
下载掌阅APP,畅读海量书库
立即打开




航班控制系统和旅客离港系统等数据库中往往存在不完整、含噪声和不一致的数据。这些数据库的结构可能是不同的,而且即便是同一个数据库中也可能存在重复的、缺失的、含噪声的数据,这些不完整的、含噪声的和不一致的数据将会影响数据挖掘的效率、降低数据挖掘结果的准确性,甚至造成错误的挖掘结果。为了给数据挖掘工作提供正确、干净的数据,在进行数据挖掘前,对数据进行预处理是非常必要的。
非空间数据的预处理,这里指的是从航班控制系统、旅客离港系统等数据源到客流预测及预警数据集市、行李需求预测数据集市和航班延误空间分析数据集市的ETL过程。图2-9所示为非空间数据的ETL流程,本节重点介绍数据清理和数据转换部分的内容。
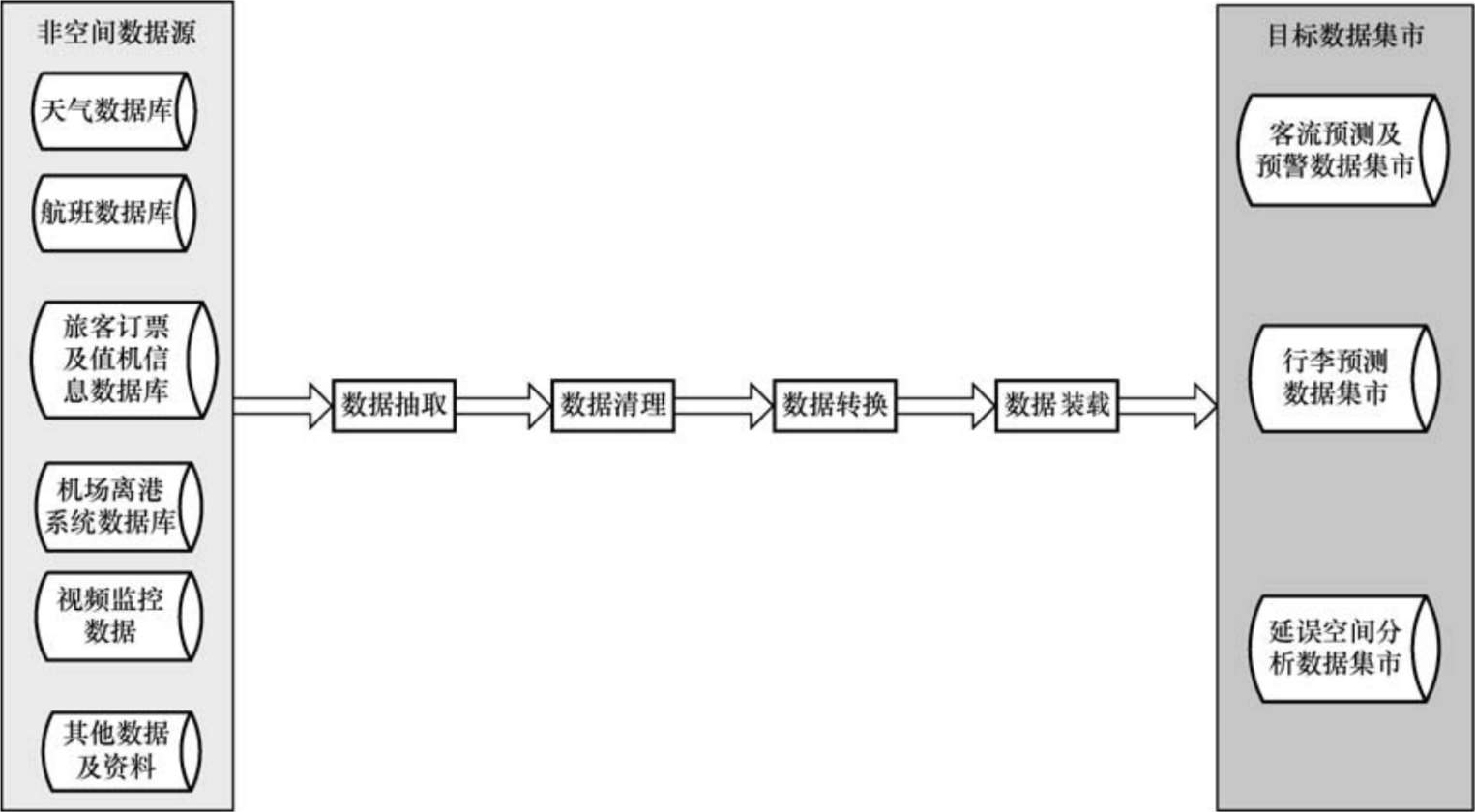
图2-9 非空间数据的ETL流程
对于数据库字段值缺失的问题,已经有很多有效的方法,如删除含缺失值的元组、人工填写法、随机抽取替代法、均值替代法、最近临域替代法、多重填补法、基于期望最大化算法的替代法和回归法等常见的填补方法。但具体采用何种方法还要根据具体情况来决定 [19][20] 。
由于旅客流量预测及预警需要基于各时段到达航站楼的旅客数据量来进行,旅客值机时刻可以被近似地作为旅客到达航站楼的时间。因此,值机系统数据库中旅客值机记录中的值机时刻字段的值对航站楼旅客流量预测及预警至关重要,需要采取有效措施谨慎地处理该字段值缺失的问题,科学合理的处理方法对确保旅客流量预测的正确性将起到关键作用。利用数据挖掘软件SPSS Modeler,对旅客值机时刻值缺失的处理流程如图2-10所示。
首先从数据库中读取旅客值机信息表,读取各字段类型值并过滤出航班ID字段及值机时刻字段;然后分别汇总各航班的旅客记录和缺失值机时刻的旅客记录,并将两个记录集以航班的FLTID为关键字进行连接操作。由于部分旅客记录的值机时刻值缺失,故将这部分旅客记录的值机时刻值字段填充为0,如图2-11所示。
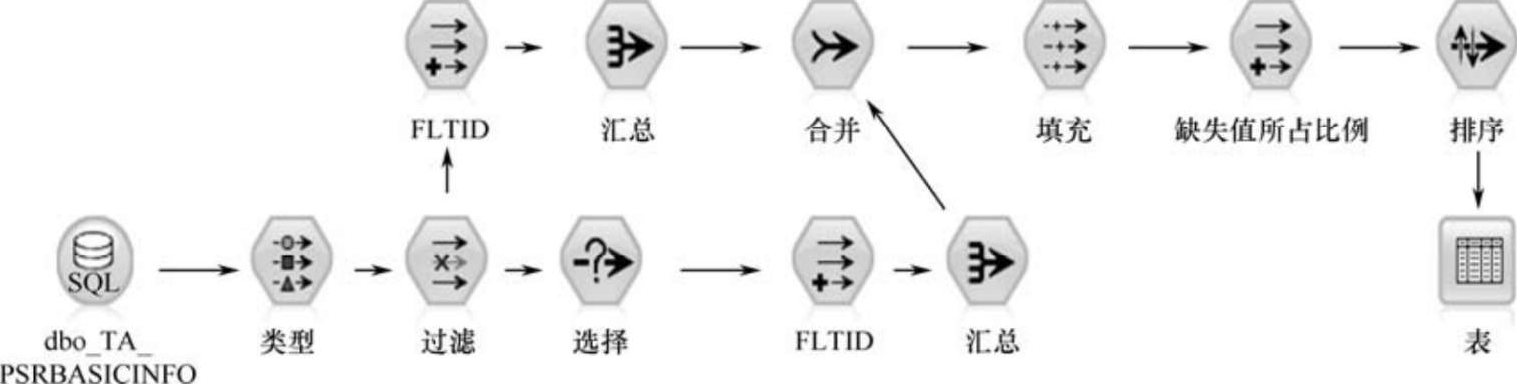
图2-10 缺失值分析数据处理流程图
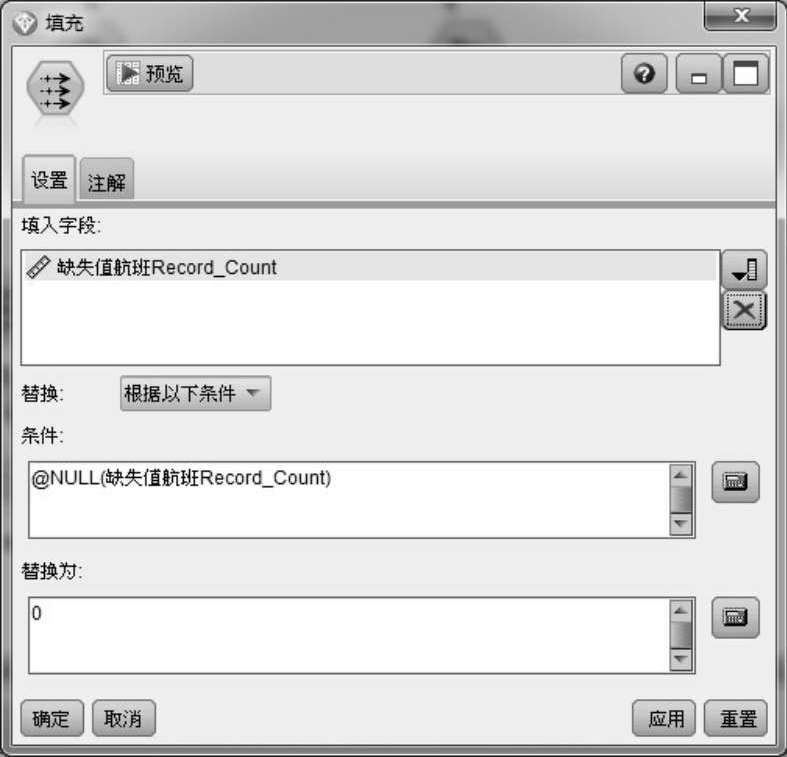
图2-11 缺失值为空的填充操作
对上述操作的结果,统计每个航班缺失值机时刻值的旅客记录数占该航班值机总人数的比例(可通过按公式导出一个缺失值所占比例字段的方法获得该比例),按照该比例对航班进行排序,如图2-12所示。
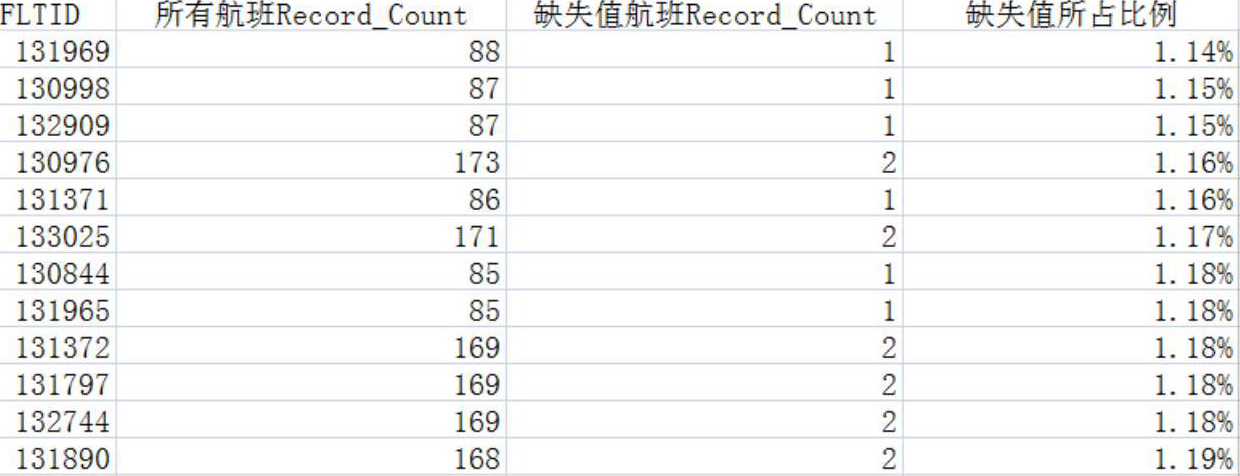
图2-12 航班旅客值机时间缺失值统计结果截图
经过统计5月1日到6月3日共计3049个国内国际航班,其中518个航班不存在值机时刻字段缺失值的情况,存在值机时刻字段缺失值的2039个航班中,旅客值机时刻字段值缺失的比率平均小于等于5%,334个航班旅客值机时刻字段值缺失的比率平均大于5%小于等于10%。58个航班旅客值机时刻字段值缺失的比率平均大于10%小于等于20%,11个航班旅客值机时刻字段值缺失的比率平均大于20%小于等于50%,46个航班旅客值机时刻字段值缺失的比率平均大于50% 小于100%,43个航班旅客值机时刻字段值缺失的比率高达100%。再对缺少值机时刻值的旅客按日进行汇总分析,汇总结果如图2-13所示。
