
下载掌阅APP,畅读海量书库
立即打开




从上一节的叙述我们可以看到,网络数据是从用户地址空间或网络适配器硬件缓冲区传送到内核地址空间的。Socket Buffer的数据包在穿越内核地址空间的TCP/IP协议栈过程中,数据内容通常不会被修改,只会有数据包缓冲区中的协议头信息会发生变化。大量操作是在sk_buff数据结构中进行的。
sk_buff 结构所包含的域和域的组织在内核的开发过程中做了多次添加和重新组织,在尽可能地使sk_buff在结构和布局上显得清晰的基础上,还考虑了数据传送的高效性。例如,按系统的cache line的大小对齐(cache Line的大小与CPU的体系结构相关,一般为64个字节),这样在系统总线上以burst方式传送,可更快速地读取sk_buff的数据。另一方面随着Linux网络功能的增强, sk_buff数据结构中也增加了一些新的数据域来标识对这些新功能的支持,比如对IP虚拟服务器的支持(ipvs_property),包过滤的支持等。
sk_buff的域从功能上大致可以划分成以下几类。
● 结构管理。
● 常规数据域。
● 网络功能配置相关域。
sk_buff中的某些域是为了方便组织和搜索数据结构本身的。在内核中,所有SocketBuffer根据其状态和类型(比如,接收、向外传送、前送或已处理完成的Socket Buffer)存放在不同的队列中。队列中的Socket Buffer链接为双向链表,队列的首地址保存在sk_buff_head结构类型的指针变量中。
队列中将sk_buff链接成双向链表的前向指针和后趋指针。sk_buff结构中的next指向链表中的下一个成员,prev指针指向链表中的前一个成员。引进一个新的数据结构保存该双向链表队列的起始地址,该数据结构为:

