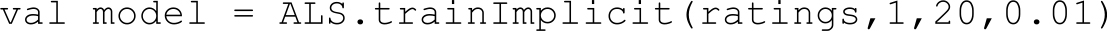下载掌阅APP,畅读海量书库
立即打开




基于RDD,Spark在一个技术堆栈上统一了各种业务需求的大数据处理场景,能够同时满足SQL、实时流处理、机器学习和图计算等,本节我们详细介绍Spark上的这4大子框架。
GraphX是Spark中用于图(Web-Graphs 和Social Networks)和图并行计算(PageRank和 Collaborative Filtering)的API,可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重写及优化。
GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,后来整合到Spark中成为一个核心组件,这里的内容是基于论文:
Xin,Reynold S.,et al."GraphX:Unifying Data-Parallel and Graph-Parallel Analytics." arXiv preprint arXiv:1402.2394(2014).[PPT][Talk][Video][GitHub][Hands-on Exercises]
Graph用来描述参数之间的关系,可以自然地做model partition/parallel,传统用key-value存储参数的方式,可能会损失模型结构信息,如图1-34所示。
图1-34 PageRank算法
早在0.5版本,Spark就带了一个小型的Bagel模块,提供了类似Pregel的功能。当然,这个版本还非常原始,性能和功能都比较弱,属于实验型产品。到0.8版本时,鉴于业界对分布式图计算的需求日益见涨,Spark开始独立出一个分支Graphx-Branch,作为独立的图计算模块,借鉴GraphLab,开始设计开发GraphX。在0.9版本中,这个模块被正式集成到主干,虽然是Alpha版本,但已可以试用,小面包圈Bagel告别舞台。1.0版本时,GraphX正式投入生产使用。
Graphx是Spark生态中非常重要的组件,融合了图并行和数据并行的优势,虽然在单纯的计算机段的性能相比不如GraphLab等计算框架,但是如果从整个图处理流水线的视角(图构建、图合并、最终结果的查询)看,那么性能就非常具有竞争性了,如图1-35所示。
图1-35 Graphx的性能
值得注意的是,GraphX目前依然处于快速发展中,从0.8的分支到0.9和1.0,每个版本的代码都有不少的改进和重构。根据观察,在没有改任何代码逻辑和运行环境,只是升级版本、切换接口和重新编译的情况下,每个版本有10%~20%的性能提升。虽然和GraphLab的性能相比还有一定差距,但凭借Spark整体上的一体化流水线处理模式,社区热烈的活跃度及快速改进速度,GraphX具有强大的竞争力。
1.分布式图计算
在正式介绍GraphX之前,先看看通用的分布式图计算框架。简单来说,分布式图计算框架的目的是将巨型图的各种操作包装为简单的接口,让分布式存储、并行计算等复杂问题对上层透明,从而使复杂网络和图算法的工程师更加聚焦在图相关的模型设计和使用上,而不用关心底层的分布式细节。为了实现该目的,需要解决两个通用问题:图存储模式和图计算模式。