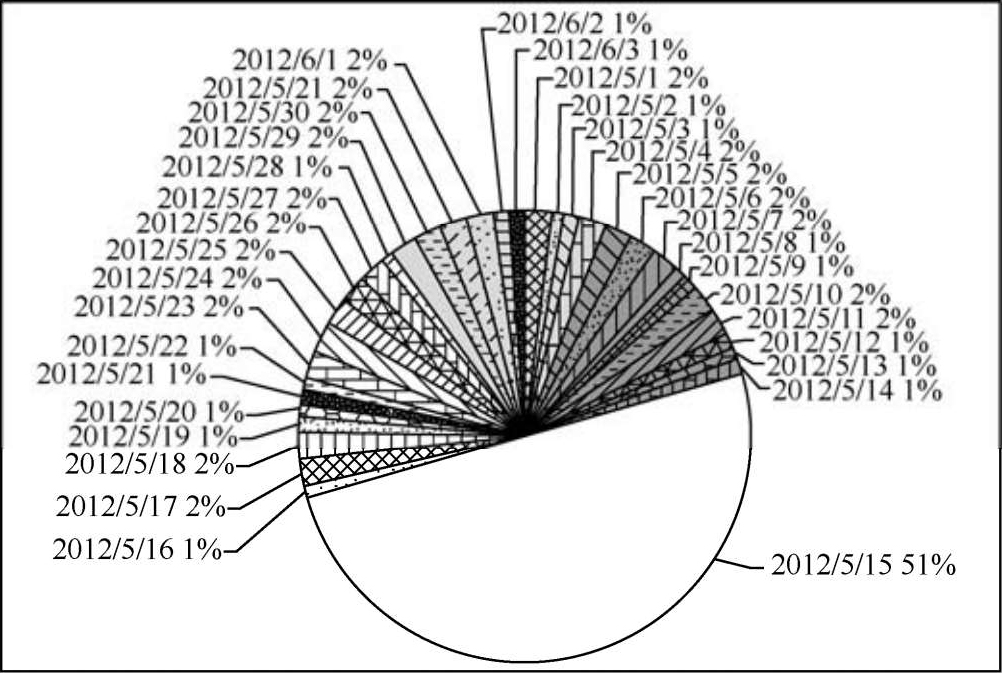
图2-13 旅客值机时刻缺失值日汇总图
由图2-13可以看出,缺少值机时刻值的旅客记录51% 集中在5月15日这一天,而其他各天缺少值机时刻值的旅客记录占比例仅占1% 或2%,因此首先需要对5月15日的航班进行深入分析。分析结果显示旅客值机时刻值缺失比率大于50%的航班共计91个,其中86个航班的起飞日期为5月15日,这86个航班ID连续地从131478一直到131563。而且,这86个航班中有值机时刻值的记录也均为错误的记录,值机时刻均为5月14日,因此,可判断:在旅客值机期间,值机系统存在故障。通过统计每日航班总数发现5月15日航班总数达到172,已经远超过其他每日航班数,统计结果如图2-14所示。而且5月15日离港旅客记录的总数共计19750(含缺少值机时刻值的旅客记录),已远超其他日离港人数。
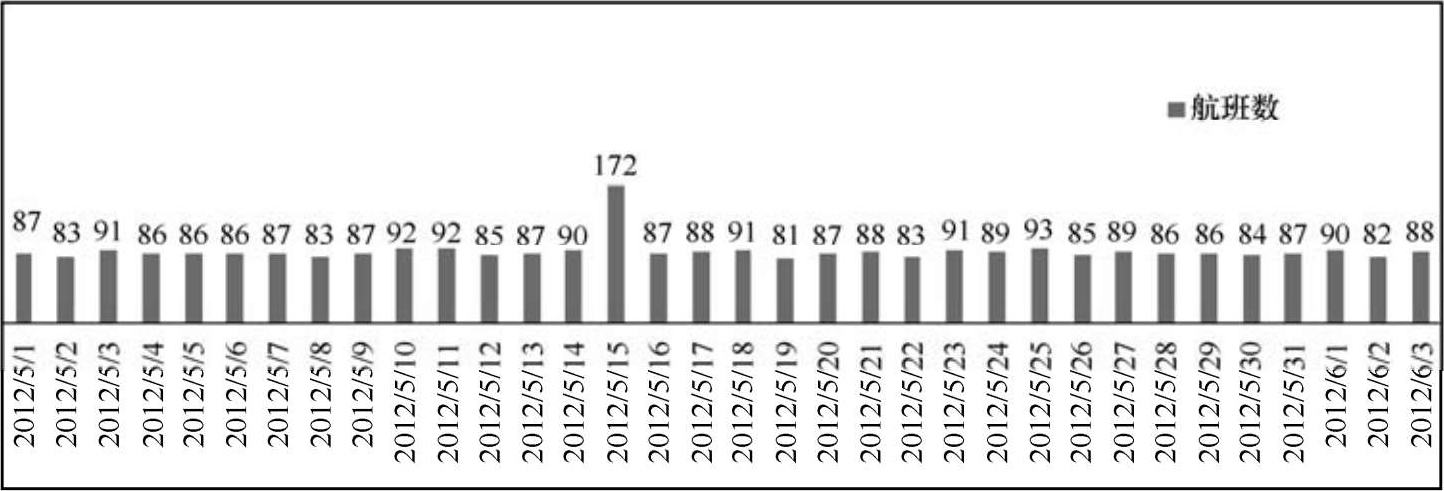
图2-14 日航班数分析图
通过上述分析初步判断:5月15日大多数航班都产生了两次旅客值机记录,一次值机是在值机系统故障状态下进行的(造成了大量记录没有值机时刻的值),另一次是在值机系统正常状态下进行的。为验证此判断,对5月15日共计172个航班进行了同航班重复查询,如图2-15所示。
经查询,172个航班记录中85个航班号有2个不同FLTID的,共计170个航班记录,而只有2个航班记录的航班号是唯一的。这85个航班为重复的含缺失值的航班记录,FLTID从131478一直到131562,缺失率均达到80%以上,对于这85个航班记录采用直接删除操作(因这些航班的旅客值机记录已经存,并非真正缺失)。再分析那2个航班号唯一的航班记录,其中FLTID为131650的航班没有缺失值,ID为131563的航班缺失值则达到了100%,对于此航班将与其他各日有缺失值的航班统一处理。
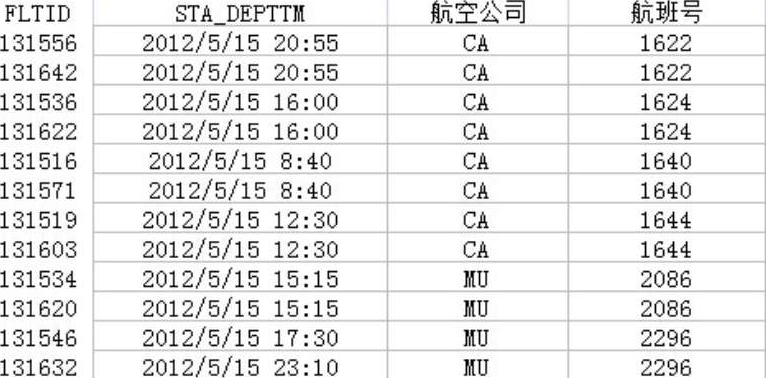
图2-15 航班重复记录查询
值机时间缺失的可能原因很复杂,分为系统原因和人为原因。系统原因如某航空公司某一时间段内柜台值机系统出现故障,导致这一时段内所有或个别值机旅客的时间未能记录。也有可能是“假缺失值”,即缺失值机时刻值的旅客记录在同航班中还有一条与之对应的有值机时刻值的旅客记录。而对于人为原因,可能是由于乘客误了航班时间导致无法值机、乘客放弃乘坐该航班或改签其他航班等多种可能性。
