
下载掌阅APP,畅读海量书库
立即打开



有诗赞曰:“手持宣化开山钺,胯下大肚蝈蝈红;称霸混世大魔王,官拜大唐鲁国公。皇杠劫在小孤山,三斧定得瓦岗山;征南大战王世充,开唐位列凌烟阁。”
这里说的是一位古人,姓程名咬金,小名阿丑,山东东昌府东阿县斑鸠镇小耙子村人士。隋唐年间一员福将,他老人家最拿手的就是三板斧。正所谓“一招鲜,吃遍天”,此人靠这几手,行遍大江南北,被封为唐朝的鲁国公,享尽人间荣华。
在基本单元设计里,除了传统的用门电路构建之外,数字逻辑设计也就是三板斧:查找表、时分复用和流水线。但是,有诗云“长江后浪推前浪”。几千年过去了,我们总得比程大将军稍稍高一点。我们会把这三招糅合,能产生变招。
闲言少叙,言归正传。下面我们分别介绍这三招的基本架势(至于变招,我们会在后面的相关内容里面进行描述,评书里面说:“欲知后事如何,且听下回分解”。等等,别走!这还没开讲呢!)。徒儿们,你们要听清楚、多记笔记,过了这个村可没这个店了。
1.组合逻辑查找表
第一招:查找表。汉语名字叫查找表(英文名字叫“Chazhaobiao”?您小沈阳看多了。)英文叫LUT,Look Up Table,是一种最简单的实现结构,传统上被贴上了大面积的标签,很少被待见(L兄哭了:“我招谁惹谁了,凭什么不用我啊?”)。在我们最初学习《数字电路》的时候,这应该是最常用的方法了。是否还记得,大家曾经乐此不疲地化简卡诺图,这就是查找表法了。现在EDA软件发达了,简化卡诺图工作不需要大家操心,计算机帮我们做得很好了,这对LUT是个好消息。
下面给一个通用的 LUT 的形式:查找表原理上就是给出全部输入可能的输出,作出一张输出的“表”。假设输入为in1,in2…,输出为out1,out 2…,那么查找表可以表示为如图1.33所示。里面好多的点点啊,左面是全部输入的组合(很多的啊,如果全部输入 N bits,那么就有2 N 个呢),右边是输入对应的输出(可以由其他程序,例如仿真得到)。如果输入规模很大,这个表是非常复杂的,因此是很多材料不建议采用的原因。但是,在某些情况下,如输入规模很小的场景,是不是可以考虑采用LUT了呢?L君终于有用武之地了。例如,后面会介绍的全加器,输入3 个比特,输出2 个比特。对于这种器件,可以考虑在Verilog 用查找表实现,叫软件实现卡诺图的简化。简化的结果嘛,就是我们数电老师成天自夸的那两个公式了(什么公式?不会吧,随便找本什么《数字电路》看看好了,一定有的)。
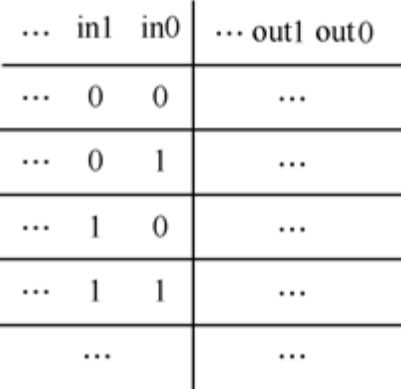
图1.33 组合逻辑的查找表
查找表的Verilog表达一般是case这个关键词,一个典型的查找表的代码是:

其中, N 是输入的总比特数, M 是输出的总比特数。Verilog的关键词里面还有“casez”和“casex”,很多资料说它俩比“case”好用。但是,因为这两个关键字属于有些综合器支持,有些不支持的,所以不建议使用。
LUT还有一种产生方法,就是利用RAM完成,如图1.34所示。具体方法是,用输入组成{…,in1,in0} 作为 RAM 的地址,把这些输入的输出作为值存在 RAM 里面。这样,读对应地址就得到想要的输出了。这个结构似曾相识?好记性,我们在第一讲里面提到过。这就是ASIC一统江湖时期,著名的江湖公敌。
这个方法在 ASIC 的二进制逻辑里面用得不多,但是对于非线性函数求值却是一个常用的策略。这个问题,在我们以后关于非线性函数求值的章节里面,有详细的介绍。
还有值得大说特说的就是,一些基于SRAM的FPGA内部,采用的就是查找表实现的组合逻辑。例如图1.35就是某公司FPGA内部一个基本单元结构。所以,即使我们采用复杂的逻辑门方法实现组合逻辑,在这类FPGA里面也会被转化为查找表的形式。换句话说,就是您老费了九牛二虎之力,简化了卡诺图,综合器还是把这些化简的结果,算出了真值表,在FPGA里面实现。这不是白费劲吗?还不如留着力气,干点别的呢。
这又掰扯到基础问题了,诸位设计FPGA不能够仅仅局限于数字电路的领域。大伙儿需要了解到FPGA的内部,才能获得更好的设计。
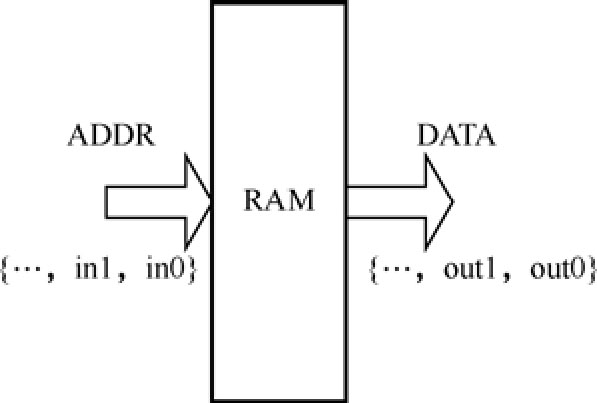
图1.34 基于RAM的查找表结构
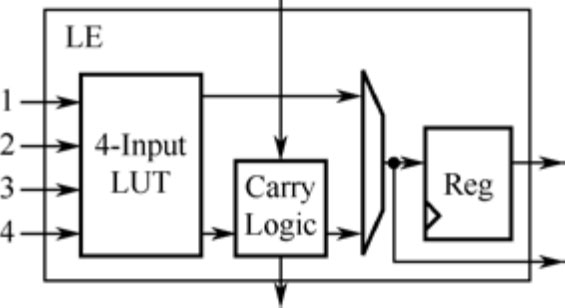
图1.35 某公司FPGA内部一个基本单元结构
第一招打完,收工了。为了便于记忆,这里承上招法口诀一首,专门讲如何做查找表:“皆说查找身材胖,瘦身即需输入少;全部输入连一串,输出数值列身旁。”
2.小巧灵活使复用
下来是第二招,不是“小鬼剔牙”了,是时分复用。时分复用的基本思想是:对于一些需要处理速度比较慢、有重复运算的单元,在可以接受的建立时间内,多次重复利用有关的运算器件,以达到减少整个单元面积的目的。
说了一堆严格的非人话,总结一下是必要的。
首先,时分复用的应用场合是“对于一些需要处理速度比较慢”,也就是需要建立时间较长的单元。
其次,这些单元里面,必须“有重复运算的单元”。例如:在 FIR 滤波器里面存在很多相同位数的加法,就适合采用时分复用。
最后,时分复用的手段是“多次重复利用有关的运算器件”。
前两个要点是第二招适用的场景,第三点是时分复用的实战招式(对方招架时,收斧头,献斧纂,攻击对方的脸。)。
