
下载掌阅APP,畅读海量书库
立即打开




下面以监督学习为例,机器学习的一般流程如图3-6所示,由训练阶段和测试阶段两部分构成。
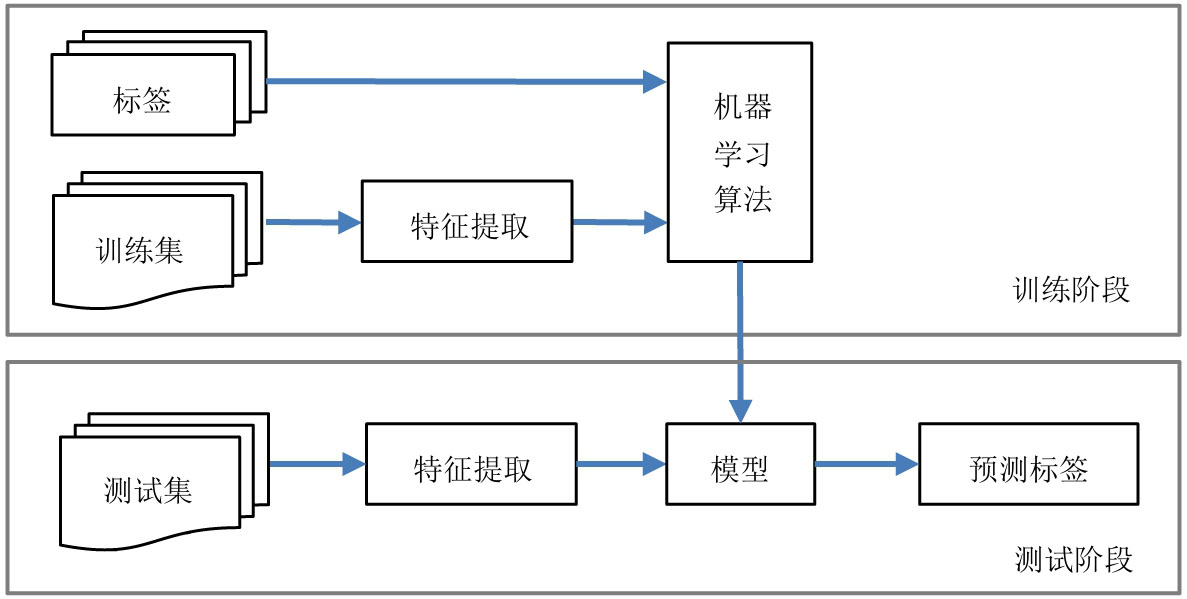
图3-6 机器学习的一般流程
训练阶段:使用带标签的训练集,在提取特征后,经机器学习算法对数据进行学习从而得到模型。
测试阶段:对标签未知的测试数据,通过同一种特征提取手段提取特征之后,把它们送入训练好的模型,预测数据的标签。
在图3-6所示的流程中,我们需要做的工作如下:
(1)制作数据集。收集数据并进行预处理与标注,制作成数据集,再将其分为训练集与测试集。通常还会将训练集再进一步划分为训练集与验证集,具体内容在3.2.2节介绍。
(2)选择或设计特征提取算法。原始的图像数据是二维(灰度图像)或三维(彩色图像)矩阵,数据量非常大,需要采用合适的方式对图像中的关键信息进行表征,让图像数据变成更加容易解析的形式,这个过程就是特征提取。对于不同的图像处理任务,应有针对性地选择或设计特征。例如,OpenCV提供的方向梯度直方图(Histogram of Oriented Gradient,HOG)特征可对行人和非行人进行分类,而HAAR-like特征可用于人脸检测等。上述两种特征提取算法均属于人工设计的特征提取算法,当然还可以使用深度学习自动提取特征,这有助于提取更加深层而本质的特征,从而提高学习算法的性能。显然,训练与测试应使用同样的特征提取算法。