对于缺失值的处理大致分为两类:一类为对含缺失值的记录进行删除;另一类是对缺失的值进行填充。本例中旅客值机时刻作为分析旅客到达航站楼时刻的重要依据,在数据预处理阶段无法利用已有的缺失值填充方法有效填补值机时刻字段的缺失值,若填补缺失值不准确将会对航站楼旅客流量预测的结果产生直接影响,因此,对含值机时刻字段缺失值的记录采用删除操作进行处理。删除缺少值机时刻值的记录有两种方式。第一种是只将缺少值机时刻值的记录删除,第二种不仅将缺少值机时刻值的记录删除,还要将缺少值机时刻值的记录所对应的航班记录一并删除。
对缺失率小于等于10%的航班,采取第一种方式直接删除缺少值机时刻值的记录,因为这些记录中的缺失值一部分是假缺失值,另一部分是未值机或改签其他航班,还有部分缺失值可能是由于系统未能成功记录造成的,前两种缺少值机时刻值的记录删除都不会研究对旅客到达航站楼的规律造成什么影响,而少数因系统未能记录值机时刻产生的记录并不会对旅客到达航站楼的整体规律造成多大影响。
对于值机时刻值缺失率大于50%的91个航班,5月15日的85个航班已经删除,针对其余6个航班记录将采取第二种方式将整个航班记录都删除,因为这些航班在值机期间系统出现故障,个别有效值也不能反映整体的旅客到达规律。
对于值机时刻值缺失率在10%到50%之间的共计69个航班,根据航班起飞时刻所处时段的航班数量、乘坐航班的旅客总数、假缺失值记录占缺失值记录的比率以及该时段值机系统是否存在故障来衡量采用第一种方式还是第二种方式,也就是根据实际情况并考虑删除记录给研究航站楼旅客流量整体规律带来的影响来决定最终的删除方式,如航班ID为132603的航班缺失率36.17%,但该航班旅客的值机记录记载的旅客值机时刻与飞机计划起飞时刻相距过长,由此判断是值机系统故障所至,故采取第二种删除策略。
按照上述方法对没有旅客值机时刻的旅客记录所对应的航班进行处理,最终保留的有效航班数为2951。
由于旅客离港系统数据库中旅客性别字段PSR_GENDER存在大量的缺失值及一些无效的值,为填补缺失的及修正错误的旅客性别字段的值,利用旅客记录中的中国旅客所具有的身份证号来进行性别推导。中国公民的18位身份证号第17位是性别的判别,若第17位为奇数,则为男性,偶数则为女性。
通过生成的新字段GENDER可以将缺失的旅客性别值填充或对已有的性别值进行修改。但由于少部分旅客身份证件号是缺失或不完整的,以及一些外国的旅客没有身份证号,因此修正后的性别字段依然有一些缺失值,对这些比例很小的没有旅客性别值的记录,只能根据旅客的名字,人工判别旅客的性别,填写旅客性别字段的缺失值。
本例中的重复记录主要包含以下情况:同一日内同一航班两次及以上的离港记录、同一航班同一旅客两次及以上的离港记录。其中重复航班记录已经在前面旅客值机时刻字段值缺失处理部分中介绍,以下是介绍对同一航班重复旅客记录的处理方法。
在SPSS Modeler软件中选择汇总节点,按照航班ID、旅客姓名、证件号码进行汇总操作并生成记录数,生成的结果为同一个航班中同一个旅客的记录数,正常情况下一个旅客在同一个航班中只有一个记录,因此记录数大于1的旅客为重复记录。通过选择节点选取记录数大于1的数据,结果共有157个旅客具有重复记录,每条重复记录数在2至10之间。
