
下载掌阅APP,畅读海量书库
立即打开



图像分类非常容易理解,就是自动识别每个图像的所属类别。图像分类是计算机视觉中最基础的任务之一,可以单独用来解决一个业务问题,比如基于图像识别的垃圾分类问题,也可以作为多模型编排中的一个环节(如OCR任务中的文字分类环节),辅助端到端地解决复杂的业务问题。图像分类的数据集一般都包含两个要素——图像和标签。根据每个图像的类别是一个还是多个,可以将图像分类细分为单标签图像分类和多标签图像分类。本节以花卉图像分类(单标签图像分类)为例,介绍如何基于图像分类模板快速开发图像分类应用。
首先在ModelArts上基于图像分类模板创建一个项目,然后上传一些图像(格式支持JPG、BMP、PNG、JPEG)。第一次上传一些类别为“小雏菊”的图像。由于刚上传的图像还没有人工标签,所以一次性选中所有刚上传的图像,手工将其标记为“小雏菊”,并单击“确定”按钮,如图2-1所示。
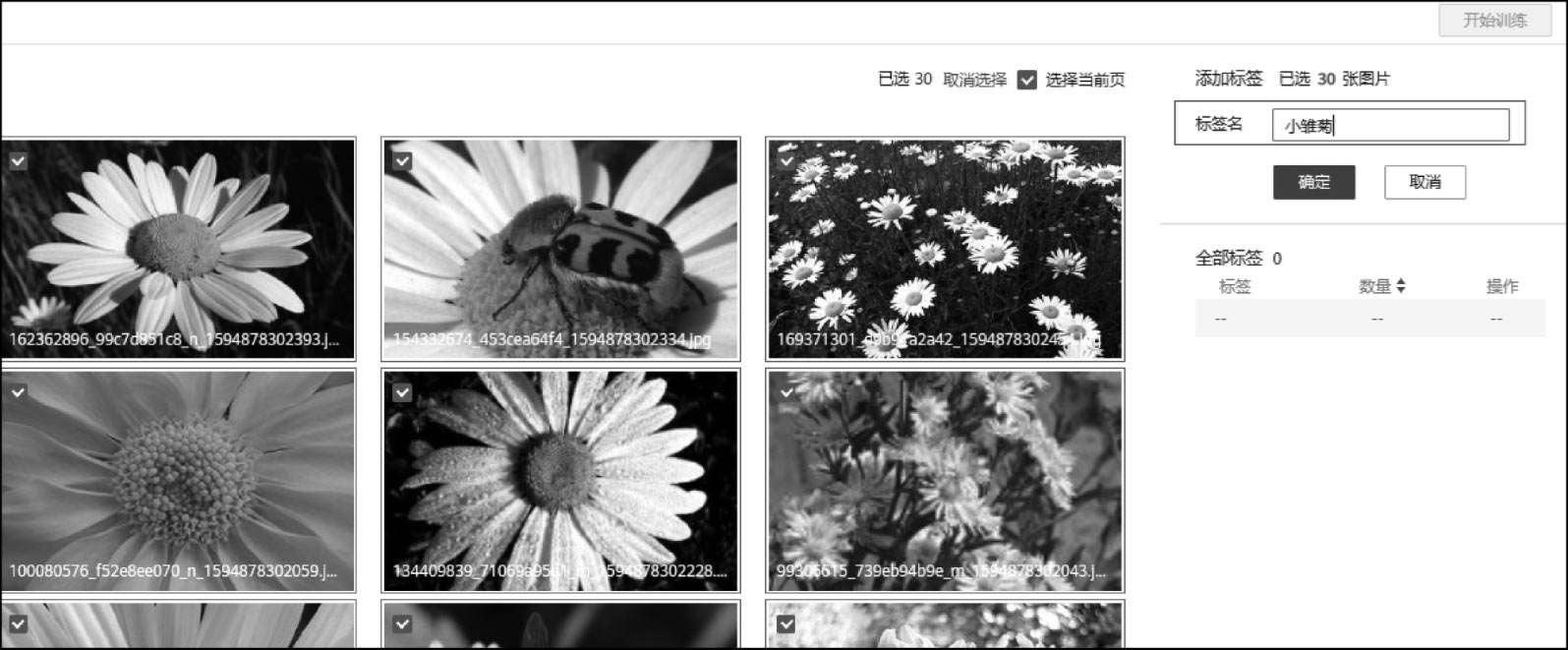
图2-1 花卉图像分类数据标注界面
