
下载掌阅APP,畅读海量书库
立即打开




Blackfin处理器基于改进的哈佛总线结构,以Blackfin BF534/536/537处理器为例,处理器的结构如图2.1所示,包括内核、存储器、DMA控制器、中断控制器、外部总线接口、JTAG调试接口、内核电压调节器、外设等部分,其中外设包括看门狗、RTC、CAN总线、高速串行口(Synchronous Serial Peripheral Port,SPORT)、外设并行总线(Parallel Peripheral Interface,PPI)、通用异步串行接口(Universal Asynchronous Receiver/Transmitter,UART)、串行外设接口(Serial Peripheral Interface,SPI)、定时器等。
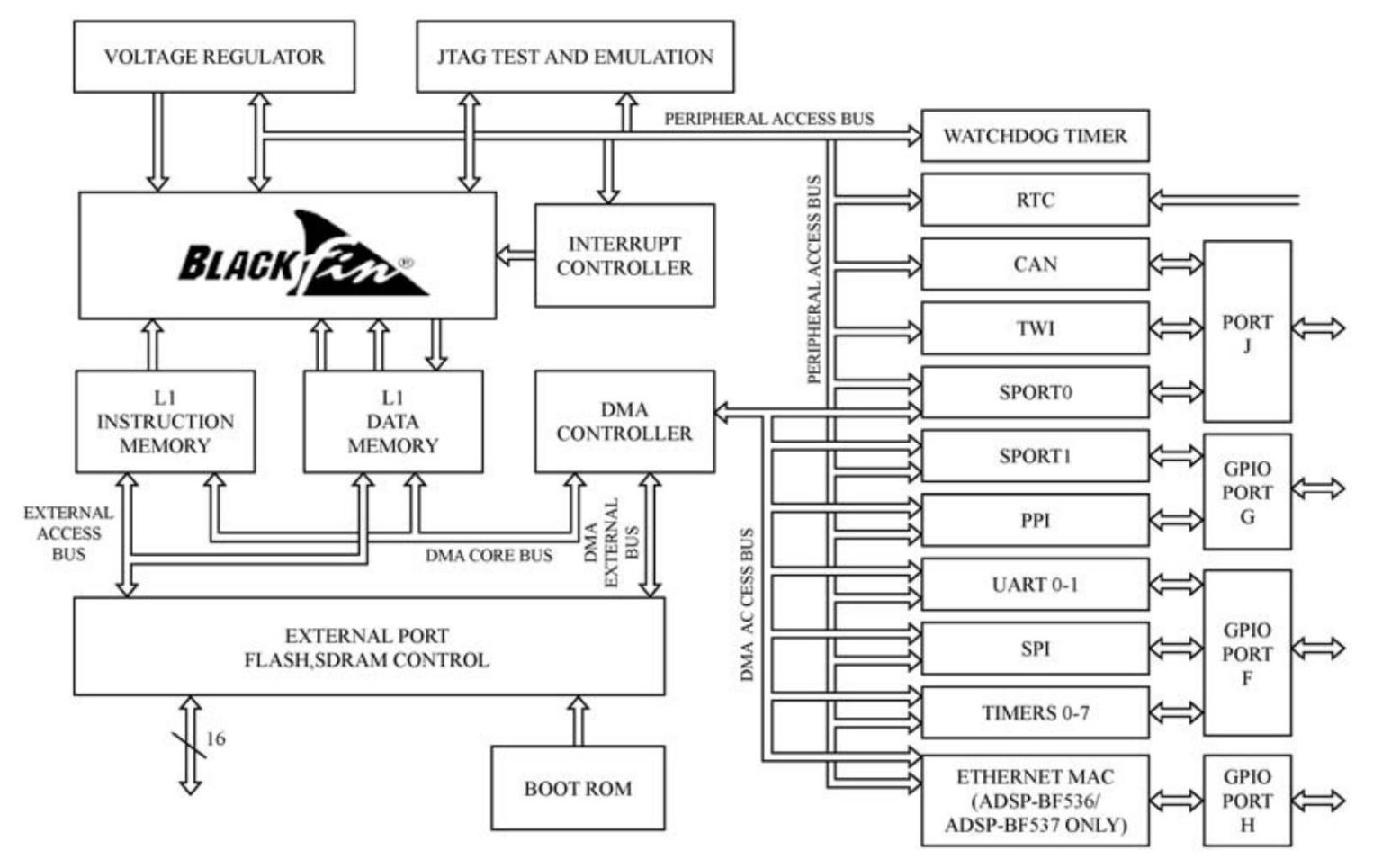
图2.1 Blackfin BF534/536/537处理器架构
所有的Blackfin处理器具有相同的内核结构,如图2.2所示。Blackfin内核包括三部分:算术单元、地址单元和控制单元。
算术单元负责算术逻辑运算功能,包括2个40位ALU、2个40位累加器、2个16位乘法器、4个8位ALU和1个桶形移位器以及8个中间寄存器。
ALU是算术逻辑运算单元,2个40位ALU可以同时执行两组16/32/40位加、减运算以及与、或、非、异或等定点运算。参与运算的操作数是定点16位、32位或者40位,输出结果为16位、32位或者40位。另外还有4个8位的ALU,可以同时执行4组8位的加、减法,在视频专用处理指令中使用。