其中qlen为链表中sk_buff结构实例成员的个数,lock用于保护该双向链表的锁,以防并发访问链表。图2-4描述了Socket Buffer在内核中的组织。
内核如此管理Socket Buffer的优点在于:某个Socket Buffer的状态变化了,需要将Socket Buffer 在各队列之间移动时,无须复制整个缓冲区,只需修改next和prev指针,就可将缓冲区从一个队列放入另一个队列中管理。
指向拥有该Socket Buffer的套接字(socket)数据结构的指针。当数据是由本机的应用产生,将要向外发送时,或者从网络来的数据包的目标地址是本机应用程序时,这个数据域需要设置。
所谓套接字就是端口号加IP地址,用来唯一识别系统中的网络应用程序。sk_buff->sk数据域表示了该网络数据包最终应传送给哪个应用程序。所以如果一个数据包是从网络上接收,经由本机继续向前传送时,这个域的值为空(NULL)。
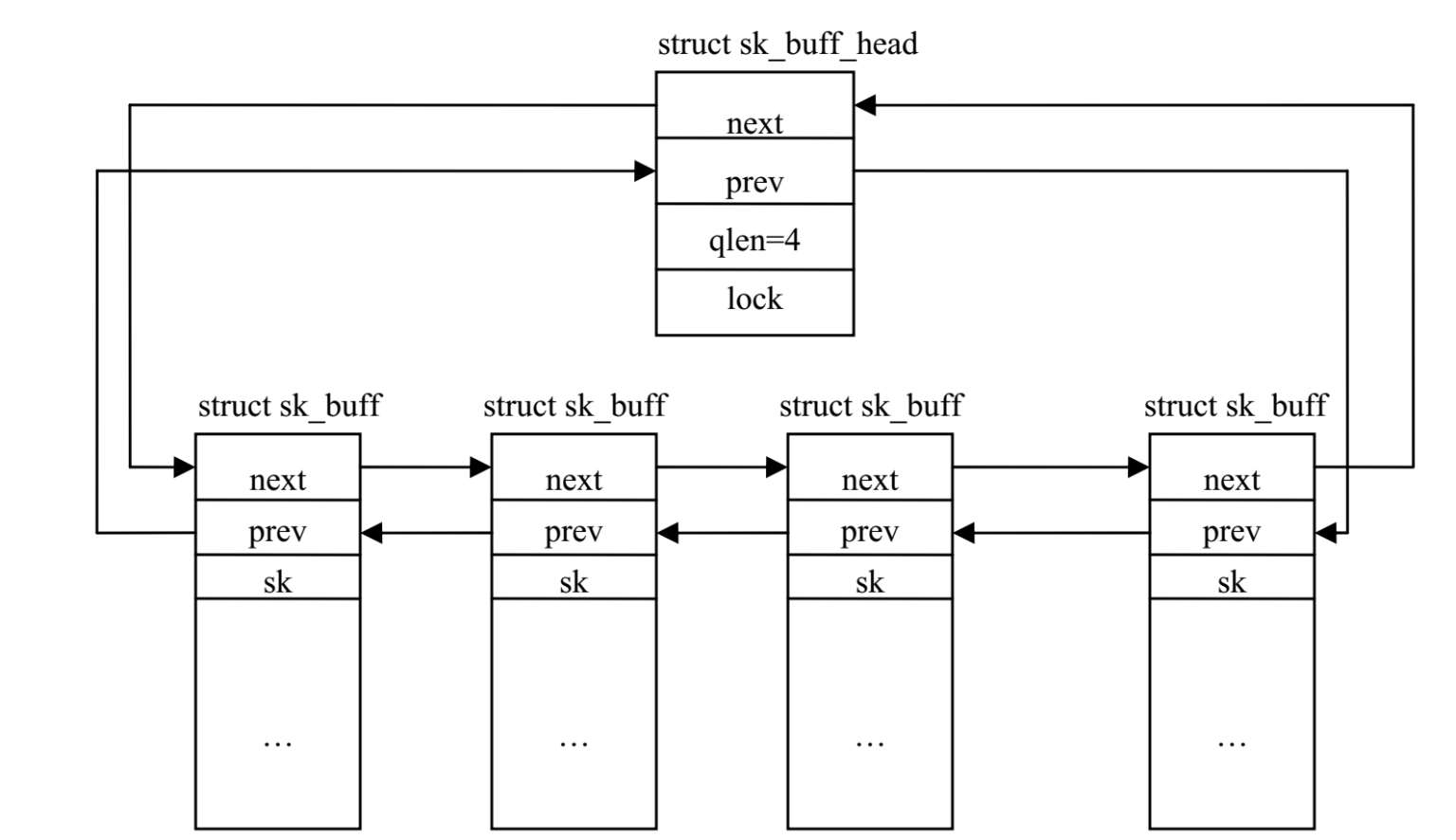
图2-4 Socket Buffer在内核中的组织
该域指明Socket Buffer中数据包的长度。这个长度是数据总长度值,即其值包括了:①主缓冲区中的数据长度(由sk_buff->head指针指向的地址存放的数据);②各分片数据的长度(当应用程序产生的数据大于网络适配器硬件一次能传送数据的最大传送单元MTU时,数据包会被分成更小的片段。数据包的分片在2.5节中介绍)。
sk_buff->len在数据包通过协议栈的各层时其值也在发生变化,因为各层的协议头信息在不断加入或从Socket Buffer中去掉。由此可见,sk_buff->len也包含协议头的长度。
data_len 只精确计算被分了片的数据块长度。
数据链路层(如Ethernet)协议头的长度。
hdr_len是针对克隆数据包时使用的,它表明克隆的数据包的头长度。当我们克隆(克隆的含义会在2.4.3节中讲解)Socket Buffer 时,可以只做纯数据克隆(即不克隆数据包的协议头信息),这时克隆Socket Buffer需要从hdr_len中获取头长度。
引用计数,或称为所有正在使用该sk_buff缓冲区的进程计数。这个参数的主要作用是防止sk_buff还在使用就被释放了。任何进程要使用sk_buff时,都应对sk_buff->users域加1,使用完成后应对sk_buff->users域减1。
sk_buff->users域记录对sk_buff结构的引用计数。数据包缓冲区的使用计数由dataref记录。用户可以用atomic_int 和atomic_dec函数来直接做加1和减1操作,但更多的是使用包装函数skb_get和free_skb来操作sk_buff->users,这样更安全。
记录整个Socket Buffer的大小,即sk_buff数据结构的长度和数据包的长度和。它是由alloc_skb函数将其值初始化为len+sizeof(sk_buff)的。
创建Socket Buffer时,我们调用alloc_skb函数来向系统申请内存。该函数需要一个参数为数据包预留的内存空间大小,即sk_buff数据结构中len域的值(由参数size给出),如:
skb->truesize的值会随着skb->len的值变化而变化。