(3)选择机器学习算法。根据机器学习任务的类型,选择某类机器学习算法,并对训练集进行训练,从而得到模型。例如,对于手写数字分类任务,我们可以选择用于分类的机器学习算法,如支持向量机(Support Vector Machine,SVM)、 K 近邻( K NN)、人工神经网络(Artificial Neural Networks,ANN)、决策树(Decision Trees)、随机森林(Random Trees)等,我们将在后续章节具体介绍这些机器学习算法的使用方法。
(4)测试。将同样格式的测试集数据输入训练好的模型,返回预测结果。这一步通常使用批处理的方式进行,可以得到使用模型预测未知数据的准确率。
数据是机器学习系统的核心。在手写数字识别的经典示例中,采用的是MNIST数据集。该数据集包含了70000幅手写数字图像,每幅图像都是28×28像素的灰度图像,内容是0~9这十个手写数字。同时,数据集中的每幅图像都包含了标注信息,即该图像中的数字,如图3-1所示。
在实际训练与测试时,数据集的使用和划分还有一些值得注意的事项,后面将重点介绍。
1. 训练集与测试集
在监督学习问题中(例如手写数字识别问题),一个关键问题是:即使我们知道判断模型准确性的方法,但如何确保该模型能够很好地适应未知的新数据呢?我们可以用各种方式测量模型的性能,如精度(Accuracy)、误差(Error)、ROC曲线和AUC等指标。为了便于讨论,假设使用精度测量模型的性能,即:
精度=预测正确的数量/总预测次数
一个自然解决方案是将总样本数据分成两组,即一组训练集(Training set)和一组测试集(Test set)。训练集用于创建模型(即训练)。由于这样训练出来的模型没有见过测试数据,且我们已经知道测试集的标签(即正确答案),所以可以在测试集上测试模型的精度,并且在很大程度上可以认为模型在未来的输入数据上会大致获得相似的精度。我们在得出这个结论时,做出的一个重要假设是训练集和测试集也代表了未来的数据。
