
下载掌阅APP,畅读海量书库
立即打开




第2章提到,数据正态分布的诊断可以利用图形方法,如箱图、直方图、核密度图或Q-Q图。图形诊断难免带有主观性。图形诊断和正式的统计检验相结合是更好的方法。本节讨论最常用的正态分布检验方法—— W 检验,由Shapiro & Wilk(1965)提出。最初提出的 W 检验针对小样本(3≤ n ≤50),后来由于算法的改进样本量扩大到5 000。如果检验统计量 W 的概率值 p >0.05,可以推断样本数据所在总体的分布呈正态。如果 p <0.05,则认为样本数据所在总体的分布呈非正态。 W 检验的公式为:

其中,
a
i
是与观测值次序
r
有关的系数,是正态化最优线性无偏系数(best linear unbiased coefficient)。在正态分布中,-
a
i
=
a
n-i
+1
。公式3.27中的
n
是样本量,
y
i
是按照次序排放的第
i
个样本观测值,
y
1
≤
y
2
≤ …≤
y
n
;
 是样本平均数。Shapiro &Wilk(1965)列出样本量
n
在2~50区间内
W
检验的系数{
a
n-i
+1
}以及样本量
n
在3~50区间内
W
分布中
W
值对应的百分点(percentage points,概率
p
值)。表3.1为样本量
n
在20~30区间内
W
检验的系数{
a
n-i+1
}。
是样本平均数。Shapiro &Wilk(1965)列出样本量
n
在2~50区间内
W
检验的系数{
a
n-i
+1
}以及样本量
n
在3~50区间内
W
分布中
W
值对应的百分点(percentage points,概率
p
值)。表3.1为样本量
n
在20~30区间内
W
检验的系数{
a
n-i+1
}。
表3.1 样本量 n =20~30时 W 检验的系数{ a n - i +1 }

来源:Shapiro& Wilk(1965,p.603)。
系数
a
i
的大小与样本量
n
和
y
i
的次序有关。根据表3.1,当
n
=20时,后10个次序统计量对应的系数值依次为:0.014 0,0.042 2,0.071 1,0.101 3,0.133 4,0.168 6,0.208 5,0.256 5,0.321 1,0.473 4。由于-
a
i
=
a
n
-
i
+1
,前10个次序统计量对应的系数值依次为:-0.473 4,-0.321 1,-0.256 5,-0.208 5,-0.168 6,-0.133 4,-0.101 3,-0.071 1,-0.042 2,-0.014 0。系数
a
i
的一个重要特点是:
 =
=
 =1,其中
a
为
n
×1矩阵(即列向量),
a′
是
a
的转置矩阵(即排向量)。因此,
W
值本质上是
a
1
,…,
a
n
与
y
1
,…,
y
n
皮尔逊相关系数(Pearson correlation coefficient,
r
)的平方(
r
2
)。
W
值介于0~1之间,最大值为1,最小值为
=1,其中
a
为
n
×1矩阵(即列向量),
a′
是
a
的转置矩阵(即排向量)。因此,
W
值本质上是
a
1
,…,
a
n
与
y
1
,…,
y
n
皮尔逊相关系数(Pearson correlation coefficient,
r
)的平方(
r
2
)。
W
值介于0~1之间,最大值为1,最小值为
 /(
n
-1)。
W
值越接近1,数据分布的正态性就越好。
/(
n
-1)。
W
值越接近1,数据分布的正态性就越好。
对于正态分布样本, W 的分布只取决于样本量 n 。 W 统计显著性检验可以通过查表的方式。表3.2显示样本量 n 在 20~30 区间内零假设条件下 W 值对应的概率 p 值。
表3.2 样本量 n =20~30时 W 值对应的 p 值