1)图存储模式
巨型图的存储总体上有边分割和点分割两种存储方式。2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得了重大提升,目前基本上被业界广泛接受并使用。
边分割:每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
点分割:每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
虽然两种方法互有利弊,但现在是点分割占上风,各种分布式图计算框架都将自己底层的存储形式变成了点分割。主要原因有以下两个:
● 磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵。这点类似于常见的空间换时间的策略。
● 在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊。而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。
2)图计算模型
目前的图计算框架基本上都遵循BSP(Bulk Synchronous Parallell)计算模式。在BSP中,一次计算过程由一系列全局超步组成,每一个超步由并发计算、通信和栅栏同步三个步骤组成。同步完成标志着这个超步的完成及下一个超步的开始。BSP模式很简洁,基于BSP模式,目前有两种比较成熟的图计算模型。
Pregel模型——像顶点一样思考
2010年,Google新的三架马车Caffeine、Pregel、Dremel发布。随着Pregel一起,BSP模型广为人知。Pregel借鉴MapReduce的思想,提出了“像顶点一样思考”(Think Like A Vertex)的图计算模式,用户无须考虑并行分布式计算的细节,只需要实现一个顶点更新函数,让框架在遍历顶点时进行调用即可。
常见的代码模板如下:

这个模型虽然简洁,但很容易发现它的缺陷。对于邻居数很多的顶点,它需要处理的消息数量非常庞大,而且在这个模式下,信息是无法被并发处理的。所以对于符合幂律分布的自然图,在这种计算模型下很容易发生假死或者崩溃。
GAS模型——邻居更新模型
相比Pregel模型的消息通信范式,GraphLab的GAS模型更偏向共享内存的风格。它允许用户的自定义函数访问当前顶点的整个邻域,可抽象成Gather、Apply和Scatter三个阶段,简称为GAS。相对应的,用户需要实现三个独立的函数gather、apply和scatter。常见的代码模板如下所示。


由于gather/scatter函数以单条边为操作粒度,所以一个顶点的众多邻边可以分别由相应的worker独立调用gather/scatter函数。这一设计主要是为了适应点分割的图存储模式,从而避免了Pregel模型会遇到的问题。
2.GraphX的框架
在设计GraphX时,点分割和GAS都已成熟,并在设计和编码中针对它们进行了优化,在功能和性能之间寻找最佳的平衡点。如同Spark本身,每个子模块都有一个核心抽象。GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,只需要一份物理存储。两种视图都有自己独有的操作符,从而提高了操作灵活性和执行效率。
