
下载掌阅APP,畅读海量书库
立即打开



在正式讲解Spark之前,读者首先需要了解大数据开发的总体架构,如图2-1所示。
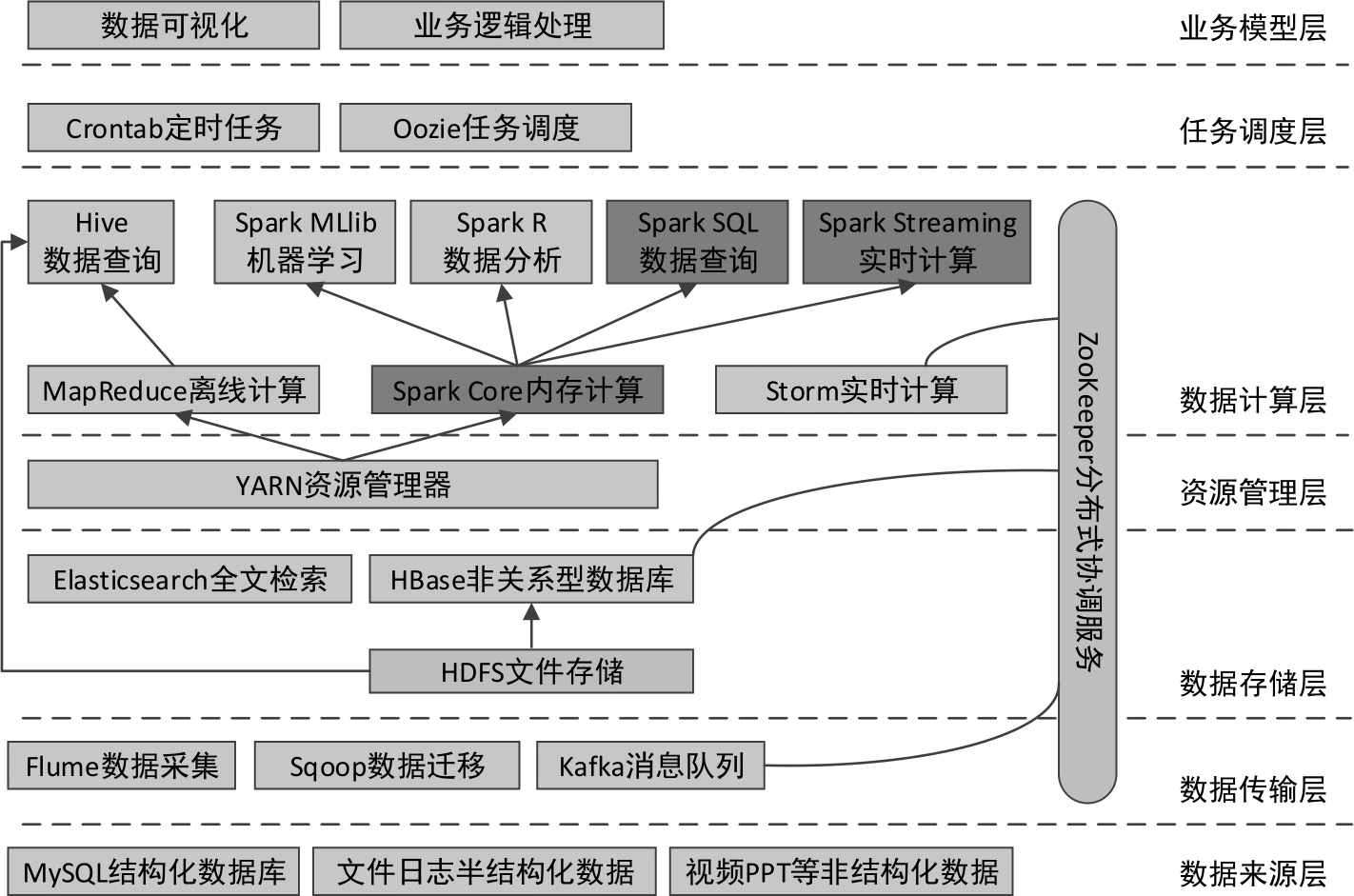
图2-1 大数据开发总体架构
● 数据来源层
在大数据领域,数据的来源往往是关系型数据库、日志文件(用户在Web网站和手机App中浏览相关内容时,服务器端会生成大量的日志文件)、其他非结构化数据等。要想对这些大量的数据进行离线或实时分析,需要使用数据传输工具将其导入Hadoop平台或其他大数据集群中。
● 数据传输层
数据传输工具常用的有Flume、Sqoop、Kafka。Flume是一个日志收集系统,用于将大量日志数据从许多不同的源进行收集、聚合,最终移动到一个集中的数据中心进行存储;Sqoop主要用于将数据在关系型数据库和Hadoop平台之间进行相互转移;Kafka是一个发布与订阅消息系统,它可以实时处理大量消息数据以满足各种需求,相当于数据中转站。
● 数据存储层
数据可以存储于分布式文件系统HDFS中,也可以存储于分布式数据库HBase中,而HBase的底层实际上还是将数据存储于HDFS中。此外,为了满足对大量数据的快速检索与统计,可以使用Elasticsearch作为全文检索引擎。
● 资源管理层
YARN是大数据开发中常用的资源管理器,它是一个通用资源(内存、CPU)管理系统,不仅可以集成于Hadoop中,也可以集成于Spark等其他大数据框架中。
● 数据计算层
MapReduce是Hadoop的核心组成,可以结合Hive通过SQL的方式进行数据的离线计算,当然也可以单独编写MapReduce应用程序进行计算;Storm用于进行数据的实时计算,可以非常容易地实时处理无限的流数据;而Spark既可以做离线计算(Spark SQL),又可以做实时计算(Spark Streaming),它们底层都使用的是Spark的核心Spark Core。
● 任务调度层
Oozie是一个用于Hadoop平台的工作流调度引擎,可以使用工作流的方式对编写好的大数据任务进行调度。若任务不复杂,则可以使用Linux系统自带的Crontab定时任务进行调度。
● 业务模型层
对大量数据的处理结果,最终需要通过可视化的方式进行展示,可以使用Java、PHP等处理业务逻辑,查询结果数据库,最终结合ECharts等前端可视化框架展示处理结果。