
下载掌阅APP,畅读海量书库
立即打开



2.1 我们如何获得网站的数据 |

|
当我们试图从各种网站分析的报表中解读各种指标和数据的时候,需要去了解它们的定义(Definition)和计算规则(Computation Rule),其中必须要具备的基础知识就是在网站中通常以何种方式获取数据。下面就介绍数据获取的基本方式,以及原始数据是以何种形式存在的。
其实网站的数据统计(早期叫流量统计)由来已久,因为网站管理员需要了解和监控网站的访问状况,通常需要记录和统计网站流量的基础数据,但随着网站在技术和运营上的不断发展,人们对数据的要求越来越高,以求实现更加精细的运营来提升网站的质量,所以网站的数据获取方式也随着网站技术的进步和人们对网站数据需求的加深而不断地发展。从使用发展的情况来看,主要分为3类: 网站日志文件(Log Files)、Web Beacons(俗称打点)、JS页面标记(JavaScript Tags) 。其实这3种数据获取方式也反映了一个进阶的过程,从网站日志到JS标记,每一项后面使用的技术都是对前面技术的部分沿用和改进,规避之前技术可能存在的一些缺陷和不足,我们可以大致了解一下数据获取(Data Capture)的基本知识和发展过程。
网站日志文件
记录网站日志文件的方式是最原始的数据获取方式,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能就能实现,如图2-1所示。
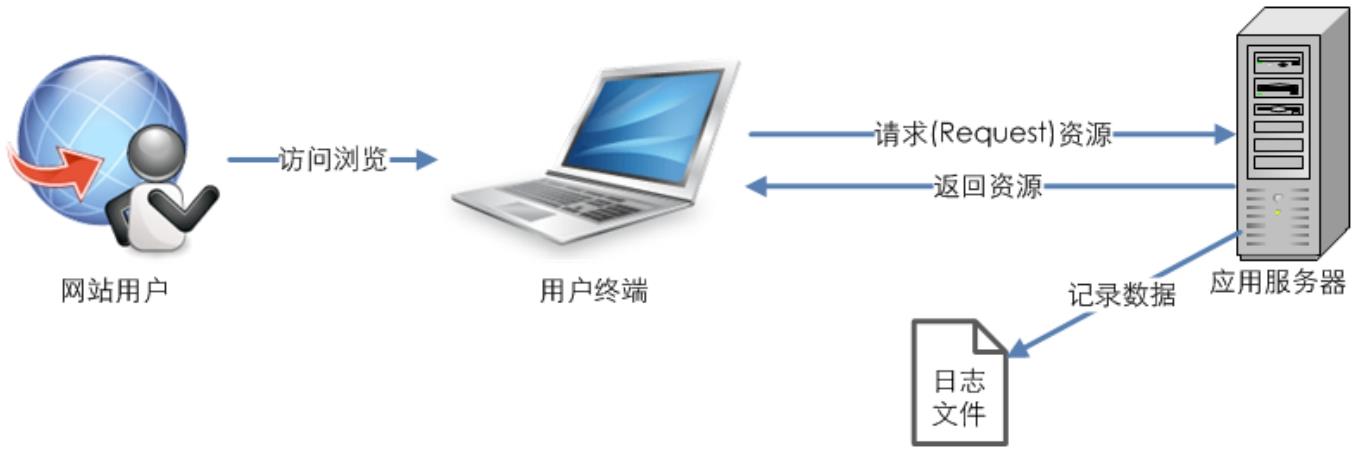
图2-1 网站日志文件数据获取方式
网站的应用服务器输出的日志所记录的其实是用户终端为了满足用户的访问需要,对服务器发起的所有的资源请求,这些资源请求不仅包含页面请求,页面展现的所有相关元素请求也会被记录,如图片、CSS、文件(Flash、视频、音乐等),另外一些iframe也会被当成请求记录。所以原始的日志文件记录了很多统计中用不到的内容,这些内容产生的筛选和过滤工作带来了巨大成本,同时导致了统计数据的不准确。日志文件的另外一个缺陷就是由于数据获取在服务端进行,很多用户在页面端的操作(如点击、Ajax的使用等)无法被记录,限制了一些指标的统计和计算。
Web Beacons
为了避免网站日志文件形式给应用服务器带来的额外压力,以及过量的日志记录导致数据筛选过滤的成本,于是就出现了Web Beacons的数据获取方式,貌似还没有正规的中文翻译,一般被称为打点。Web Beacons的实现方式是在需要统计的网站页面或者模块上嵌入一个1×1像素的透明图片,用户完全察觉不到,当用户访问该网页的同时会请求透明图片,并完成页面访问的记录工作,就像是在纸上画了一个不易看到的小点来标记那张纸,如图2-2所示。
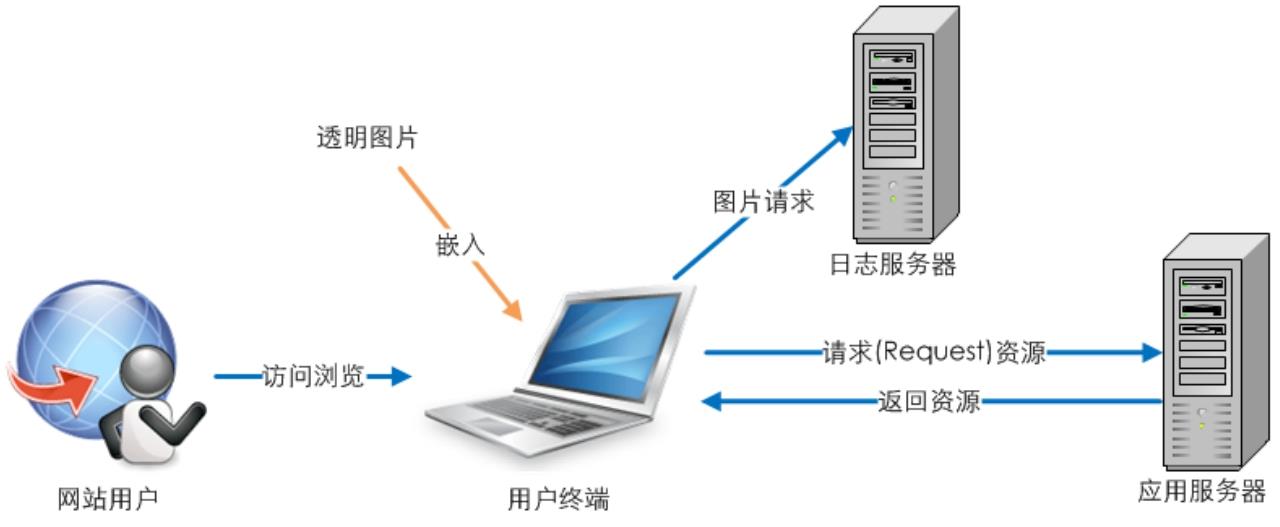
图2-2 Web Beacons数据获取方式