来源:Shapiro& Wilk(1965,p.605)。
假如有变量 Y 的一组数据(已按升序排列)( n =20):8,8,8,9,9,9,10,11,12,15,15,16,16,16,18,18,28,40,41,53。由表3.1得到 Y 次序统计量对应系数 a i :-0.473 4,-0.321 1,-0.256 5,-0.208 5,-0.168 6,-0.133 4,-0.101 3,-0.071 1,-0.042 2,-0.014 0,0.014 0,0.042 2,0.071 1,0.101 3,0.133 4,0.168 6,0.208 5,0.256 5,0.321 1,0.473 4。利用公式 3.27,执行以下R命令:(t(ai)%*% y)^2/(t(y-mean(y))%*%(y-mean(y))), [1] 得到 W =0.750 4(保留四位小数)。查表3.2发现, n =20时, W =0.868对应 p =0.01。本例数据 W =0.750 4小于 W =0.868,因而本例 W 检验拒绝零假设( p <0.01),有证据表明本例数据违反正态分布。
计算统计量
W
的关键是计算系数
a
i
。系数
a
i
的精确计算比较复杂,特别是在样本量大的时候。Royston(1992)提出了
a
i
近似算法。系数
 近似等于
近似等于

 ,其中
,其中
 ,
,
 是标准正态累积分布函数
,
是标准正态累积分布函数
,
 是
是
 的反函数(inverse function),
i
=1,…,
n
。系数
a
与
c
的主要不同之处在于样本中的前两个系数和后两个系数。由于
a
1
=-
a
n
,
a
2
=-
a
n
-1
,因而只需计算
a
n
和
a
n
-
1
。令4≤
x
≤1 000,将
的反函数(inverse function),
i
=1,…,
n
。系数
a
与
c
的主要不同之处在于样本中的前两个系数和后两个系数。由于
a
1
=-
a
n
,
a
2
=-
a
n
-1
,因而只需计算
a
n
和
a
n
-
1
。令4≤
x
≤1 000,将
 作为预测变量将,
a
n
-
c
n
和
a
n-1
-
c
n-1
作为效标变量(因变量)开展5次(quintic)多项式回归分析,得到:
作为预测变量将,
a
n
-
c
n
和
a
n-1
-
c
n-1
作为效标变量(因变量)开展5次(quintic)多项式回归分析,得到:
 =
c
n
+0.221 157
x
-0.147 981
x
2
-2.071 190
x
3
+4.434 685
x
4
-2.706 056
x
5
=
c
n
+0.221 157
x
-0.147 981
x
2
-2.071 190
x
3
+4.434 685
x
4
-2.706 056
x
5
 =
c
n
-1
+0.042 981
x
-0.293 762
x
2
-1.752 461
x
3
+5.682 633
x
4
-3.582 633
x
5
=
c
n
-1
+0.042 981
x
-0.293 762
x
2
-1.752 461
x
3
+5.682 633
x
4
-3.582 633
x
5
若
n
≤5,令
 ;若
n
>5,令
;若
n
>5,令

 ,则正态化(normalize)剩余
,则正态化(normalize)剩余
 值得到
值得到
 ,其中
i
=2,…,
n
-1(
n
≤5)或
i
=3,…,
n
-2(
n
>5)。
,其中
i
=2,…,
n
-1(
n
≤5)或
i
=3,…,
n
-2(
n
>5)。
针对本例
Y
变量数据,利用以上近似计算方法,得到正态化系数
 :-0.473 371 10,-0.321 740 27,-0.255 663 23,-0.208 297 20,-0.168 639 82,-0.133 584 21,-0.101 474 39,-0.071 289 30,-0.042 323 22,-0.014 035 13,0.014 035 13,0.042 323 22,0.071 289 30,0.101 474 39,0.133 584 21,0.168 639 82,0.208 297 20,0.255 663 23,0.321 740 27,0.473 371 10。这些近似值与表3.1中的
a
i
值差异很小。利用以上系数
:-0.473 371 10,-0.321 740 27,-0.255 663 23,-0.208 297 20,-0.168 639 82,-0.133 584 21,-0.101 474 39,-0.071 289 30,-0.042 323 22,-0.014 035 13,0.014 035 13,0.042 323 22,0.071 289 30,0.101 474 39,0.133 584 21,0.168 639 82,0.208 297 20,0.255 663 23,0.321 740 27,0.473 371 10。这些近似值与表3.1中的
a
i
值差异很小。利用以上系数
 计算检验统计量
W
,得到
W
=0.750 2(保留四位小数),与利用表3.1计算得到的
W
值只在小数点后第四位上有差异。
[2]
计算检验统计量
W
,得到
W
=0.750 2(保留四位小数),与利用表3.1计算得到的
W
值只在小数点后第四位上有差异。
[2]
W 检验显著性概率 p 的计算可以采用正态化 W 统计量的方法,转化后的值称作 w 。根据Royston(1992),若4≤ n ≤11,则:

若12≤ n ≤2 000,则:

要计算显著性概率 p ,则先根据 w 值、 μ (平均数)和 σ (标准差)计算标准正态分布的 Z 值,再利用R函数1-pnorm(Z)计算显著性概率。标准正态分布 Z 值的计算公式为:

针对本例,根据公式3.28,得到 Z =3.581 5, p =0.000 17<0.001。
W 检验可以利用R函数shapiro.test(x)或者stat.desc(x,norm=TRUE),其中x为数值向量,norm=TRUE表示结果输出包括正态检验统计量。本例中, W =0.750 2, p =0.000 17<0.001,说明该组数据违反正态分布。利用函数skewness(x,type=2)和kurtosis(x,type=2)分别得到偏度值1.73和峰度值2.26,说明该组数据呈正偏态和正峰态。图3.7诊断变量 Y 的数据分布。

图3.7 变量 Y 数据分布
图3.7中的实线代表经验分布,虚线代表理论正态分布。该组数据分布呈尖峰状,中央过剩,右尾巴拉长,小凸块显示有异常值存在。利用R函数outbox(x)发现有3个异常值:40,41,53。
Shapiro& Francia(1972)在Shapiro& Wilk(1965)研究的基础上提出大样本(样本量大于50)正态分布近似检验方法,称作
 检验。该检验使用的系数只取决于正态次序统计量(order statistics)的期望值。
检验。该检验使用的系数只取决于正态次序统计量(order statistics)的期望值。
 统计量的计算公式为:
统计量的计算公式为:

其中,
 为标准正态次序统计量期望值向量,
为标准正态次序统计量期望值向量,
 为样本第
i
个次序观测值,
为样本第
i
个次序观测值,
 为样本观测值平均数。
为样本观测值平均数。
Royston(1993)提出
W
′及其
p
值的近似算法。样本量大于5时,Royston(1993)提出的算法的精确性足以满足实际应用的要求。正态分数
m
i
(
i
=1,…,
n
)可以通过
 近似得到,其中
近似得到,其中
 是标准正态分布反函数,
是标准正态分布反函数,
 。
W′
值转化为标准正态分布
Z
分数的公式为:
。
W′
值转化为标准正态分布
Z
分数的公式为:

其中, λ 、 μ 和 σ 是ln( n )的多项式函数。 n ≥10时,| λ |接近0,表明1- W′ 的分布近似服从对数正态分布(lognormal distribution)。检验统计量 Z′ 的计算公式为:

其中,
 =-1.272 5+1.052 1(ln(ln())
n
-ln(
n
)),
=-1.272 5+1.052 1(ln(ln())
n
-ln(
n
)),
 =1.030 8-0.267 58(ln(ln(
n
))+2/ln(
n
))。
Z′
为标准正态分布的上尾巴值。计算
Z′
显著性概率
p
值的R函数为pnorm(Z′,lower.tail=FALSE)。
=1.030 8-0.267 58(ln(ln(
n
))+2/ln(
n
))。
Z′
为标准正态分布的上尾巴值。计算
Z′
显著性概率
p
值的R函数为pnorm(Z′,lower.tail=FALSE)。
在前面关于变量 Y 值的例子中,如果采用 W′ 检验,利用上面的计算公式,得到 W′ =0.748 415 4, Z′ =3.383 587, p =0.000 357 7<0.001,与 W 检验得出的结论相同。 W′ 检验的R函数为来自数据包nortest中的函数sf.test(x),其中x为数值向量。本例执行R函数sf.test(y),得到 W′ =0.748 42, p =0.000 357 7<0.001。
Shapiro& Francia(1972)从12个非正态分布族中随机抽取样本量为35和50的随机样本数各100个,比较 W′ 和 W 检验的统计效力。总体上,这两个检验在效力上的差异不大。具体而言,在以下分布情况下, W′ 检验似乎比 W 检验更敏感:①分布为连续性对称分布,四阶距(fourth moment)高;②分布接近正态;③分布具有离散性,且呈偏态。当分布为连续性非对称分布且四阶距高或者分布为离散性对称分布时, W 检验与 W ′检验似乎对等,但是在其他情况下, W 检验的效力更高。
思考与练习
1.简要说明描述性统计包括的维度。
2.简要概括正态分布的特点。
3.编写计算变量 X 样本标准差的R的函数std.dev,利用该函数计算以下一组数值的标准差,并利用R自带函数sd检验两个函数计算结果的一致性:25.96,30.83,37.15,24.91,29.64,30.60,33.19,28.92,38.93,29.38,31.88,34.42,28.23,25.32,38.02,19.60,33.95,30.16,34.56,31.95。
4.有以下一组由小到大排序的数值:35,39,40,40,41,42,45,46,47,48, x , x , x ,63,96,其中 x 值未知。下面哪个或哪些陈述是正确的?
(a)众数是40;
(b)平均数大于中位数;
(c)中位数为46;
(d)没有异常值。
5.以下哪些描述正确体现标准差的特点?
(a)标准差对异常值有抗扰性,即不受或较少受到异常值的影响。
(b)标准差与各个数值的平均数离差平方和有正向关系。
(c)每个数值加上或减去一个常数(如10),标准差不变。
(d)平均数上下移动两个标准差构成的区间包括大约95%的数值。
6.利用R自带函数mean计算以下一组数值的算术平均数,再调用R数据包Rallfun-v37中的函数tmean计算该组数据的20%截尾平均数:35,41,50,33,40,41,44,39,52,39,43,46,2,38,5,9。两个平均数是否有较大的差异?如果差异较大,说明造成较大差异的主要原因。
7.利用本章介绍的四种函数boxplot(x)、outbox(x)、outbox(x,mbox=TRUE)和out(x)诊断第6题数据分布中的异常值。四种诊断方法得出的结果是否一致?
8.利用数据包pastecs中的函数stat.desc计算第6题数据分布的偏度值和峰度值、 W 检验统计量和相关的概率 p 值。本次检验得出的结论是什么?
9.下图是一组数据分布的核密度图,其中的横坐标值表示某个变量的测量值。

要求:根据以上核密度图,诊断数据分布的特点。
10.通常情况下,样本20%缩尾方差(
 会小于样本方差(
s
2
)吗?为什么?
会小于样本方差(
s
2
)吗?为什么?
11.某年级英语学习者英语水平测试的平均分
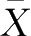 =65,方差
s
2
=25。某位学生的得分为80,该生得到的标准分(
Z
分数)是多少?
=65,方差
s
2
=25。某位学生的得分为80,该生得到的标准分(
Z
分数)是多少?
12.一组数据的平均数为
 =15,标准差为
s
=3.5。如果将该组数据中的每个数值均增加5,平均数和标准差是多少?如果将该组数据中的每个数值扩大到两倍,平均数和标准差又是多少?
=15,标准差为
s
=3.5。如果将该组数据中的每个数值均增加5,平均数和标准差是多少?如果将该组数据中的每个数值扩大到两倍,平均数和标准差又是多少?
13.已知一批英语学习者的英语水平测试成绩服从平均数为 μ =70、标准差 σ =6的正态分布。根据正态分布原理,回答以下问题:
(a)低于58分的分值数占总分值数的百分比大约是多少?
(b)分值在64和82之间的百分比大约是多少?
14.下图显示一组数据分布的核密度图。图中的两条线(实线和虚线)体现平均数和中位数所在的位置。

试问:平均数位于哪一条线所在的点,中位数位于哪一条线所在的点?请给出理由。
[1] R命令中的ai代表系数 a i 构成的列向量,y代表 Y 值构成的列向量。
[2] Royston(1992,p.118)指出,Shapiro& Wilk(1965)给出的 n >20时 a i 近似值的近似度不足,甚至给出的 n ≤20时的 a i “精确”值也不精确。