在MNIST数据集中共包含了60000幅图像的训练集和10000幅图像的测试集。
2. 验证集
大多数建模技术都有参数。例如,在决策树中,我们可以选择生成完整的树,其中包含输入变量和这些组合中每个组合结果的所有组合。假设决策树有20个级别,这时模型不仅变得极其复杂,而且极有可能出现对训练集数据的过拟合。如果在这种情况下计算训练集上预测的准确性,将获得极高的准确度,但该模型可能在测试集上表现不佳。为了提高模型的泛化能力,可以不考虑完整的树,而是只采用前5个级别、前7个级别或前10个级别,此时级别就是模型参数。
现在最重要的问题是如何知道哪个级别是最好的推广模型,即使在看不见的数据上也能表现最佳。我们应该使用2级、3级、15级或20级吗?最简单的解决方案是创建每个可能级别的模型,并在测试集上对这些模型分别进行测试,找到准确率最高的模型,选择模型的参数,获得最佳精度。
上述方法存在一个重大缺陷,即当通过测试集确定参数时,会无意中在确定模型时暴露测试数据。这意味着测试数据不再是模型的新数据,因此根据此测试数据计算的准确率可能无法代表未来未知数据的准确率。
解决此问题的方法是将样本数据分为3部分:
◎ 训练集。
◎ 验证集。
◎ 测试集。
训练集将像之前一样使用,但不是使用测试集来确定模型参数的,而是使用验证集来确定模型参数。测试集仅用作输入数据,并且仅用于近似获得现实世界中模型的准确率。
通常,可以使用以下两种方法中的任何一种获得验证集。
1)Holdout(又称HoldBack)
这是一种非常简单的创建验证集的方法。我们所做的是简单地阻止一小部分训练数据,比如大约10%,并使用其余的训练数据训练模型。该方法的问题之一是它对数据划分方式较为敏感。Holdout验证集中产生的任何随机偏差都可能对模型产生不利影响。