同学们,我们来解剖时分复用的结构。时分复用在流程上很类似程序语言,运算不像以前我们介绍硬件描述语言那样并行进行,而是按照一定顺序串行完成的。这个顺序,是设计人员按照系统的要求设计的,一般用时序图的形式表现。由于硬件描述语言的特殊性,在采用时分复用的单元里面,一般需要一个计数器来控制时序。
以下用一个简单的例子来说明时分复用的方法,计算 e = a + b + c + d 。时序图如图1.36所示,我们在节拍0(计数器为0),计算 x = a + b ;在节拍1,计算 e = e + c ;;在节拍2,计算 e = e + d 。
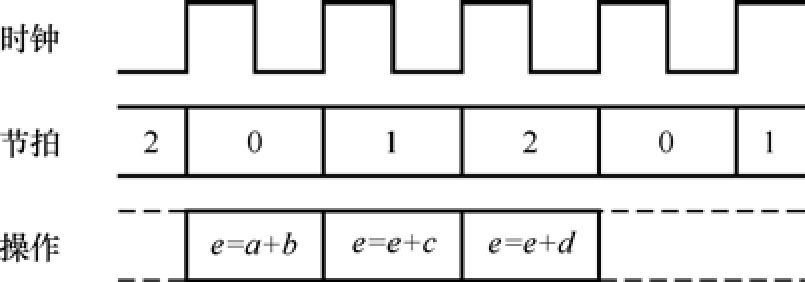
图1.36 时分复用的时序图
好了,下来是设计代码(为了简化,就不写常规操作和计数器部分,只写操作有关的部分了):

简单吧?对不起,这位写上面代码的英雄。来人啊,拖出去给我打。还真的以为是程序语言了,这个实现里面还是三个加法器的复用,而不是一个加法器的复用。列位啊,虽然综合器都号称自己很牛,但是实际上他们都很水。不要指望综合器能帮你实现时分复用或者流水线。器件很笨、综合器也很笨,所以才有您的饭碗,别抱怨了。
还是看看正解吧:

这才是用一个加法器,实现了3次加法。另外,里面的“#2”是模拟加法器处理时延的一个手段。对应地,前面代码的结构图如图1.37所示。比较时序图和结构图,不难发现时序图的表达更为简单易读,因此以后讲到时分复用都用时序图表示。
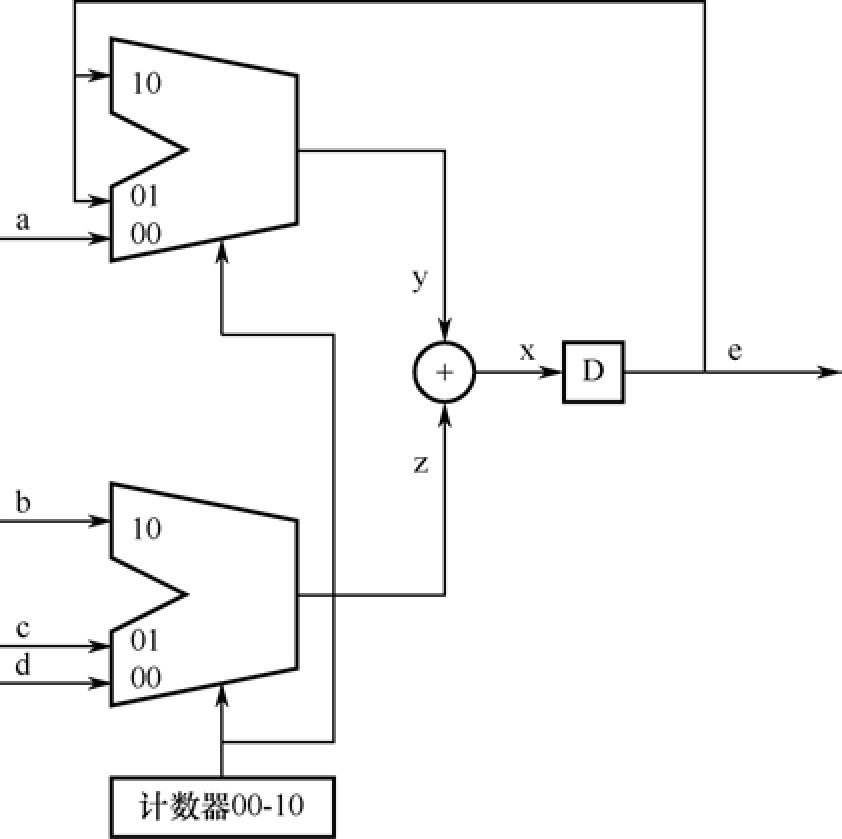
图1.37 时分复用的结构图
在实际设计中,还需要注意的是加法的进位问题。这个和时分复用关系不大,为了突出重点,就忽略了。
现在是提问时间,我们需要的4 个数字相加的结果在什么时候有效?“节拍2!”,谁回答的?接着打,打得长记性为止。听好了,记住了,4 个数字相加的结果在下一个节拍0才真正建立。回答2的忘记了寄存器在时钟上升沿才采样了。
再回过头来看看这个例子,发现没,里面的运算全是加法,所以可以用时分复用的方法简化面积。那么,如果要计算第一步加,第二步乘,第三步除的公式,就没法用时分复用的绝招了。那该怎么办?老老实实地实现呗。以为老夫是神仙呢?就是神仙,估计也没招。
第二招也有口诀:“他强由他强,清风抚山冈。他横由他横,明月照大江。”我看谁敢说:“忘记一半了”!我不是张真人,这里也不教太极拳;还有更重要的是:你以为你是张无忌啊。
第二招真正的口诀是:“时分妹子身材棒,找个计数(器)掌节拍。重复操作单独撰,输入输出时钟控。”
3.快速反应流水线
最后,压轴的好戏来了!
