
下载掌阅APP,畅读海量书库
立即打开



让我们先从计算机说起,计算机的启动流程分为如下三个阶段:

BIOS(Basic Input/Output System)程序是指固化到主板上BIOS芯片内的一段初始启动程序,是系统启动时运行的真正意义上的第一段程序。在计算机中,BIOS程序主要负责硬件自检和初始化、中断处理程序的基本设置,以及从存储器中加载零道零扇区的代码到内存并从该位置开始运行。而存储在外存零道零扇区的代码,通常就是所谓的引导程序了。
简而言之,引导程序就是用来引导操作系统的。由于多数操作系统都要存储在外存中而运行于内存。因此,需要一段小程序能够将操作系统从外存搬运到内存之中并交出CPU的控制权,这就是引导程序存在的意义。引导程序与操作系统有很大的关系,有些特定的引导程序只能引导特定的系统,但他们仍然不是操作系统本身。引导程序的作用就是给被引导的操作系统提供运行时所需的环境和条件,然后从外存中把真正的操作系统加载到内存中运行。
以上就是一个普通计算机的启动过程,但这样的过程并不一定适合于嵌入式系统。在很多嵌入式平台中,人们会将计算机的三个启动阶段简化为两个:

这里,引导程序通常会固化到Flash或ROM存储器中,当系统上电时会首先被运行,起到初始化基本硬件和引导操作系统的双重作用。
还有一些更加简单的嵌入式操作系统,不需要额外的引导程序就可以直接运行对硬件的初始化等工作,作为该操作系统的一部分而发挥作用。
以上是有关操作系统启动的最简要的介绍,有些读者可能会产生如下疑问,如果BIOS或引导程序已经对板载硬件完成了初始化,操作系统在被引导以后是否需要重复执行这个工作?例如,引导程序已经完成了串口设备的初始化工作,在操作系统运行时,是否需要重新初始化串口?
这个问题的答案不言而喻,操作系统是有必要对所有硬件重新进行初始化的。究其原因,可以总结为一点:我们不能让操作系统只适应于特定的引导程序,或者可以说我们希望任何引导程序都能引导我们的操作系统。但引导程序五花八门,有的简单,有的复杂,初始化过程又各不相同,如果将启动时需要进行的初始化任务全权交给引导程序负责,势必会降低操作系统的通用性,容易产生错误。因此比较保险的做法是,无论引导程序是如何初始化的,操作系统自身的初始化过程都要重新进行。
既然如此,那么就可以按照上述原则对操作系统从何处开始这一问题做界定了。我们的操作系统开始于一个基础代码可以运行的环境,处在板载硬件未被初始化的状态,也就是说,我们默认已有一个引导程序保证了我们的操作系统能够出现在内存中并且正确运行,但该引导程序不负责环境的任何初始化工作。
接下来我们就来聊聊ARM的启动。
ARM的启动其实再简单不过了。在CPU上电的时候,ARM就会首先从地址零处开始运行,第2章的几个例子程序都说明了这一点。因为是精简指令集,同时硬件结构较新,所以不需要考虑让人挠墙的历史兼容问题。这些都使程序在ARM体系结构下的启动变得简洁而自然。但是作为操作系统,我们不能简简单单地让程序能够运行就了事了。操作系统的根本目的之一是维护和保障其他程序能够依托本系统顺利工作。因此,区别于简单的裸机程序,操作系统在启动时应至少关心如下两个方面。
1.程序运行栈的初始化。程序的运行离不开栈,程序运行时所需的临时变量、数据、函数间调用的参数传递等都需要栈的支持。如果是在操作系统之上进行编程,堆栈的问题往往不需要程序员关心,但对于操作系统本身而言,需要对用户应用程序提供统一的运行环境和资源,堆栈的处理就不可避免了。因此操作系统在启动时,必须首先解决好堆栈的初始化问题。
2.处理器及外设的初始化。一个操作系统能够正常运行,处理器的正确配置和外设的正常工作也是必不可少的先决条件。例如,中断处理程序能够提供给操作系统非顺序的、突发的执行逻辑。时钟设备则可以产生固定频率的时钟驱动整个系统运行。所以在操作系统各功能模块得以发挥作用之前,处理器及外设也必须被初始化。
