
下载掌阅APP,畅读海量书库
立即打开




CRISP-DM是一种得到广泛应用的数据挖掘方法论(其他方法论请参考文献[1]),由SPSS、Teradata等公司于1999年发布第一版。该方法将大数据分析分为业务理解、数据理解、数据准备、模型建立、模型评价、模型部署6个阶段,如图3-1所示 [2] 。与一般的IT项目不同,分析项目的不同阶段之间存在很强的迭代关系。
业务理解:这一初始阶段从业务角度理解项目的目标和要求,并将理解转化为数据挖掘问题的定义和初步执行计划。
数据理解:始于原始数据的收集,熟悉数据并标明数据质量问题,对数据进行初步探索和理解,提取有趣的数据子集以形成对隐藏信息的假设。
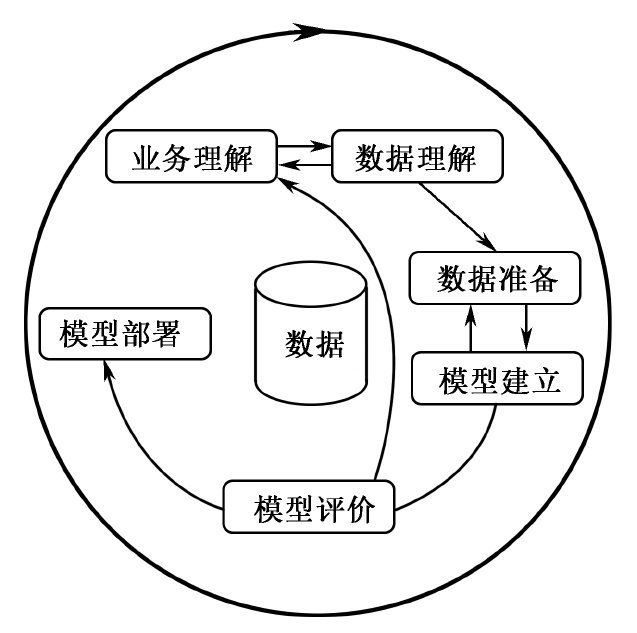
图3-1 CRISP-DM方法论
数据准备:包括从原始数据集到最终数据集的所有活动。数据准备任务可能迭代多次,而且不存在一成不变的顺序。这些任务包括数据的整合、选择、清洗、特征加工。
模型建立:主要包括分析算法选择、超参数调优和模型融合。在该阶段,通常会发现新的数据质量问题,因此,常常需要返回数据准备阶段。
模型评价:在进入该阶段时,已经建立了一个或多个相对可靠的模型。在模型发布前,需要更彻底地评估模型和检查建模步骤,以确保其达到了业务目标和落地应用条件。该阶段的关键目的是检查是否忽略了一些重要的业务场景。应该在该阶段确定数据挖掘模型是否可用。