Web Beacons的方式实现了日志记录服务器与网站应用服务器的分离,使用独立的日志记录和处理服务器避免了应用服务器的额外压力,而且可控的图片嵌入方式大幅度降低了日志记录数(对于一般的网站页面而言,当请求一个页面时,传统网站日志记录数是6到10条,也就是说,使用Web Beacons的方式记录的日志数量大约只有原始服务器日志的1/8,传统的流量统计工具如AWStats、Webalizer等用Hits这个指标来记录原始记录数,一般是正常页面浏览PV的6到10倍,对于某些复杂的站点甚至是20多倍),保证了数据统计的效率和准确性。
而Web Beacons的最大劣势就是获取信息的有限性,尤其是记录的来源页面(Referral)为图片所在的页面,而不是该页面的前一个页面,同时由于与网站应用服务器分离,用户cookie等信息的记录也有可能丢失。所以单纯使用Web Beacons的形式无法完全获取网站分析指标需要的信息,于是就出现了JS页面标记。
JS页面标记
JS页面标记同样是对Web Beacons的改进,弥补Web Beacons在信息获取上的不足。JS页面标记同样需要在页面端进行处理,只是嵌入的不再是图片,而是JS标记代码,当用户访问网页时同时出发并执行JS代码,JS代码会将一些统计需要的信息以URL参数的形式附带在图片请求地址的后面,然后再向日志服务器请求图片,这样日志服务器就可以获取比较完整的访问数据。如图2-3所示。
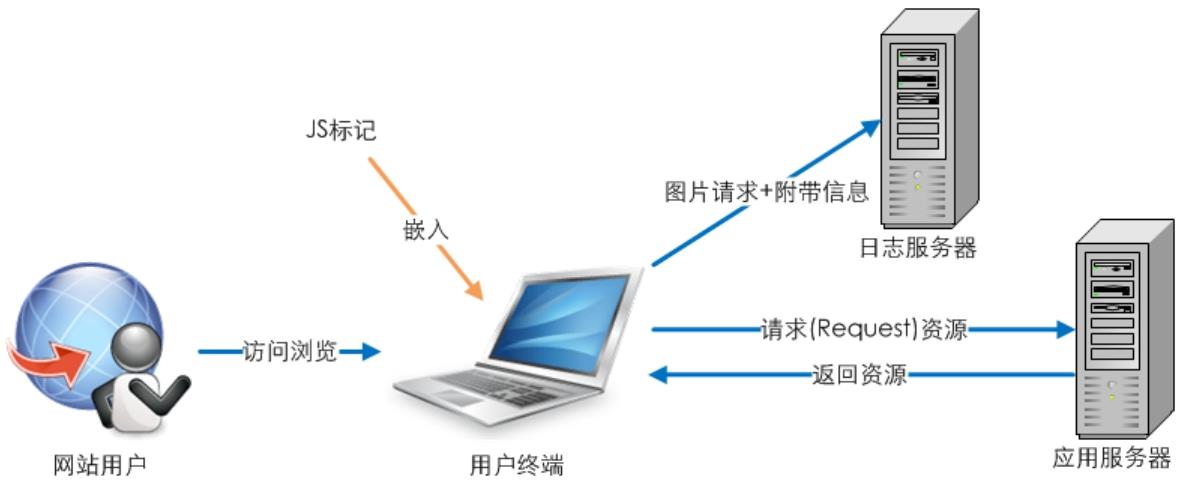
图2-3 JS页面标记数据获取方式
JS页面标记的方式具备了数据获取的灵活性和可控性,以及获取信息的完整性等优势,同时可以监控页面端的各种操作,如点击、Ajax等,唯一的缺点就是当用户禁用JS功能时,所有的信息将无法获取。
通过以上对三类数据获取方式的介绍,我们可以来比较下它们的优缺点,见表2-1。
表2-1 三种数据获取方式的比较

所以,JS页面标记方式因为其使用灵活性、可获取数据的丰富度和统计得到的指标的相对准确性成为目前最常用的一种数据获取方式。下面来简单比较一下网站的日志文件和JS标记所获取的数据具备哪些信息、记录的方式有何不同。
其实无论是哪种数据获取方式,最终的输出形式都是网站日志,只是原始日志输出的是既定的记录,而JS页面标记输出的是执行过JS代码经过处理的图片日志请求记录,所以我们不妨先来看下网站日志记录的数据包括哪些。
网站的日志形式最常见的是Apache日志格式,以一定的格式规范记录服务器的每次请求,以一个请求一条记录的形式输出日志文件,而网站分析之后的指标统计和计算基本都来源于这些日志中记录的信息,所以网站的日志记录是网站分析的最原始数据(Raw Data)。Apache日志的标准格式如图2-4所示(我的博客文章页面的访问记录,当条记录原始格式不换行,为便于展现做了换行处理)。
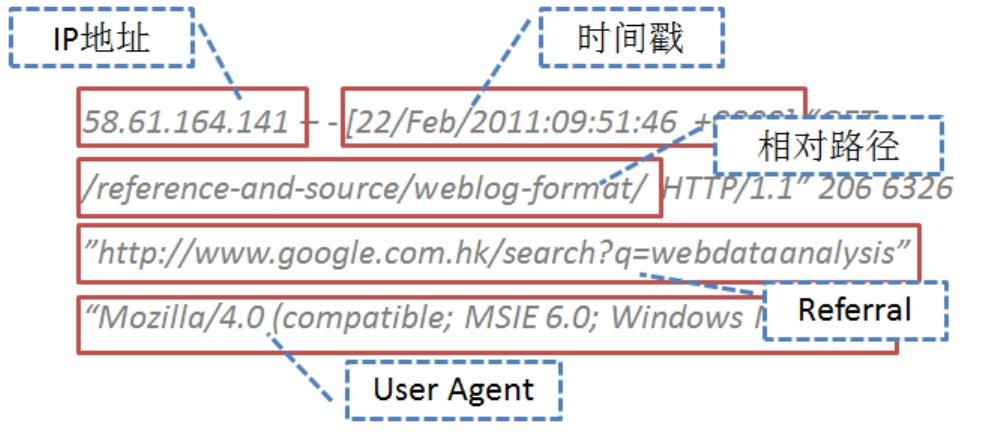
图2-4 Apache日志格式
图2-4中用红色框起来的是一些统计中常用的信息字段,主要包括以下几个信息。
访问终端IP地址