上述两条原则只是理论上的,不同的操作系统运行在不同的平台上,实现方法可能各不相同,但无论如何这两条原则都是要遵守的。
接下来我们来看一段例子,研究一下ARM体系结构下的操作系统在初始化的过程当中,应该如何实现。
代码3-1
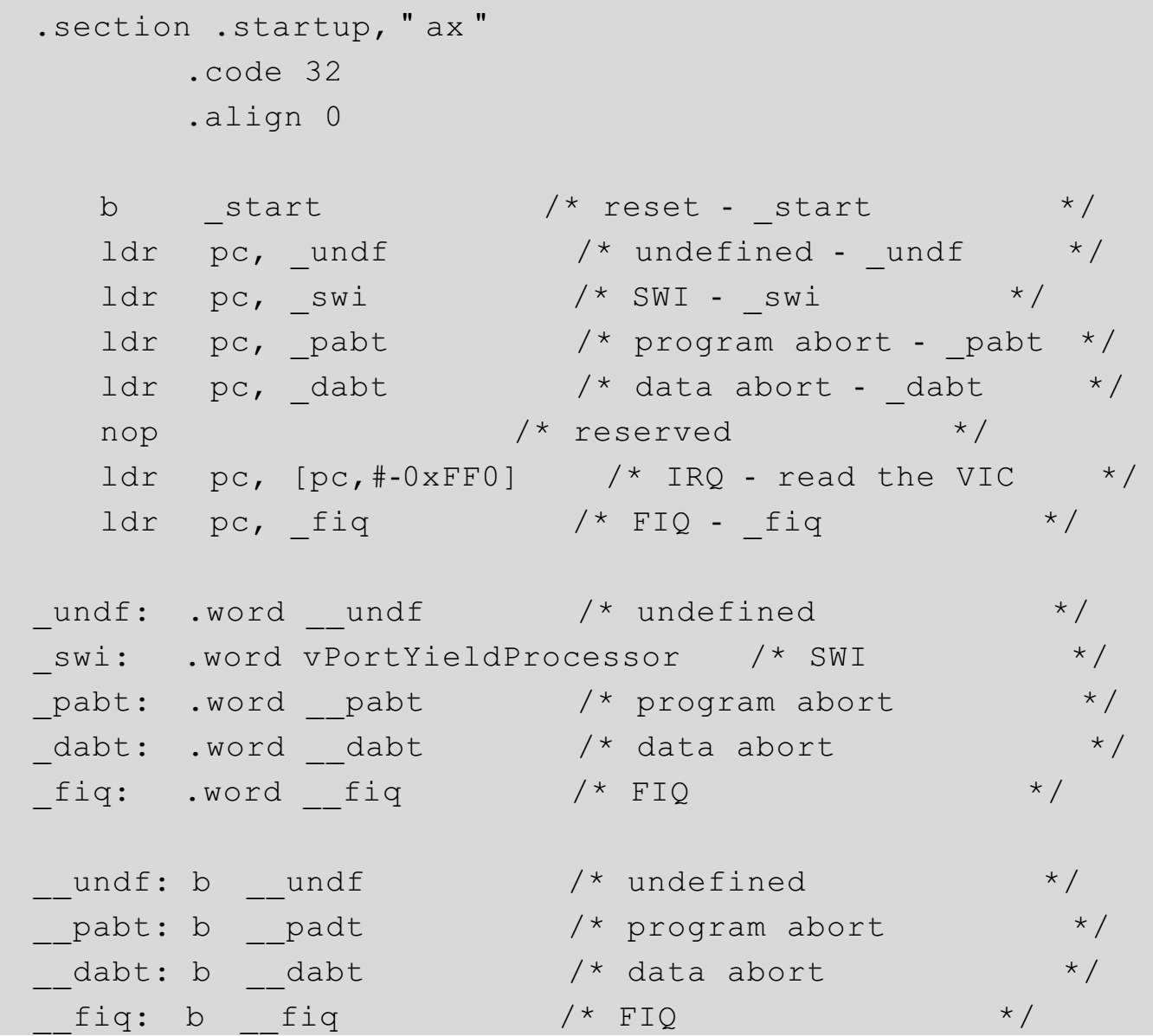
这一段代码节选自开源嵌入式操作系统freeRTOS的初始化部分,与该段代码类似的初始化方式广泛应用于支持ARM的各种类型的操作系统和引导程序中,因此非常具有代表性。
代码一开始使用了三条伪指令,其中,.align的含义和用法我们已经介绍过了(参见第2章)。
.section的作用是声明接下来的代码属于该段,其格式为.sectionname[, "flags"]或.section name[, subsection]。代码3-1中采用的是第一种形式,将整段代码编译到startup段中,该段也是整个操作系统的入口。而方括号内的内容是可选的,代码中该标志被定义为ax,其中的“a”代表可重定位(section is allocatable),而“x”的意思是可执行(section is executable)。
另一个伪指令.code 32的作用是编译生成32位指令集的代码。.code的另一种形式是.code 16,其作用是生成16位指令集的代码。伪指令.arm以及.thumb分别与.code 32和.code 16效果相同。我们知道,在传统的ARM体系结构中既可以使用32位的指令,又可以使用16位的指令,此处正好与ARM的这套指令系统相统一。
接下来,代码3-1将执行该程序的第一条指令—跳转指令,通过该指令程序将直接跳转至_start处继续运行。既然如此,紧接着跳转指令的其他指令在什么情况下才能运行呢?熟悉ARM体系结构的读者可能清楚,包括第一条指令在内,这段代码正是异常向量表。也就是说,所有其他指令都会在异常模式发生时才会运行。
对ARM不了解的读者可能会问,异常模式是何物?简单地说,异常模式就是程序由于某种原因执行不正常时,系统所处于的一种运行模式。当异常模式出现时,预先指定的代码将会被运行,从而可以尽可能地解决异常并返回到正常模式中。
在ARM v6及以前的体系中定义了七种模式,分别是管理模式(SVC)、快速中断模式(FIQ)、中断模式(IRQ)、未定义模式(UND)、终止模式(ABT)、用户模式(USR)以及系统模式(SYS)。其中,前五种就是所谓的异常模式。每一种异常模式都拥有私有的堆栈指针寄存器R13、返回地址寄存器R14以及模式备份寄存器SPSR。一段代码只有处在该异常模式下时才有权力访问属于该异常模式的这三个私有寄存器。当某种异常发生时,CPU会立刻停止当前正在执行的动作,转而去运行预先指定的代码,同时,系统会切换到特定模式中,这是一种被动的模式切换方法。除此之外,程序员还可以通过编程主动进行模式切换,使用的方法是更改CPSR寄存器中的模式位。有关异常模式的细节我们将会在第5章详细阐述。
既然程序在启动时,就立刻跳转到_start处运行,那么在_start位置上freeRTOS又做了哪些工作呢?我们接着来看_start处的代码。
代码 3-2

代码3-2从_start处开始,一步步进行栈指针和bss段的初始化工作,最终通过一条bl指令跳转到主程序处继续运行。示例代码删减了相对重复和不具有代表性的内容,以使代码结构更清晰。
程序一开始,将局部变量.LC6的值加载到寄存器中,也就是__stack_end__这一变量的值。从名字上我们可以判断出,该值应该是程序堆栈的顶端。问题似乎随之而来,从理论上讲,任何CPU都必须使用一个专有寄存器来指向程序当前的堆栈地址。在ARM中寄存器R13充当了这一角色,在x86下,我们可以通过ESP寄存器实现类似的功能。无论什么体系结构,在处理堆栈指针寄存器时都必须面对两个问题:堆栈如何增长?堆栈为满堆栈还是空堆栈?