乘法器每个指令周期可以同时执行2组16×16位的乘法运算,配合ALU可以完成数字信号处理中常用的乘累加(Multiply Accumulators,MAC)运算。
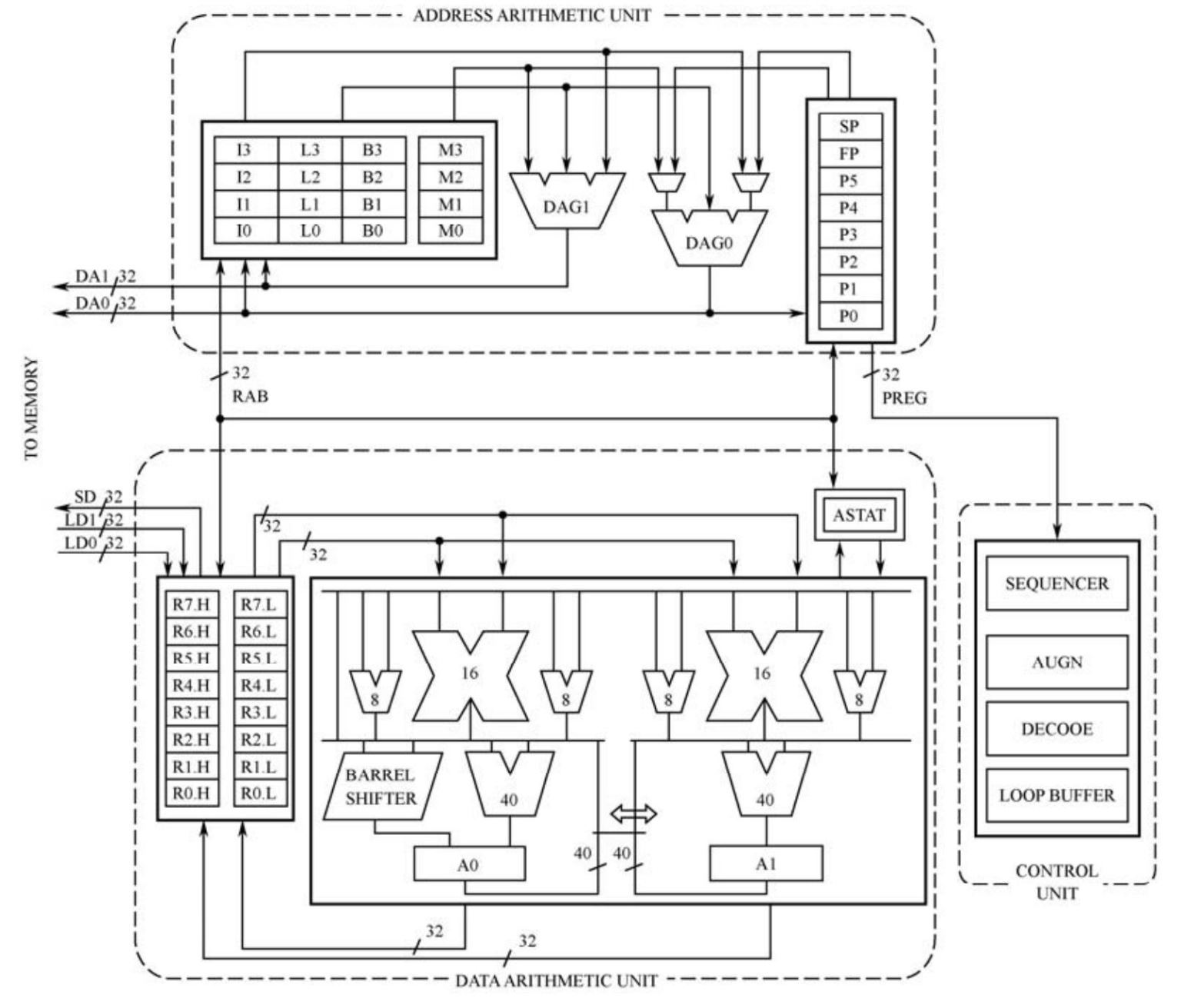
图2.2 Blackfin处理器内核结构
寄存器包括8个32位的数据寄存器R0~R7和2个40位的累加器A0和A1。R0~R7可以作为2个独立的16位或者1个32位使用,作为操作数参与算术逻辑运算。A0和A1存放累加结果,配合ALU、乘法器完成MAC运算。
桶形移位器对有符号整数或者无符号整数完成算术移位、逻辑移位、置位和清零等位操作。
计算单元从数据寄存器获得操作数,进行算术、逻辑或者乘法运算,结果返回到数据寄存器。ALU可以执行16位和32位的操作,下面列出ALU和MAC运算支持的基本模式。
单16位操作:
以下例子为16位加法操作,数据寄存器R2的低16位和R3的高16位相加,结果存放在R6的高16位,运算结果考虑饱和处理,如图2.3所示。
双16位操作:
以下例子执行双16位加减法操作,数据寄存器R2的高16位加上R3的高16位,结果存放到R6的高16位,同时R2的低16位减去R3的低16位,结果存放在R6的低16位,如图2.4所示。
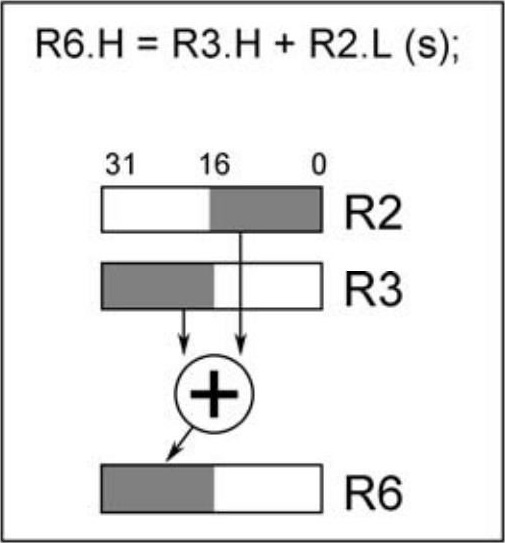
图2.3 单16位操作 |
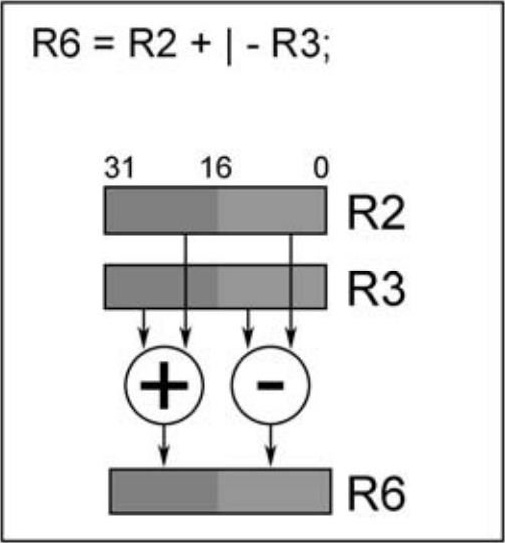
图2.4 双16位操作 |
四16位操作:
以下例子同时执行4个16位加减法操作,输入为2个32位操作数,输出可以是另外2个32位寄存器。图2.5中寄存器R0的低16位减去R1的低16位,结果存放在R2的低16位,R0的高16位减去R1的高16位,结果存放在R2的高16位;寄存器R0的低16位加上R1的低16位,结果存放在R3的低16位,R0的高16位加上R1的高16位,结果存放在R3的高16位。
注意由于计算单元每次最多只能读取2个32位操作数,所以以上运算中参与运算的左、右两边是同样的操作数。下面这条指令同样是执行4个16位操作,但是由于输入操作数多于2个32位寄存器,因而是错误的。
R3 = R0 −|− R1,R2 = R0 +|+ R4;
单32位操作:
以下操作执行32位加法操作,寄存器R2和R3中存放的均是32位操作数,二者相加结果存放到R6中。
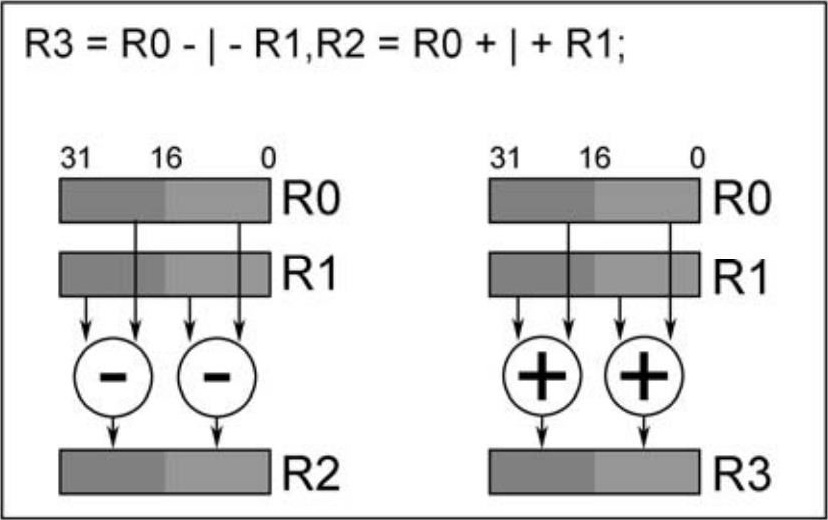
图2.5 四16位操作
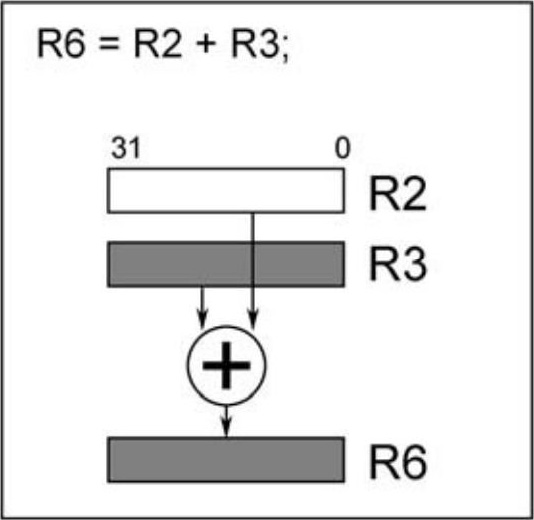
图2.6 单32位操作
双32位操作:
以下操作执行2个32位加减法操作,该指令的输入为R1和R2两个32位操作数,分别进行加、减操作,结果分别存放在R3和R4中,如图2.7所示。
注意由于计算单元每次最多只能读取2个32位操作数,所以以上运算中参与运算的左、右两边是同样的操作数。下面这条指令由于输入多于2个32位寄存器,因而也是错误的。
R3 = R1 − R2,R4 = R0 + R2;
双MAC操作:
Blackfin处理器具有2个16位乘法器,因此单周期可以执行两条乘法运算,配合累加寄存器器A0和A1,可以实现数字信号处理中最常见的MAC运算。下图中数据寄存器R2的高16位和R3的高16位相乘,结果与累加器A1中的数据相减,最终结果存放在A1中;同理,R2的低16位和R3的低16位相乘,结果与累加器A0中的数据相加,最终结果存放在A0中,如图2.8所示。
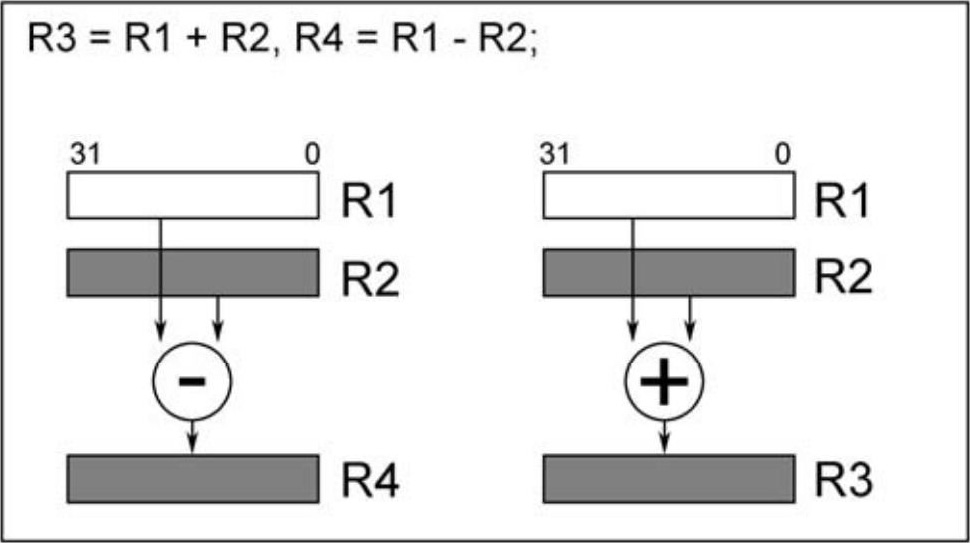
图2.7 双32位操作
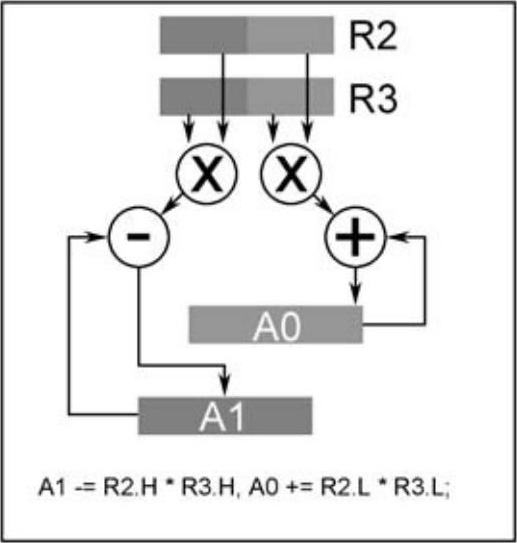
图2.8 双MAC操作
数据参与计算时需要把数据从内存读到数据寄存器,计算后的结果需要从数据寄存器复制到内存。地址单元用于生成数据加载和回写所需要的地址,包括两个地址生成器和一组寄存器。DAG0和DAG1单指令周期可以生成2个独立的32位地址。地址单元结构如图2.9所示。
地址单元包括6个通用指针寄存器、1个SP寄存器、1个FP寄存器、4个I寄存器和4组M、B、L寄存器,寄存器文件结构如图2.10所示。
P0~P5:通用寄存器,存放32位地址。例如指令R0 = [P0],是指把P0指向的地址处的数据加载到R0中。
I0~I3:索引寄存器,存放32位无符合数地址。例如指令R0 = [I0],是指把寄存器I0指向的地址中存放的数据装载到数据寄存器R0,用于间接寻址。
M0~M3:调整寄存器,配合索引寄存器使用,用于修改索引寄存器的值。例如指令R0 = [I0 ++ M0],首先把I0指向的地址中的数据装载到R0,然后寄存器I0的值被修改为I0+M0。
B0~B3,L0~L3:基址寄存器和长度寄存器,二者配对使用,用于硬件循环操作。
