
下载掌阅APP,畅读海量书库
立即打开



Spark带有交互式的Shell,可在Spark Shell中直接编写Spark任务,然后提交到集群与分布式数据进行交互,并且可以立即查看输出结果。Spark Shell提供了一种学习Spark API的简单方式,可以使用Scala或Python语言进行程序的编写(本书使用Scala语言进行讲解)。
进入Spark安装目录,执行以下命令,可以查看Spark Shell的相关使用参数:
$ bin/spark-shell --help
Spark Shell在Spark Standalone模式和Spark On YARN模式下都可以执行,与2.6节中使用spark-submit进行任务提交时可以指定的参数及取值一样,唯一不同的是,Spark Shell本身为集群的client提交方式运行,不支持cluster提交方式,即使用Spark Shell时,Driver运行于本地客户端,而不能运行于集群中。
在任意节点进入Spark安装目录,执行以下命令,启动Spark Shell终端:
$ bin/spark-shell --master spark://centos01:7077
上述命令中的--master参数指定了Master节点的访问地址,其中的centos01为Master所在节点的主机名。
Spark Shell的启动过程如图2-20所示。
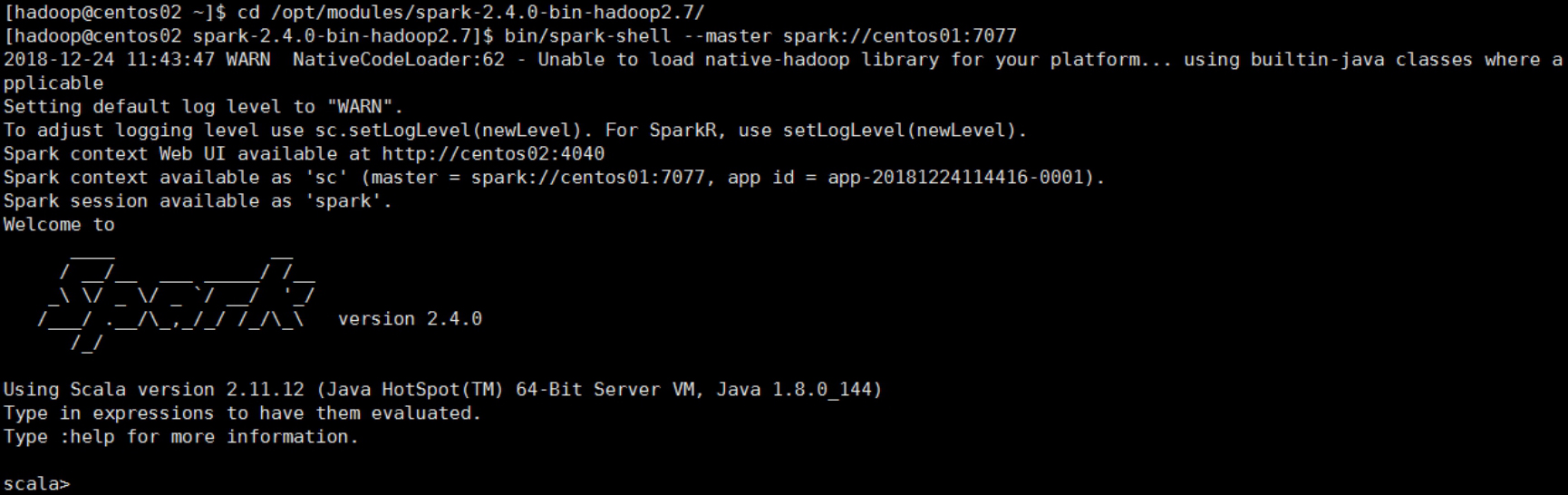
图2-20 Spark Shell的启动过程
从启动过程的输出信息可以看出,Spark Shell启动时创建了一个名为sc的变量,该变量为类SparkContext的实例,可以在Spark Shell中直接使用。SparkContext存储Spark上下文环境,是提交Spark应用程序的入口,负责与Spark集群进行交互。
若启动命令不添加--master参数,则默认是以本地(单机)模式启动的,即所有操作任务只是在当前节点,而不会分发到整个集群。
启动完成后,访问Spark WebUI http://centos01:8080/查看运行的Spark应用程序,如图2-21所示。

图2-21 查看Spark Shell启动的应用程序
可以看到,Spark启动了一个名为Spark shell的应用程序(如果Spark Shell不退出,该应用程序就一直存在)。这说明,实际上Spark Shell底层调用了spark-submit进行应用程序的提交。与spark-submit不同的是,Spark Shell在运行时会先进行一些初始参数的设置,并且Spark Shell是交互式的。
若需退出Spark Shell,则可以执行以下命令:
scala>:quit
Spark On YARN模式下,Spark Shell的启动与Standalone模式不同的是:--master的参数值为yarn。例如以下启动命令:
$ bin/spark-shell --master yarn
若启动过程中报如图2-22所示的错误,则说明Spark任务的内存分配过小,YARN直接将相关进程杀掉了。

图2-22 Spark On YARN模式下Spark Shell启动错误输出
此时只需要在Hadoop的配置文件yarn-site.xml中加入以下内容即可:
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
上述配置属性解析如下:
● yarn.nodemanager.pmem-check-enabled:是否开启物理内存检查,默认为true。若开启,则NodeManager会启动一个线程检查每个Container中的Task任务使用的物理内存量,如果超出分配值,就直接将其杀掉。
● yarn.nodemanager.vmem-check-enabled:是否开启虚拟内存检查,默认为true。若开启,则NodeManager会启动一个线程检查每个Container中的Task任务使用的虚拟内存量,如果超出分配值,就直接将其杀掉。
需要注意的是,yarn-site.xml文件修改完毕后,记得将该文件同步到集群其他节点,然后重启YARN集群。