模型部署:模型的建立并不是项目的结尾,通常需要以业务应用的形式发布和部署模型。即使建模只是为了增加对数据的了解,所获得的洞察通常也需要以一种用户能够理解的方式呈现出来。
如果大数据分析仅停留在上述6个阶段,则看起来与“炒菜”没有太大区别。先了解餐饮需求,再看有什么菜,然后做摘菜、洗菜、切菜、初级加工等前期准备工作,接着进入烹饪环节,适当品尝或观察色泽后装盘上桌。令人欣慰的是,CRISP-DM方法论对每个阶段的执行内容都进行了细化,使其成为指导性方法论,如图3-2所示。即使如此,对于特定领域的大数据分析项目来说,我们也需要在CRISP-DM方法论的基础上,加入领域特征、细化活动内容、实例化交付物、明确重点,使其成为在特定领域内具有可操作性的方法论。
在大数据分析问题中,不同项目的需求明确度差异很大。分析问题的实际执行路径如图3-3所示。
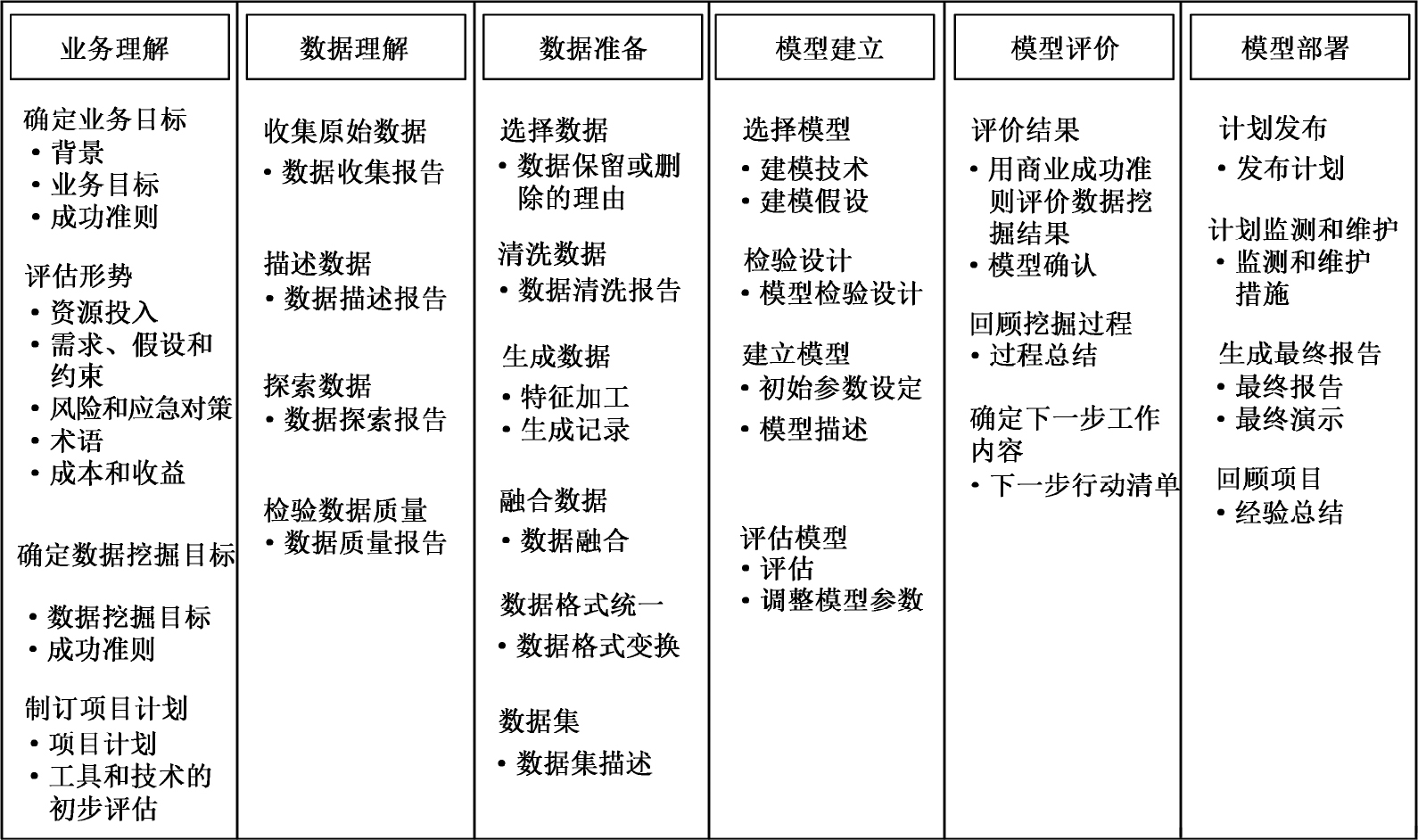
图3-2 CRISP-DM方法论每个阶段的执行内容
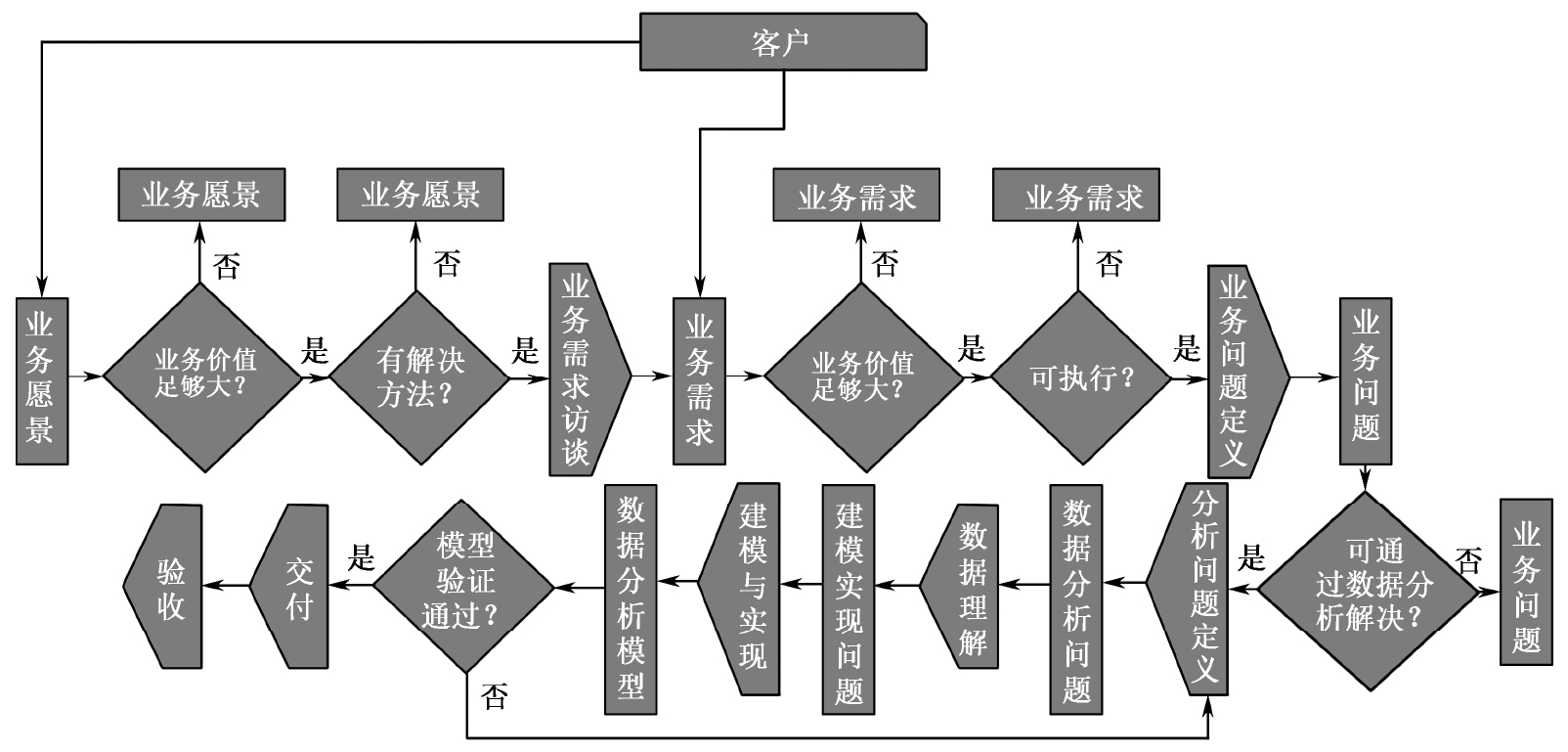
图3-3 分析问题的实际执行路径
分析问题成熟度的差异和数据分析师经验知识体系的差异使得不同项目在CRISP-DM方法论的“业务理解”环节中差异很大,在执行中具体体现为3类典型场景。