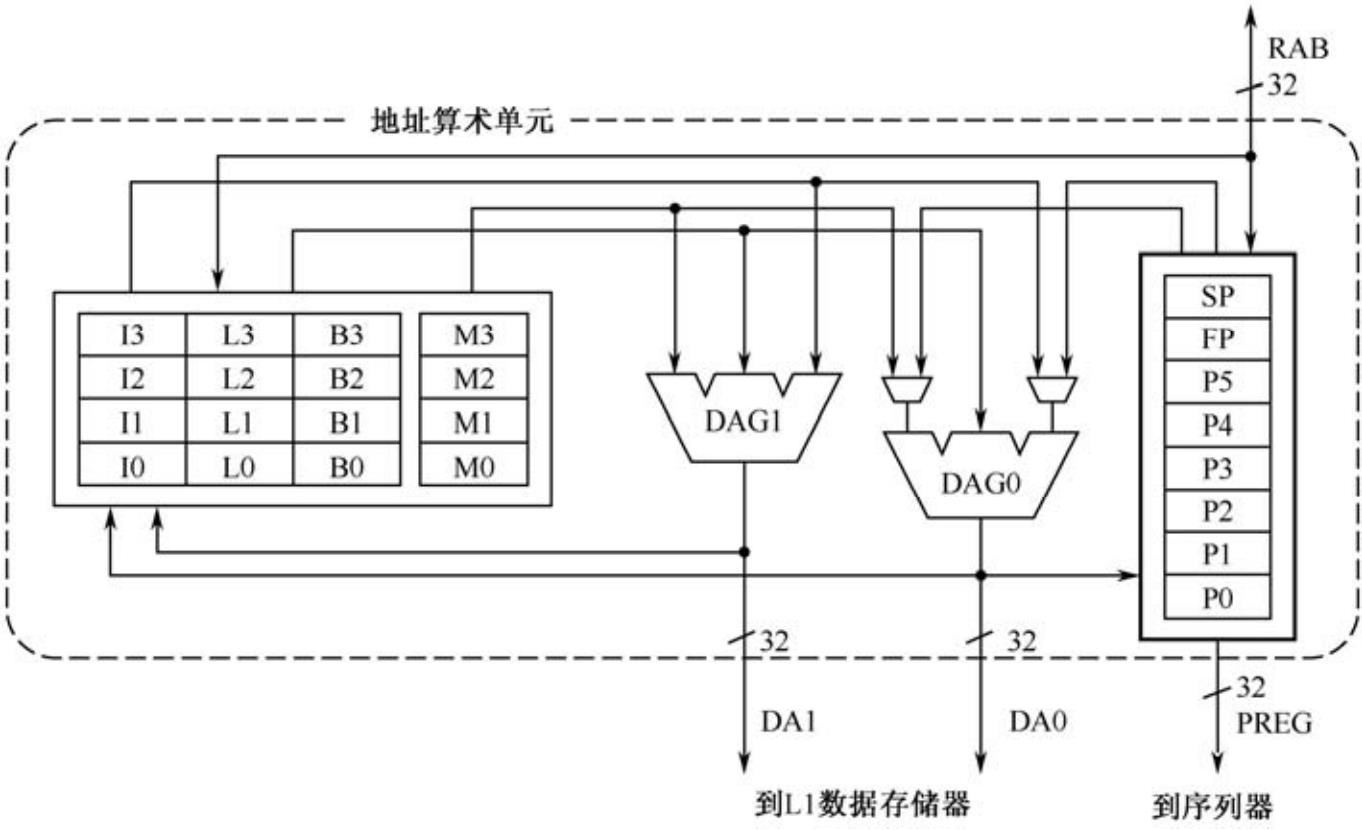
图2.9 地址单元结构
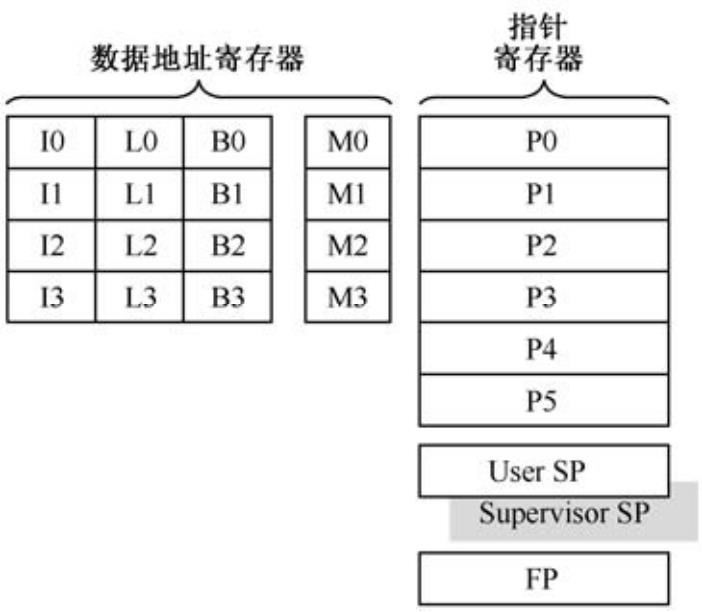
图2.10 地址单元的寄存器文件
控制单元包括序列器、地址对齐、地址解码、硬件循环等部分,负责确定程序的执行顺序。通常程序是按照线性顺序执行的,但是循环、子程序、跳转、中断等处理会打断程序的顺序执行,序列器就是负责确定下一条程序执行的地址,即确定PC寄存器的值。Blackfin处理器包括一个没有CPU开销的硬件循环单元,通常循环操作需要打乱程序执行顺序,因此执行效率较低,而采用Blackfin的硬件循环单元可以做到无CPU开销,有效提高循环操作的效率。
Blackfin处理器采用改进的多总线哈佛结构,程序存储器和数据存储器相互独立,统一编址,共支持4 GB的寻址空间。4 GB的地址空间包括片内存储器、片外存储器、外设I/O映射寄存器、片内ROM等,BF534/536/537处理器的内存总线结构和内存配置分别如图2.11和图2.12所示。
Blackfin处理器为了达到最佳的数据吞吐性能,采用分层的内存结构,分为片内静态存储器L1和片外存储器L3。L1的特点是运行速度快,单周期完成数据的读或者写,与内核总线时钟同步。L3片外存储器延迟大,与系统时钟同步,但是L3的存储容量可以做的很大,价格便宜。通常DSP处理器一个很重要的指标就是片内高速SRAM容量,SRAM容量越大,意味着有更多的数据可以在片内进行处理,减少片内和片外存储器之间的数据复制过程,因此可以获得更高的性能。