2) k 折叠交叉验证( k -Fold Cross Validation)
交叉验证是一种在有限样本条件下,在训练阶段评估机器学习模型对未知数据的预测能力的方法。当然,也可以通过交叉验证方法选择模型参数,即选择在交叉验证中平均预测性能最佳的模型。这种方法在机器学习任务中十分常用,因为它简单易行,且效果通常好于只对训练集做一次切分的方法(如Holdout)。
如图3-7所示, k 折叠交叉验证的一般步骤如下。
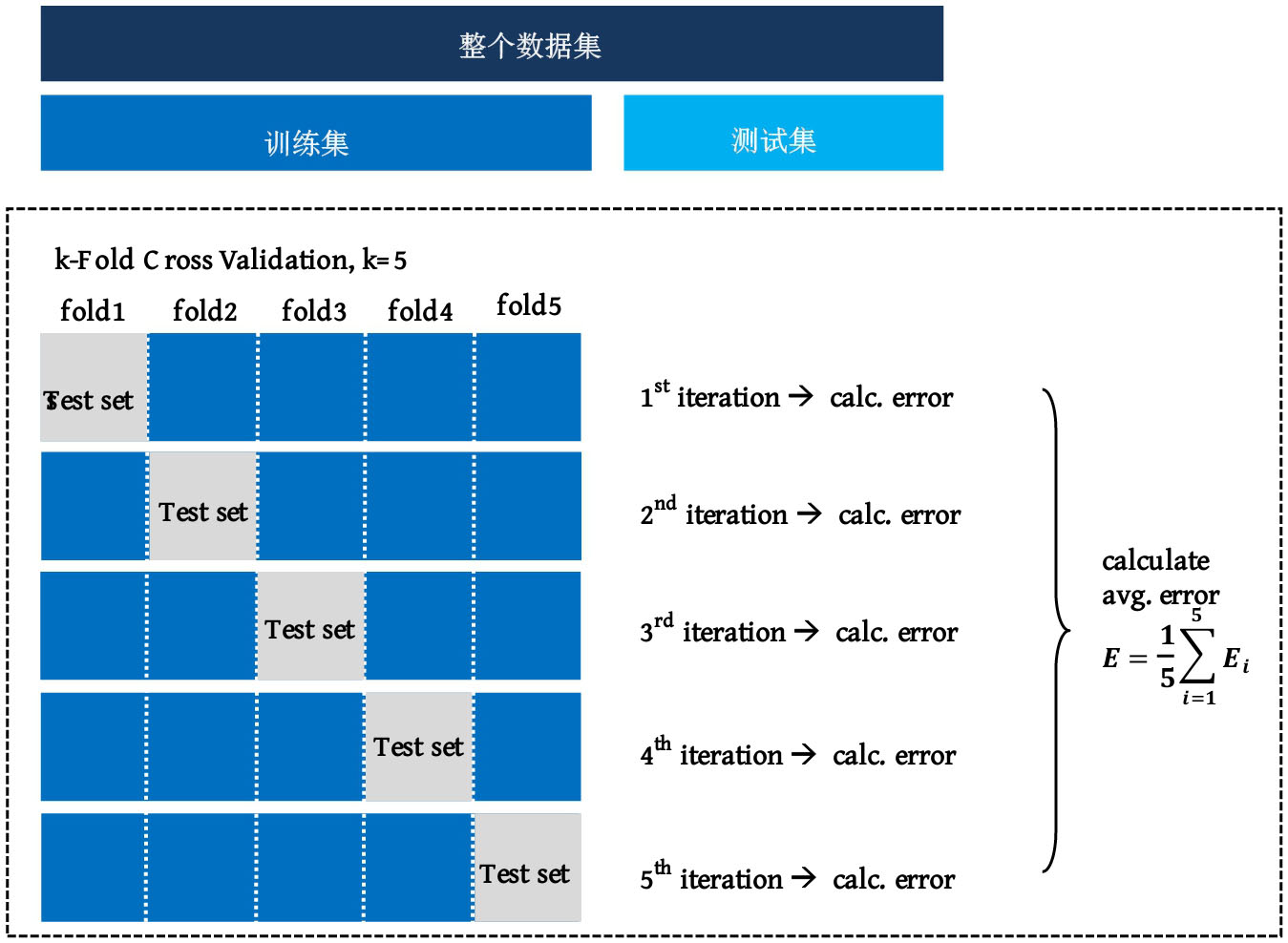
图3-7 k 折叠交叉验证的一般步骤
第1步,将整个数据集分为训练集(Training dataset)和测试集(Test dataset)。
第2步,随机打乱训练集。
第3步,将训练集平均拆分为 k 个组。
第4步,对于 k 个组中的每一组:
◎ 将该组作为验证集;
◎ 将剩余的 k -1个组合并为训练集;
◎ 在训练集上拟合模型,并在验证集上进行评估;
◎ 保留评估分数并丢弃模型。
第5步,使用评估分数样本,总结模型的性能。
参数 k 的选择非常重要,因为在 k 折叠交叉验证中存在与 k 选择相关的偏差—方差权衡。通常使用 k =5或 k =10执行 k 折叠交叉验证,因为经验显示,通过5折或10折交叉验证得到的模型性能,既不受过高偏差影响,也不受过高方差影响。
3. Bootstrapping验证方法
前文分析过,训练集和验证集的测试结果并不能精确地反映对真实数据的测试结果。为了更准确地评估模型性能,可以采用交叉验证。除此之外,还有一种与交叉验证相近的方法,称为Bootstrapping验证方法。
