
下载掌阅APP,畅读海量书库
立即打开




1.3.1.1.1 向量结构
进入R工作界面后,出现命令提示符“>”。要退出(quit)R界面,输入命令q(),按回车键(Enter)即可,或者点击右上方的关闭按钮(×)。
向量(vector)是 n 个实数 x 1 , x 2 ,…, x n 构成的数组 x ,是数据(data)单维的(one-dimensional)排列方式,也是最基本的数据存储方式。只有一排的矩阵(matrix)称作排向量(row vector)。只有一列的矩阵称作列向量(column vector)。譬如:

其中, x′ (排向量)表示将向量 x 的列转置(transpose)为排。排向量和列向量可以看作矩阵的特殊形式。一组数据可以作为一个向量(vector)储存在一个R变量(variable)中。一种常用方法是利用R函数(function,即执行某项任务的代码)c(combine的缩写,表示“组合”),数值置于括号内,用逗号隔开。变量赋值符号是“<-”(the less-than sign and the hyphen sign)。尽管用等值符号(=)通常也可以,但是它不是标准语法,不建议使用。需要注意的是,R对字母大小写很敏感,甚至标点符号(要用英文标点符号),譬如不能将c写成C。利用c将变量x的一组数值型(numeric)数据(2,4,5,6,8,10,15,20,21)输入到R中,输入变量名后按回车键查看输出结果:
>x<-C(2,4,5,6,8,10,15,20,21)
Error in C(2,4,5,6,8,10,15,20,21):
object not interpretable as a factor
>V<-c(2,4,5,6,8,10,15,20,21)
>V
Error:object
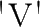 not found
not found
>x<-c(2,4,5,6,8,10,15,20,21)
>x
[1]2 4 5 6 8 10 15 20 21
当R命令正确时,R返还的结果以指标[1]显示。注意,在输入命令时,提示符“>”是R自带的,不可再输入一个提示符。
我们可以利用c把一个向量值添加到另一个向量值的后面。例如:
>data1<-c(1,2,3,4,5)
>data2<-c(3,4,5,6,7)
>data<-c(data1,data2)
>data
[1]1 2 3 4 5 3 4 5 6 7
如果要从向量中提取一个元素(element),则用方括号“[]”(square brackets)。譬如,从上例data向量中提取第5个元素,R命令和执行结果如下:
>data[5]
[1]5
如果要从一个数值向量中提取多个元素,则用c。譬如,从上例data向量中提取第5个和第7个元素,则R命令和执行结果如下:
>data[c(5,7)]
[1]5 4
如果要从一个向量中提取最小值(minimum value)和最大值(maximum value),则分别使用函数min和max。例如,提取上例data中的最小值和最大值的R命令和执行结果如下:
>min(data);max(data)
[1]1
[1]7
上例中两个命令之间用分号(;)隔开,可以同时得到两个结果。如果要对一个向量中的数值排序,则使用函数sort。对上例data中的数值进行排序的R命令和执行结果如下:
>sort(data)
[1]1 2 3 3 4 4 5 5 6 7
R默认从小到大的排序方式,即升序。如果要采用降序,则在函数sort中增加变元(argument)设置decreasing=TRUE。例如:
>sort(data,decreasing=TRUE)
[1]7 6 5 5 4 4 3 3 2 1
1.3.1.1.2 向量算术
我们可以利用R对数值向量进行加、减、乘、除运算,运算符号依次为:+、-、*、/。这些运算按元素(elementwise)进行。例如:
>x<-c(10,11,12,13,14,20,20)
>x-3
[1]7 8 9 10 11 17 17
>x*3
[1]30 33 36 39 42 60 60
上例使用常数计算新的向量,向量中的每个元素都依次减去或乘以某个常数。两个向量之间可以进行同样的运算,但是向量长度(length)(即数值的数量,在统计分析中指样本量)要相同。两个向量加、减、乘、除时,按照数值排列对应的顺序依次加、减、乘、除。例如:
>x<-c(10,11,12,13,14,20,20)
>y<-c(5,6,6,7,13,15,18)
>x-y;x/y
[1]5 5 6 6 1 5 2
[1]2.000000 1.833333 2.000000 1.857143 1.076923 1.333333 1.111111
如果要计算一个向量中的所有数值之和,则用函数sum。例如:
>sum(y)
[1]70
如果要计算一个变量数值的平均数如何编写代码呢?下面是计算平均数的简单程序代码:
Mean<-function(x) sum(x)/length(x)
该函数中,Mean代表求平均数的函数名称,函数length计算样本量,x代表数值向量,即某个数值型(numeric)或连续性(continuous)变量的值。例如:
>W<-c(10,13,14,20,22,76,33,21,18)
>Mean(W)
[1]25.222 22
统计编程是R软件的主要优势之一。学会简单的程序编写对理解统计概念是很有价值的。R自带多个函数计算统计量(statistics)。譬如,利用R自带函数mean,可以得到同样的值。例如:
>mean(W)
[1]25.222 22
再举个例子。如果我们要编写一个函数,确定一个数值向量中的最大值,可以使用for循环(for loop)。一个loop指被反复执行多次的一组命令。这些命令以for陈述开始,以大括号(})结束。对于求最大值的例子,编写的R命令如下:
Max=function(v){
max.value=0
for(i in 1:length(v)){
if(v[i]>max.value){
max.value=v[i]
}
}
return(max.value)
}
以上命令中,max.value=0表示初始最大值设为0,for陈述中的i in 1:length(v)表示索引变量i的范围,if(v[i]>max.value)为条件陈述,更新值储存在max.value中。返还值陈述return(max.value)置于for loop的外面。
假如我们要计算以下向量X中的最大值:
X<-c(35.00,36.57,48.24,40.62,41.03,36.45,28.90,34.93,42.45,41.74,36.09,41.44,32.79,40.74,34.90,44.12,42.91,30.37,36.93,33.90,41.41,44.89,30.86,35.59,40.79,37.79,38.46,41.20,42.70,43.35)
执行利用函数Max的R命令得到以下结果(其中的加号“+”是R自带的):
>Max=function(v){
+ max.value=0
+for(i in 1:length(v)){
+if(v[i]>max.value){
+ max.value=v[i]
+ }
+}
+return(max.value)
+ }
>X<-c(35.00,36.57,48.24,40.62,41.03,36.45,28.90,34.93,42.45,41.74,36.09,41.44,32.79,40.74,34.90,44.12,42.91,30.37,36.93,33.90,41.41,44.89,30.86,35.59,40.79,37.79,38.46,41.20,42.70,43.35)
>Max(X)
[1]48.24
要检验编写的函数计算是否正确,我们可以利用R自带函数max:
>max(X)
[1]48.24
以上结果显示,两个函数的计算结果相同,我们编写的R函数Max正确。
除了加、减、乘、除运算之外,还可以对向量开展其他运算,如幂(power)运算,运算符为“^”。例如:
>W^2
[1]100 169 196 400 484 5776 1089 441 324
R还提供了一些特殊的向量函数。函数seq返还按照某种间隔排序的一组数据。研究者可以根据需要设置函数变元。譬如,seq(from=1,to=20,by=1)中数值序列的初始值为1,终点值为20,序列间隔值为1,得到20个数值。该序列可以简化为:seq(1,20,1)。
另外一个很有用的函数是rep。该函数用于得到等值的向量,数据的长度可以通过重复的次数设定。例如:
>rep(2,times=10)
[1]2 2 2 2 2 2 2 2 2 2
>rep(2,10)# omit times
[1]2 2 2 2 2 2 2 2 2 2
向量空间不仅可以有数值型数据,还可以有字符数据(character data)、因素(factor)水平和逻辑数据(logical data)。字符向量中的元素是字符串,是名义(nominal)或类别(categorical)变量数据。创建字符向量可以利用函数c,字符串上添加引号('')。例如:
>Group<-c(' Male',' Female')
>Group
[1]' Male' ' Female'
因素是存储字符数据的另外一种方式。因素与名义或类别变量同义,由两个或两个以上水平(levels)构成。例如:
>Group<-factor(c(' Male',' Female'))
>Group
[1]Male Female
Levels:Female Male
当向量元素重复时,函数factor是十分有效的字符数据存储方式,同样的水平标签只出现一次。R内存因素水平为整数(integers)。例如:
>Group<-c(' Male',' Female',' Female',' Male',' Male')
>Group<-factor(Group)
>Group
[1]Male Female Female Male Male
Levels:Female Male
>as.integer(Group)
[1]2 1 1 2 2
这个例子表明,因素Group有两个水平,水平数值对应于字符串中字母的顺序,2对应于male,1对应于female。
如果一个因素有多个水平,每个水平多次重复,可以使用函数factor,并用c和rep函数,或者使用gl函数,无需多次重复输入每个水平。例如:
>Group<-rep(factor(c('grp1','grp2','grp3')),10)