即用户访问网站时所用设备的IP地址,这里用了“访问终端”,因为移动设备的兴起使网站访问不再局限于PC,手机、平板电脑等设备同样可以浏览网站,同样也有相应的IP地址。IP地址信息对于指标统计非常重要,在最初的时候IP地址被当成识别访问用户的标志,即使当前还有很多网站把访问IP数作为一个重要指标来衡量网站的热门程度;同时,使用IP地址可以识别访问终端所处的地域,用于地域省份的维度细分。但由于代理、VPN的使用和伪IP的存在,使得IP的统计存在误差。
访问时间戳
访问时间戳记录了用户访问的时间点(其实是资源被请求的时间点,几乎可以认为是同时发起),是统计中必不可少的信息。主要包括日期、时间、时区等信息,可以精确到毫秒级别:

时间戳记录了动作的时间点,是所有统计中时间维度的基础,有了时间戳我们可以判断用户页面浏览的先后顺序,也可以根据时间做基于小时或天等粒度的统计汇总。
访问地址路径
日志里面记录的访问地址一般是相对路径,也就是不包含HTTP+域名信息,由于服务器自身知道指向哪个域名,所以只要有相对路径就能准确获取请求的资源,比如图2-4中用户的完整访问的URL应该是:http://webdataanalysis.net/reference-and-source/weblog-format/,其中http:// webdataanalysis.net被省略。所以访问地址路径其实定位了访问的具体对象,网站的页面和内容信息就是通过访问地址来确定的,因为URL唯一地标识了网站的所有资源。
在JS标记的日志中,访问的资源路径是最关键也是信息含量最高的一个字段,所有由JS代码产生的附带信息都会以参数的形式附带在图片URL请求的后面,如pic.gif?a=&b=&c=…通过之后的URL解析可以得到相应参数a、b、c……的值,进而获取统计需要的信息。
访问来源
访问来源对于网站分析而言同样是非常重要的一个信息,它直接关系流量的来源判定和优化,如果是JS标记,来源页信息一般会以参数形式带到URL中,但网站原始日志中就会记录相应页面访问的Referral信息。如图2-4中该页面浏览的访问来源就是Google搜索关键词“webdataanalysis ”后的结果页。通过这个信息可以进一步区分来源的类型(Source),是搜索引擎如Google、Baidu,还是外链网站,或者是直接访问(Direct),当用户直接访问或者由于某些特殊原因Referral丢失时,日志中该字段会显示“-”。
User Agent
UA中附带了用户终端的一些信息,包括操作系统OS、浏览器Browser的信息,有些“访问者”为了表明自己的身份也可以将一些身份信息写入UA中,如正规搜索引擎的爬虫,所以UA信息用户可以自己定制,如果你详细看过浏览器的设置选项,那么就会发现一般都有设置UA信息的地方。
UA被用于识别用户的身份,统计用户所使用终端设备的产品和版本信息,但由于UA可以自定义,统计的信息也可能因此存在偏差。
其他定制信息