类似地,继续上传更多的图片,并覆盖“蒲公英”“玫瑰”“向日葵”“郁金香”这4个类别。最终可以获得一个标注好的花卉数据集,每个类有30张图像,如图2-2所示。
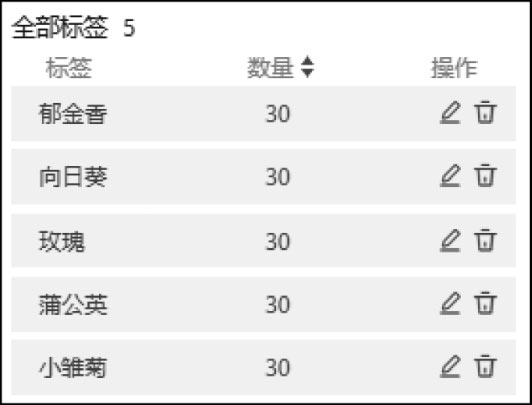
图2-2 花卉数据集的标签统计信息
数据准备完毕后,可以单击“开始训练”按钮启动模型的自动训练。开发者只需要输入预期的推理时延、能接受的最大训练时间和其他一些限制条件即可。ModelArts会根据开发者选择的推理时延,选择一个预期精度最高的算法进行自动训练,并且支持训练超参的自动调整,包括学习率自适应等。最大训练时间表示开发者可以接受的最长训练时间,但不代表一定会训练这么长时间。如果数据简单,可以提前结束训练;如果数据复杂,当训练作业时间达到最大训练时间时,训练作业会立刻停止并保存最优的一个模型。
经过短暂的等待,训练即可完成,训练结果如图2-3所示。可以看出,该模型在5分类花卉数据集上的综合准确率为81%。