Bootstrapping验证方法与交叉验证类似,但是验证集是从训练集中随机选取的。选取的数据仅用于测试,不在训练中使用。这样做 N 次,每次随机选择一些验证集,最后把得到的结果平均。这意味着一些数据样本会出现在不同的验证集中,Bootstrapping验证方法的效果一般要好于交叉验证。
1. 偏差与方差的概念
偏差与方差是解决机器学习问题必须掌握的概念。图3-8是不同参数(此处为多项式拟合的阶数)的模型对含噪声观测的 y =sin( x )函数数据集的学习结果。好的参数能让模型“恰到好处”(good fitting)地拟合带噪声的训练数据,比较客观地反映数据背后的规律,如图3-8(a)中实线所示。而不合适的参数有可能让模型遇到高偏差或者高方差。高偏差会造成模型对数据欠拟合(under fitting),高方差会造成模型对数据过拟合(over fitting),如图3-8(b)所示,点画线为3阶拟合结果,实线为28阶拟合结果,显然两者都不是我们所希望看到的。
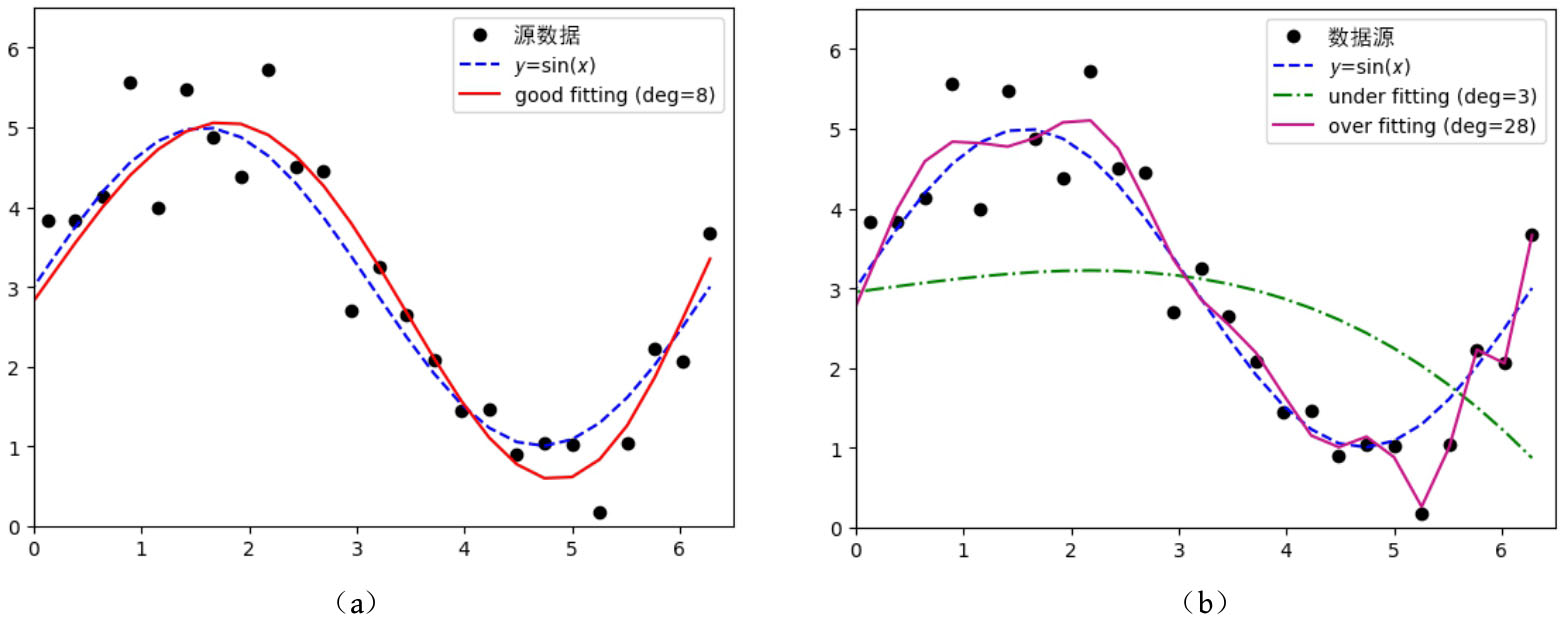
图3-8 不同参数的模型对含噪声数据的拟合
出现高偏差与高方差的主要原因是:简单的模型可能会因为缺乏灵活性而无法刻画复杂规律,从而出现高偏差,影响精度;复杂的模型会对训练数据有过拟合的风险,因为训练数据中的噪声会让复杂的模型出现高方差,这也将影响精度。显然上述两种模型之间存在权衡,关键是在哪里权衡,以及何时应用哪种类型的模型。