当然,Apache的日志格式不仅有这些信息,我们还可以在设置日志输出时定制需要的信息,详细可以参考Apache日志格式定制的官方文档或者询问网站的技术人员。通常还会增加如域名(Domain)和Cookie信息,对于拥有多个域名或者多个子域名的网站,Domain可以帮我们更好地分离日志和数据,而Cookie是用户信息的另一种标记方式,从一定程度上可以弥补用户身份识别的误差。
下面再来了解一下JS获取数据的方式,通过在网站页面实施JS代码来获取数据是目前较为流行的方法。很多工具都在使用这种方法,无论是付费的商业网站分析软件,如Omniture和Webtrends,还是免费的网站分析工具Google Analytics,以及国内常见的CNZZ和百度统计。现在就以Google Analytics为例来介绍JS获取数据的方式。
当我们访问带有GA追踪代码的页面时,页面中的GA追踪代码被执行,然后会向Google服务器发送一个1像素的图片请求(http://www.Google-analytics.com/__utm.gif),并将所收集到的数据作为请求__utm.gif图片链接的变量一起发送回Google服务器,然后经过Google服务器的处理发布到我们的数据报告里,如图2-5所示。
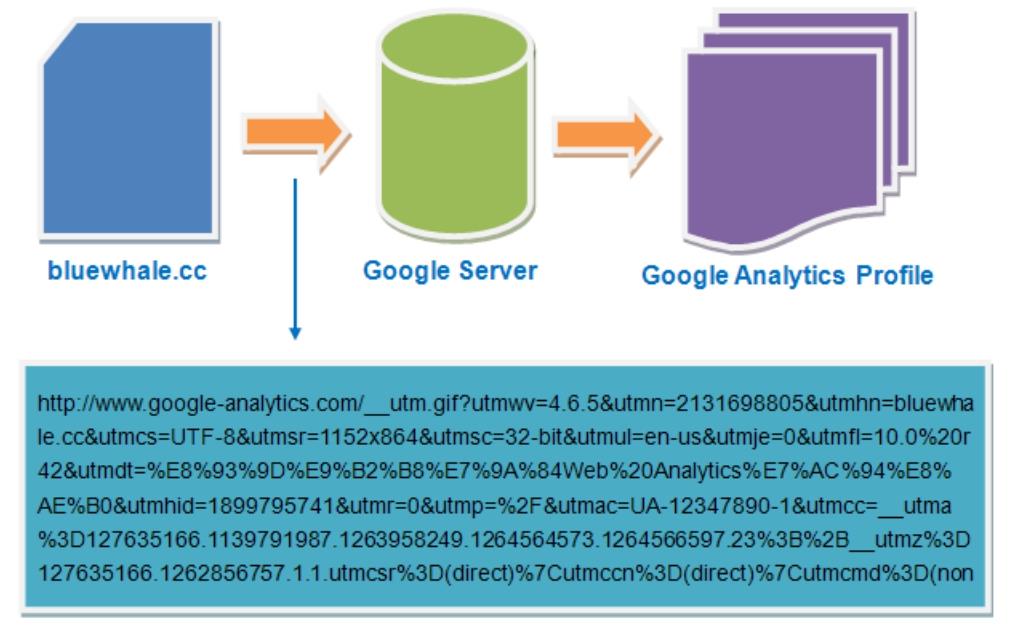
图2-5 Google Analytics传输数据过程
通过分析链接里的这些变量,就可以知道GA都追踪到了哪些信息。以下是GA追踪日志中的常见变量含义。
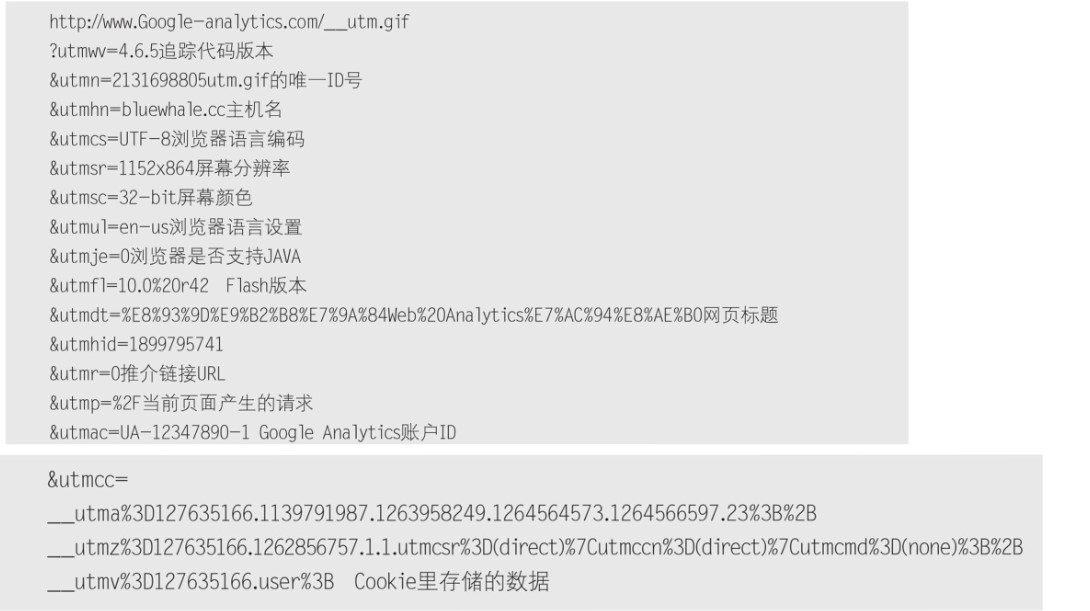
通常,这里面的大部分值是不会经常改变的,如utmsc屏幕颜色,utmsr分辨率,utmul语言设置等,而另一些变量在用户访问不同的网页时,值会不一样,如utmdt网页标题URL、utmp当前页面产生的请求等。通过这些变化的变量值,我们可以检查不同的页面上的追踪代码是否正常工作。比如utmp就是一个非常重要的值,我们利用_trackPageview函数所监测的各种数据都存在这个变量里,通过检查这个链接里的变量值,可以知道GA的代码以及我们的定制追踪部分是否能正常工作。
我们可以使用很多工具查看Google Analytics追踪日志中的内容,并检查代码设置是否正确。如httpwatch。当然,以上这些只是GA发送数据的一部分。如果你的网站开通了电子商务追踪功能或事件追踪功能,在返回Google服务器的链接中就会看到更多的变量值。
例如:
&utme事件追踪数据
&Utmipc用户购买的产品编号
&Utmipn用户购买的产品名称
&Utmipr用户购买的产品单价
&Utmtsp运费
&Utmttx税款
……
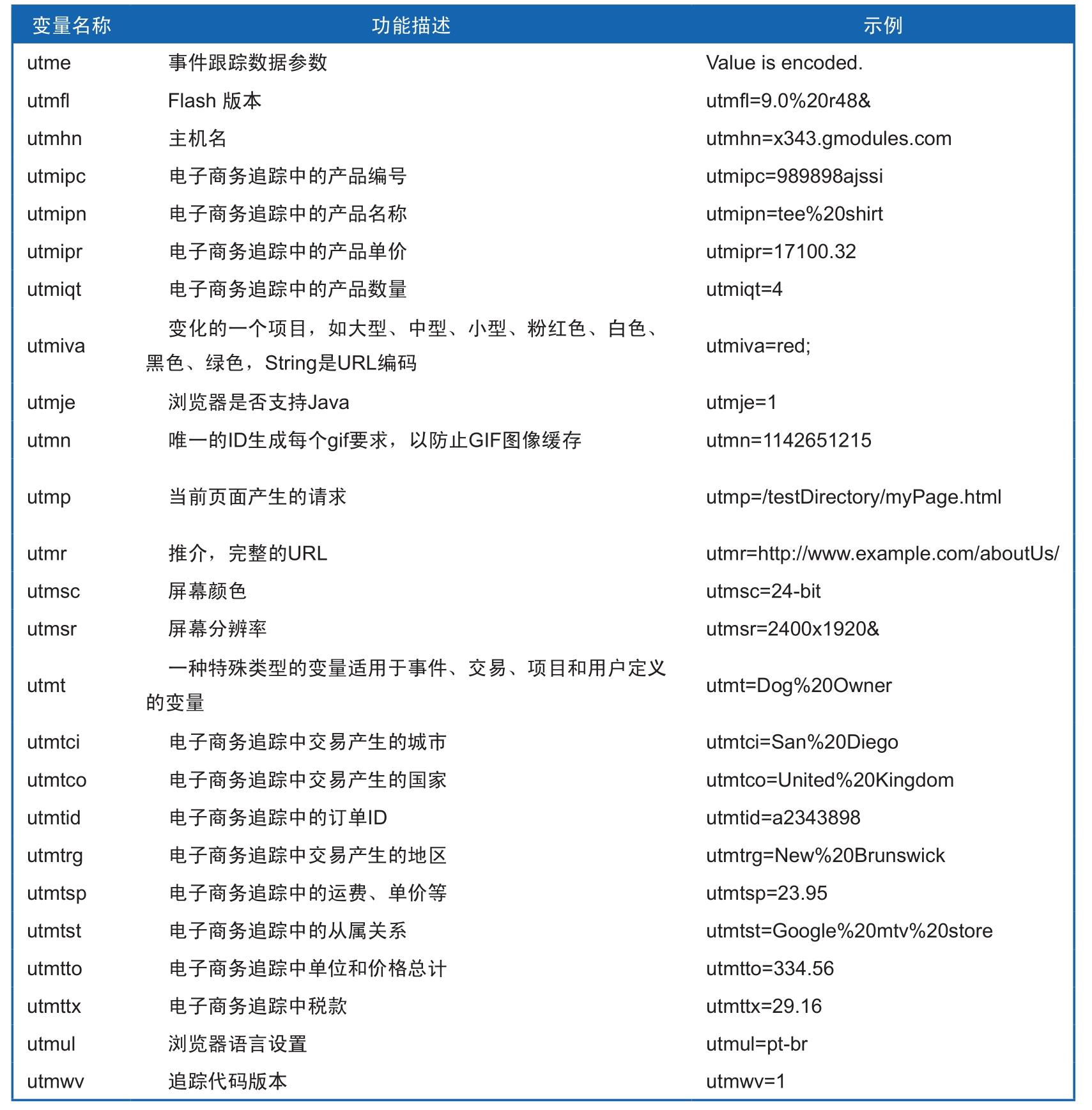
表2-2是Google Analytics返回数据中的参数名称和功能的列表。按照这个列表你能很轻松地发现Google在日志中记录到了哪些内容。同样,也可以用这些参数和值来检查代码设置是否正确。
表2-2 Google Analytics追踪日志参数描述

续表
