
下载掌阅APP,畅读海量书库
立即打开




线性表是最简单和最常用的一种数据结构,线性表是由相同类型的结点组成的有限序列。一个由n个结点a 0 ,a 1 ,…,a n-1 组成的线性表可记为(a 0 ,a 1 ,…,a n-1 )。线性表的结点个数为线性表的长度,长度为0的线性表称为空表。对于非空线性表,a 0 是线性表的第一个结点,a n-1 是线性表的最后一个结点。线性表的结点构成一个序列,对序列中两相邻结点a i 和a i+1 ,称a i 是a i+1 的前驱结点,a i+1 是a i 的后继结点。其中a 0 没有前驱结点,a n-1 没有后继结点。
线性表中结点之间的关系可由结点在线性表中的位置所确定,通常用(a i ,a i+1 )(0≤i≤n–2)表示两个结点之间的先后关系。例如,如果两个线性表有相同的数据结点,但它们的结点在线性表中出现的顺序不同,则它们是两个不同的线性表。
线性表的结点可由若干个成分组成,其中能唯一标识该结点的成分称为关键字,或简称键。为了讨论方便,往往只考虑结点的关键字,而忽略其他成分。
线性表包含的结点个数可以动态地增加或减少,也可以在任何位置上插入或删除结点。线性表常用的运算可分成几类,每类有若干种运算,如下所示。
在线性表中查找具有给定键值的结点。
在线性表的第i(0≤i≤n–1)个结点的前面或后面插入一个新结点。
删除线性表的第i(0≤i≤n–1)个结点。
● 统计线性表中结点的个数;
● 输出线性表各结点的值;
● 复制线性表;
● 线性表分拆;
● 线性表合并;
● 线性表排序;
● 按某种规则整理线性表。
线性表常用的存储方式有顺序存储和链接存储。
顺序存储是最简单的存储方式,通常用一个数组,从数组的第一个元素开始,将线性表的结点依次存储在数组中,即线性表的第i个结点存储在数组的第i(0≤i≤n–1)个元素中,用数组元素的顺序存储来体现线性表中结点的先后次序关系。
顺序存储线性表的最大优点就是能随机存取线性表中的任何一个结点。缺点主要有两个:一是数组的大小通常是固定的,不利于任意增加或减少线性表的结点个数;二是插入和删除线性表的结点时,要移动数组中的其他元素,操作复杂。
链接存储是用链表存储线性表(链表),最简单的是用单向链表,即从链表的第一个结点开始,将线性表的结点依次存储在链表的各结点中。链表的每个结点不但要存储线性表结点的信息,还要用一个域存储其后继结点的指针。单向链表通过链接指针来体现线性表中结点的先后次序关系。
链表存储线性表的优点是线性表的每个结点的实际存储位置是任意的,这给线性表的插入和删除操作带来方便,只要改变链表有关结点的后继指针就能完成插入或删除的操作,不需移动任何表元。链表存储方式的缺点主要有两个:一是每个结点增加了一个后继指针成分,要花费更多的存储空间;二是不方便随机访问线性表的任一结点。
线性表上的查找运算是指在线性表中找某个键值的结点。根据线性表中的存储形式和线性表本身的性质差异,有多种查找算法,例如顺序查找、二分法查找、分块查找、散列查找等。其中二分法查找需要线性表是一个有序序列。
设线性表结点的类型为整型,插入之前有n个结点,把值为x的新结点插在线性表的第i(0≤i≤n)个位置上。完成插入主要有以下步骤。