对这157名旅客再进行深入分析,按照其值机时间进行汇总,发现其中50个旅客的重复记录中值机时间是相同的,也就是说这部分旅客在同一分钟值机两次,其原因可能是值机系统故障或办理值机工作人员误操作导致,对于此类重复记录只保留其中一条。还有43名旅客重复记录的值机时间在5分钟以内,此类数据与值机时间相同的重复记录类似,但在处理时选择保留值机时间较早的记录。其余的重复旅客记录值机时间都相差5分钟以上,在研究数据的过程中发现此部分旅客中有一些虽然拼音名字及证件号相同,但中文汉字的名字却在其中某个字上有差异,分析这些旅客可能是由于第一次值机时名字输入有问题导致二次值机。对这部分数据处理首先看同一旅客重复记录中是否有行李托运记录,有行李托运则保留此记录,若都没有托运记录则保留值机时间较早的记录。
研究各时段到达航站楼的旅客人数以及旅客提前多久到达航站楼所涉及的错误及噪声主要是旅客的值机时间和航班的计划起飞时间。由于无法直接判断这两类数据哪些是错误及哪些是噪声数据,因此引入它们的差值作为辅助。本例定义提前到达时长为航班的计划起飞时间与该航班旅客值机时间的差,即在航班未延误情况下从旅客到达航站楼到飞机起飞前的这段时间。在SPSS Modeler中用离港航班数据表的DEPTTM字段与旅客值机数据表的CKITIME字段通过time_mins_difference函数及date_days_difference函数生成旅客先于飞机起飞时刻到达航站楼的时长,分别以分钟为单位及天为单位进行存储。以分钟为单位计算时SPSS Modeler算法存在瑕疵,计算时不考虑时间记录中对应的日期部分,只是用对应的时间部分相减,导致乘坐凌晨时段航班的旅客先于飞机起飞时刻到达航站楼的时间出现负值,因此还需要在数据库中通过DateDiff("n",[PSR_CKITIME],[STA_DEPTTM])函数生成的字段值对这部分负值进行修正。以天为单位字段的作用是辅助异常值的发现。生成该字段的流程如图2-16所示。
旅客先于飞机起飞时刻到达航站楼时长的字段生成后,异常数据便浮现出来。接下来将异常数据归类并介绍每类异常数据的处理方法。
少数旅客先于飞机起飞时刻到达航站楼时长(分钟)字段的值出现负值,即“值机时间反而比航班起飞时间要晚”。这种异常数据的产生,可能是个别旅客值机期间系统故障所致或航班计划起飞时刻字段值存在问题。通过观察发现这些数据集中在个别的几个航班记录中,因此,要结合该航班其他旅客到达航站楼的时间以及该航班在不同日期的计划起飞时间综合分析导致旅客先于航班计划起飞时刻提前到达航站楼的时长为负值的原因。
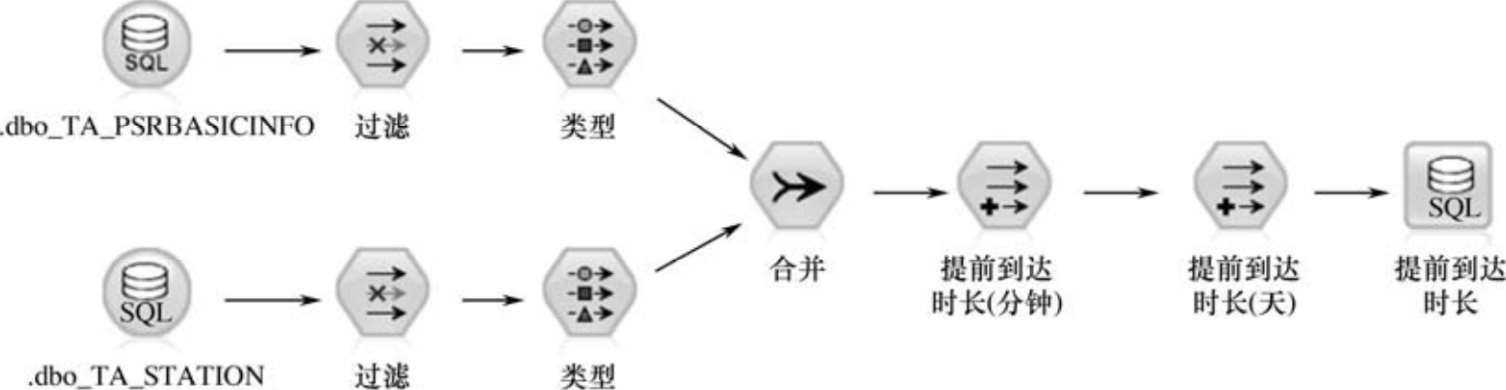
图2-16 提前到达时长字段生成
如图2-17所示,航班ID为132138的GS6486号航班,该航班不仅有11名提前到达航站楼的时长为负数的旅客,而且还有很多旅客提前到达时长不足半小时(这与先行机场管理条例中提前半小时截止值机的规定相违)。再观察GS6486往日的飞机计划起飞时刻大多为12:50,由此可判断132138航班的旅客提前到达航站楼的时长为负值是由于飞机计划起飞时刻字段值错误所致,需要将飞机计划起飞时刻字段值改正后重新生成旅客提前到达航站楼的时长。