但是片内SRAM尺寸较大,受限于体积和成本,SRAM容量不可能太大。L3通常是片外的SDRAM存储器,价格便宜,Blackfin处理器可以寻址多达512 MB的SDRAM,适合存放程序和大量的数据。为了达到更优的数据吞吐性能,需要协调L1片内存储器和L3片外存储器之间的工作。
从图2.11可以看出,L1存储器和Blackfin内核之间有多条总线连接,包括64位指令总线,2个32位的数据装载总线和1个32位的数据回写总线。理解了图2.11所示的总线结构,有助于理解2.2.1节讲到的ALU双32位指令为什么会有参与运算的操作数不能多于2个32位寄存器的限制。Blackfin处理器的总线结构单指令周期只能装载2个32位数据寄存器,同时回写1个32位寄存器。
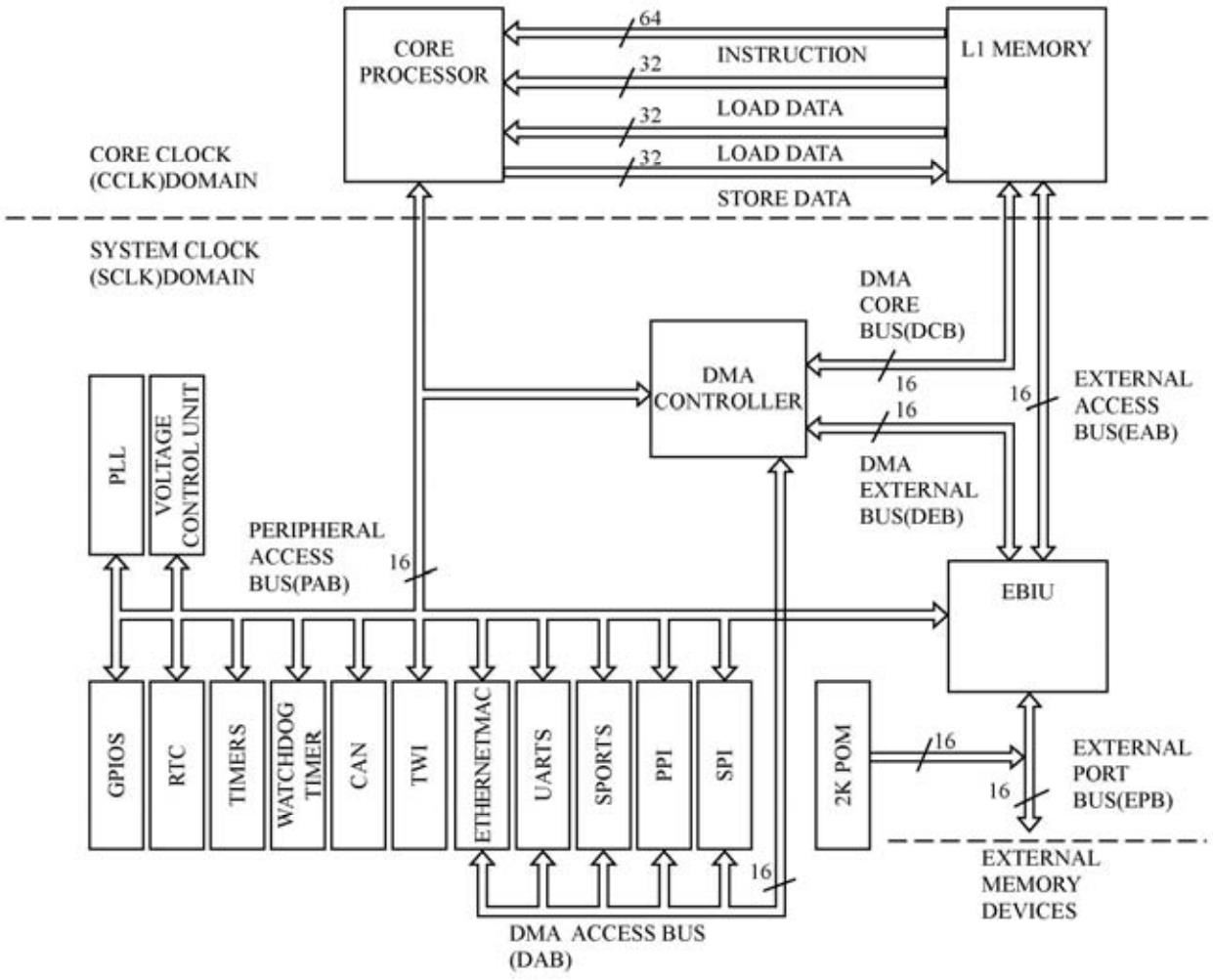
图2.11 Blackfin处理器内存与总线结构
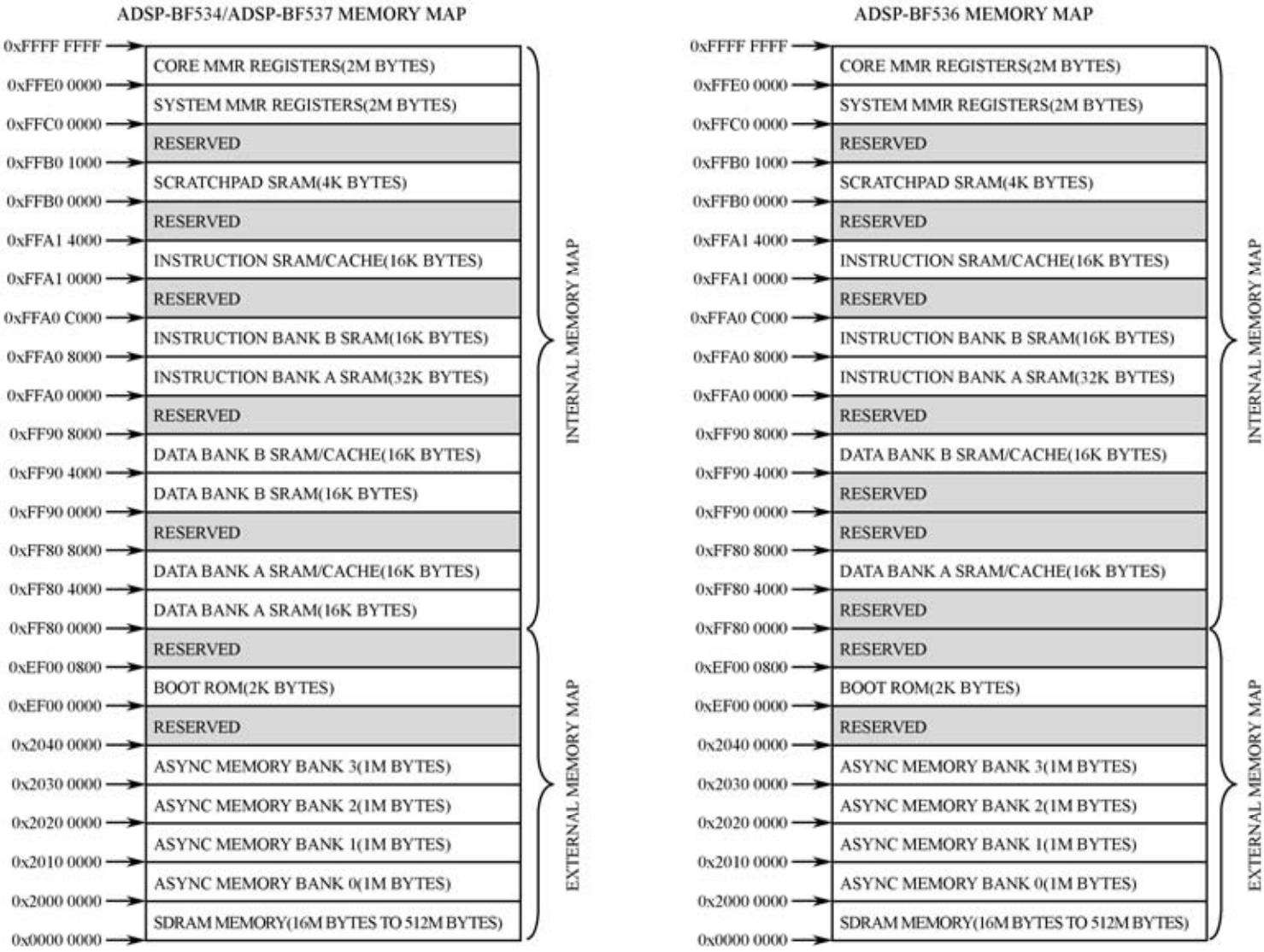
图2.12 Blackfin BF534/536/537内存配置
L1存储器安装类型分为指令存储器(Instruction Memory)、数据存储器(Data Memory)和暂存器(Scratchpad SRAM)。暂存器用于存储堆栈等需要高速性能的数据,以加快中断处理时的内容切换。指令存储器和数据存储器分为Bank A和Bank B两部分,分别对应于两条数据装载总线,因此需要并行处理的数据如果分别存放在Bank A和Bank B中是可以提高系统吞吐性能的。