Socket Buffer中数据包缓冲区的内容包括:①TCP/IP协议栈各层的协议头信息;②负载数据。这是最终在网络上传送的内容。以上的几个域代表了数据包缓冲区中各种信息的边界。
当每层协议处理函数为自己的活动准备空间时,在head和end之间分配自己所需的空间。head和end 指向整个数据包缓冲区的起始和结束地址,data和tail指向实际数据的起始和结束地址,各层协议处理函数可以在data和head之间的空隙处填写头信息,在tail和end之间放新的数据,如图2-5所示。
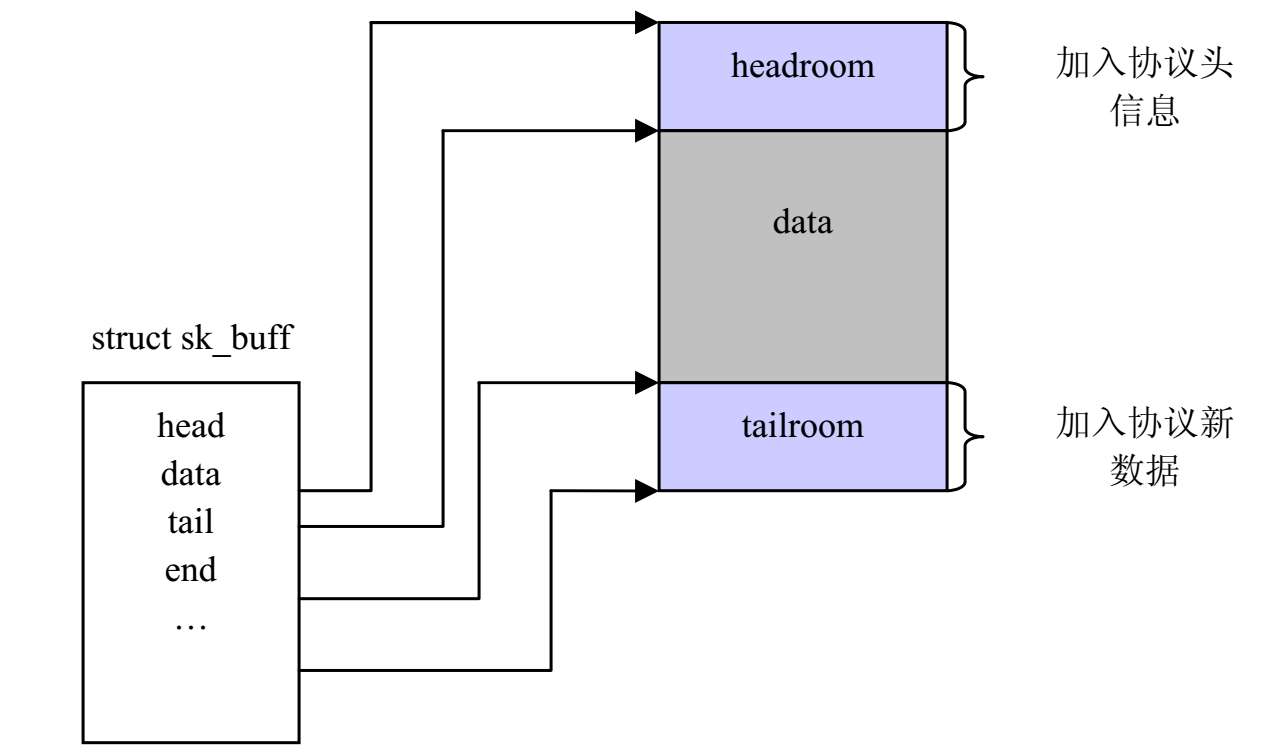
图2-5 Socket Buffer数据包与管理数据的指针
10.void(*destructor) (…)
destructor函数指针可以在sk_buff数据结构初始化时指向Socket Buffer的析构函数。在释放Socket Buffer时,完成具体的清除工作。当sk_buff缓冲区不属于任何套接字时,析构函数通常不需要初始化。
这些管理域全面描述了Socket Buffer的各种管理信息:Socket Buffer应放在哪个队列,有多少进程在访问sk_buff,有多少进程在访问数据包,各种信息的大小、边界等。
这一节介绍sk_buff数据结构中的一些常规域,这些常规域是描述Socket Buffer状态的主要数据域,也是TCP/IP协议栈处理程序操作最频繁的数据域。
描述了接收数据包到达内核的时间。由接收数据包处理函数netif_rx调用net_timestamp(skb)来对该数据域赋值。netif_rx是由网络设备驱动程序在收到网络数据时调用的(网络设备驱动程序和netif_rx函数实现功能会分别在第5章及第6章中讲解)。
Int iif
dev是指向代表网络设备数据结构的指针,它表明该数据包是通过哪个网络设备接收或传送的。当网络设备从网络收到一个数据包时,设备驱动程序将该域更新为一个net_device类型的指针,指向接收该数据包的网络设备,以下程序示例是cs89x0网络设备驱动程序,其接收数据包的函数为:net_rx。
当传送数据包时,dev代表的是数据包将通过哪个网络设备发送出去。