上面已经提到了Cookie,Cookie是目前网站分析中用户身份识别的主流方法,但其实根据网站数据统计的发展,用户身份的识别也经过了一系列演变。随着网站的不断发展,同时由于网站的平台和业务特征的区别,各类网站都有自己的一套用户身份识别的方法,这里大概归纳了一下,并生成了一张用户身份识别的关键词图,如图2-6所示。

图2-6 用户身份识别关键词
图2-6基本包含了目前识别用户身份可能用到的一些信息和方法的关键词,随着互联网的不断发展和越来越广泛的跨平台应用,用户识别的方法会更加多样。这里主要介绍几个有代表性的、对网站普遍适用的方法,从最初使用IP到目前广泛使用的Cookie,来看看它们的优势和特点。
IP地址
IP地址是最早使用的识别唯一用户的标志,目前仍然有很多网站分析工具提供IP数这个指标,尤其是一些国内的工具,其实很大一方面的原因就是数据的用户已经习惯观察IP数,而被广泛提到的UV(Unique Visitors)最早就是通过IP去重统计得到的。
使用IP来标识唯一用户目前来看会有很大的弊端,造成用户数统计的误差,伪IP、代理、动态IP、局域网共享同一公网IP出口等情况都会干扰获取的IP地址的唯一性和准确性,但无论怎么样,IP地址都是最容易获取的信息。

IP + User Agent
于是,人们开始察觉到单一使用IP地址无法准确地定位每个用户,IP地址的不确定性太多,但为了不增加数据获取的难度,于是就有了多个信息联合去确定用户身份的方法,其中最常见的就是IP + User Agent。对于用户而言,当使用相同的终端浏览网站时,User Agent的信息是相对固定的,固定的操作系统,相对固定的浏览器,使用通过IP + User Agent的方式可以适当提高IP代理、公用IP这类情况下用户的分辨度,从而使唯一用户数的统计更加准确。
当然,只要使用了IP地址,伪IP、动态IP和VPN等IP变动的情况同样无法避免,同时又因为User Agent的信息是用户可以自定义的,用户身份识别的准确度还是不够高。

Cookie
当Cookie被引入作为网站识别用户身份的方式后,用户唯一身份定位的准确性有了一定程度的提升。Cookie是网站以一小段文本的形式存放在用户本地终端的信息,以便网站之后的读取。Cookie都有一定的有效期限,其中Google Analytics用于识别用户身份的Cookie的有效期是2年,由GA通过随机数和时间戳来生成字符串唯一地标识用户。
Cookie几乎能够唯一对应到用户的访问终端,但不像IP地址都能获取到,Cookie需要预先写入访问终端,如果用户禁用Cookie,那么这种用户识别机制就会失效,当用户执行了清理Cookie或者重装系统等操作时,Cookie同样也会丢失。

User Id
如果你的网站提供用户注册的功能,那么在用户注册完成后一般都会分配给每个用户一个用户ID,这个用户ID必然是唯一的,所以完全可以作为用户身份的标识符。同时,很多网站把这个用户ID写入到Cookie中以便用户下次访问时直接判别用户身份,或者完成“自动登录”的功能,如图2-7所示,当我进入亚马逊网站时,即使我没有登录,网站仍然知道我的身份。