● 检查插入要求的有关参数的合理性;
● 把原来的第n – 1个结点至第i个结点依次往后移一个数组元素的位置;
● 把新结点放在第i个位置上;
● 修改线性表的结点个数。
在具有n个结点的线性表上插入新结点,其时间主要花费在移动结点的循环上。若插入任一位置的概率相等,则在顺序存储线性表中插入一个新结点,平均移动次数为n/2。
在链接存储线性表中插入一个键值为x的新结点,分以下4种情况。
● 在某指针p所指结点之后插入;
● 插在首结点之前,使待插入结点成为新的首结点;
● 接在线性表的末尾;
● 在有序链表中插入,使新的线性表仍然有序。
在有n个结点的线性表中,删除第i(0≤i≤n–1)个结点。删除时应将第i+1个表元至第n–1个结点依次向前移一个数组元素的位置,共移动n–i–1 个结点。完成删除主要有以下几个步骤。
● 检查删除要求的有关参数的合理性;
● 把原来第i+1个表元至第n–1个结点依次向前移一个数组元素的位置;
● 修改线性表表元个数。
在具有n个结点的线性表上删除结点,其时间主要花费在移动表元的循环上。若删除任一表元的概率相等,则在顺序存储线性表中删除一个结点,平均移动次数为n/2。
对于链表上删除指定值结点的删除运算,需考虑几种情况:一是链表为空链表,不执行删除操作;二是要删除的结点恰为链表的首结点,应将链表头指针改为指向原首结点的后继结点;其他情况,先要在链表中寻找要删除的结点,从链表首结点开始顺序寻找。若找到,执行删除操作,若直至链表末尾没有指定值的结点,则不执行删除操作。完成删除由以下几个步骤组成。
● 如链表为空链表,则不执行删除操作;
● 若链表的首结点的值为指定值,更改链表的头指针为原首结点的后继结点;
● 在链表中找指定值的结点;
● 将找到的结点删除。
栈是一种特殊的线性表,栈只允许在同一端进行插入和删除运算。允许插入和删除的一端称为栈顶,另一端称为栈底。称栈的结点插入为进栈,结点删除为出栈。因为最后进栈的结点必定最先出栈,所以栈具有后进先出的特征。
可以用顺序存储线性表来表示栈,为了指明当前执行插入和删除运算的栈顶位置,需要一个地址变量top指出栈顶结点在数组中的下标。
栈也可以用链表实现,用链表实现的栈称为链接栈。链表的第一个结点为顶结点,链表的首结点就是栈顶指针top,top为NULL的链表是空栈。
队列也是一种特殊的线性表,只允许在一端进行插入,另一端进行删除运算。允许删除运算的那一端称为队首,允许插入运算的一端称为队尾。称队列的结点插入为进队,结点删除为出队。因最先进入队列的结点将最先出队,所以队列具有先进先出的特征。
可以用顺序存储线性表来表示队列,为了指明当前执行出队运算的队首位置,需要一个指针变量head(称为头指针),为了指明当前执行进队运算的队尾位置,也需要一个指针变量tail(称为尾指针)。
若用有N个元素的数组表示队列,随着一系列进队和出队运算,队列的结点移向存放队列数组的尾端,会出现数组的前端空着,而队列空间已用完的情况。一种可行的解决办法是当发生这样的情况时,把队列中的结点移到数组的前端,修改头指针和尾指针。另一种更好的解决办法是采用循环队列。