正确地判断模型是否存在高偏差或者高方差可有的放矢地改进模型,进而提高模型的泛化能力。交叉验证得到的模型性能更接近模型对未知数据的测试性能。通常用误差来衡量模型的性能,下面就使用交叉验证误差与训练误差来观察模型的性能曲线。如图3-9所示,横坐标为模型复杂度,纵坐标为错误率。可以通过训练集与验证集的误差曲线来判断是否出现了高偏差或高方差。当训练集和验证集误差都较高时,为高偏差;当训练集误差很低,而验证集误差很高时,为高方差。
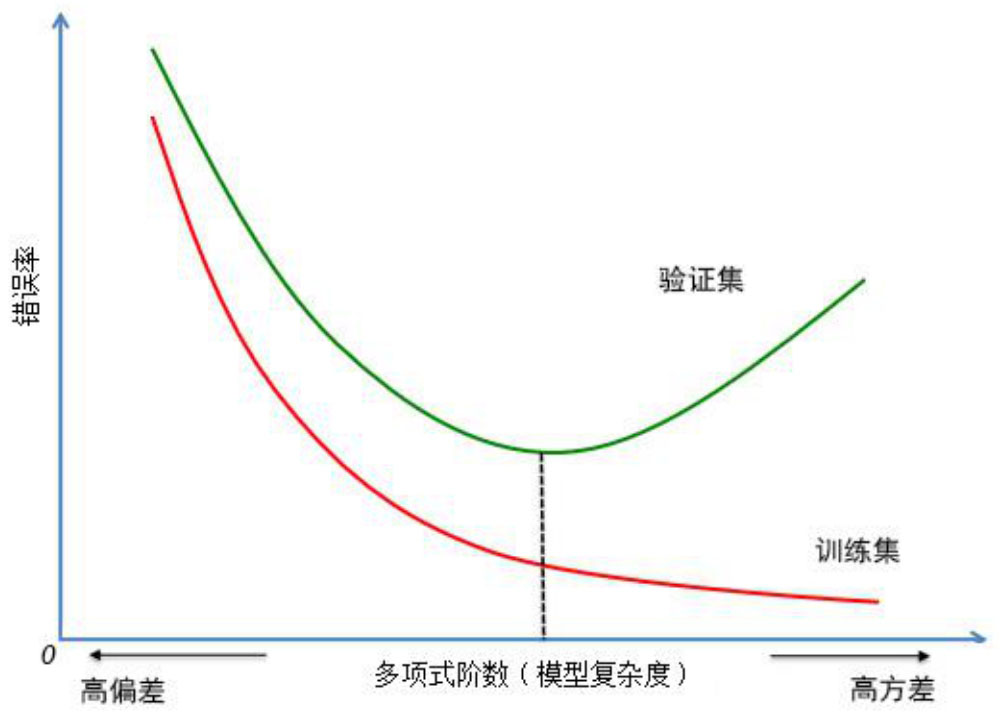
图3-9 高偏差与高方差的判断
下面以分辨图片中的动物是不是猫的二分类问题予以说明。假设训练集误差是15%,验证集误差是16%,而在此案例中人的错误率几乎为0,即人们在浏览图片时总是能正确地分辨出图片中的动物是不是猫。由于训练集误差和验证集误差都偏高,所以可以判断这个模型的偏差较高,但是,它对于验证集产生的结果却是合理的,因为验证集误差只比训练集的多了1%。
2. 偏差—方差困境
对于监督学习而言,一个必须考虑的问题是偏差—方差困境,即如何使机器学习模型在不同的数据集上都保持较高的准确率,我们希望模型在验证集上的误差尽可能小。从图3-9中可见,当模型复杂度低于某临界点时会出现高偏差,导致验证集误差增大;当模型复杂度提高之后,对训练集的刻画能力也会提高,所以在训练集的误差会越来越小,但是当复杂度超过某临界点时,会出现高方差,此时验证集误差会迅速增大。因此,模型复杂程度既不是越高越好,也不是越低越好,而是有一个权衡,这就是偏差—方差权衡。
了解这些可能存在的基本问题有助于我们分析模型的表现,并且有针对性地对性能进行改善。
在评估和调整分类器性能的方法中有两种比较有效的方法,分别是ROC曲线和混淆矩阵,下面简单介绍这两种方法。
1. ROC曲线