图2-7 亚马逊用户身份识别
User_Id相较上面介绍的其他用户身份识别方式的另外一个区别就是用户ID绑定的不再是用户使用的终端设备,而是用户本身;同时使用用户ID可以串联用户的访问记录数据和CRM及后台其他系统的用户数据,为之后的关联分析和交叉分析提供便利。但使用用户ID的要求也相对较高,网站需要提供用户注册功能,同时在用户首次登录后将用户ID写入Cookie中以便之后的调取。所以一般用户ID会跟Cookie结合使用,已注册用户访问网站时获取用户ID作为用户标识,未注册的用户用随机分配的Cookie识别用户身份,这样保证了所有用户身份的可标记识别。

其他
现在还有很多网站注册时把邮箱地址或者手机号码作为用户的识别ID,当然它们也可以被认为是User_Id的一种形式。对于那些PC平台的客户端而言,它们可以获取PC机的MAC地址,这个地址具有长久的固定性,是作为用户标识的不错选择;而在手机或者其他移动平台,需要用户使用SIM卡时,获取用户的SIM卡ID来作为用户身份标识也是一种非常不错的选择。
通过前面对网站底层数据获取方式、底层日志格式和用户识别技术的介绍,就可以引出我们在网站分析的指标统计中最常用的底层数据模型——点击流模型(Clickstream)。点击流来源于网站的原始日志数据,经过一定的处理来区分用户的每次访问(Visit)及每次访问中浏览页面的先后顺序,其实就是将原先分散记录的“点”串成了“线”,如图2-8所示。
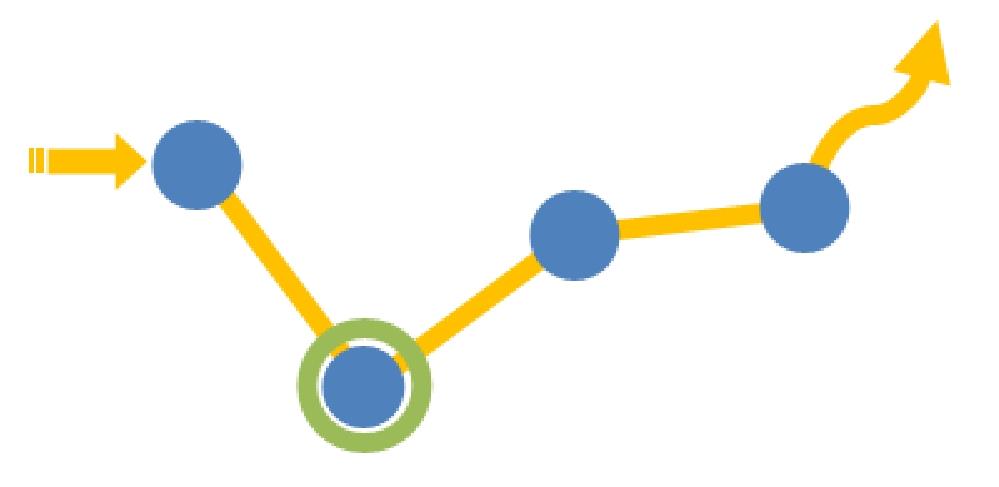
图2-8 点击流模型图
图2-8中,原始的网站日志中记录的信息可以被认为是以蓝色的点的形式存在的,一次访问请求一条记录,虽然也有时间戳和Referral信息,但我们无法知道那条记录具体是对应用户的哪次访问,也无法知道这条请求记录的是用户整个访问浏览网站过程中的哪一步。而生成点击流的过程就是将所有蓝色的点用黄色的线串连的过程,所有串联的线形成了用户的一次完整的访问,而根据时间顺序排列后,所有的点就有了前后的次序,这些信息对于某些指标的统计计算至关重要,甚至部分指标没有点击流就无法计算得到。
Tips
这里有必要先解释一下访问(Visit)这个概念,简单地说,一次访问就是用户从进入网站到离开网站的一个过程,这个过程可能很短(用户只打开一个页面就直接离开了),也可能很长(用户对网站很感兴趣,一口气浏览了很多网页,停留了很长一段时间)。访问(Visits)介于独立用户(Unique Visitors)和页面浏览(Pageviews)之间,一个用户在一天中可能会产生多次访问(比如用户早晨进入网站访问一次,下午或晚上又来访问一次,虽然是同一用户但产生的访问数是多个);而一次访问可能产生多次页面浏览(用户访问网站时可以浏览一个页面,也可以浏览多个)。
我们可以来具体看一下生成点击流模型的详细过程。先设定一张简化的解析后的原始日志记录表,假如以JS页面标记的方式获取到了更加丰富的信息,见表2-3。
