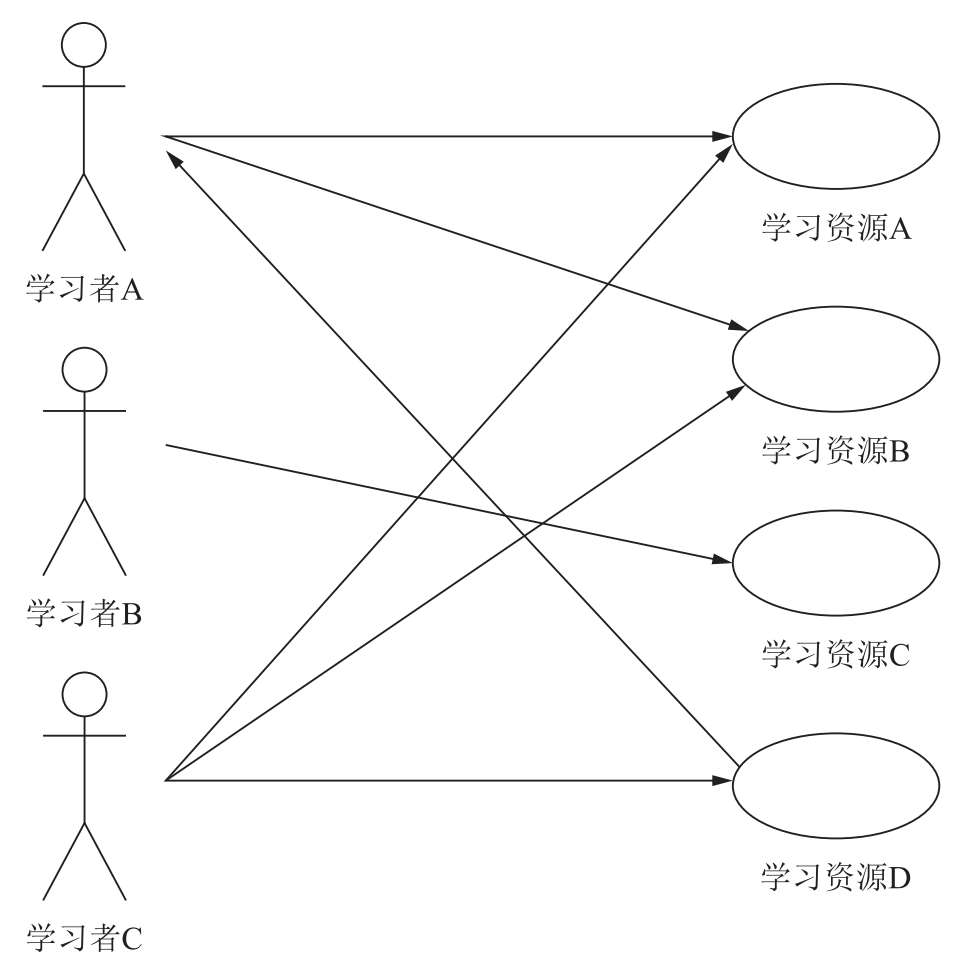
图 2-3 基于用户的协同过滤推荐机制的基本原理
图2-3给出了基于用户的协同过滤推荐机制的基本原理:假设学习者A喜欢学习资源A和学习资源B,学习者B喜欢学习资源C,学习者C喜欢学习资源A、学习资源B和学习资源D;从这些用户的历史喜好信息中,我们可以发现学习者A和学习者C的口味和偏好是比较类似的,因为学习者C还喜欢学习资源D,那么我们可以推断学习者A可能也喜欢学习资源D,因此可以将学习资源D推荐给学习者A。
通过对比基于用户的协同过滤推荐机制和基于人口统计学的推荐机制,我们发现,其实两者的原理是一样的,都是根据历史信息计算用户间的相似度,找到邻居用户,然后基于“邻居”用户进行推荐。但是两者也有不同点,那就是计算用户的相似度时所选取的数据不同:基于人口统计学的机制在计算用户间相似度时所选取的数据是用户属性信息,这种数据一般是静态的;基于用户的协同过滤机制所选取的数据是用户的历史偏好数据,即用户对物品的操作数据或者评价数据,这种数据是动态的。
(2)基于项目的协同过滤推荐
基于项目的协同过滤推荐的原理和基于用户的协同过滤推荐的原理非常相似,两者都需要用户对资源的历史偏好信息。但是,前者是根据历史数据,发现资源与资源之间的相似度,将类似的学习资源推荐给用户。图2-4给出了基本原理。
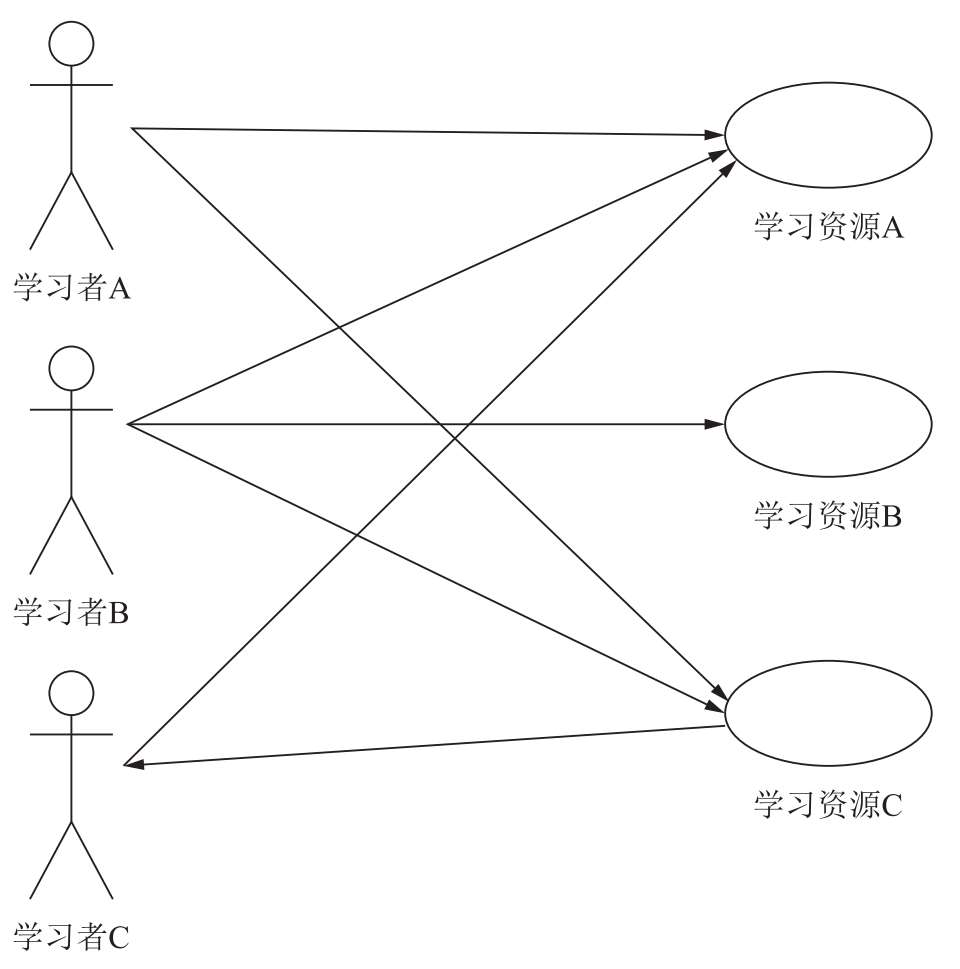
图 2-4 基于项目的协同过滤推荐机制的基本原理
图2-4给出的是基于项目的协同过滤推荐机制的基本原理:假设学习者A喜欢学习资源A和C,学习者B喜欢学习资源A、B和C,学习者C喜欢学习资源A,从这些用户的历史喜好可以分析出,喜欢学习资源A的人都喜欢学习资源C,学习资源A和C是比较类似的,基于这个数据可以推断学习者C很有可能也喜欢学习资源C,所以系统会将学习资源C推荐给学习者C。