iif数据域为接收/发送数据包的网络设备索引号。在Linux系统中,某种类型的网络设备的命名方式是以字符开头的设备名后跟顺序索引号。例如Ethernet 类型的设备名为eht0、eth1等。设置索引号便于快速查找到网络设备。

由路由子系统使用,当接收到的数据包的目标地址不是本机,只是通过本机继续向前发送时,则这个数据域包含的信息指明应如何将数据包向前发送。该域是一个联合域,它或者指向路由表中的一条路由记录,其中存放了数据包的发送目标IP地址;或者指明应在系统的哪个路由表中查找数据包发送地址的信息。
这是一个控制缓冲区(Control Buffer),是各层协议在处理数据包时存放私有信息或变量的地方。各层协议可以自由使用该控制缓冲区。在当前的内核版本中,它的大小是48个字节。例如在传输层,UDP协议用控制缓冲区来存放它的udp_skb_cb数据结构。

为了使代码更易理解,在各层中通常都定义了宏来访问控制缓冲区,以下代码是UDP访问其私有数据的宏:

以下是在初始化过程中对UDP数据包做校验和时,填写控制缓冲区的代码:


如果你需要让控制缓冲区的信息跨协议层传送,则必须克隆sk_buff。
__u8 ip_summed
csum 域存放数据包的校验和。校验和是检验网络数据包在接收/发送过程中是否损坏的手段。发送数据包时,我们将数据从用户地址空间复制到内核地址空间,同时以相应的算法计算数据包的校验和存放于该域。接收数据包时,csum中存放的是网络设备计算的校验和。其中必须包含csum_start/csum_offset对。
● csum_start:以skb->head为起始地址的偏移量,指出校验和从数据的什么位置开始计算。
● csum_offset:以csum_start为起始地址的偏移量,指明校验和存放的地址。
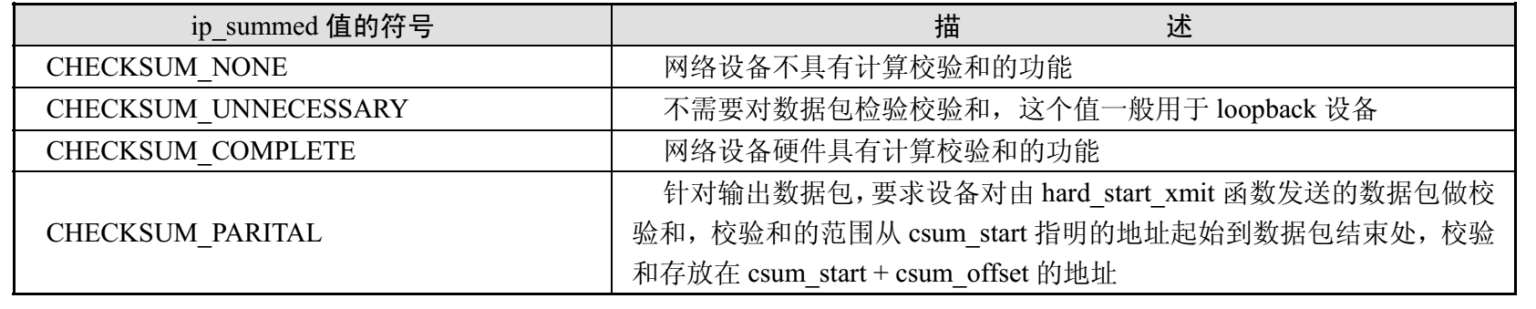
ip_summed 描述的是网络设备是否可用硬件来对IP数据进行校验编码或解码。ip_summed用两位编码来描述网络设备硬件对校验和的支持,它是由设备驱动程序反馈的信息,它的合法值在表2-1中给出。
表2-1 ip_summed数据域的值定义
priority数据域是用来实现质量服务(Quality of Service)QoS功能特性的。QoS描述了数据包传送的优先级别。例如网络视频数据、语音数据需要使用QoS以保证视频、语音的流畅。
该域的值说明要传送或前送的数据包在传送队列中的优先级。如果数据包是本地产生的,则由套接字(socket)层填priority的值;如果数据包是要前送的,则由路由子系统的函数根据数据包中IP协议头信息的Tos(Type of Service,服务类型)域来填写priority的值。

