
下载掌阅APP,畅读海量书库
立即打开




在机器学习领域,另一个著名的数据集称为鸢尾花数据集(Iris dataset)。鸢尾花数据集包含3个不同种类(山鸢尾,Setosa;花斑鸢尾,Versicolor;维吉尼亚鸢尾,Viriginica)中150朵鸢尾花的测量值。这些测量值包含花瓣的长度和宽度、花萼的长度和宽度,所有的测量值均以厘米为单位。
我们的目标是建立可以学习这些鸢尾花测量值(这些花的种类是已知的)的一个机器学习模型,这样我们就可以预测一朵新鸢尾花的种类。
在我们开始本节之前,让我们发出警告——尽管名为逻辑回归,但实际上是一个分类模型,尤其是在我们只有两个类时。逻辑回归的名称来源于将输入的任意实值x转换成值在 0 到 1 之间的一个预测输出值ŷ的逻辑函数(或者Sigmoid函数),如图3-12所示。四舍五入到最近的整数,有效地将输入分类为 0 或者 1 。
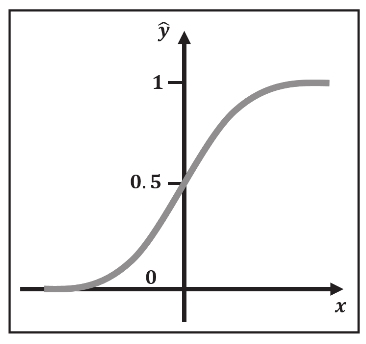
图3-12 输入的实值x和预测值ŷ之间的函数关系
当然,我们的问题通常有多个输入或者特征值x。例如,鸢尾花数据集一共提供4个特征。为了简单起见,我们将重点关注前两个特征:花萼长度——我们将其称为特征f 1 ,花萼的宽度——我们将其称为特征f 2 。使用在线性回归中学习的技巧,我们可以把输入x表示成两个特征f 1 和f 2 的一个线性组合:
x = w 1 f 1 + w 2 f 2
(3.5)
但是,与线性回归相比,我们还没有完成。从3.4节我们知道乘积的和将生成一个实值输出——但是,我们感兴趣的是分类值:0或者1。这就是逻辑函数的作用——充当一个压缩函数,将可能的输出值范围压缩到[0, 1]的范围内:
ŷ=σ(x)
(3.6)
因为输出总是在0和1之间,所以可以将输出解释为一个概率。如果我们只有一个输入变量x,输出值ŷ可被解释为x属于类1的概率。
现在,让我们把这些知识应用到鸢尾花数据集!
在scikit-learn中包含了鸢尾花数据集。首先,我们加载所有必要的模块,就像我们在前面的例子中所做的那样:

然后,加载数据集只需一行程序:

这个函数返回一个名为iris的字典,其包含一系列不同的字段:

这里,所有的数据点都包含在'data'中。有150个数据点,每个数据点有4个特征值:

这4个特征对应于花萼和花瓣的尺寸:

对于每个数据点,我们都在target中存储了一个类标签:

我们还可以查看类标签,发现一共有3个类:

为了简单起见,现在我们将重点放在一个二值分类问题上,在这个问题上我们只有2个类。最简单的方法是丢弃所有属于某一类的数据点,例如类标签2,选择不属于类2的所有行:

接下来,让我们检查数据。
在开始建立一个模型之前,最好先查看一下数据。在之前的城镇地图例子中我们就已经这样做了,所以让我们在这里重做一遍。使用Matplotlib,我们创建了一个 散点图 ,其中每个数据点的颜色与类标签对应:

为了使绘图更简单,我们只使用前两个特征(iris.feature_names[0]是花萼的长度,iris.feature_names[1]是花萼的宽度)。在图3-13中,我们可以看到类很好地分开了。
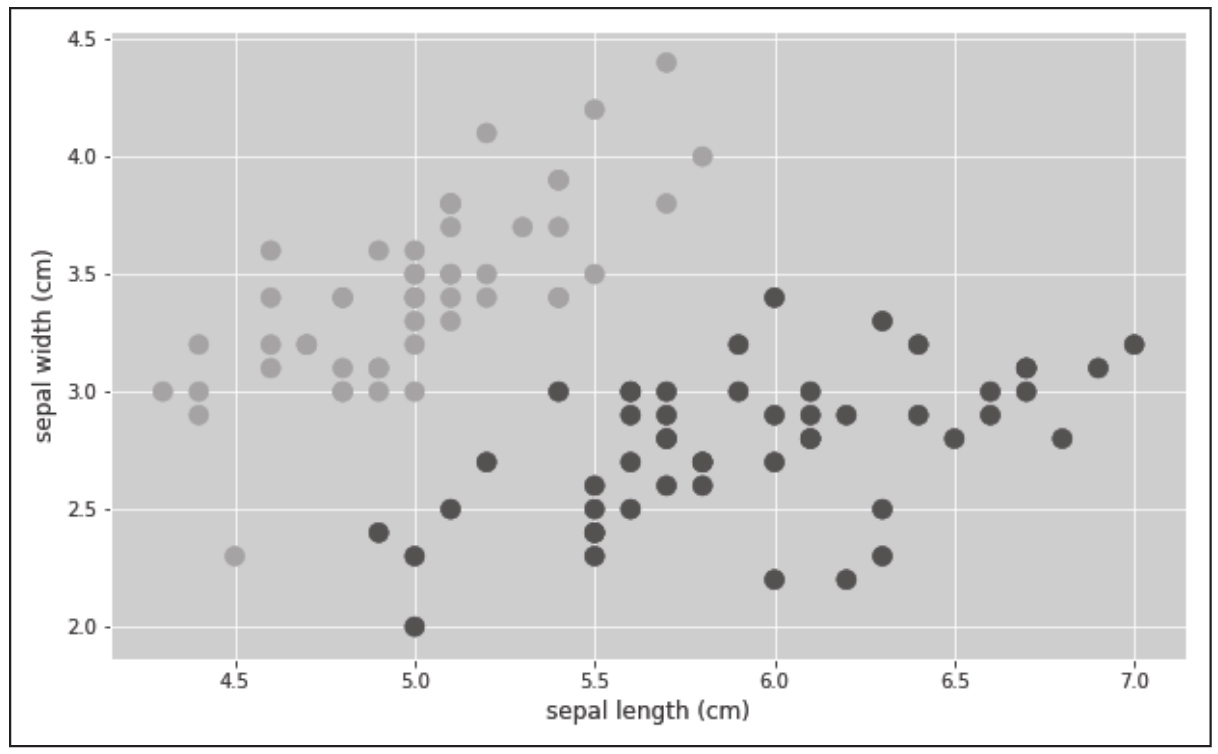
图3-13 Iris数据集前两个特征的散点图
在第2章中,我们学习了训练数据和测试数据相互独立是很重要的。在scikit-learn的众多帮助函数中,使用其中一个辅助函数,我们可以很容易地拆分数据:

这里,我们希望将数据分为90%的训练数据、10%的测试数据,我们使用test_size=0.1来指定这两个数据。通过查看返回参数,我们注意到,最终我们得到90个训练数据点,10个测试数据点:

创建一个逻辑回归分类器的步骤与创建一个k-NN的步骤基本相同:

接下来,我们必须指定所需的训练方法。这里,我们可以选择cv2.ml.LogisticRegression_BATCH或者cv2.ml.LogisticRegression_MINI_BATH。现在,我们需要知道的是,我们希望在每个数据点之后都更新模型,这可以通过下列代码来实现:

我们还希望指定算法在终止前应该运行的迭代次数:

然后,我们可以调用对象的train方法(与前面的方法完全相同),它将在成功后返回True:

正如我们刚才看到的那样,训练阶段的目标是找到一组最佳权重,将特征值转换为一个输出标签。单个数据点由它的4个特征值(f 0 、f 1 、f 2 和f 3 )给出。因为我们有4个特征,所以我们还应该有4个权重,使得x = w 0 f 0 + w 1 f 1 + w 2 f 2 + w 3 f 3 ,而且ŷ = σ(x)。但是,如前所述,该算法增加了一个额外的权重,它作为偏移量或偏置,使得x = w 0 f 0 + w 1 f 1 + w 2 f 2 + w 3 f 3 + w 4 。我们可以重新得到这些权重,如下所示:

这就意味着逻辑函数的输入是x = –0.0409f 0 – 0.0191f 1 – 0.163f 2 + 0.287f 3 + 0.119。然后,在我们输入一个新的属于类1的数据点(f 0 、f 1 、f 2 和f 3 )时,输出ŷ = σ(x)应该接近于1。可是实际效果如何呢?
让我们来计算一下训练集的准确率得分:

完美得分!可是,这仅仅意味着该模型能够完美地记住训练数据集。这并不意味着该模型能够对一个未知的、新的数据点进行分类。为此,我们需要检查测试数据集:

很幸运,我们得到了另一个完美的得分!现在,我们可以确定我们建立的模型真的很棒。