ROC与混淆矩阵如图3-10所示。其中,ROC(Receiver Operating Characteristic)曲线描述的是分类模型的性能参数对分类模型性能的影响,显示的是分类模型参数在所有取值范围内变化时,正确识别率和错误识别率的关系。假设分类模型用于识别图像中的黄色,并且我们在黄色上设置了一个阈值作为参数。如果将黄色阈值设置得非常高,则意味着分类模型将无法识别任何黄色,产生虚警率(False Positive Rate,FPR)为0,真正率(True Positive Rate,TPR)同样为0的情况,对应图3-10中曲线的左下角部分。如果黄色阈值设置为0,则任何信号都能被识别成黄色。这意味着所有真正的黄色都能被识别,即TPR=100%,但由于阈值为0,所以所有橙色和红色等也都被识别为黄色。因此,此时的FPR=100%。这种情况对应图3-10中曲线的右上角部分。好的ROC曲线应该是跟随 y 轴达到100%,之后水平切割到右上角的曲线。如果做不到这样,则曲线越接近左上角越好。实际上,人们通常会计算ROC曲线下方的面积和整个ROC的总面积之比,该比率越接近1,分类模型越好。
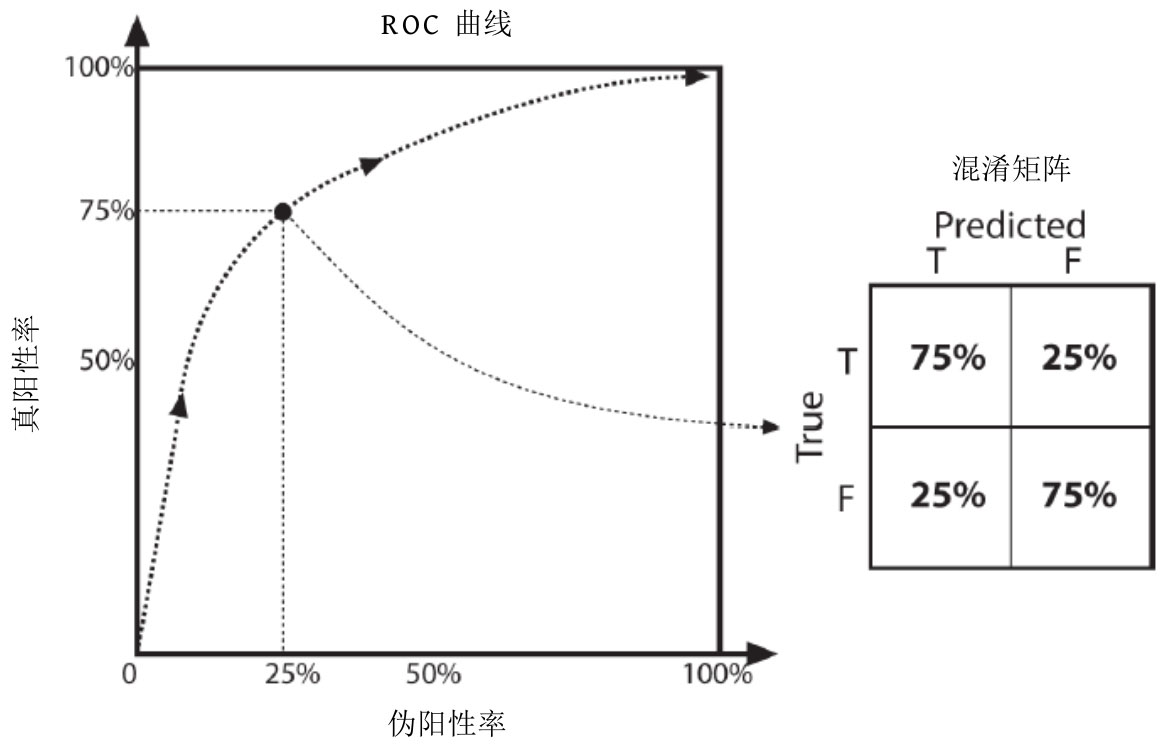
图3-10 ROC曲线与混淆矩阵
2. 混淆矩阵
图3-10右侧显示了一个混淆矩阵。它是一个包含错误识别率、正确识别率、错误拒绝率和正确拒绝率的图。它是评估分类模型性能的另一种快速方法:理想情况下,我们在左上—右下对角线上看到100%,在其他地方看到0%。如果是一个可以识别多个类的分类模型(例如,多层感知器或随机森林,它们可以同时学习许多不同的类标签),那么混淆矩阵将被推广到涵盖所有类标签,并且条目代表所有类别标签上的真假阳性和阴性的总体百分比。多个类的ROC曲线只记录测试数据集的真假决策。