图3-1直观地描述了这两个问题的四种组合情况,所谓堆栈如何增长,指的是堆栈指针更新时,是向着高地址方向还是低地址方向,而所谓满堆栈和空堆栈,指的是当程序利用堆栈指针向堆栈中存储数据或从堆栈中提取数据时,是先将数据存入或读出再更新堆栈指针还是先更新堆栈指针,然后再存取数据,也就是说,当前堆栈指针是否指向了有效数据。因此,堆栈的处理方法可以总结为四种,分别为空递增堆栈、满递增堆栈、空递减堆栈、满递减堆栈。读者可以将这四种处理方法在图3-1中一一对号入座。
其实无论堆栈的处理有多少种方法,只要保证所有的函数在保存局部变量或相互调用过程中始终使用同一种处理方法,程序的运行就不会出问题。因为堆栈的使用在汇编语言下是可控的,也就是说,数据向堆栈的存取和堆栈指针寄存器的更新是需要程序员自行处理的。因此,如果所有的程序都使用汇编写成,我们可以直接选择一种处理方式来处理堆栈,就不会出问题了。但如果使用其他语言编程,堆栈的处理已经被编译器屏蔽,程序员并不知道编译器选择了哪种方式,这样编译出来的程序就会存在隐患。例如,使用C语言编程,并且编译器是按照满递减的方式处理源代码的,但我们却错误地在操作系统初始化时将堆栈指针寄存器设置成内存的最低地址,一旦该程序使用堆栈,便会出现数据异常的情况。
那这个问题该如何解决呢?答案是,通过过程调用标准来解决。
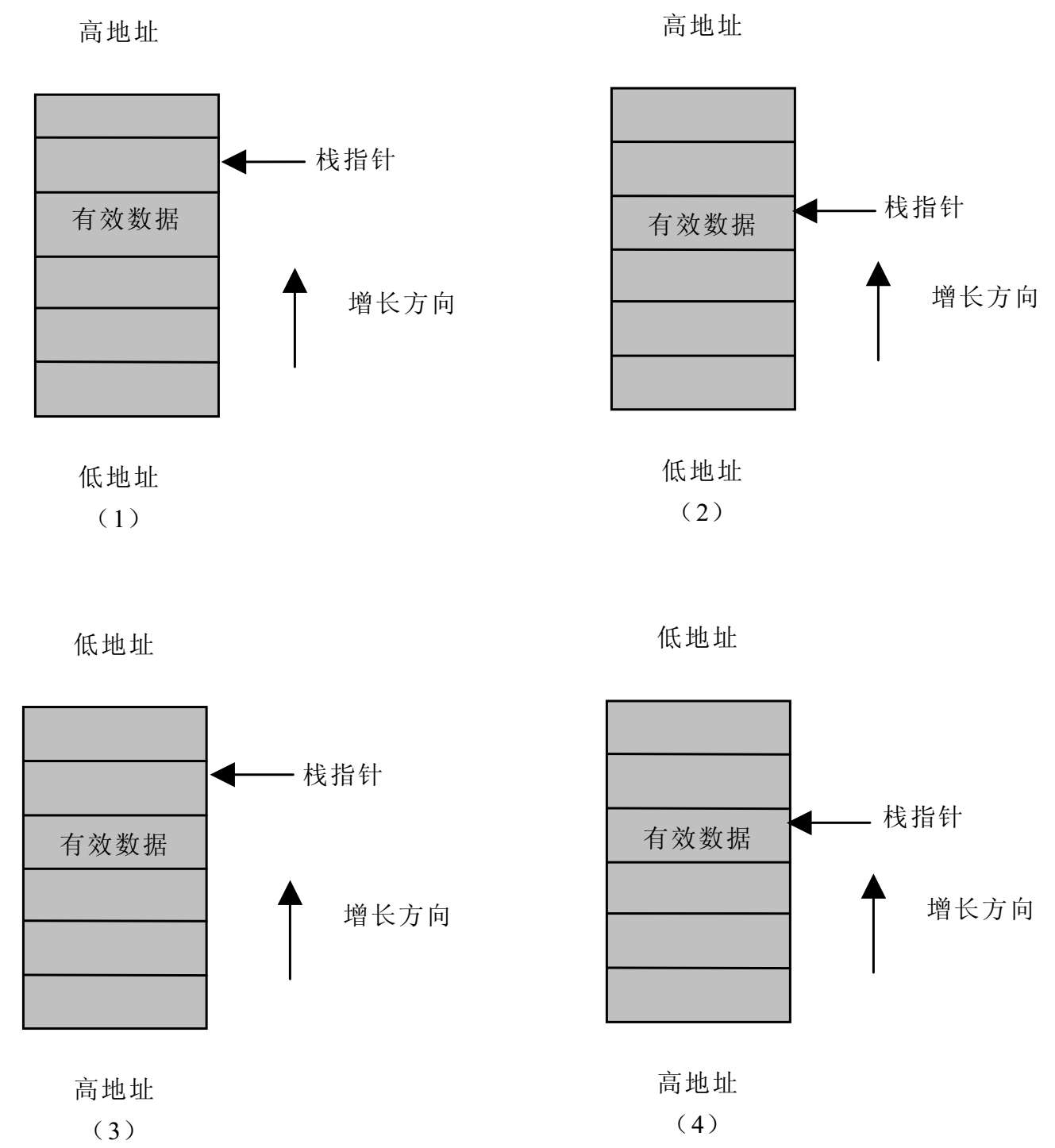
图3-1 堆栈的四种处理方法
回想一下我们前面的介绍,过程调用标准规定了程序间相互调用时所要遵守的规则,无论程序来源于哪、使用什么语言写成,只要共同遵守某一规则,程序间就可以相安无事、各司其职。也就是说,堆栈工作方式在过程调用标准当中会被明确地规定。AAPCS中明确指出使用满递减堆栈方式处理堆栈。这表示操作系统在堆栈初始化阶段,必须将堆栈指针寄存器赋予一个高端的内存地址值,在代码3-2中,该值是内存的最高地址值减4。
回到代码3-2中,R0被赋值之后,紧接着程序通过一条msr指令更改当前处理器模式为未定义指令模式。在ARM的7种处理器模式中,除用户模式和系统模式共用一个R13寄存器外,其他异常模式都有独立的R13寄存器,这表示各模式的堆栈是彼此独立的。同时,因为不同模式之间的私有寄存器不能够互相访问,因此,想要对不同模式的R13寄存器分别进行初始化,必须首先切换到相应模式中,然后再对R13寄存器赋值。而msr指令便能实现模式切换,其完整格式如下。
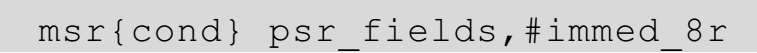
或

显然,代码3-2采用的是第一种格式,将一个立即数赋值给CPSR寄存器的控制域,其结果是将处理器模式由启动时默认的SVC模式切换到未定义模式。在未定义模式中,程序将寄存器R0的值赋给堆栈指针寄存器SP,从而完成了一次异常模式的堆栈初始化工作。接下来,类似的代码被重复执行,最终完成处理器各个模式的堆栈初始化。
在完成堆栈初始化后,代码3-2进入下一阶段,清除掉bss段的数据。bss段通常是用来存放程序中未初始化或初始值为零的全局变量或静态变量的一块内存区域。与data段不同,bss段内的所有数据都没有初始值或初始值为零。也就是说,在编译程序的过程中,没有必要将bss段的内容生成在可执行程序中,这意味着如果我们将无所谓初始值的变量都空下来不赋值或赋值为零,将会大大减少可执行程序的尺寸,这一点对于对文件大小敏感的程序来说很有意义。当然,有利必有弊,虽然存储空间被节省了,可是这些变量的初始值就不得不在运行时赋值了。换句话说,程序的启动速度会受到一定程度的影响。