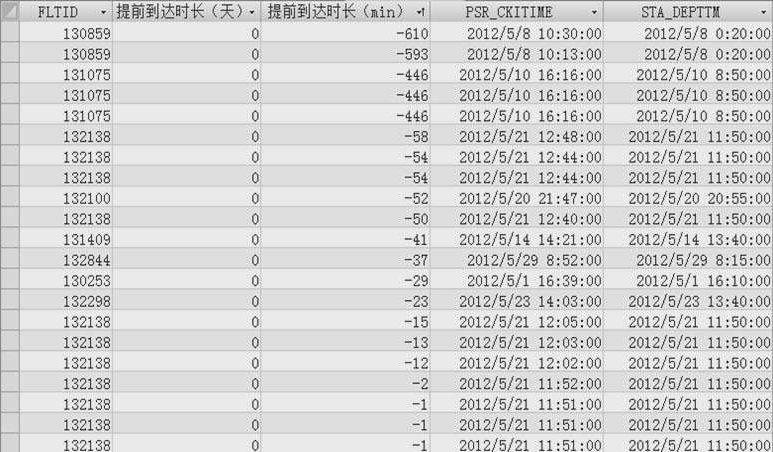
图2-17 提前时长负值数据截取图
对ID为130859的航班也可按照上述的思路分析,发现该航班只有2人的提前到达航站楼时长为负值,可能由系统故障所致,因此将这2人的值机记录从系统中直接删除。
本例使用的数据来源于国内某机场,该机场2012年关于旅客办理值机手续的规定如下:一般旅客值机截止时间为航班起飞前的30分钟,在航班起飞前15~30分钟内到达航站楼的旅客可以去专门为这些旅客服务的柜台办值机手续,但若旅客先于飞机起飞时刻不足15分钟到达航站楼,则不允许其办理值机手续登机。根据该规定,将先于飞机起飞时刻不足15分钟到达航站楼的旅客记录视为异常,并对这些记录进行分析,如图2-18所示。
处理这类记录的思路与处理提前到达时长为负值的思路类似,也是从这些记录对应航班全体旅客的角度及该航班历史起飞时刻两个方面加以分析,目的是寻找如132138这种提前到达时长不足15分钟的旅客所乘坐的航班。分析结果显示先于飞机起飞时刻不足15分钟到达航站楼的旅客共计82个。这些记录分别对应于不同的航班,绝大多数情况下一个航班只有一到两个记录对应,因此,可将其视为系统噪声予以删除。提前到达时长不足15分钟的旅客所乘坐的航班中可能包括提前到达时长为负值的旅客所乘坐的航班(如132138),由于这些航班已经更改了航班计划起飞时间,因此,保留这些航班记录。
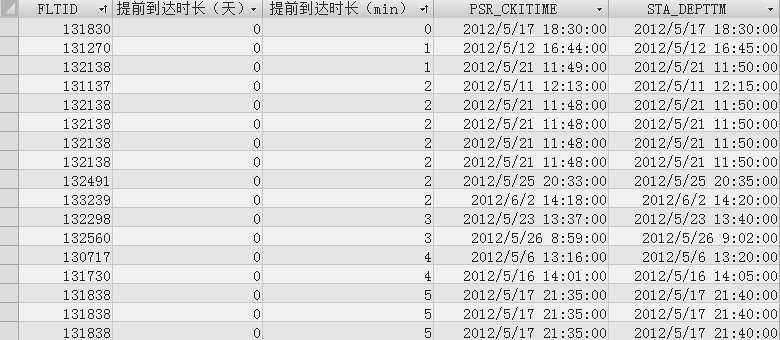
图2-18 提前时长不足15分钟的旅客记录截图
观察本例的数据,发现很多旅客提前到达航站楼的时长超过360分钟,有的旅客甚至提前1800分钟就办理了值机手续。虽然本例中的机场在春秋季节执行的是全天开放值机(即对于当天离港的航班,旅客可随到随值机),但是这部分旅客先于航班计划起飞时刻提前值机的时长超乎常理,且数量较多。通常情况下,很少会有旅客提前6小时或更长时间便来到机场办理值机手续。经过对数据进行分析,发现导致旅客先于航班计划起飞时刻提前到达航站楼进行值机的时长过大可能有以下几种情况:第一种是旅客进行了网上值机,这部分旅客在去机场前便在网上办理了值机手续并自行打印了登机牌,因此,这部分旅客提前值机时长过长是合理的,他们是提前值机时长过长旅客的绝大部分;第二种是旅客确实由于种种原因在飞机起飞前很长时间到达航站楼办理了值机手续,这部分旅客提前到达航站楼办理值机手续的时长过长也是合理的;第三种情况是某个航班在某一日旅客提前办理值机手续的时长总体要比其他各日提前办理值机手续的时长明显偏大,比如MU5662航班在5月13日的116名旅客中先于飞机起飞提前值机手续的时长最短的是为192分钟,而该航班在其他各日旅客提前值机的时长在180分钟以内的为绝大多数,因此,判定该航班离港时刻出现异常。深究其原因,发现该航班记录中计划起飞时间为19:30,而该航班在其他各日的计划起飞时间大多为17:00。通过与机场工作人员咨询,得知该机场根据季节变化调整航班计划,航班计划调整期间会增加或取消一些线路的航班,航班时刻也会有所调整。有的航班计划起飞时刻推迟了,但先前订票的旅客未接到通知,依然根据更改前的航班时刻安排到达机场值机的时间,导致了该航班旅客整体提前到达航站楼进行值机的时长过长。对于第三种情况,需要特殊处理。