前面已经提到L1存储器具有最高的执行效率,用好L1对于系统性能的提高是至关重要的。为了达到更优的数据吞吐性能,需要协调L1片内存储器和L3片外存储器之间的工作。有两种方法使用L1存储器:缓存(Cache)和动态加载。L1指令和数据存储器都可以配置为Cache和SRAM。
Cache是一种通用RISC处理器使用片内存储器的方法,如果Cache功能打开,内核在读取片外存储器中的指令或者数据时并不是仅仅读取所需要的部分,而是把同一内存页相邻的数据一起读进Cache中。Cache由多个Cache行组成,当下次读取指令或者数据时,内核首先在Cache中查找匹配的数据,如果有匹配的数据则不再去片外存储器读取,称为“Cache hit”,反之如果找不到匹配的数据称为“Cache miss”。如果发生“Cache miss”,Blackfin处理器采取一套机制来更新Cache行,重新去片外存储器读取需要的指令。Cache行的更新是通过L1和EBIU之间的外部存取总线(External Access Bus,EAB)来完成的。Cache通过CPLB表来管理,内存管理单元把所有的指令和数据内存分为多个内存页,每个内存页的大小可以配置,CPLB定义每个内存页是否需要被“Cache”。从Cache的工作原理来看,显然顺序执行的程序效率更高,而跳转较多的程序出现“Cachemiss”的概率较大,增加读取外存的操作,影响程序执行效率,因此尽量把顺序执行的程序放在一起可以提高程序效率。
