
下载掌阅APP,畅读海量书库
立即打开




当分类器的设计完成后,对待测样品进行分类,一定能正确分类吗?如果有错分类情况发生,是在哪种情况下出现的?错分类的可能性有多大?这些是模式识别中所涉及的重要问题,本节用概率论的方法分析造成错分类的原因,并说明与哪些因素有关。
这里以某制药厂生产的药品检验识别为例,以此说明贝叶斯决策所要解决的问题。如图4-1所示,正常药品“+”,异常药品“-”。识别的目的是要依据X向量将药品划分为两类。对于图4-1来说,可以用一直线作为分界线,这条直线是关于X的线性方程,称为线性分类器。如果X向量被划分到直线右侧,则其为正常药品,若被划分到直线左侧,则其为异常药品,可见对其作出决策是很容易的,也不会出现什么差错。
问题在于可能会出现模棱两可的情况,如图4-2所示。此时,任何决策都存在判错的可能性。由图4-2可见,在直线A、B之间,属于不同类的样品在特征空间中相互穿插,很难用简单的分界线将它们完全分开,即所观察到的某一样品的特征向量为X,在M类中又有不止一类可能呈现这一X值,无论直线参数如何设计,总会有错分类发生。如果以错分类最小为原则分类,则图中A直线可能是最佳的分界线,它使错分类的样品数量为最小。但是如果将一个“-”样品错分成“+”类,所造成的损失要比将“+”分成“-”类严重,这是由于将异常药品误判为正常药品,则会使病人因失去及早治疗的机会而遭受极大的损失;把正常药品误判为异常药品会给企业带来一点损失,则偏向使对“-”类样品的错分类进一步减少,可以使总的损失为最小,那么B直线就可能比A直线更适合作为分界线。可见,分类器参数的选择或者学习过程得到的结果取决于设计者选择什么样的准则函数。不同准则函数的最优解对应不同的学习结果,得到性能不同的分类器。
错分类往往难以避免,这种可能性可用P(ω i X)表示。如何做出合理的判决就是贝叶斯决策所要讨论的问题。其中最有代表性的是基于最小错误率的贝叶斯决策与基于最小风险的贝叶斯决策。
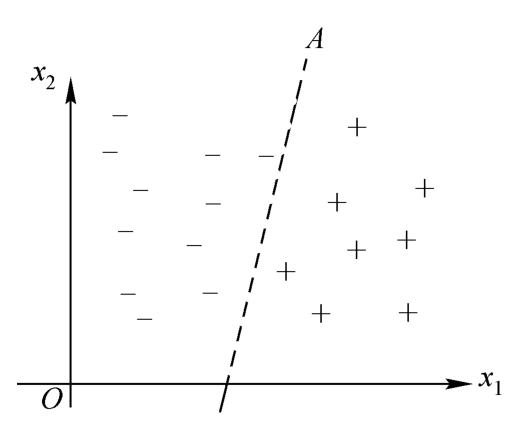
