
下载掌阅APP,畅读海量书库
立即打开



在更详细地讨论感知器及其相关算法之前,让我们先简要地回顾机器学习的早期历史。为了设计人工智能,人们试图了解生物大脑的工作原理。Warren McCulloch和Walter Pitts于1943年首先发表了一篇论文,提出简化脑细胞的概念,即所谓的 McCulloch-Pitts (MCP)神经元 [1] 。生物神经元是大脑中那些联结起来参与化学和电信号处理与传输的神经细胞,如图2-1所示。
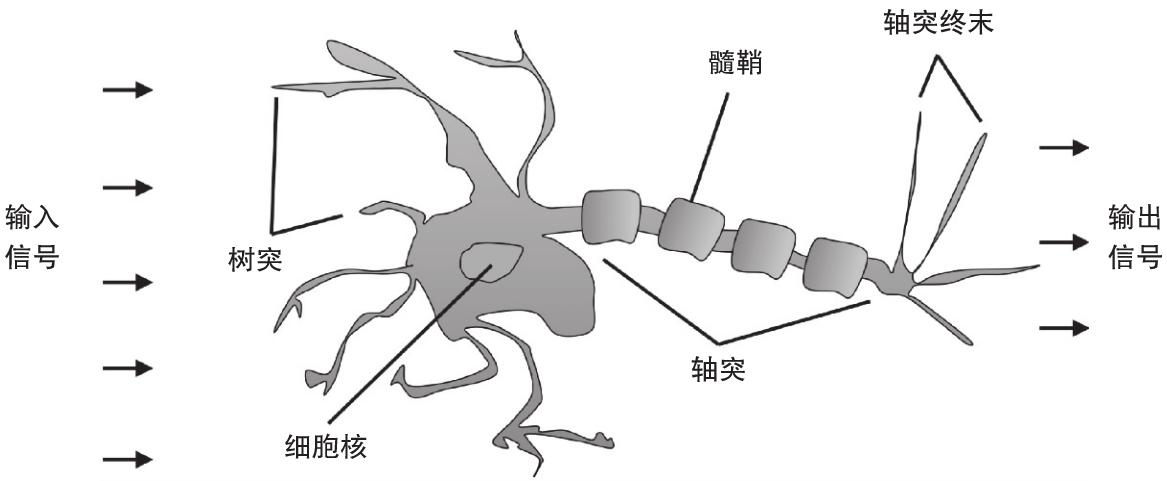
图 2-1
麦库洛和皮兹把神经细胞描述为带有二元输出的简单逻辑门。多个信号到达树突,然后整合到细胞体,并当累计信号量超过一定阈值时,输出信号将通过轴突。
在论文发表之后仅几年,Frank Rosenblatt就基于MCP神经元模型首先提出了感知器学习规则的概念 [2] 。根据其感知器规则,Rosenblatt提出了一个算法,它能先自动学习最优的权重系数,再乘以输入特征,继而做出神经元是否触发的决策。在监督学习和分类的场景下,这样的算法可以用来预测新数据点的类别归属。
更准确地说,可以把人工神经元逻辑放在二元分类的场景,为简化操作,我们将这两个类分别命名为1(正类)和-1(负类)。然后定义决策函数(ϕ(z)),该函数接受特定输入值 x 的线性组合及其相应的权重向量 w ,两者计算的结果z为所谓的净输入z=w 1 x 1 +w 2 x 2 +…+w m x m :
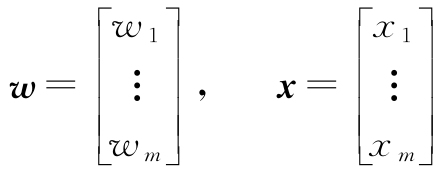
如果某个特定样本的净输入值 x (i) 大于定义的阈值θ,则预测结果为1,否则为-1。在感知器算法中,决策函数ϕ(·)是单位阶跃函数的一个变体:

为了简化起见,我们把阈值θ放在等式的左边,权重零定义为w 0 =-θ,x 0 =1,这样就可以用更紧凑的方式来表达z:
z=w 0 x 0 +w 1 x 1 +…+w m x m = w T x
和

在机器学习文献中,我们通常把负的阈值或权重w 0 =-θ称为 偏置 。