表2-3 用于生成点击流的日志表
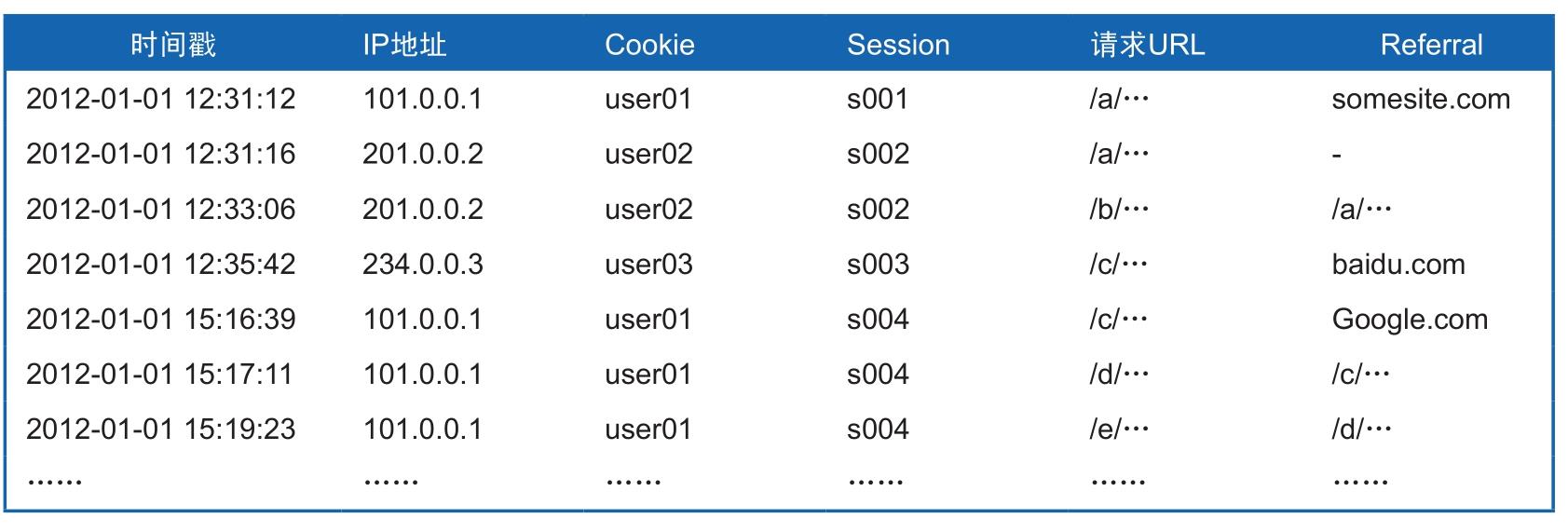
表2-3的Cookie其实就是用户身份的唯一标记,Session是用户访问的唯一标记,是技术层面的一种叫法,也称为“会话”,如果Session相同说明用户的这些浏览动作发生在同一次访问过程中,这个过程中用户未离开网站并且沉默时间不超过30分钟(Session标记跟Cookie一样,也有一个有效期,当用户停留在你的网站但长时间不活动时,Session将被重置,Google Analytics对这段时间的定义是30分钟)。如果你已经对网站分析的指标有所了解,可以尝试从上表中算一下,看哪些指标可以直接从原始日志记录中计算得到。如果将上面的用户访问记录用可视化的方法画成图形表现出来,可以是如图2-9所示的形式。
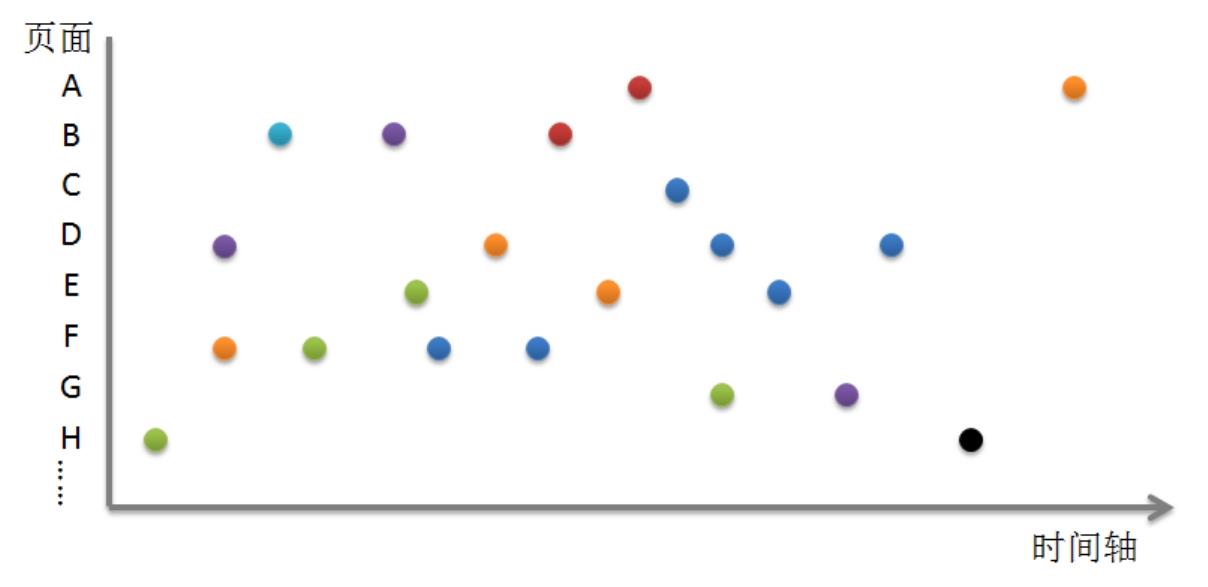
图2-9 原始日志记录可视化展现图
如图2-9所示,许多用户在各个时间点对各个页面的访问浏览以点的形式散布在一个平面坐标系上。其中横坐标代表时间轴,事件由左向右按时间顺序依次发生;纵坐标代表了网站拥有的N个页面,它们其实没有顺序之分,独立地罗列出来就行;点的不同颜色代表着不同的访问用户,也就是表2-3中用Cookie进行区分的;空白区间内的点就代表了用户的一次页面浏览,也就是表2-3中的一条记录,用记录的时间戳对应横坐标,页面URL对应纵坐标来确定位置,这样我们只要看图就能知道谁在什么时间访问了什么页面。但对于指标统计而言,这些信息还远远不够,因为我们无法区分用户的这些浏览行为是在一次访问中完成的,还是访问了多次,每次都进行一些操作,同时我们也需要将这些点整理得更加有序,能够一目了然地发现用户浏览各页面的先后顺序,以及用户从哪里进入,又从哪里离开网站。
于是,就有了从原始日志记录生成点击流模型的过程,目的就是为了解答以上的诸多问题。其实生成点击流的思路非常简单,就是将相同Session的点根据发生时间的先后(根据时间戳判断)和页面浏览的前后关系(根据Referral判断)连成线的过程,当然在程序中实现需要考虑诸多因素,并没有图形上显示的那么简单。于是,假设我们将所有的线连接起来后画出的结果如图2-10所示。
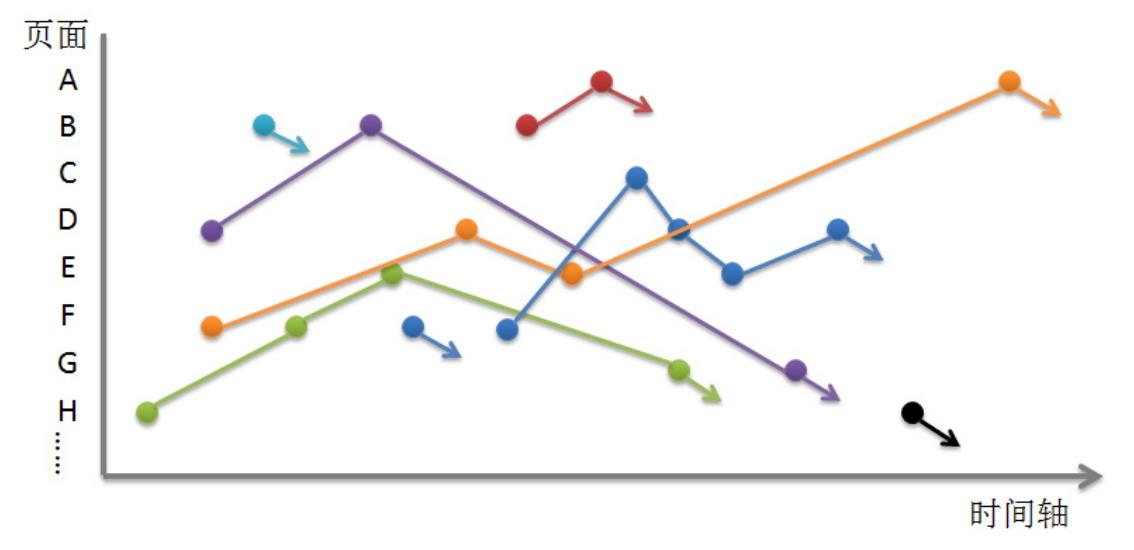
图2-10 点击流模型可视化展现图
看到图2-10后,用户的访问路径似乎变得清晰可见了,每个箭头代表了用户离开网站,有些用户只浏览了一个页面就离开了(淡蓝色和黑色的用户),有些用户选择浏览多个页面以查看他们感兴趣的内容(红色、紫色、黄色、绿色用户),当然这些用户的浏览页面数或多或少,访问的时间跨度也可长可短,有些用户则多次访问了网站(蓝色用户,第一次浏览一个页面后直接离开了,紧接着又一次进入网站,并浏览了多个页面)。经过简单的连线操作,让原始日志记录所能反映的信息更加丰富。