第三招:流水线(P君,pipeline)。小P可是FPGA/ASIC界的风云人物啊。您随便去 baidu 一下“流水线+FPGA”,网上的资料可谓汗牛充栋。给人的感觉是:您不会流水线,都不好意思说自己是 FPGA 界的。(作者本人是“娱乐界”的,这个可以没有。)
流水线的主要思想是把一个操作分为多个步骤,每个时钟节拍做一个步骤。对于单个数据,经过 N 个步骤之后,获得最终的结果。硬币的另一面,对于整个数据流而言,每个时钟节拍有一个数据进入处理。这样,由于每个步骤的处理时延小于总的处理时延,系统能够以更高的时钟周期工作,相应处理的数据流的速度也就提高了。然而,考察一个处理的建立时间,由于 N 个时钟之后才能获得最终结果,实际的建立时间一般比其他方式长。对于面积的考虑,流水线也没有节约面积,反而由于其中必然采用的寄存器延时链,系统的面积一般大于其他方法。一句话,流水线也是用面积和建立时延换系统工作频率和数据流速度的一种实现方式。
贫僧最不喜欢抽象的概念了,读经也不喜欢看《金刚经》;有人问起来,某家喜欢《百喻经》,都是小故事。
现在,也用一个例子来说明一下流水线的基本实现流程。输入数据是 a,b,c…,它们经过步骤1,2,3,4,得到结果A,B,C…。
时刻1,第一个数据a进入流水线。a完成处理1,记为a1。输出为无效数据。
时刻2,第二个数据b进入流水线。b完成处理1,记为b1;同时,a完成处理2,记为a2。输出为无效数据。
时刻3,第三个数据c进入流水线。c完成处理1,记为c1;同时,b完成处理2,记为b2;a完成处理3,记为a3。输出为无效数据。
……
时刻5,第五个数据e进入流水线。e完成处理1,记为e1;同时,b完成处理4,记为b4;a完成全部处理。输出流水线为A。