在图像分类中,针对每个类而言,一般会用以下几个指标去评价模型的效果:①精确率(Precision),指被模型预测为某个类别的所有正样本中,被模型正确预测为该类别的样本所占比例;②召回率(Recall),指被开发者标注为某个类别的所有正样本中,被模型正确预测为该类别的样本比例;③准确率(Accuracy),指在某个类别的所有正负样本中,模型预测正确的样本所占比例;④F1值(F1-score),指模型精确率和召回率的加权调和平均,用于评价模型的好坏,当F1较高时说明模型效果较好。最终的精度是所有类别的综合平均值(具体有两种做法,在此不具体展开,详细内容可参考第7章)。
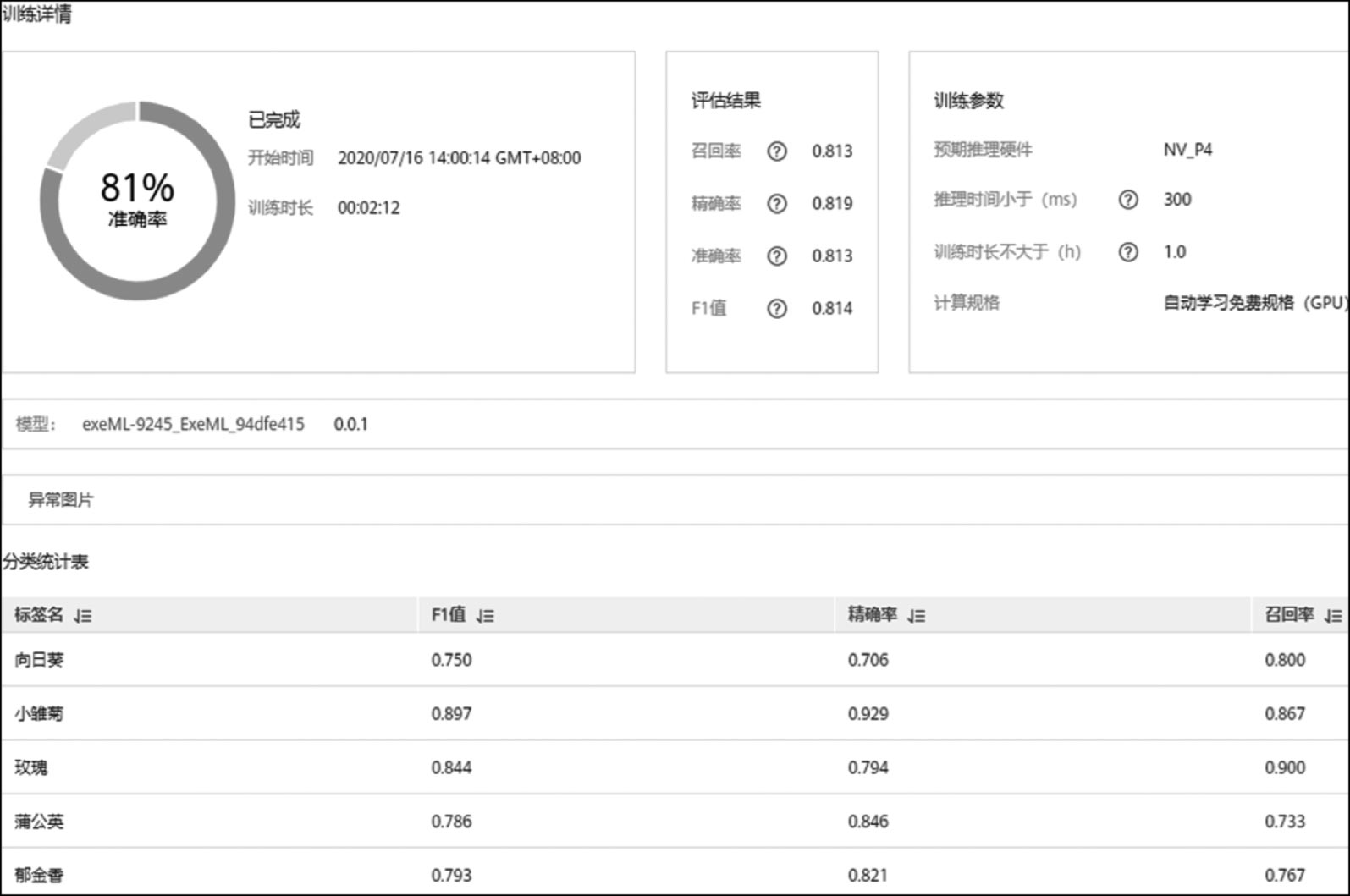
图2-3 花卉图像分类训练结果展示界面
如果对本次训练结果不满意,那么为了实现更高精度的训练,一般需要利用更多的数据做训练。首先,上传新一批的图像数据并标注,然后开始训练。为了节省训练时间,在本次训练开始前,选择以V001(即上一次训练的版本)为基础进行增量训练,如图2-4所示。