首先要找到因航班计划季节性调整导致的航班计划起飞时刻发生变化的航班。单从数据库中的记录无法识别出这些航班,因此,需要借助其他辅助信息找出这些航班,然后再根据该航班在其他日期的计划起飞时刻来修改此航班的计划起飞时刻,以便于利用旅客值机时刻的数据,发现旅客距离飞机起飞时刻提前到达航站楼的时长所具有的规律。
以FLTID为关键字设计表的模式,每个元组中包含该航班的航空公司代码及航班号、航班的计划起飞时刻、航班计划起飞时刻所处的时段、该航班值机旅客的数目,以及该航班所有旅客先于航班计划起飞时刻提前到达航站楼的时长均值及标准差,如图2-19所示。
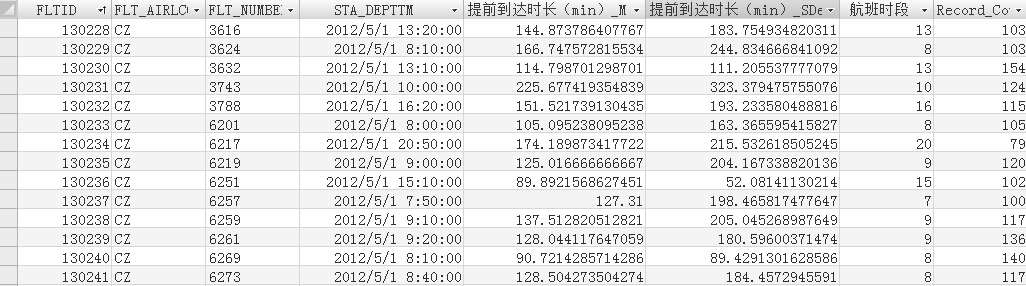
图2-19 航班旅客提前情况分析
形成的表共有2951个航班记录,这些记录分属于126个航班。利用这126个航班对应的多日多个航班记录(每个航班记录具有不同FLTID)的提前到达时长均值、方差以及航班计划起飞时刻综合判断,最终找出因航班计划季节性调整导致的航班计划起飞时刻发生变化的航班。根据统计学知识,不同日期的同一航班(相同的航班号)旅客先于飞机计划起飞时刻提前到达航站楼的时长均值不会出现非常显著差异。若某日乘坐某航班(以航班号标识)的旅客提前到达航站楼时长的均值显著大于其他各日乘坐该航班的旅客提前到达航站楼时长的均值,并且航班的计划起飞时刻也较其他各日有所推迟,那么,该航班可能为受航班计划调整影响而推延计划起飞时刻的航班,再根据该航班所有旅客提前到达航站楼时长最终做出判断。
以航班号为MU5662航班为例,该航班共有34天的航行记录,从图2-20的数据表截图可看出,5月13日航行记录显示乘坐MU5662航班的旅客提前到达航站楼的时长均值显著高于其他各天的记录,而且该记录中的计划起飞时间也都比其他记录要晚,因此,初步断定该航班可能是我们要找的航班。接下来再进入5月13日FLTID为131363的航行记录对应的旅客记录表中进行分析,发现所有旅客提前到达航站楼的时长均介于192分钟到583分钟之间,而旅客值机的时刻与其他正常各日旅客值机时刻大致相符,即旅客值机时刻与乘坐17:00起飞的MU5662航班的旅客的值机时刻基本相符。因此,最终断定该航班是因航班计划季节性调整而推延了计划起飞时刻,将FLTID为131363的航行记录的航班计划起飞时刻字段的值改成17:00。
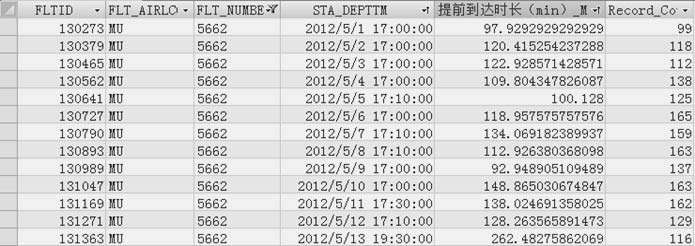
图2-20 提前时长异常航班分析