循环队列就是将实现队列的数组a[N]的第一个元素a[0]与最后一个元素a[N–1]连接起来。一般地,用tail指向队尾元素的下一个位置(注意,并不是指向最后一个元素本身),用head指向队头元素。队空的初态为 head=tail=0。在循环队列中,当tail 赶上head时,队列满。反之,当head赶上tail时,队列变为空。这样队空和队满的条件都同为head=tail,这会给程序判别队空或队满带来不便。因此,可采用当队列只剩下一个空闲结点的空间时,就认为队列已满,用这种简单办法来区别队空和队满。即对空的判别条件是head=tail,队满的判别条件是head=(tail+1)%N。
队列也可以用链接存储线性表实现,用链表实现的队列称为链接队列。链表的第一个结点是队列首结点,链表的末尾结点是队列的队尾结点,队尾结点的链接指针值为NULL。队列的头指针head 指向链表的首结点,队列的尾指针tail指向链表的尾结点。当队列的头指针head值为NULL时,队列为空。
在计算机中存储一个矩阵时,可使用二维数组。例如,M×N阶矩阵可用一个数组a[M][N]来存储(可按照行优先或列优先的顺序)。如果一个矩阵的元素绝大部分为零,则称为稀疏矩阵。若直接用一个二维数组表示稀疏矩阵,则会因存储太多的零元素而浪费大量的内存空间。因此,通常采用三元组数组或十字链表两种方法来存储稀疏矩阵。
稀疏矩阵的每个非零元素用一个三元组来表示,即非零元素的行号、列号和它的值。然后按某种顺序将全部非零元素的三元组存于一个数组中。
如果只对稀疏矩阵的某些单个元素进行处理,则宜用三元组表示。
在十字链表中,矩阵的非零元素是一个结点,同一行的结点和同一列的结点分别顺序循环链接,每个结点既在它所在行的循环链表中,又在它所在列的循环链表中。每个结点含5个域,分别为结点对应的矩阵元素的行号、列号、值,以及该结点所在行链表后继结点指针、所在列链表后继结点指针。
为了处理方便,通常对每个行链表和列链表分别设置一个表头结点,并使它们构成带表头结点的循环链表。为了方便引用某行某列,全部行链表的表头结点和全部列链表的表头结点分别组成数组,这两个数组的首结点指针存于一个十字链表的头结点中,最后由一个指针指向该头结点,如图1-1所示。
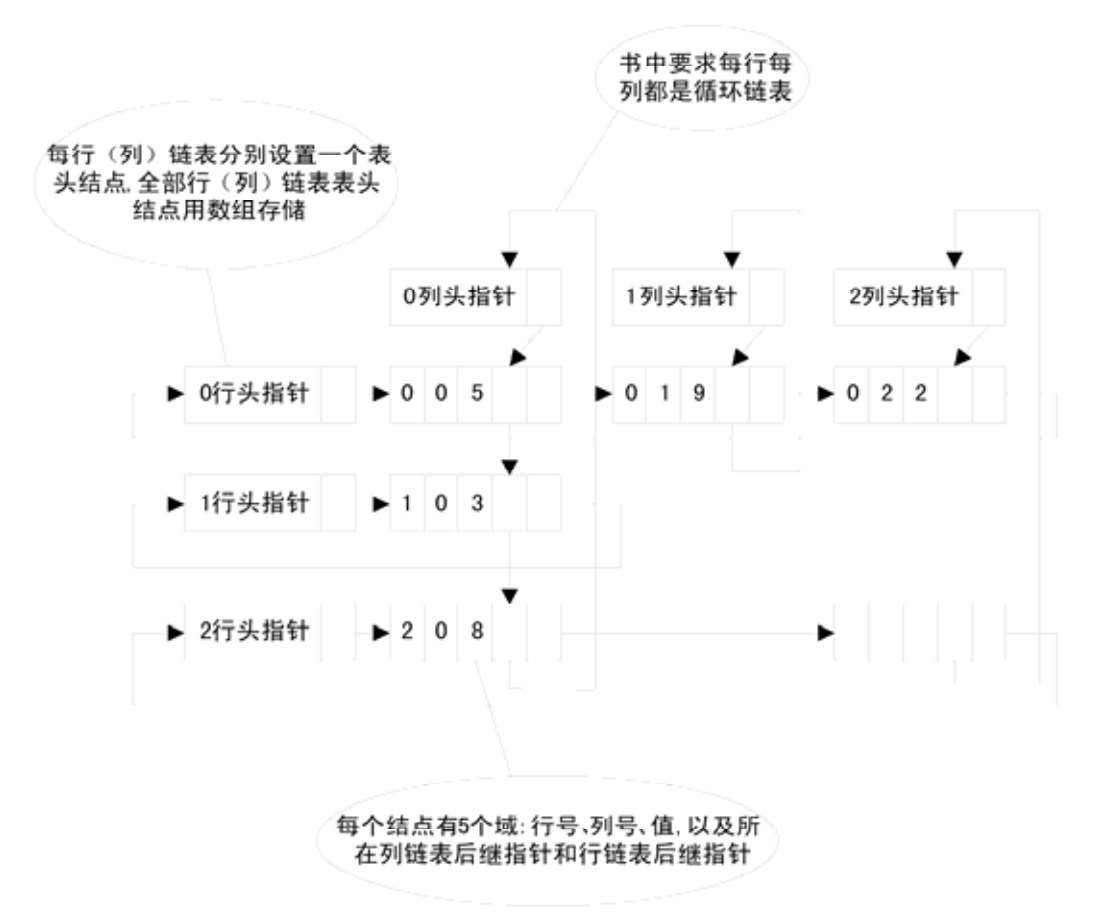
图1-1 十字链表
如果对稀疏矩阵某行或某列整体进行某种处理,可能会使原来为零的元素变为非零,而原来为非零的元素可能变成零。对于这种场合,稀疏矩阵宜用十字链表来表示。
字符串是由某字符集上的字符所组成的任何有限字符序列。当一个字符串不包含任何字符时,称它为空字符串。一个字符串所包含有效字符的个数称为这个字符串的长度。一个字符串中任一连续的子序列称为该字符串的子串。
字符串通常存于足够大的字符数组中,每个字符串的最后一个有效字符之后有一个字符串结束标志,记为'\0'。通常,由系统提供的库函数形成的字符串末尾会自动添加'\0',但是由用户的应用程序形成字符串时,必须由程序自行负责在最后一个有效字符之后添加'\0',以形成字符串。
对字符串的操作通常有:
● 统计字符串中有效字符的个数;
● 把一个字符串的内容复制到另一个字符串中;
● 把一个字符串的内容连接到另一个足够大的字符串的末尾;
● 在一个字符串中查找另一个字符串或字符;
● 按字典顺序比较两个字符串的大小。