训练完成后,可以看到精度指标有所提升,达到83%,如图2-5所示。如果要进一步提升精度,则需要重复上述过程,进行进一步增量训练。增量训练对于大部分模板都是适用的。

图2-4 提交训练作业时的参数配置展示界面
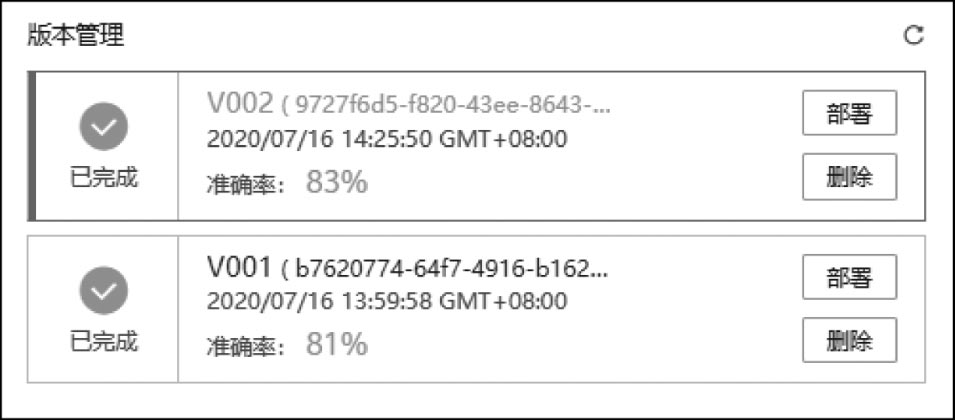
图2-5 不同的训练作业版本对比展示界面
当对模型精度满意之后,就可以进行部署和在线测试。例如,选择V002的训练版本,然后单击“部署”按钮,即可将其生成的模型直接部署到云上,成为一个推理服务(即云服务形态的人工智能应用)。当部署成功后,可以上传一个新的图像做推理,并得到推理结果,如图2-6所示。
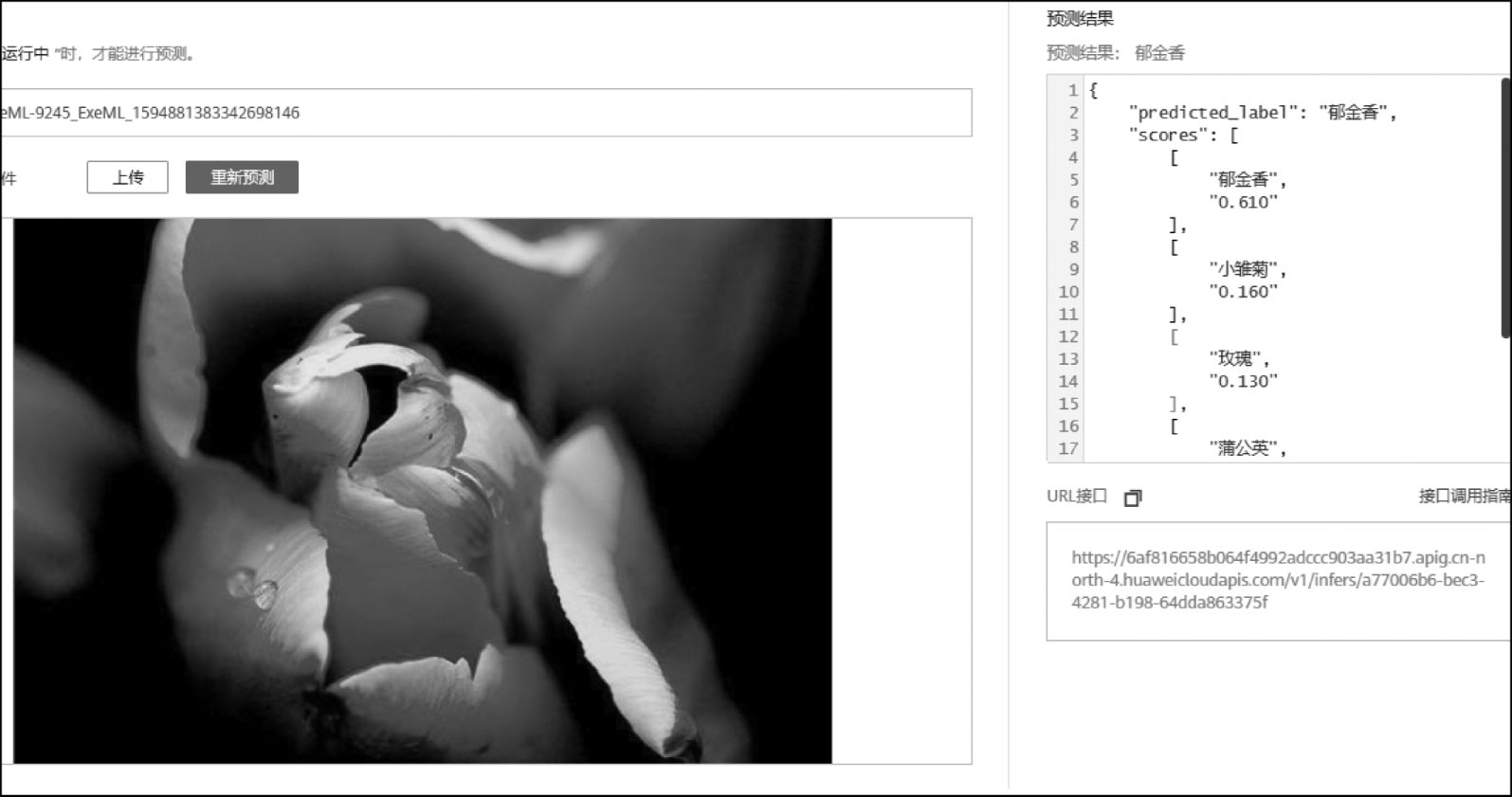
图2-6 花卉图像分类的推理结果展示界面
ModelArts推理服务可支持多种计算规格(CPU、GPU),并且支持自动停止功能,开发者可以灵活选择在“1小时后”“2小时后”“4小时后”“6小时后”后自动停止推理服务,也可以自定义在线时长,避免造成不必要的计费。