(1)业务规划类:只有大概业务愿景或目标,如用大数据提高产品质量、用大数据构建精加工工业互联网(向第三方开放自己的精加工能力)等。此时需要业务分析师与客户一起从业务角度分解业务愿景,并将其总结为若干数据分析问题。
(2)业务问题理解类:有明确业务需求(如备件需求预测等)。需要将组织结构、业务流程、典型业务场景(如促销、囤货、地区公司合并等)等业务上下文信息进行细化并对其进行理解。
(3)数据分析问题定义类:有些问题不涉及业务上下文,如监控图像识别等。此时,将业务期望(如检出率、误报率、处理速度等要求)确认清楚即可。
“业务理解”和“数据准备”阶段往往会占用75%以上的时间。很多分析问题的定义需要在迭代中不断理清;数据结构层面的数据预处理(包括数据类型及值域检查、数据集的合并等)通常比较简单,但业务语义层面的数据质量问题只能在数据探索和建模过程中不断发现。
在经典CRISP-DM方法论中,假设分析问题是给定的,“业务理解”阶段对该问题的业务背景和含义进行理解。但很多大数据分析项目并不是这样,它们需要分析人员根据业务需求不断对业务进行细化和定义,这在工业大数据分析中更为普遍。工业大数据分析常常出现知识严重二分的情形。数据分析师对工业过程缺乏深入了解,而业界人员对数据分析的了解相对缺乏,需要将两者有效结合,以定义一个有价值且可落地的数据分析问题。