priority将一个字节划分成不同的位域,标记sk_buff的状态以及sk_buff中与网络特性相关的状态。ip_summed在该字节中占两位,编码网络设备对数据帧做的校验和的类型,其值我们已在前面介绍了。其余几个位域的作用如表2-2所示。
表2-2 位域定义说明

这是另一个划分成不同位域以标明Socket Buffer特性的字节。
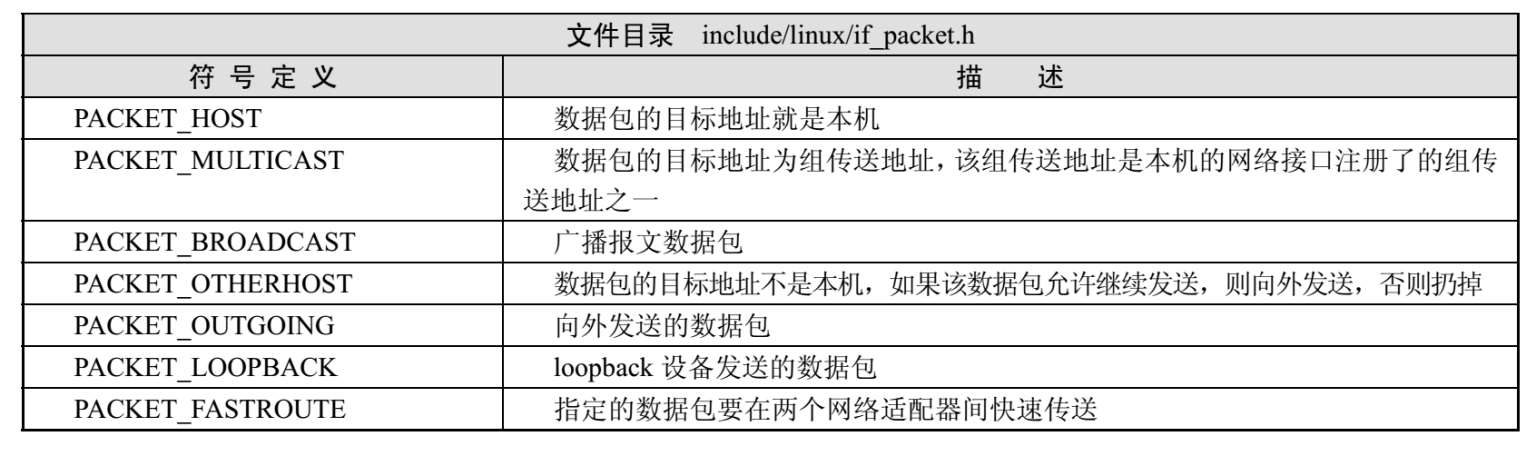
● pkt_type:数据包的类型。数据包的类型是按照数据链路层中设置的目标地址类型来划分的,如表2-3所示。
表2-3 数据包类型值定义
● fclone:sk_buff克隆类别,它的值与含义如下。
◆ SKB_FCLONE_UNAVAILABLE:sk_buff未克隆。
◆ SKB_FCLONE_ORIG:被克隆的sk_buff。
◆ SKB_FCLONE_CLONE:克隆的sk_buff。
● ipvs_property:该Socket Buffer是否是IP 虚拟服务器拥有的数据包。
● peeked:为UDP 协议使用的,在Linux以前的版本中,裸的UDP数据包的状态都是独立处理的。这样的问题是可能存在重复设置UDP数据包状态。使用peeked位后,说明该数据包在前面的处理过程已见到了,其状态已设置好,不需再设备。
● nftrace_:该标志是为网络过滤功能(Netfilter)使用的,是包过滤的跟踪标志。当该位被置1,说明需要对数据包进行过滤检查。
接收数据包的网络层协议(如IP协议)。它标志了网络数据包应传给TCP/IP协议栈网络层的哪个协议处理函数。
protocol域协议的完整定义在include/linux/if_ether.h头文件中,该域是由网络适配器的驱动程序调用相关函数来填写的,可能的协议如:
#define ETH_P_802_3、#define ETH_P_802_2 等。
具有多个缓冲队列的网络设备的队列映射关系。早期的网络设备只有一个数据发送缓冲区,现在很多的网络设备都有多个发送队列来存放待发送的网络数据包,queue_mapping描述了发送网络数据包所在队列与设备硬件发送队列的映射关系。
数据包为常规数据包的标志。
虚拟局域网的标记控制信息(Vlan Tag Control Information)。
安全路径(Security Path),用于发送帧。它是用于IPsec协议跟踪网络数据包的传送路径。
虚拟局域网与IPsec在本书不会讲解到,我们就不对以上三个数据域做更详细的分析了。
sk_buff_data_t network_header
sk_buff_data_t mac_header
以上3个域是sk_buff结构中描述Linux内核网络协议栈中各层协议头在网络数据包的位置信息,它们各自的含义如下。
● transport_header:传输层协议头在网络数据包中的地址。
● network_header:网络层协议头在网络数据包中的地址。
● mac_header:数据链路层协议头在网络数据包中的地址。
如果定义了使用偏移量(针对64位CPU体系结构),这几个值是指相应协议头在网络数据包中的地址是以skb->head为起始的偏移量,否则sk_buff_data_t 的类型就为指针(用于32位CPU体系结构),存放各层协议头在网络数据包中的起始地址。