通过对比基于项目的协同过滤推荐机制和基于内容的推荐机制,我们发现,其实两者的原理是一样的:两者都是基于物品间的相似程度进行推荐,只是相似度计算时所选取的历史数据不一样。基于项目的协同过滤推荐机制计算用户间的相似度时所选取的是用户的历史偏好推断,这种数据是动态的;而基于内容的推荐机制是基于物品本身的属性特征信息,这种数据一般是静态的。
(3)基于协同过滤推荐的优缺点
在现在的电子商务领域,基于协同过滤的推荐机制的应用是最为广泛的,因为它有显著的优点,当然它还有其自身的缺点。具体来说,它最主要的优点如下所述。
基于协同过滤的推荐机制比较简单,它需要的只是用户的评分数据或者是类似于评分数据,一般来说它不需要专业领域的知识,也不需要严格的建模。只要有相关的数据即可直接使用此推荐算法;并且,基于协同过滤的推荐的结果比基于人口统计学、基于内容的推荐的结果更准确一些。
当然,基于协同过滤的推荐机制也有其固有的缺点。
首先,基于协同过滤的推荐方法会出现“冷启动”的问题,因为该推荐算法需要历史偏好数据,因此,当新物品和新用户出现在系统内时,没有历史数据,算法将无法运算,导致新物品永远不会推荐给用户,而新用户也不会有最近的邻居用户;其次,也是因为基于协同过滤的推荐方法对于历史数据的依赖性,使得如果历史数据很少时,该推荐算法的准确性就会不够高;还有,在现实中,确实存在一部分特殊的用户,他们对于物品的喜好和其他任何人都是不同的,因此推荐算法是无法根据其偏好信息发现相似用户的;最后,当用户兴趣发生改变时,基于协同过滤的推荐方法依然依据历史偏好数据产生推荐结果,这样的推荐是不能随用户兴趣的改变而随之变化的。
从上面的介绍中可以看出不同的推荐算法都是各有利弊的。现在的电子商务网站中采取的策略是组合推荐算法,取长补短,这样既能避免“冷启动”问题,又能提高推荐结果的准确性。关于如何组合各个推荐机制,目前较为常用的组合方法有以下几种。
混合推荐结果,就是在一开始用不同的推荐机制各自计算得到不同的推荐结果作为中间结果,然后采取某种算法,将中间结果混合成最终的结果。
混合推荐方法,直接产生最终结果,而不会产生中间结果。它是在最开始分析系统,比较各种推荐机制准确性,选择一种推荐机制作为系统的主要推荐机制,然后再混合其他推荐方法,最终使混合后的推荐算法可以一次性得到推荐结果。