图4-1 线性可分示意图
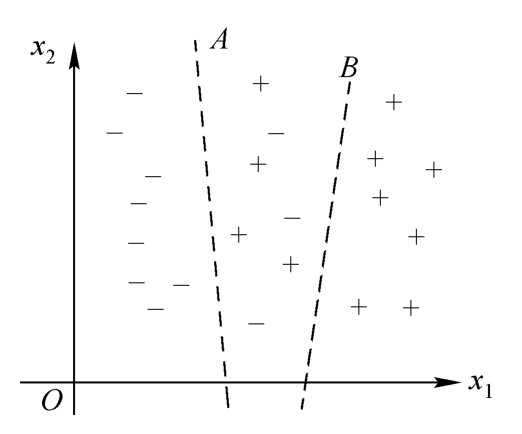
图4-2 线性不可分示意图
(1)基于最小错误率的贝叶斯决策
它指出机器自动识别出现错分类的条件,错分类的可能性如何计算,如何实现使错分类出现可能性最小。
(2)基于最小错误风险的贝叶斯决策
错分类有不同情况,从图4-2可见,两种错误造成的损失不一样,不同的错误分类造成的损失会不相同,后一种错误更可怕,因此就要考虑减小因错分类造成的危害损失。为此,引入一种“风险”与“损失”的概念,希望做到使风险最小,减小危害大的错分类情况。
若已知总共有M类物体,以及各类在这n维特征空间的统计分布,具体来说是已知各类别ω i ,i=1,2,…,M的先验概率P(ω i )及类条件概率密度函数P(X|ω i )。对于待测样品,贝叶斯公式可以计算出该样品分属各类别的概率,叫做后验概率;看X属于那个类的可能性最大,就把X归于可能性最大的那个类,后验概率作为识别对象归属的依据。贝叶斯公式为
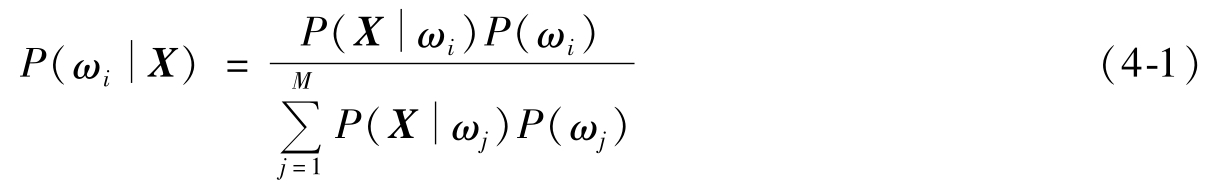
类别的状态是一个随机变量,而某种状态出现的概率是可以估计的。贝叶斯公式体现了先验概率、类条件概率密度函数、后验概率三者关系的式子。
1.先验概率P(ω i )
先验概率P(ω i )针对M个事件出现的可能性而言,不考虑其他任何条件。例如,由统计资料表明总药品数为N,其中正常药品数为N 1 ,异常药品数为N 2 ,则

我们称P(ω 1 )及P(ω 2 )为先验概率。显然在一般情况下正常药品占比例大,即P(ω 1 )>P(ω 2 )。仅按先验概率来决策,就会把所有药品都划归为正常药品,并没有达到将正常药品与异常药品区分开的目的。这表明由先验概率所提供的信息太少。
2.类条件概率密度函数P(X ω i )