有些读者可能会有这样的疑问,对于那些没有初始值的数据,是不是有必要仍然将其初始化成零?其实,这是C语言标准所规定的,所有的变量都应该被初始化。具体地说,所有的指针都应该被初始化为空指针,所有的算术类型数据,都应该被初始化成零。正因为如此,即使程序在整个运行期间不会使用零这个值,在操作系统启动的过程中,却仍然需要对bss段进行初始化。
于是在代码3-2里,程序将bss段起始地址和结束地址读出,并算出bss段的大小,然后在.clear_loop循环内,逐个对bss段的内容赋值。其中用到的一些汇编指令是前面没有提过的,下面具体介绍一下。
(1)sub指令是减法指令,几乎所有的体系结构都支持这种指令并使用同样的指令助记符。我们在这里看到的减法指令稍有变化,是在sub后边又多加了一个s,意思是根据该指令运行的结果来更新CPSR寄存器的标志位。减法指令的标准格式是:sub{<cond>}{s} Rd,Rn,N。它可以将寄存器Rn减N的结果保存在寄存器Rd中,并且根据是否带有后缀s来选择更改标志位。举例来说,“subs r3,r3,#1”将会使R3寄存器的值减一,当减到零时,CPSR中的零标志位会被置1。
(2)b指令是我们早已熟悉的了,但是b后边的gt后缀我们却是头一次接触。这里的gt充当了条件助记符的作用,表示如果“有符号数大于”这一条件发生时便执行跳转。这里所谓的“有符号数大于”针对的是上一条减法指令。无论Rn和N是正是负,当二者相减的结果大于零时,该条件就会发生。而在代码3-2中,这一条件其实是表示R3的值并未递减到零,因此需要跳转回.clear_loop处继续将下一个位置清零,直至bss段末尾。
代码3-2中有一个细节需要注意,那就是.word伪指令。这个伪指令可以用来在内存中分配一个4字节的空间,并可以同时对其初始化。例如,代码中的“.LC6: .word __stack_end__”,就是在定义空间的同时,又向该空间赋予了__stack_end__这一变量的值,这样就可以直接在程序中引用.LC6了。
在所有初始化过程完成后,程序跳转到main函数处继续接下来的工作。
对于freeRTOS来说,程序在进入main函数后立即执行prvSetupHardware函数,完成特定硬件平台的初始化工作,这些初始化工作因为与平台相关,因此程序本身不具有代表性,但程序执行的基本流程仍然是确定的,总结起来有如下两个方面。
(1)时钟初始化。时钟的频率直接决定了CPU的性能,因此如果条件允许,我们都会尽量提高CPU的时钟频率,从而提高效率。但是这样,问题也就来了,一般CPU内部时钟都是可编程的,时钟的本源往往来源于外部晶振,很多CPU允许外接的晶振频率是可选的,而我们必须根据晶振的频率计算出相应的值来产生正确的CPU时钟。因此,CPU通常不是一上电就立刻工作在一个较高的频率下的,而是首先以一个相对较低的频率运行,之后通过编程的方法进行配置,才可以使用高频时钟。除此之外,CPU内部集成的外围器件或控制器也需要不同频率的时钟,这些时钟频率远远低于CPU的工作频率,因此需要通过分频的方法获得。无论怎样,时钟就是机器的心跳,是不可或缺的。对时钟的初始化几乎是任何一款操作系统初始化阶段的必要步骤。
(2)内存初始化。多数CPU与内存的耦合程度并不是特别紧密。通俗地讲,多数CPU不需要特别复杂的硬件辅助就可以直接与内存连接。但是,这不能表示已经连接上的内存处于一个可用或者好用的状态。不同的内存芯片、厂商、型号类型在不同的板子上都是不同的,通常我们需要根据实际情况,专门对内存进行配置以适应这种环境。由于内存在没有正确配置之前很可能不能正常使用,或者仅能以很低的效率被使用。因此,初始化内存就成了操作系统初始化时又一必不可少的工作。