>Group
[1]grp1 grp2 grp3 grp1 grp2 grp3 grp1 grp2 grp3 grp1 grp2 grp3 grp1 grp2
[15]grp3 grp1 grp2 grp3 grp1 grp2 grp3 grp1 grp2 grp3 grp1 grp2 grp3 grp1
[29]grp2 grp3
Levels:grp1 grp2 grp3
或者利用以下方式:
>Group<-gl(3,10,labels=c('grp1','grp2','grp3'))
>Group
[1]grp1 grp1 grp1 grp1 grp1 grp1 grp1 grp1 grp1 grp1 grp2 grp2 grp2 grp2
[15]grp2 grp2 grp2 grp2 grp2 grp2 grp3 grp3 grp3 grp3 grp3 grp3 grp3 grp3
[29]grp3 grp3
Levels:grp1 grp2 grp3
函数gl中的第一个变元代表因素水平数,第二个变元代表每个水平的重复次数,第三个变元设置因素水平标签或名称。本例的因素Group有三个水平,每个水平重复10次。在实验设计中,这表明有三个实验组,每组样本量( n )为10。
逻辑向量包括TRUE和FALSE两个元素(用于真假陈述判断),或者包括NA(表示缺失值,missing value)。例如:
>a<-c(TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE)
>b<-c(3,5,7,9,12,13,15)
>b[a]
[1]3 5 7 9 12
上例中,向量b中对应于TRUE(真)的数据被选中。逻辑向量常用操作符(operators)为:&(and,和)、|(or,或者)、!(not,非)。例如:
>!a
[1]FALSE FALSE FALSE FALSE FALSE TRUE TRUE
向量a中的真假值与!a给出的结果相反。关于操作符“&”和“|”的作用,试比较R输出结果:
>a<-c(TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE)
>b<-c(TRUE,TRUE,TRUE,TRUE,FALSE,TRUE,FALSE)
>a&b
[1]TRUE TRUE TRUE TRUE FALSE FALSE FALSE
>a|b
[1]TRUE TRUE TRUE TRUE TRUE TRUE FALSE
在两个向量对应数值同为TRUE或同为FALSE时,a&b判定结果为TRUE或FALSE。如果对应值一个为TRUE,另一个为FALSE,则a&b判定结果为FALSE。对于a|b,只要对应值中至少有一个为TRUE,则判定结果就为TRUE。如果两个对应值均为FALSE,a|b判定结果则为FALSE。
如果对逻辑向量进行运算,则R将元素TRUE转化为1,FALSE转化为0。譬如,对逻辑向量a求和:
>sum(a)
[1]5
在逻辑向量a中有5个真值(true values)。判断一个向量中有无缺失值,使用函数is.na,可以利用函数sum计算缺失值数量。例如:
>x<-c(1,2,3,4,5,7,NA)
>is.na(x)
[1]FALSE FALSE FALSE FALSE FALSE FALSE TRUE
>sum(is.na(x))
[1]1
如果要对包含缺失值的数据进行统计分析,则需要明确缺失值的处理方式,通常利用na.rm=TRUE删除缺失值。例如:
>mean(x,na.rm=TRUE)
[1]3.666667
要提取缺失值以外的所有数据,则用R命令x[!is.na(x)]。例如:
x[!is.na(x)]
[1]1 2 3 4 5 7
R还利用关系操作符(relational operators)进行逻辑判断。关系操作符包括:<、>、=、>=、<=、!=。下面是一些R输出的例子:
>W<-c(20,30,50,15,60,50)
>W<50 # which elements are less than 50
[1]TRUE TRUE FALSE TRUE FALSE FALSE
>W<=50 # which elements are less than or equal to 50
[1]TRUE TRUE TRUE TRUE FALSE TRUE
>W>50 # which elements are more than 50
[1]FALSE FALSE FALSE FALSE TRUE FALSE
>W>=50 # which elements are more than or equal to 50
[1]FALSE FALSE TRUE FALSE TRUE TRUE
>W==50 # which elements are exactly equal to 50
[1]FALSE FALSE TRUE FALSE FALSE TRUE
>W[!W==50]# print them
[1]20 30 15 60
附带提一下,标量(scalar)是指含有一个元素的向量,数据类别可以是数值,也可以是字符、因素水平或逻辑数据。例如,a<-3;b<-'gender' ;c<-FALSE。