动态加载是另外一种使用L1存储器的方式。DSP处理器区别于RISC处理器的地方在于DSP处理器是为密集运算设计的,因此用户希望能够手动控制DSP的所有资源以获得最佳性能,而不是由内核控制。Cache是一种内核自动控制的方法,而动态加载则是一种手工使用L1存储器的方法。可以把参与密集运算的指令和数据分别复制到L1存储器,然后进行运算,这样可以减少对外存的读写操作,绕过系统带宽瓶颈,提升运算速度。例如视频编码运算中的绝对差和SAD运算就是典型的密集运算例子,对它进行优化时可以采取这种方法,一方面通过DMA控制器把外存的数据复制到L1存储器,另一方面内核对已复制到L1存储器的数据进行加工,二者是并行的,明显提高了程序执行效率。
Blackfin处理器不是超标量结构,不能同时执行多条指令。但是在满足一定条件下可以执行64位长度的指令,实现并发功能。Blackfin的指令长度有三种:16位、32位和64位。1个64位长度的并发指令由1个32位指令和2个16位指令组成,指令的选择是有限制的,并非所有的32位和16位指令都可以组成64位并发指令,限制如下:
•32位指令是ALU或者MAC操作;
•16位指令只能有一个是回写操作;
•如果2条16位指令都是内存操作,那么不能使用P寄存器寻址。
Blackfin并发指令的限制是由其总线结构决定的,图2.11很清楚地表明内核与L1存储器之间只有1个64位指令总线、2个32位数据装载总线和1个数据回写总线。举例说明64位并发指令:
A1 += R0.L * R1.L, A0 += R0.H * R1.H || R0 = [I0++] || R1 = [I1++];
以上指令由1个32位MAC操作和2个16位数据加载操作组成,在计算MAC的同时加载寄存器R0和R1,为下次计算做好准备。