以上面这种方式定义,其优越性表现在以下几个方面。
● 使程序实现更灵活。因为在内核中TCP/IP协议栈的各层都存在着多个网络协议实例,每种协议的头信息长度不一样,将协议头在数据包中的地址信息以偏移量或指针的方式来描述,我们就不必关心具体协议头的长度。
● TCP/IP协议栈各层协议头信息独立操作。在接收数据包的过程中,TCP/IP协议栈中负责处理第n 层的处理函数接收从第n-1层传来的sk_buff。这时sk_buff 的data指针指向的是第n层协议头的起始位置,如图2-6(a)所示。
第n 层协议处理函数在处理数据包之前需要解析协议头的信息,才能确定应对数据做何操作。第n层的协议处理函数应初始化该层的头指针指向其头信息来读取协议头数据。因为第n层的协议头在数据包传到第n+1层后就不再需要了,所以第n层的处理程序在把数据包传到第n+1层之前,要把skb->data指针的位置调整到第n层头信息结束的地址,也就是第n+1层协议头信息的起始位置。这时如果没用头指针保存头信息的地址,头信息就不再可访问。其次,解析协议头信息时不直接操作skb->data,可保证数据包的完整性和协议头操作的独立性。
发送数据包的过程正好与此相反,是在每层加入头的信息。头指针和skb->data指针的操作如图2-6所示。
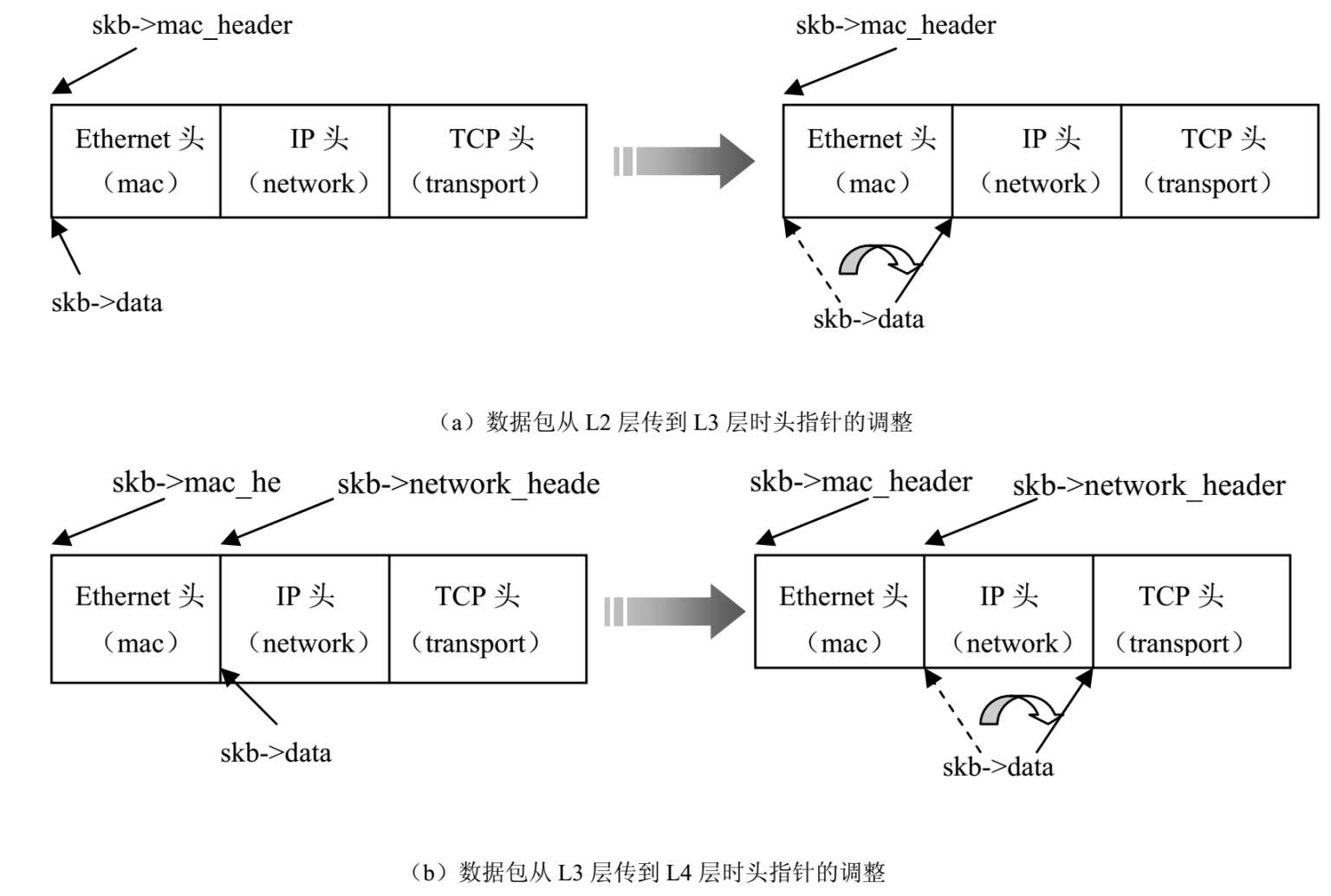
图2-6 Socket Buffer头指针的操作
Linux内核的网络子系统实现了大量功能,这些功能的实现是模块化的,用户可根据实际需要配置自己的系统,决定内核包含什么功能,不包含什么功能。例如,你可以将系统配置为路由器,或将系统配置为桥设备。根据内核配置,sk_buff数据结构中包含的数据域也随之变化。有的域只有在配置内核时选择了这些功能支持,编译器才会将这些数据域根据条件编译包含在sk_buff数据结构中。这些域的定义形式通常如下。