类条件概率密度函数P(X|ω i )是指在已知某类别的特征空间中,出现特征值X的概率密度,指第ω i 类样品其属性X是如何分布的。假定只用其一个特征进行分类,即n=1,并已知这两类的类条件概率密度函数分布,如图4-3所示,概率密度函数P(X|ω 1 )是正常药品的属性分布,概率密度函数P(X|ω 2 )是异常药品的属性分布。
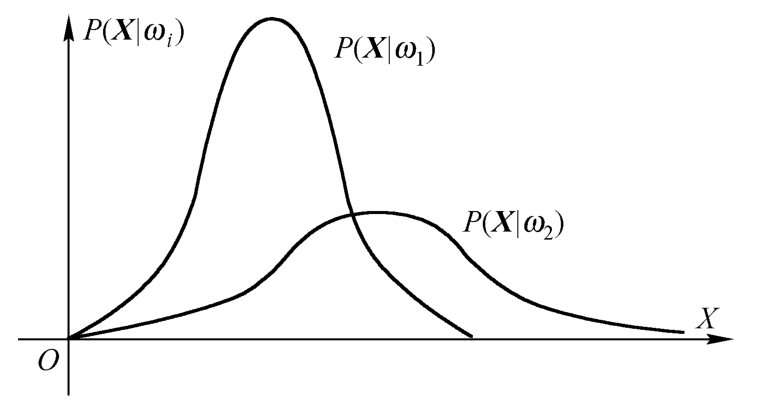
图4-3 类条件概率
例如,全世界华人占地球上人口总数的20%,但各个国家华人所占当地人口比例是不同的,类条件概率密度函数P(X|ω i )是指ω i 条件下出现X的概率密度,在这里指第ω i 类样品其属性X是如何分布的。
在工程上的许多问题中,统计数据往往满足正态分布规律。正态分布简单、分析方便、参量少,是一种适宜的数学模型。如果采用正态密度函数作为类条件概率密度的函数形式,则函数内的参数,如期望和方差是未知的。那么问题就变成了如何利用大量样品对这些参数进行估计,只要估计出这些参数,类条件概率密度函数P(X|ω i )也就确定了。
单变量正态密度函数为
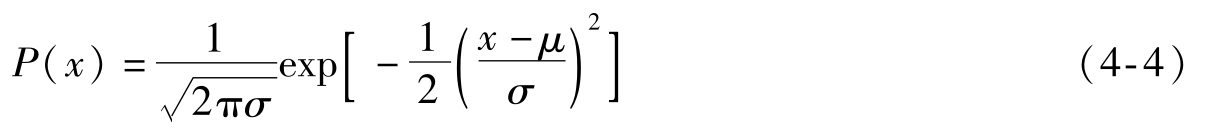
μ为数学期望(均值)

σ 2 为方差
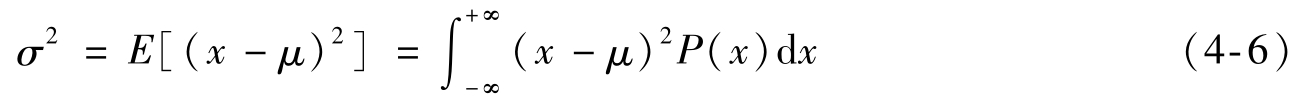
多维正态密度函数为
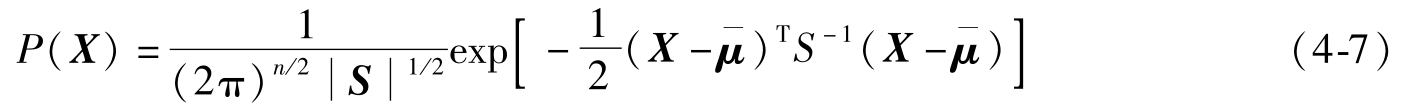
式中,X=(x
1
,x
2
,…,x
n
)为n维特征向量;
 =(μ
1
,μ
2
,…,μ
n
)为n维均值向量;S=
=(μ
1
,μ
2
,…,μ
n
)为n维均值向量;S=
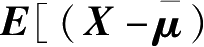
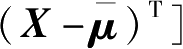 为n维协方差矩阵;S
-1
是S的逆矩阵;S 是S的行列式。
为n维协方差矩阵;S
-1
是S的逆矩阵;S 是S的行列式。
在大多数情况下,类条件密度可以采用多维变量的正态密度函数来模拟。
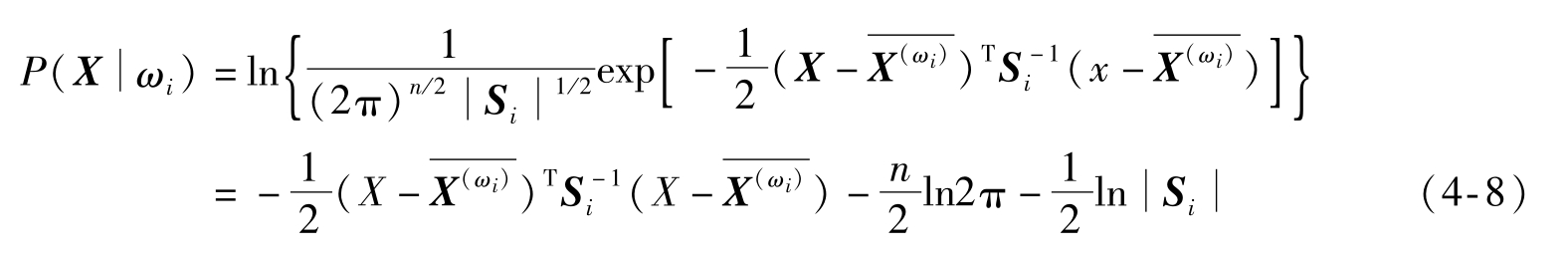