……
以此类推,就得到了全部需要的结果,如图1.38所示。
值得说明一下的是,与时分复用不同,流水线并不要求每一步处理的组合逻辑一致。针对上面的例子,处理1是加法,处理2是乘法,处理3是除法,然而处理4是求正弦函数值,这也是允许的。
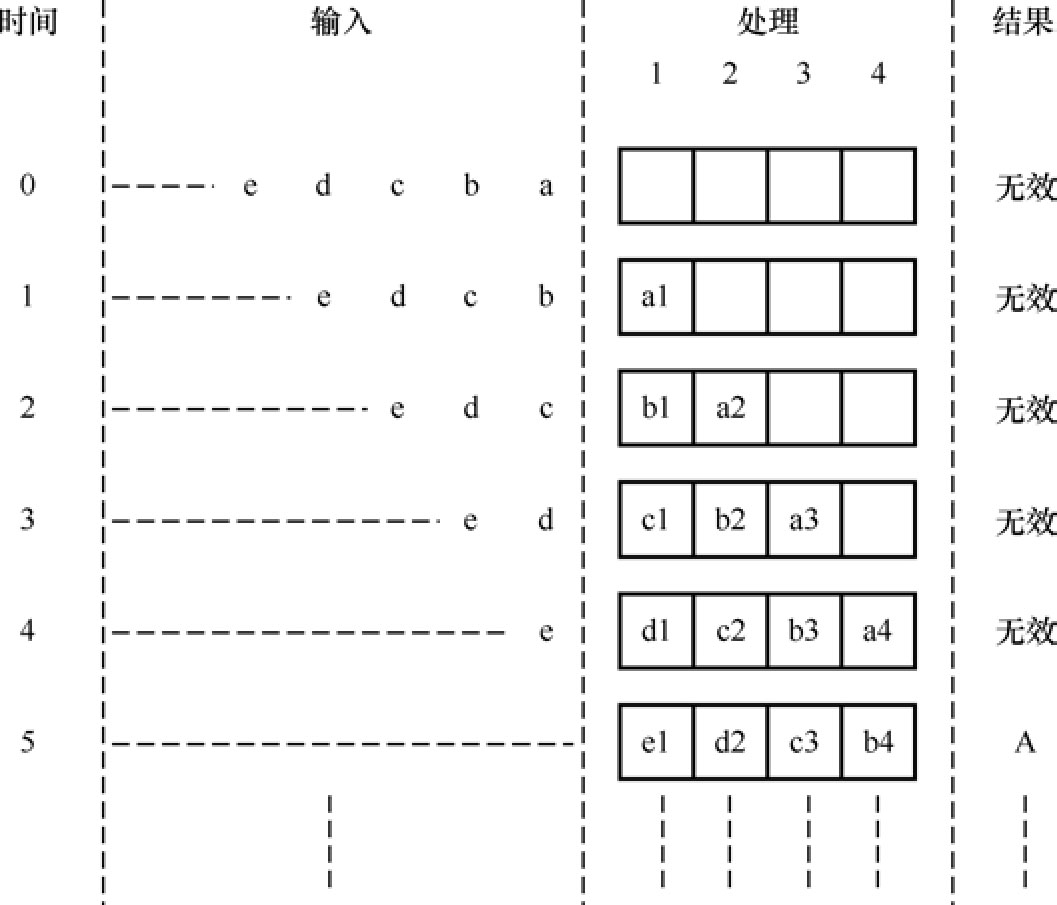
图1.38 流水线的基本思想
P 君这个人属于开“防忽悠”热线之前的“范厨子”——一根筋,用北京土话说就是“轴”。数据流的方向必须是勇往直前的“奔腾到海不复还”。因此,如果是“数据处理”的话,流水操作再适合不过。如果是“驱动”、“控制”之类的工作,还想交给P君完成,那就是三两棉花——免谈(弹)。
图1.39是一个流水线的一般模型。可以看出,一个流水线由三部分组成:数据延迟链(组)负责原始数据的存储,结果延时链(组)完成各步骤结果的存储,组合逻辑链接这两种延时链(组)是各个步骤的真实操作。通用模型里面值得注意的是,结果延时链(组)可能是D触发器的串联,也可能是单独的D触发器用于存储中间结果,还可能是两者的组合。
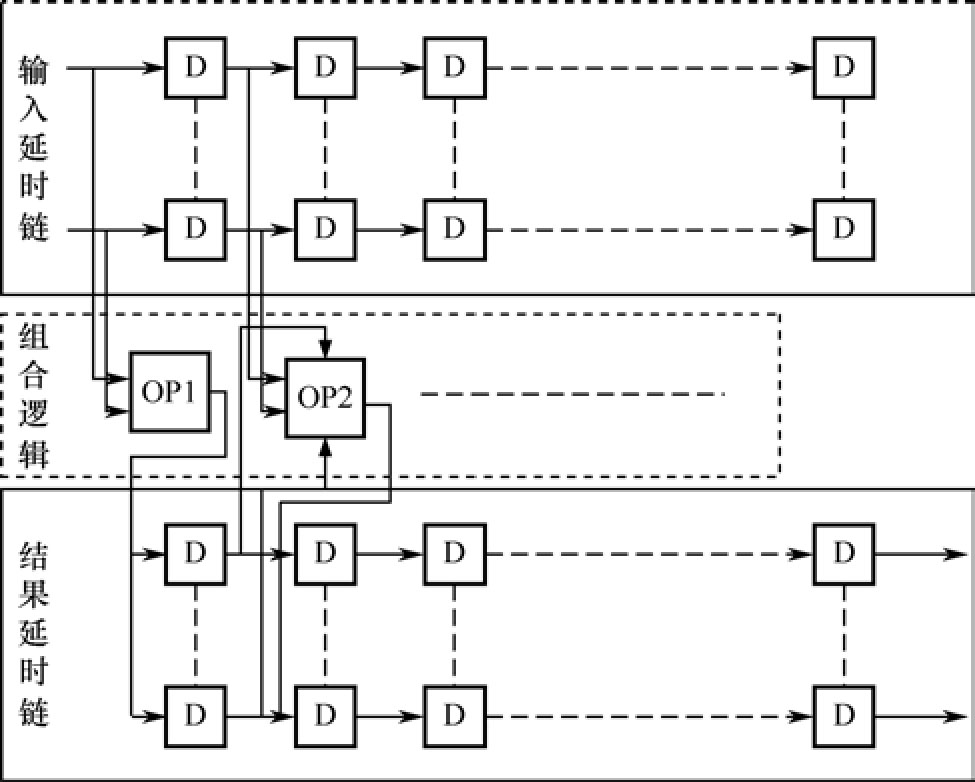
图1.39 流水线的一般结构图
这个描述比较抽象,以后的章节里面会针对不同功能的单元,给出对应的具体实现。俗话说得好:心急吃不得热豆腐。
笔者真心不想写代码。这个习惯不是因为懒惰,而是在书里加上代码有故意占页面的嫌疑。这里必须给出一个例子,大家担待,对应图1.39的建议的Verilog代码是:


其中,input是输入,Delay_Input_i是输入延时链的存储结果,Delay_Result_i是结果延时链的存储结果,OPij是对应操作。
有细心的听众说了:“为什么用了for语句了呢?不是说不建议使用for吗?”
官方回答是这样的:首先,我们只说“不建议”,从来没说禁止。其次,这种连续的延时链,使用 for 的确可以节约很多打字时间。如果您老乐意,去把每一步时延都敲出来,我们也绝对不会反对。最后,如果每个步骤的操作都是一致的,结果延时链也建议采用for的形式编码。这样的代码比较简洁。
什么?还要具体的例子?不急,不急,书后面全是,诸位慢慢看。
也有几句口诀赞扬 P 君:“双边两条延迟链,组合逻辑中间站,数据结果每节拍,高速设计流水线。”
虽然没到年底,也没有年终奖,但是这也阻拦不了贫僧来给各位施主总结一下。
这一讲里面分别介绍了时分复用和流水线两种手段。不知道有人发现没有,这两种方法有一个十分明显的相似之处。不故弄玄虚地吊胃口了,那就是需要把一个完整的处理分为若干个子处理,然后分别完成。如果这些子处理是一样的,这样就在时分复用与流水线之间搭了一座桥。“低速要求用时分,高速时钟靠流水”,切记。图1.40是一个示意图,为了简化,流水线只有一个结果延时链。

图1.40 时分复用与流水线之间的转换
最后,需要叮嘱一句,本次讲的三种基本结构只是典型的例子。在设计中,这三种结构不是泾渭分明的。在真实的设计中,大家需要根据需要,自由组合。真正做到你中有我,我中有你,才是高手,高高手。这种例子,在后面的讲座中鄙人也会给大家介绍一二的——好戏刚刚开场。
这正是:“设计自有三斧开,劝君切莫随意来;复用流水查找表,如何选择看能耐。组合逻辑查找在,复用低速流水快;假若时钟要求变,两者转化重编裁。”