除了上述必须完成的工作之外,一款成熟的操作系统还可能包含一些可选的初始化步骤,比如输入输出设备、存储设备的初始化等。只有操作系统赖以生存的环境被正确并且完整的配置后,操作系统才能发挥出它真正的威力。
前面我们分析了一段基于ARM的典型初始化程序并总结了系统初始化的一般步骤,做到了知其然并知其所以然。接下来就利用我们学到的知识和原理,正式开始编写属于我们自己的操作系统。请打开一款代码编辑器,并输入下面这段代码。
代码3-3
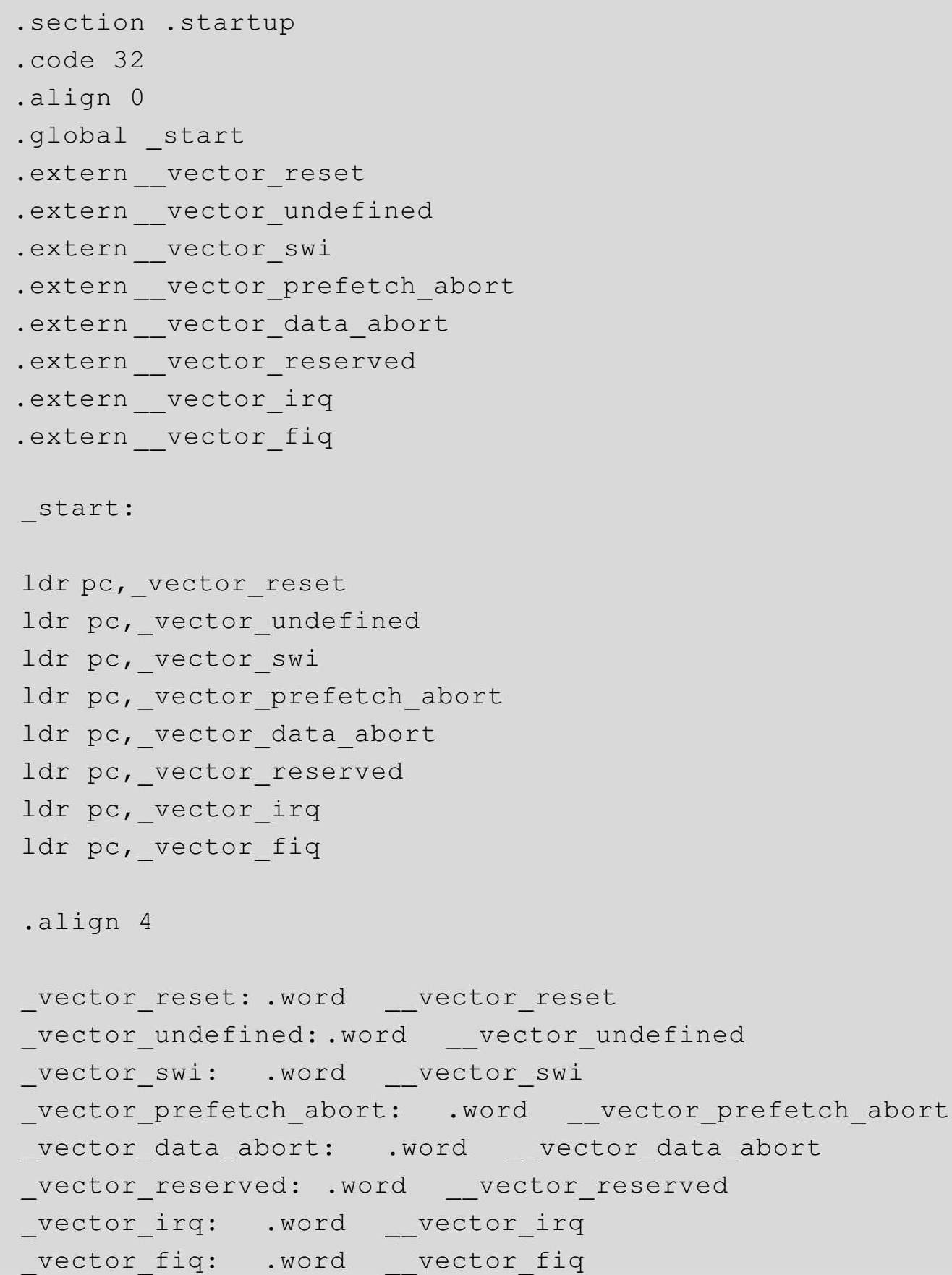
有些读者可能已经意识到,以前从未接触过或很少接触的汇编程序,现在看起来似乎已非常简单。这说明我们已经在实践中掌握了一定的ARM汇编知识。
这段代码我们无须解释,但需要辨析一下不同的跳转指令之间的区别。在ARM汇编程序中,要实现程序间跳转有三种方法可供使用:
(1)使用跳转指令b、bl、bx等。使用这一系列指令的优点是执行速度快,只需要一个指令周期即可完成跳转。但该系列指令有一个明显的缺点,那就是它们都不能实现对任意地址的跳转。比如说程序在地址0x0处运行了跳转指令,但是该指令不能跳转到0xc0000000处去运行,这是由ARM指令等宽特性决定的。ARM指令集是32位等长的,所以,所有的指令(包括指令的参数在内)都必须在4字节的范围内完成。这样,当一条指令需要附带一个立即数或一个地址值作为参数时,该立即数或地址值必然要小于32位。事实上,跳转指令b所能跳转的最大范围是当前指令地址前后的32M。
(2)使用内存装载指令,将存储在内存的某一地址装载到程序计数器PC中。例如,若我们将跳转的目的地址存储在高于当前地址24字节处,就可以使用“ldr pc,[pc,#24]”这条指令实现跳转。当然,在实际编码中,我们并不一定要亲自做这种偏移量的计算,而可以采用代码3-3的方法,用一条ldr伪指令来实现。这样,编译器会根据情况将该指令展开成b指令或ldr指令。ldr指令能够实现任意地址的跳转,但因为需要读写存储器,所以在执行速度上与b指令相比就稍逊一筹了。
(3)第三种跳转方法是通过mov指令来实现的。mov指令是最简单的移动指令,几乎所有的处理器都包含这条指令。通过mov指令将已经保存到某一寄存器中的地址值直接赋值给程序计数器PC,也可以实现程序跳转。使用该方法仍然需要额外的指令或别的手段,将跳转地址预先保存到寄存器中。因此这种方法多用在函数返回时的跳转中。
了解了ARM中的跳转方法之后,相信读者已能在编程过程中灵活应用它们了。但是,代码3-3是只有当异常模式发生时才会运行的。正常情况下,程序一开始就会马上跳转到__vector_reset处运行。
下面就让我们跟随程序的执行过程,继续完善我们的操作系统。
代码3-4

在正常模式下,程序会进入__vector_reset并运行,而后分别进行堆栈寄存器的初始化和bss段的清除工作。这里有一个细节需要强调,那就是对__bss_start__和__bss_end__两个变量的定义,在代码3-4的开始部分我们用.extern关键字声明了这两个变量,这表明这些变量来自于别处。但问题是bss段的开始和结束的位置是动态的,程序稍有修改就会产生变化,因此我们很难确定一个固定的值。那么这两个值到底是如何确定的呢?
答案是,由编译器确定。回想一下第2章关于链接脚本的内容,bss段、data段和text段的具体位置都是在链接脚本中指定的,也就是说,编译器在编译的时候会计算每段程序的代码、未初始化的全局变量和已经初始化的全局变量,并根据链接脚本安排各段的大小和位置。
读者也许还是会问,就算能够确定bss段的起始位置和结束位置,那这两个值又是如何传递的呢?