连接跟踪可以记录有什么数据包经过了你的主机以及它们是如何进入网络连接的。要支持连接跟踪功能,可以在Linux的源码树目录下运行以下几条命令。
● make xconfig:进入内核配置的图形界面,在内核配置的树形结构中做以下选择。该功能也可配置成模块,在运行时动态加载到系统中。
● nfct:用于连接跟踪计数。
● nfct_reasm:用于连接跟踪时数据包的重组装。
为桥设备配置防火墙功能,该功能是通过以下内核配置加入系统的:
nfct_bridge:存放桥数据包的数据结构。
当内核有多个数据包要通过网络设备向外发送时,内核必须决定哪个先送,哪个后送,哪个数据包扔掉,内核实现了多种算法来选择数据包。如果没有选择该功能,内核发送数据包时就选用最常规的先进先出(FIFO)策略。
流量控制功能通过以下内核配置加入系统。
● tc_inde:存放数据包发送选择算法的索引号。
● tcverd_:存放选择流量控制后对数据包所做处理行动(Action)的索引号,如排序、优先级设置等。
其他的条件编译与此类似,在sk_buff数据结构中与网络功能配置相关的其他数据域如表2-4所示。

表2-4 sk_buff中与网络功能选择配置相关的数据域

以功能配置的方式来决定sk_buff中数据域的构成,用户可以根据自己的系统需要量体裁衣,特别是在嵌入式系统中,系统资源极其有限的情况下,依据系统资源配置内核组件尤其重要。配置内核时只保留必需的功能,以最大限度地节省系统开销。