采用相同的分析方法对所有的126个航班共计2591次航行记录进行分析。注意,有一些航班的航行记录中,虽然飞机计划起飞时刻较其他航行记录中的飞机计划起飞时刻有所延后,但旅客提前到达航站楼的时长的均值没有大的变化,对于这些航行记录中的飞机计划起飞时刻字段的值不作调整。
在对航行记录进行分析的过程中,发现FLTID为130945的记录中旅客提前到达航站楼的时长均值为1339分钟,远超于其他航行记录中的旅客提前到达航站楼的时长均值,153名旅客中有146人提前到达航站楼的时长超过1300分钟,而这部分人中只有少数几人为网上值机旅客,对于造成此航行记录中旅客提前到达航站楼时长异常的原因尚不明确,但此航行记录的数据不能用于对旅客提前到达航站楼的时长进行分析,故进行删除处理。
对共计2951次航行记录深入分析后,判定其中的127个航行记录中的飞机计划起飞时刻受到航班计划季节性调整的影响,对这些航行记录中的飞机计划起飞时刻字段值进行了相应的修正,处理过程如图2-21所示。
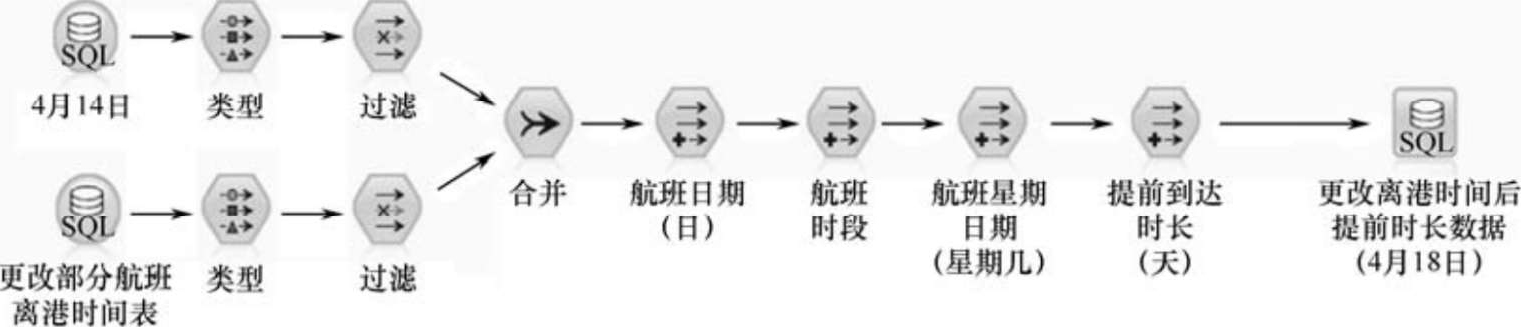
图2-21 飞机计划起飞时刻字段值的修正过程
不同数据库中相同语义字段的名称可能会不同,在进行数据集合并操作时,需要将这些语义相同的字段值映射到同一字段名标识的字段,典型的例子就是几个数据库中的航行记录标识字段的名称不一致,将FLTID、FLT_ID等语义相同的字段的值都映射到FLTID标识的字段。
根据数据分析的需求,在数据模型中添加数据源数据库没有的字段。以多维数据模型的时间维表为例,根据航班的计划起飞时刻的年份、季度、月份、日期、星期几、时段以及是否是节假日字段都是按照分析需要添加的字段,如图2-22所示。
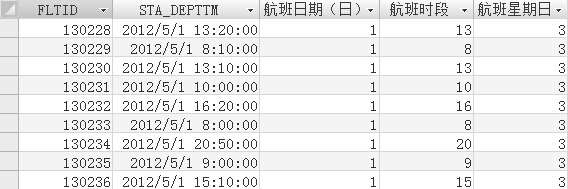
图2-22 时间维表示例
为了获得每半小时到达航站楼的旅客人数,首先根据值机时刻生成半小时时段,使每一个值机时刻都有对应的半小时时段。
在航班类型维表,添加航班目的地字段,来标识航班是国内航班还是国际航班。如CAN代表广州白云国际机场,从而得知该航班为国内航班。在航班延误事实表中添加航班延误时间及延误机场间距离数据字段。
值机系统中拥有每名旅客的值机记录,而航站楼旅客流量预测及预警需要每半小时到达航站楼的乘坐某航班的旅客数量作为客流量预测及预警的基础数据。航站楼旅客服务资源的调度需要的旅客流量数据是航班级的,如值机柜台的调度,而航空公司或机场需要的是航空公司级和机场航站楼级别的数据。因此,按照数据分析对数据粒度的要求,将旅客级粒度的数据聚集为航班级粒度的数据,再根据需要将航班级粒度的数据聚集为航空公司级粒度的数据,装载到数据集市中。同样,行李数量也需要从旅客级聚集到航班级,再聚集到航空公司级。
对于业务规则的计算,可参见本章2.8节,先于航班离港时刻到达航站楼的旅客半小时时段流量需要转换成以整点时刻开始划分的半小时时段流量。
业务规则计算不可避免地需要对数据以及数据之间的关系进行重新定义,但无论如何变化,它们都必须遵循统一的模型和语义,以保持数据集市中数据的一致性。通过计数、求和、均值、方差、极值等聚合计算方法,可以将不同来源数据整合到不同粒度和主题数据集市中。