这个问题的答案还是在于链接脚本,看看下面这段代码,读者朋友们就会明白了。
代码3-5

读者可能已经在代码3-5中发现了__bss_start__和__bss_end__两个变量。在这段链接脚本中,我们将__bss_start__变量赋予了当前位置值,紧接着的就是bss段。因此,__bss_start__变量恰好代表了bss段的起始地址,而__bss_end__变量也是通过同样的方式赋值的,最终这两个变量在代码3-4中被引用。
回到代码3-4中,在对bss段的清零工作完成后,代码通过一条跳转指令跳转到函数plat_boot处执行,开始外围硬件的初始化工作。
由于操作系统在设计之初就兼顾了自身的可移植性,因此,板载硬件的初始化工作对于不同的平台,虽然毫无相同之处,但却必须要追求一种统一。这种不同平台的统一其实是一种抽象,在程序设计当中,好的抽象能够以最高的效率、通过最少的代码修改实现最大程度的兼容,可以说软件设计能力其实就是一种抽象能力。可能有些读者会觉得我的这段话也很抽象,那就让我们直接看代码,体会一下抽象软件设计的优势吧。
代码3-6

这段代码其实很简单,首先在程序中定义了一个名为init、类型为init_func的数组。init_func类型其实是一种函数类型,其定义如下:
代码3-7

从定义中我们可以看出,init_func类型的函数既没有参数也没有返回值。初始化函数不需要参数,是因为它们只需要被调用一次,并不需要通过参数的动态改变来执行内容,也不需要返回值,因为这些函数都不允许执行失败,即便能够返回执行失败的结果,在初始化阶段也没有能力补救。但不管怎样,正是init数组中的各个成员函数完成了对各种硬件的具体的初始化工作。在plat_boot函数中,将init数组作为参数传递给了load_init_boot函数,而该函数便是这个数组成员函数的实施者,让我们来看一下这个函数的具体实现:
代码3-8

函数通过for循环依次运行init数组中的成员函数,最终调用boot_start()函数,至此,操作系统的初始化过程结束。