本书后续部分将经常用到线性代数的基本表达方法。例如,用向量点积的方法表示 x 和 w 的值相乘后再累加的结果,上标T表示转置,该操作将列向量转换为行向量,反之亦然:
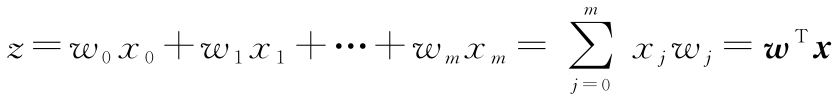
例如:
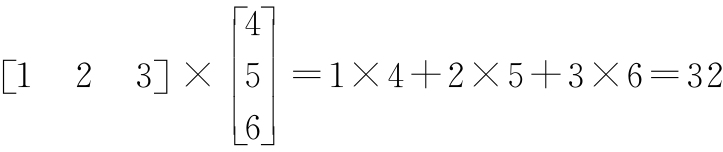
转置操作也可以从矩阵的对角线上反映出来,例如:
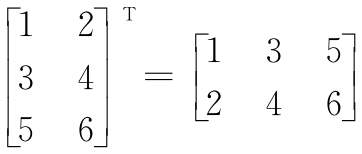
请注意,转置操作只严格定义在矩阵上。然而,在机器学习中,向量一词通常指n×1或者1×m矩阵。
本书仅涉及非常基本的线性代数概念,然而,如果需要做个快速回顾,可以看下Zico Kolter的Linear Algebra Review and Reference,该书可以从http://www.cs.cmu.edu/~zkolter/course/linalg/linalg_notes.pdf免费获得。
图2-2阐释了如何通过感知器的决策函数把净输入z= w T x (左图)转换为二元输出(-1或者1),以及如何区分两个可分隔的线性类(右图)。
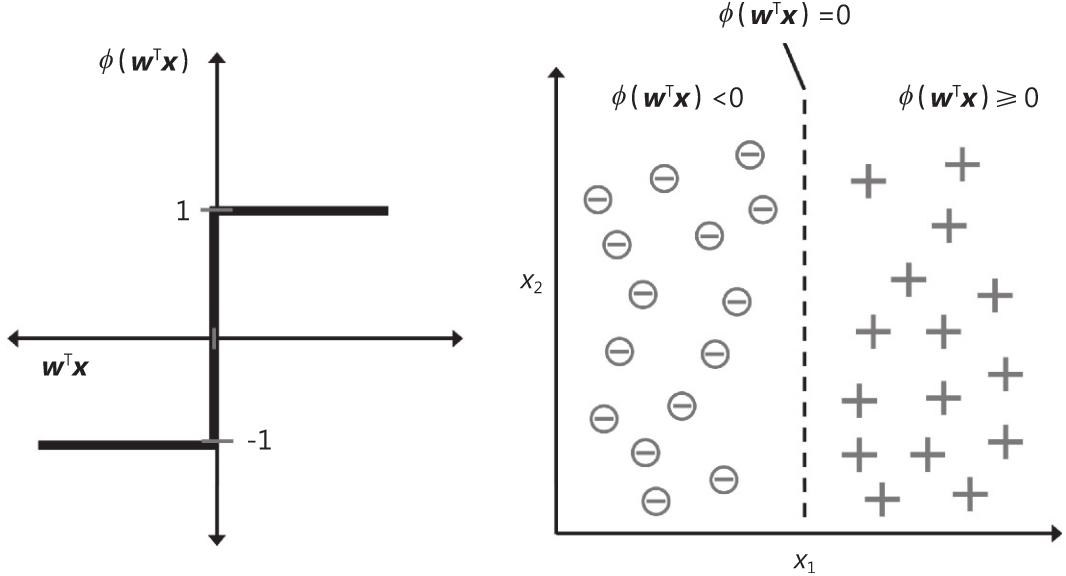
图 2-2
MCP神经元和Rosenblatt 阈值 感知器模型背后的逻辑是,用还原论方法来模拟大脑神经元的工作情况:要么 触发 ,要么不触发。因此,罗森布拉特的初始感知器规则相当简单,其感知器算法可以总结为以下几个步骤:
1)把权重初始化为0或者小的随机数。
2)分别对每个训练样本 x (i) :
a. 计算输出值
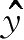 。
。
b. 更新权重。
输出值为预先定义好的单位阶跃函数预测的分类标签,同时更新权重向量 w 的每个值w j ,更准确的表达式为:
w j :=w j +Δw j
其中,Δw j 是用来更新w j 的值,根据感知器学习规则计算该值如下:
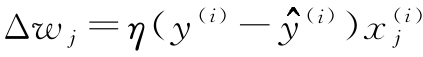
其中η为学习速率(一般是0.0~1.0之间的常数),y
(i)
为第i个训练样本的正确类标签,
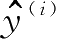 为预测的分类标签。需要注意的是,权重向量中的所有值将同时被更新,这意味着在所有权重通过对应更新值Δw
j
更新之前,不会重新计算
为预测的分类标签。需要注意的是,权重向量中的所有值将同时被更新,这意味着在所有权重通过对应更新值Δw
j
更新之前,不会重新计算
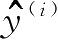 。具体来说,二维数据集的更新可以表达为:
。具体来说,二维数据集的更新可以表达为:
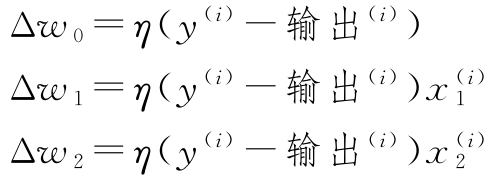
在用Python实现感知器规则之前,让我们先做个简单的思考实验来说明该学习规则到底有多么简单。在感知器正确预测两类标签的情况下,保持权重不变,因为更新值为0:
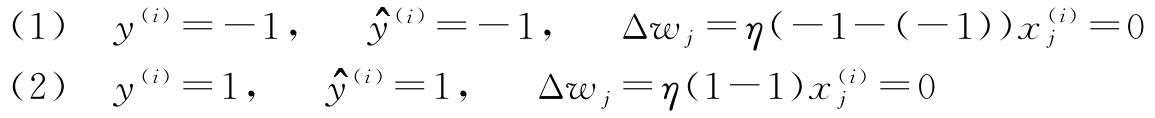
然而,如果预测有误,则权重应偏向阳或阴的目标类:
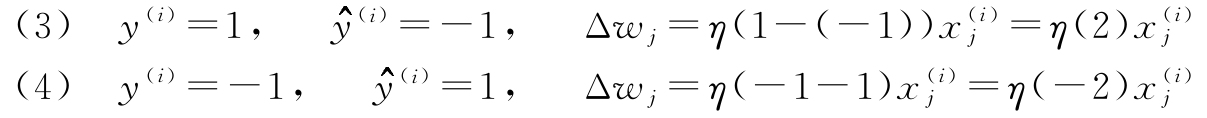
为了能更好地理解乘积因子
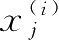 ,让我们再来看下另外一个简单的示例,其中:
,让我们再来看下另外一个简单的示例,其中:
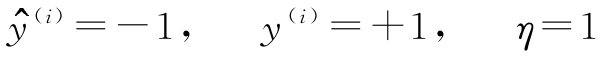
假设
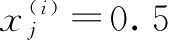 ,模型错把该样本判断为-1。在这种情况下,把相应的权重增加1,这样当下次再遇到该样本时,净输入
,模型错把该样本判断为-1。在这种情况下,把相应的权重增加1,这样当下次再遇到该样本时,净输入
 就会更偏向阳,从而更有可能超过单位阶跃函数的阈值,把该样本分类为+1:
就会更偏向阳,从而更有可能超过单位阶跃函数的阈值,把该样本分类为+1:
Δw j =(1-(-1))0.5=(2)0.5=1
权重更新与
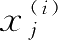 成正比。例如,假设有另外一个样本
成正比。例如,假设有另外一个样本
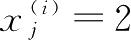 被错误地分类为-1,可以将决策边界推到更大,以确保下一次分类正确:
被错误地分类为-1,可以将决策边界推到更大,以确保下一次分类正确:
Δw j =(1 (i) -(-1) (i) )2 (i) =(2)2 (i) =4
重要的是,我们要注意只有两个类线性可分且学习速率足够小时,感知器的收敛性才能得到保证(感兴趣的读者可以在我的讲义找到数学证明,地址为:https://sebastianraschka.com/pdf/lecture-notes/stat479ss19/L03_perceptron_slides.pdf.)。如果不能用线性决策边界分离两个类,可以为训练数据集设置最大通过数(迭代次数)及容忍误分类的阈值,否则分类感知器将会永不停止地更新权重,如图2-3所示。
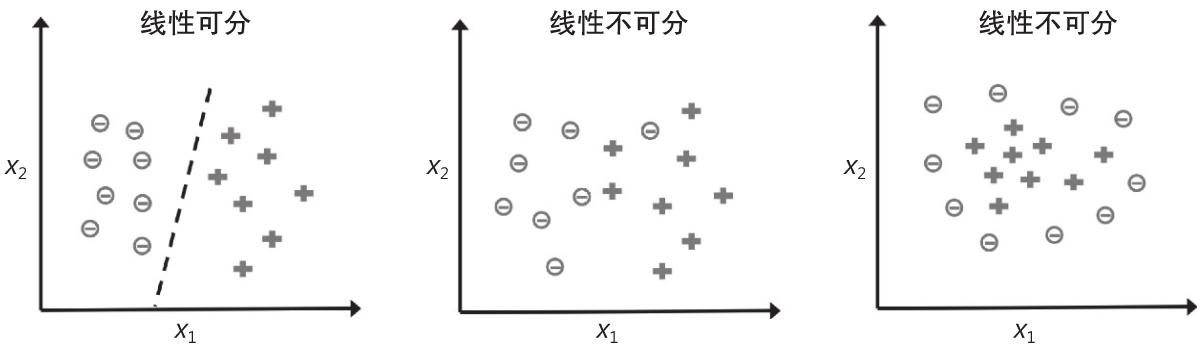
图 2-3
可以直接从华章网站或下述网站下载示例代码:
https://github.com/rasbt/python-machine-learning-book-3rd-edition
在开始进入下一节进行实现之前,让我们先把刚所学到的知识用一个简单的图做个总结,以此说明感知器的一般概念,如图2-4所示。
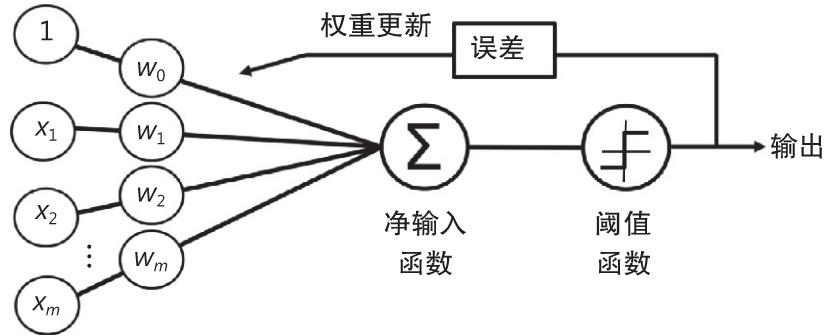
图 2-4
图2-4说明了感知器如何接收输入样本 x ,并将其与权重 w 结合以计算净输入。然后再把净输入传递给阈值函数,产生一个二元输出-1或+1,即预测的样本分类标签。在学习阶段,该输出用于计算预测结果的误差并更新权重。