从可视化图形的变化效果,我们看到了生成点击流模型的基本过程,那么底层的日志记录表也需要做相应的改变——从一张拆分成两张。生成点击流的基本思路就是让原先只有页面浏览(点)的日志记录划归到相应的访问(线)的层面,所以底层的表可以从单纯记录页面浏览拆分为记录页面浏览和网站访问的两张表,一张就是原日志表简化后的表,不妨叫Pageviews表(参见表2-4),另一张记录了每次的访问信息,不妨叫Visits表。
表2-4 点击流模型Pageviews表

续表
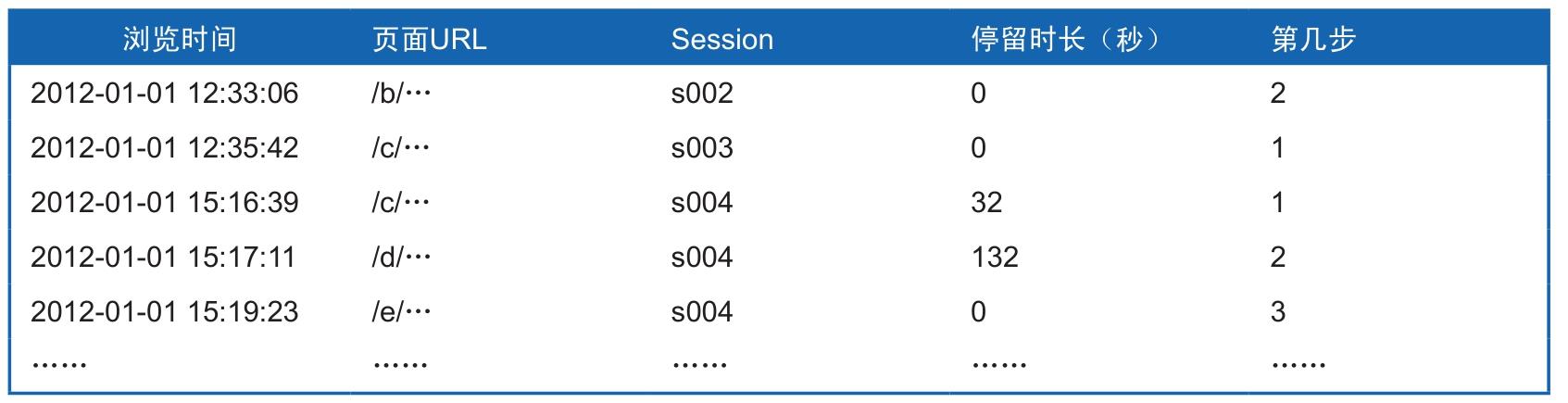
表2-4中,因为对访问信息做了拆分,相应的页面浏览记录可以进行简化,一些用户信息(包括IP、Cookie等)不需要记录在Pageviews表中,而只需要记录Session字段就可以通过关联从Visits表中获取的相应信息。而基于页面的每次浏览时间和浏览的页面URL需要进行记录,同时根据每次页面浏览在每个访问中所处的前后位置记录位于“第几步”的信息,同时每步的Referral就可以省略。这里比较关键的是计算得到了每个页面的停留时长,通过请求后面一个页面的时间点减去请求当前页面的时间点得到的时间间隔就是用户在该页面停留的时长。
页面停留时间注意点!
日志中记录的时间戳其实就是用户打开页面的时间点,也就是向服务器发送请求的时间点,所以当用户未打开后续页面时我们认为用户在浏览当前页面(当然用户也可能被外界因素打扰,如电话、临时呼唤、处理其他事物等),而请求当前页面到后续页面的请求之间的时间间隔被当成该页面的停留时长。所以,每次访问的最后一个页面无法计算得到停留时长,因为无后续页面请求,这会干扰页面平均停留时间的计算,需要格外注意。
表2-5是根据Session区分出来的Visits表信息。
表2-5 点击流模型Visits表
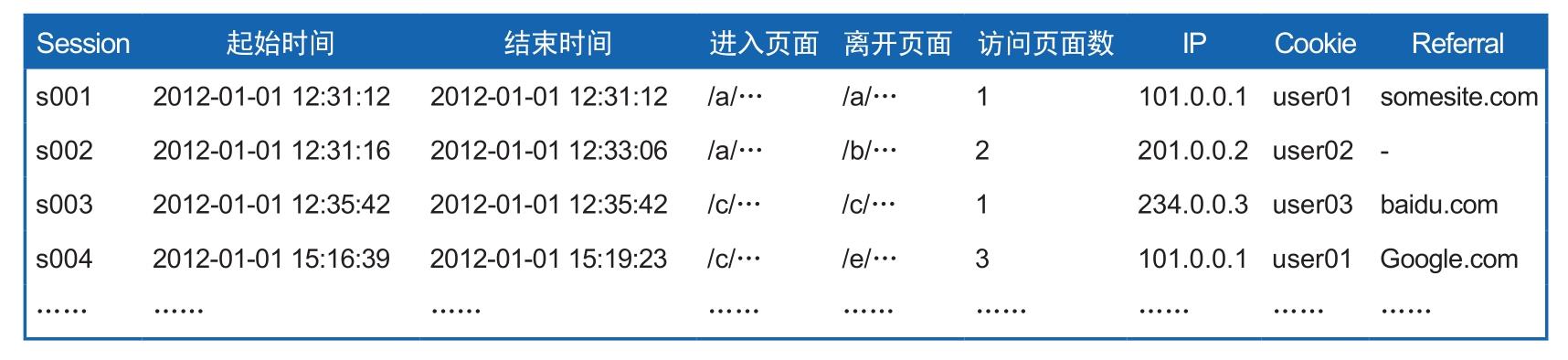
表2-5中,每个Session唯一标识一次访问,在Visits表中生成一条记录,其中Session就是关键词字段,因为每次访问的用户必然是相同的,所以用户的信息被统一记录在Visits表中,包括IP、Cookie等;而每个访问的站外Referral信息也需要记录在Visits表中,因为这是访问的外部来源,如果没有,则可能像s002这个Session一样记录的是短横杠,说明用户是直接访问或者Referral信息丢失。然后再根据串连页面访问的结果,可以记录每个访问的起始时间、结束时间、进入页面、离开页面,当然整个访问的浏览页面数也可以被计算得到。所有这些信息让很多基于访问层级的指标的统计变得更加容易。
点击流模型生成的两张表可以用Session字段实现相互之间的关联,从而Pageviews层面也可以获取用户的IP、Cookie等信息。在生成了点击流模型后,如果你熟悉网站分析指标,不妨再试试从这两张表中计算一下,看看现在你可以算出哪些指标了?而下面要介绍的正是网站分析中的基础指标,包括指标的定义、计算方法和应用,如果你已经完全了解了点击流模型,那么下面的指标学习你将游刃有余。