这段程序之所以这样设计主要是从体系结构相关性这个角度考虑的。代码3-8中的函数就是一个与体现结构无关的函数,无论我们的代码运行在什么硬件平台下,load_init_boot都可以被重复使用。而init_func数组是与体系结构相关的,因此当我们需要支持新的体系结构,或者更改原有体系结构的代码时,只需要重写或修改init_func数组实现其内部相关函数即可。我们所说的最基本的抽象指的就是这个。将各硬件平台都要实施的部分提炼出来,供所有体系结构复用,并将各平台独有的部分交给平台相关代码随意实现,从而在一定程度上解决了平台间移植的问题。
目前我们已经完成了操作系统初始化的第一阶段。现在不如让我们暂时停下来,整理并运行一下前边学习到的代码。
首先需要做的是将代码3-3的内容保存成文件,命名为start.s。
为了节省篇幅,在代码3-4中我们只列出了核心程序,许多宏定义并没有列出来。为了使这段代码能够运行,我们需要在代码3-4最开头的地方添加如下内容:
代码3-9
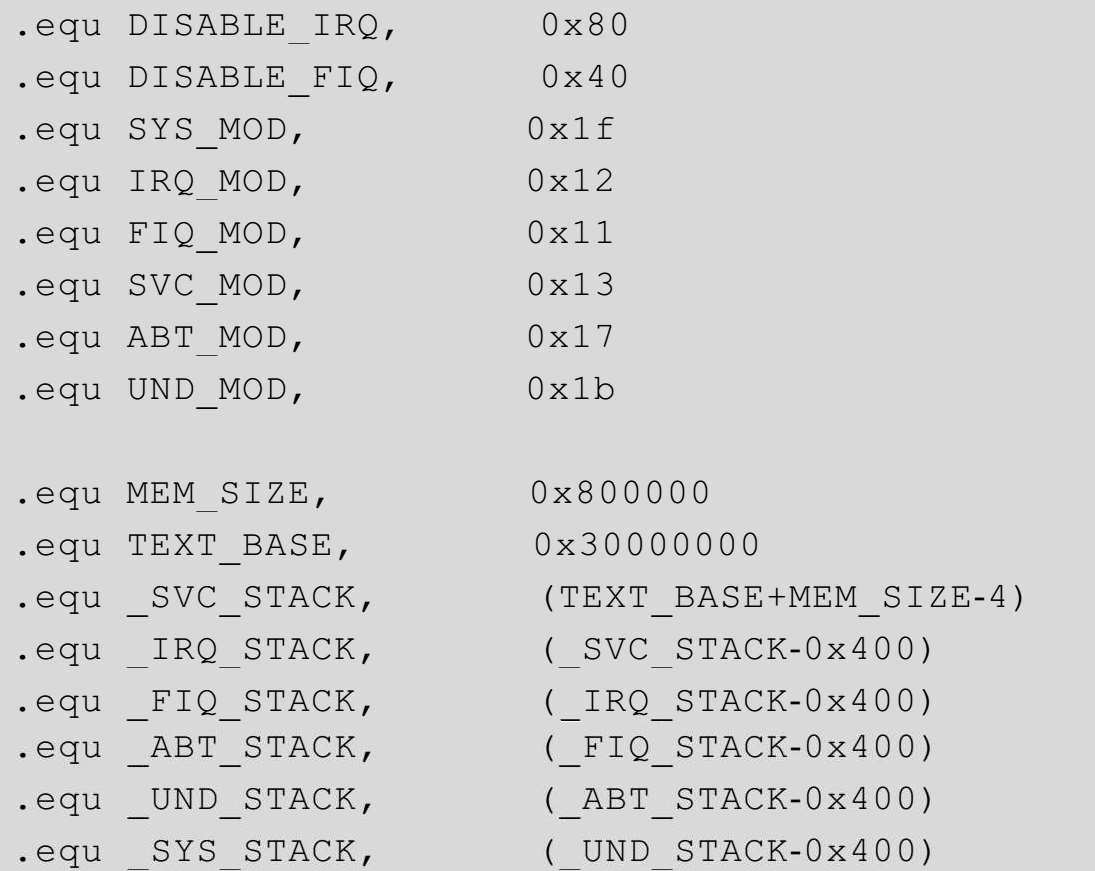
在代码3-9中,程序主要定义了两类宏。
一类是与处理器模式和中断有关的,我们可以使用这些宏来方便地在不同模式间切换,同时使能或禁止中断。这些细节我们会在后续的学习中详细讲解。
另一类宏定义则是与内存有关的。根据2410的芯片手册,外部sdram可以接在起始地址为0x30000000的位置上,我们虚拟的内存便是从这一地址开始的,并假设内存总容量为8M。这样,我们选取SVC模式堆栈的最顶端为内存的最后一个字节(即0x30000000+0x800000-4),并给其分配1K的堆栈空间供该模式使用,其他模式的堆栈空间大小同样为1K,位置依次排列。我们将代码3-9与代码3-4的内容保存成文件,命名为“init.s”。
在代码3-3中,程序通过.extern关键字声明了很多外部变量,但这些变量并未定义。于是我们需要新建一个文件并将这些变量的定义写进去,其内容如下:
代码3-10
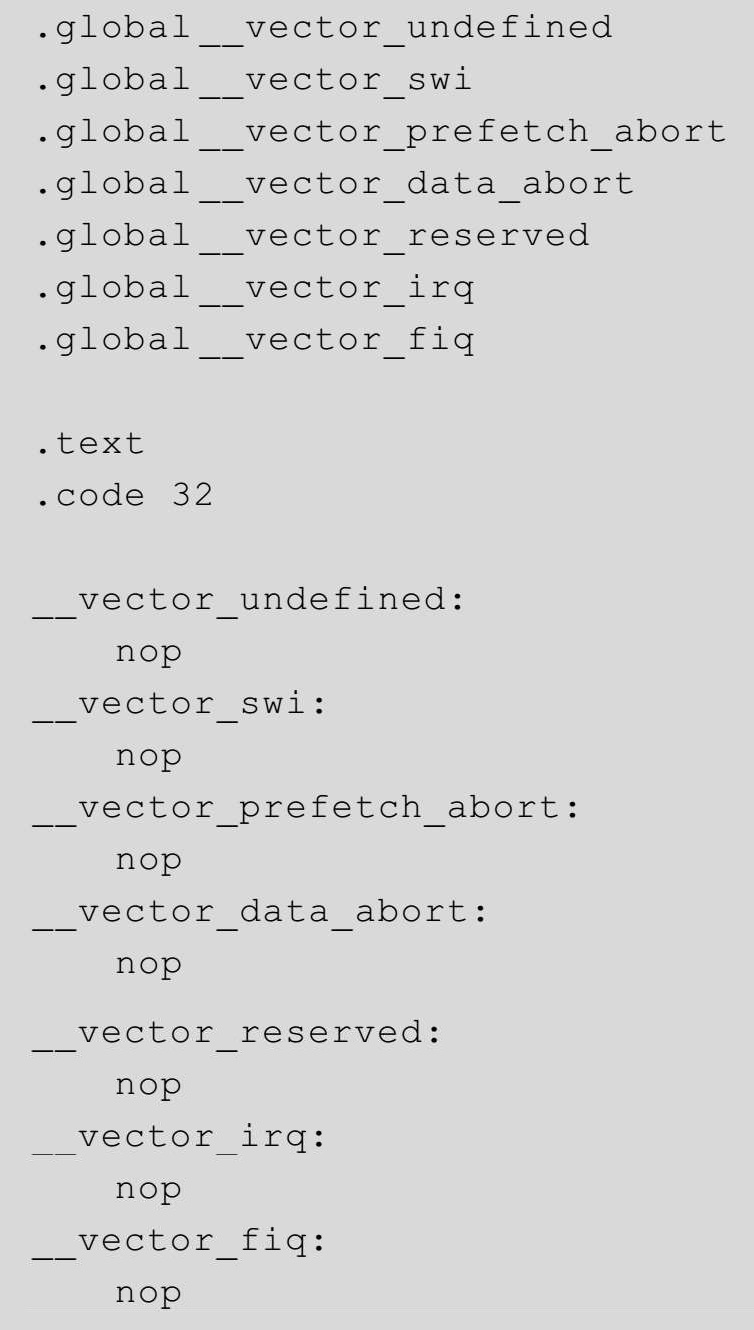
这里我们只需要将这段代码复制到文件中,命名为“abnormal.s”。代码3-10还有一条指令,那就是nop指令。其实这条指令在这里根本没有什么作用,只是在执行的时候能够消耗掉一个指令周期。此时我们尚未涉及到异常模式的处理,所以使用nop指令,权当占个位置,在讲到异常模式的时候,我们会进一步改写这些异常处理函数。