要实现航站楼平面布局CAD文件中的数据到地理空间数据库的要素类的转换,若直接采用GIS软件附带的工具箱中的“CAD文件至地理空间数据库”的工具进行数据转换,则输出的将是整个CAD图层的点、线、多边形、多面体以及注记的要素类,无法满足数据分析的需要,因此,需要借助专用的空间数据ETL工具将航站楼平面布局CAD文件中的数据转换成地理空间数据库的要素类,本书使用Feature Manipulate Engineering(FME)软件实现航站楼平面布局数据到地理空间数据库要素类的转换。
FME是加拿大Safe Software公司开发的为空间数据的ETL提供完整解决方案的软件。该软件基于OpenGIS组织提出的“语义转换”的数据转换理念,通过提供在转换过程中重构数据的能力,实现了超过300种不同空间数据格式(模型)之间的转换,为实现多种需求的快速、高质量数据转换应用提供高效、可靠的技术手段。
利用FME可对一个CAD文件的每个图层分别进行转换,而且数据转换的过程可以由软件的使用者自己定义,该软件有400多个内置的数据转换器,可以根据需要添加一个或多个数据转换器,并对转换的过程进行自定义,如可以添加AreaBuilder转换器,将在读模块中输入的CAD文件中的闭合线转换成写模块中的地理数据库(Geodatabase)的面要素,完成CAD闭合曲线到地理数据库面要素的转换。此外,FME还可以定义输出到写模块中的地理数据库要素类的属性,使地理数据库要素类属性表的设计在FME中即可实现。
利用FME将CAD文件中包含的信息转换到地理数据库要素类的过程中,要求CAD文件的图层与地理数据库的要素类对应,而原始航站楼平面布局CAD文件的图层并不是按照地理数据库的要素类进行分层的,因此,需要首先按照地理数据库的要素类对CAD文件重新进行分层,然后再将进行数据转换。本例中,航站楼平面布局CAD文件被分为92个图层,每个图层对应一个地理数据库的要素类,如图2-23所示。
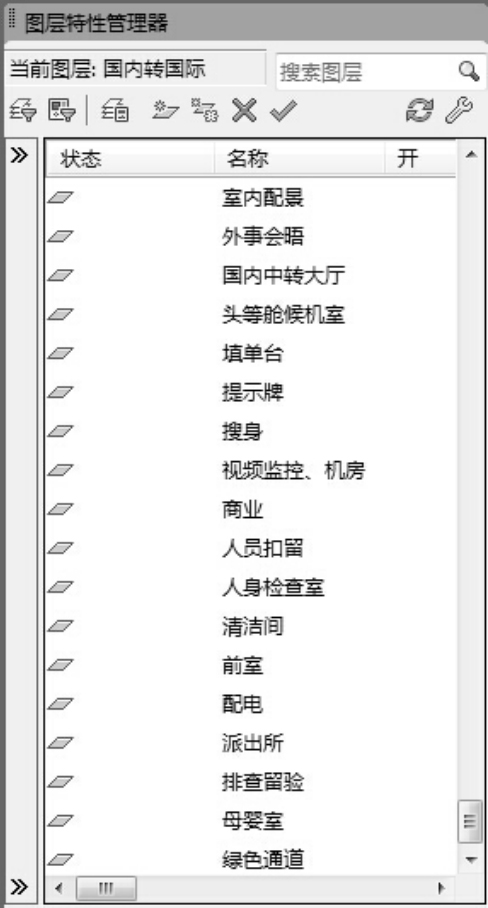
图2-23 航站楼平面布局CAD文件中的图层
利用FME转换航站楼平面布局CAD文件的图层到地理数据库Geodatabase要素类的界面如图2-24所示。
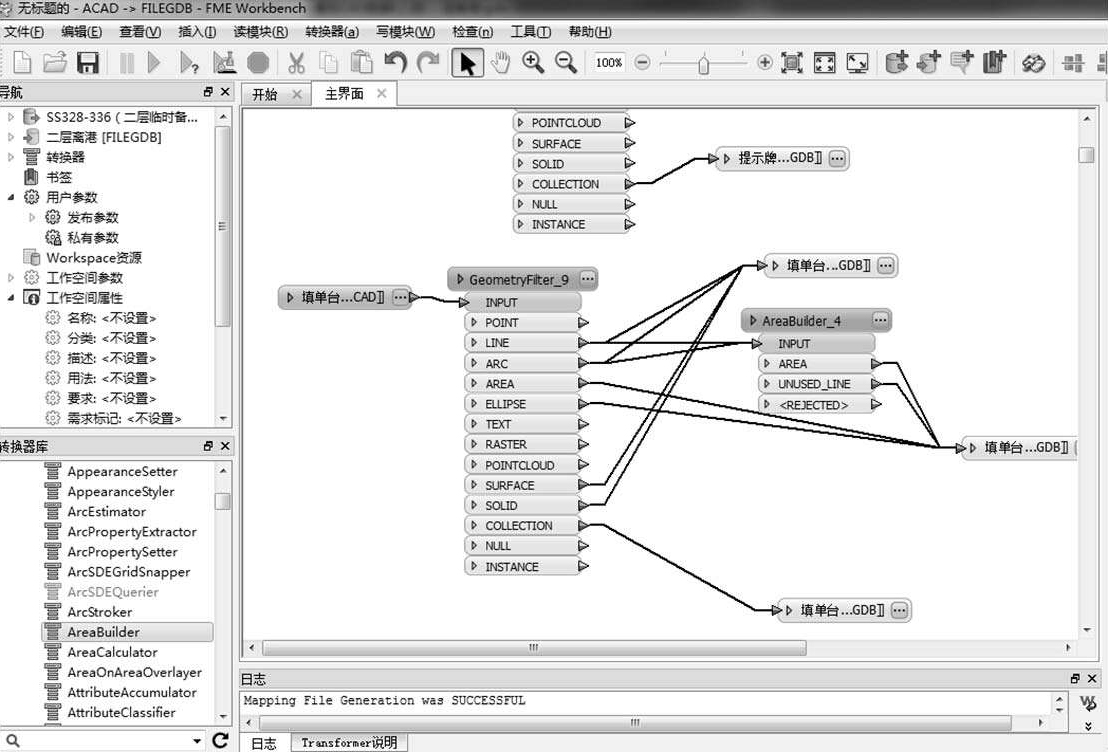
图2-24 CAD到Geodatabase格式文件转换
正确设置FME中的读模块、写模块以及转换器之后,单击运行按钮,完成转换过程。在ArcCatalog目录树可以查看转换成功的要素类,如图2-25所示。
最后,根据空间对象间的空间关系,建立要素数据集,将空间对象导入到对应的要素数据。对于同时属于多个要素数据集的要素类,如电梯要素类同属于多个要素数据集,则需要根据空间对象与要素数据集的关系,利用SQL查询构建器来完成要素类的对象到要素数据集的导入工作,结果如图2-26所示。

图2-25 成功转换的Geodatabase要素类

图2-26 航站楼空间地理数据库构建完成