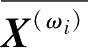 为ω
i
类的均值向量。
为ω
i
类的均值向量。
3.后验概率
后验概率是指呈现状态X时,该样品分属各类别的概率,这个概率值可以作为识别对象归属的依据。由于属于不同类的待识别对象存在着呈现相同观测值的可能,即所观测到的某一样品的特征向量为X,而在类中又有不止一类可能呈现这一X值,它属于各类的概率又是多少呢?这种可能性可用P(ω i |X)表示。可以利用贝叶斯公式来计算这种条件概率,称为状态的后验概率P(ω i |X)。
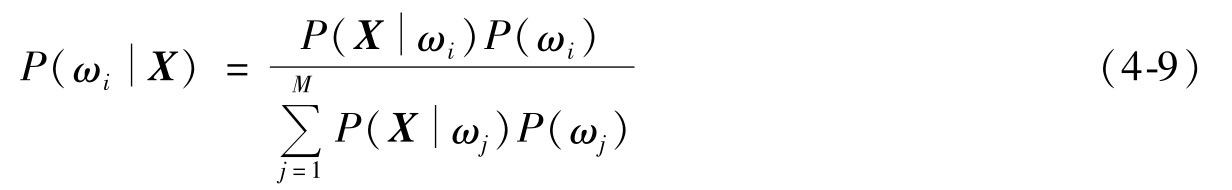
P(ω i |X)表示在X出现的条件下,样品为ω i 类的概率。在这里要弄清楚条件概率这个概念。P(A|B)是条件概率的通用符号,在“|”后边出现B的为条件,之前的A为某个事件,即在某条件B下出现某个事件A的概率。
4.P(ω 1 |X)和P(ω 2 |X)与P(X|ω 1 )和P(X|ω 2 )的区别
① P(ω 1 |X)和P(ω 2 |X)是在同一条件X下,比较ω 1 与ω 2 出现的概率,若P(ω 1 |X)>P(ω 2 |X),则可以下结论,在X条件下,事件ω 1 出现的可能性大,如图4-4所示。两类情况下,则有P(ω 1 |X)+P(ω 2 |X)=1。
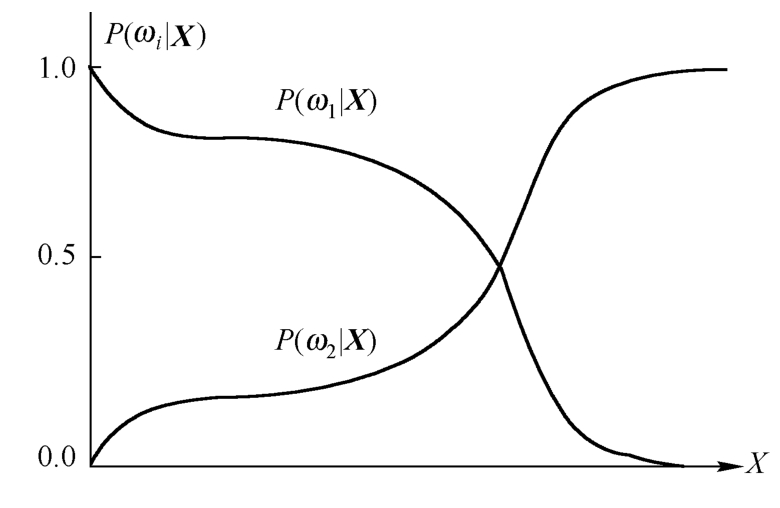
图4-4 后验概率比较图
② P(X|ω 1 )与P(X|ω 2 )都是指各自条件下出现X的可能性,两者之间没有联系,比较两者没有意义。P(X|ω 1 )和P(X|ω 2 )是在不同条件下讨论的问题,即使只有两类ω 1 与ω 2 ,P(X|ω 1 )+P(X|ω 2 )≠1。不能仅因为 P(X|ω 1 )>P(X|ω 2 ),就认为X是第一类事物的可能性较大。只有考虑先验概率这一因素,才能决定X条件下,判为ω 1 类或ω 2 类的可能性比较大。