为了能够运行这部分程序,我们需要临时将代码3-6、代码3-7和代码3-8改写一下,并使用我们在第2章中编写的helloworld函数来验证操作系统初始化部分的运行进度。
代码3-11
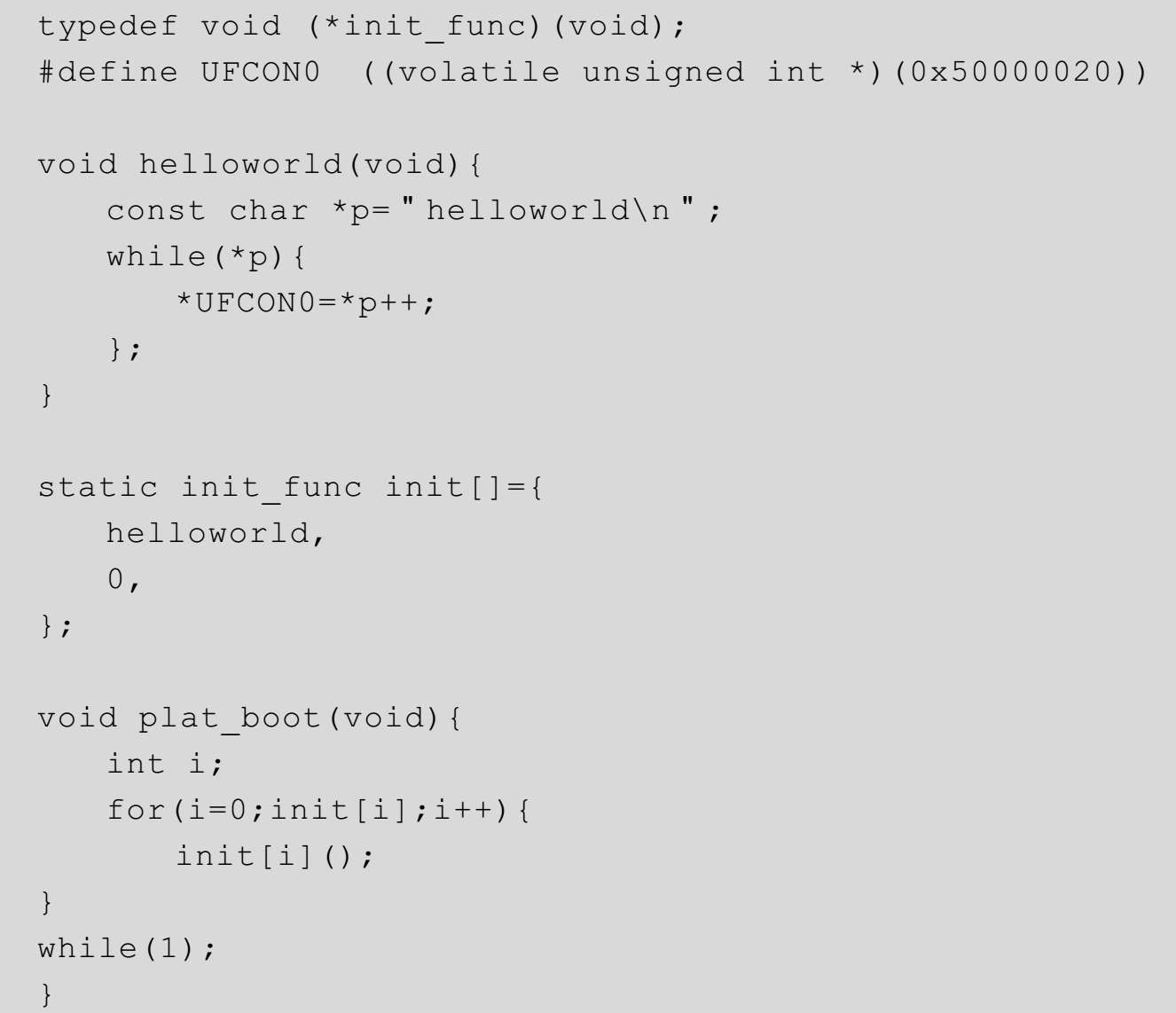
在代码3-11中,原本是应该填写启动函数的init数组,现在只填写了一个helloworld函数,目的仅是看到操作系统启动时的运行现象。我们将代码3-11保存到文件中,命名为“boot.c”。
接着将代码3-5的内容保存到文件中,将其命名为“leeos.lds”。
编译过程非常简单,我们需要写一个Makefile文件,将代码3-12的内容保存成文件,与源代码放在同一目录下,命名为Makefile。
代码 3-12
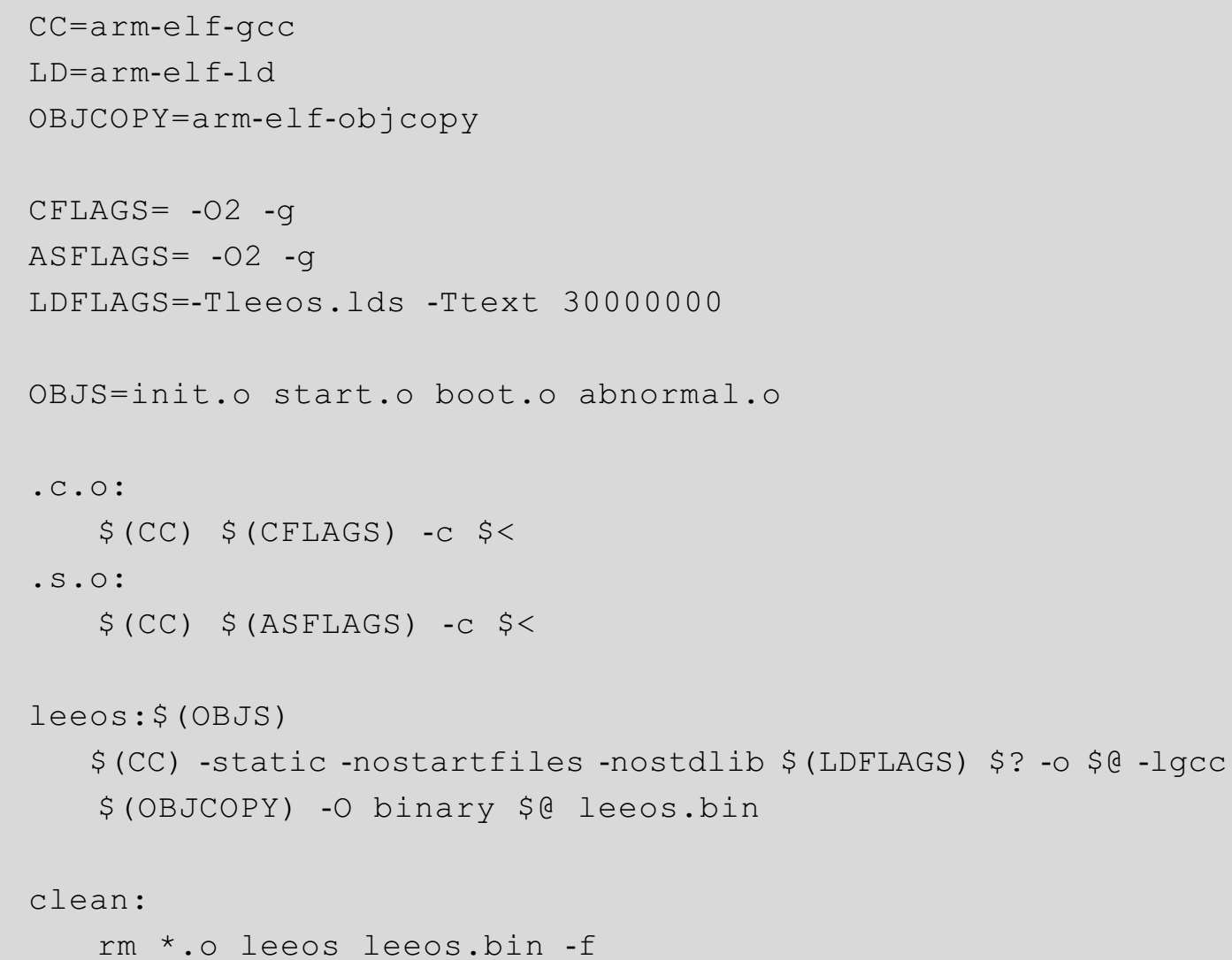
在确认所有文件都处在同一目录下后,只需要在终端上运行make这条命令,最终将会生成二进制文件“leeos.bin”。
当然,如果需要在skyeye中虚拟运行,还有一个文件是我们需要的,那就是“skyeye.conf”文件,不同于第2章的配置文件,这里的skyeye.conf的内容稍有变化,如下所示。

因为在代码中,我们已经假设内存起始于地址0x30000000处,大小为0x00800000。为保证代码能够成功运行,我们必须虚拟出一块内存,起始位置和大小恰与代码一致。
现在万事俱备了,在终端运行skyeye命令,将可以看到helloworld字符串从skyeye中打印出来:

看到这个结果,不能不让人兴奋,虽然该结果与第2章相比没有什么变化。但从代码实现上看,二者有本质区别,其意义完全不同。我们现在正在一步步地将我们所学的知识转化为实践,逐步打造属于自己的嵌入式操作系统!
当然,现在就沾沾自喜还为时过早。接下来我们就来啃一块硬骨头— MMU。这一部分内容,相对来说是比较具有挑战性的。如果您的ARM基础相对薄弱,或者读过前面的内容之后仍然是一知半解,不妨暂时略过这一节,继续阅读接下来的内容。