如同Spark,GraphX的代码非常简洁。GraphX的核心代码只有3千多行,而在此之上实现的Pregel模型,只要短短的20多行。GraphX的代码结构整体如图1-36所示,其中大部分的实现都是围绕Partition的优化进行的。这在某种程度上说明了点分割的存储和相应的计算优化的确是图计算框架的重点和难点。
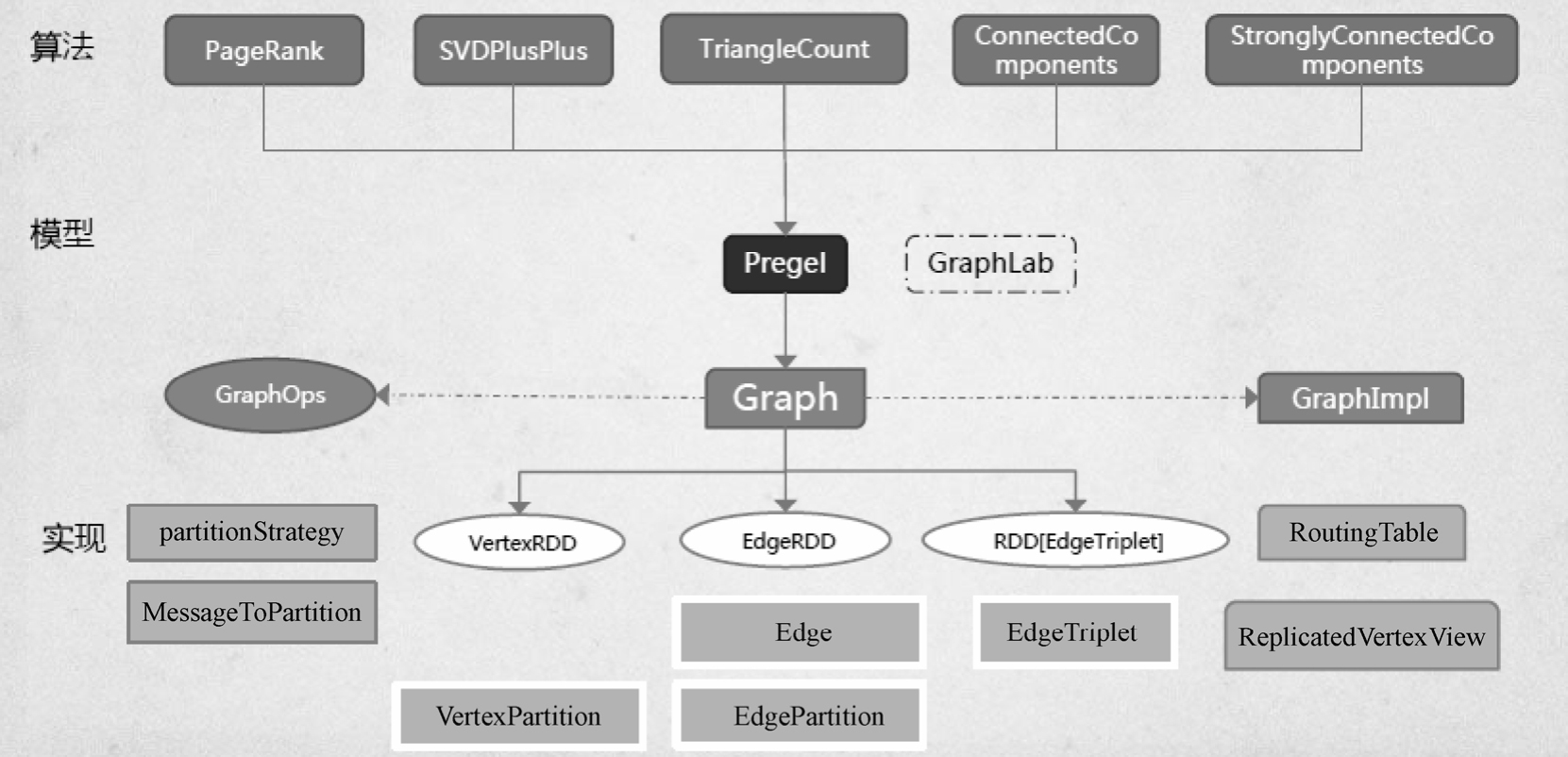
图1-36 GraphX的代码结构
GraphX的底层设计有以下几个关键点。
对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作。这样对一个图的计算,最终在逻辑上等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:Immutable、Distributed和Fault-Tolerant,其中最关键的是Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
两种视图底层共用的物理数据由RDD[Vertex-Partition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略(PartitionStrategy)。划分策略会将边分配到各个EdgePartition,顶点Master分配到各个VertexPartition,EdgePartition也会缓存本地边关联点的Ghost副本。划分策略的不同会影响需要缓存的Ghost副本数量,以及每个EdgePartition分配的边的均衡程度,需要根据图的结构特征选取最佳策略。目前有EdgePartition2d、EdgePartition1d、RandomVertexCut和CanonicalRandomVertexCut这4种策略。在淘宝大部分场景下,EdgePartition2d的效果最好。
GraphX通过引入Resilient Distributed Property Graph(一种点和边都带属性的有向多图)扩展了Spark RDD这种抽象数据结构,这种Property Graph拥有两种Table和两种Graph视图(及视图对应的一套API),而只有一份物理存储,如图1-37所示。
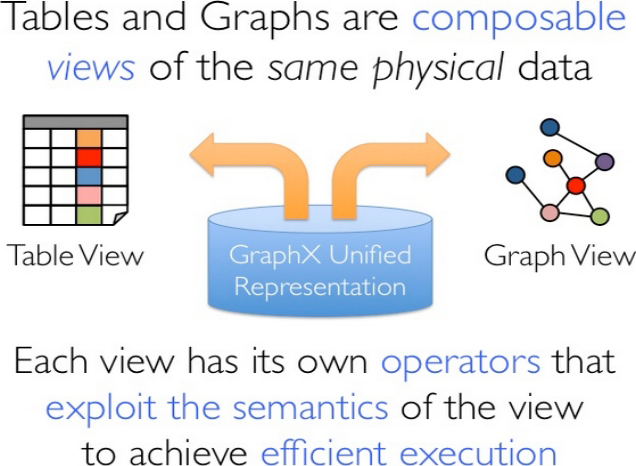
图1-37 Property Graph
Table视图将图看成Vertex Property Table和Edge Property Table等的组合,这些Table继承了Spark RDD的API(fiter、map等),如图1-38所示。
Graph视图上包括reverse/subgraph/mapV(E)/joinV(E)/mrTriplets等操作。结合pagerank和社交网络的实例看看mrTriplets(最复杂的一个API)的用法,如图1-39所示。
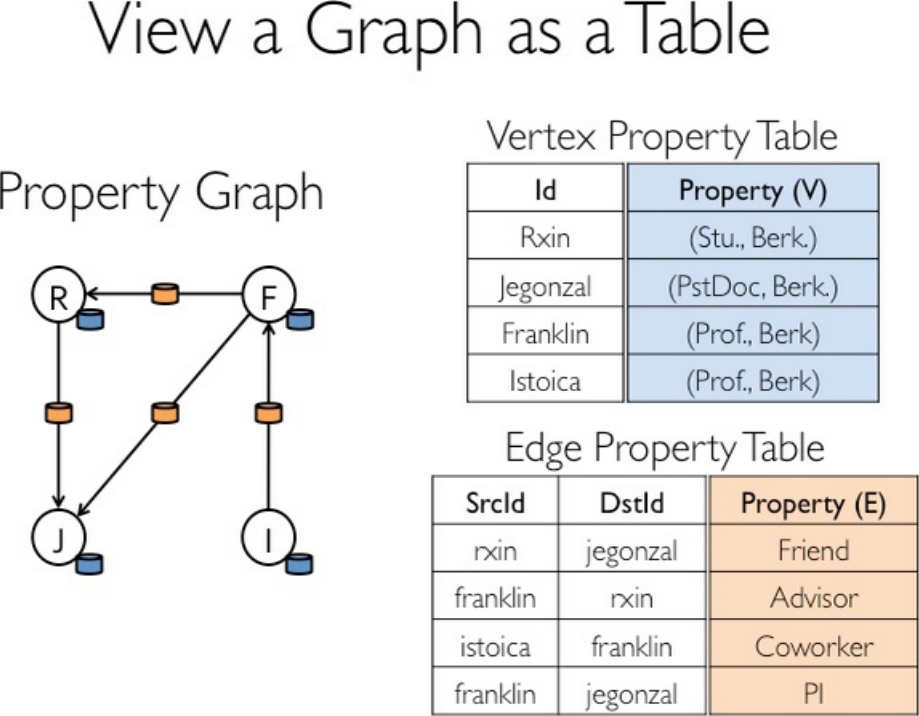
图1-38 Table视图将图看成Vertex Property Table和Edge Property Table等的组合
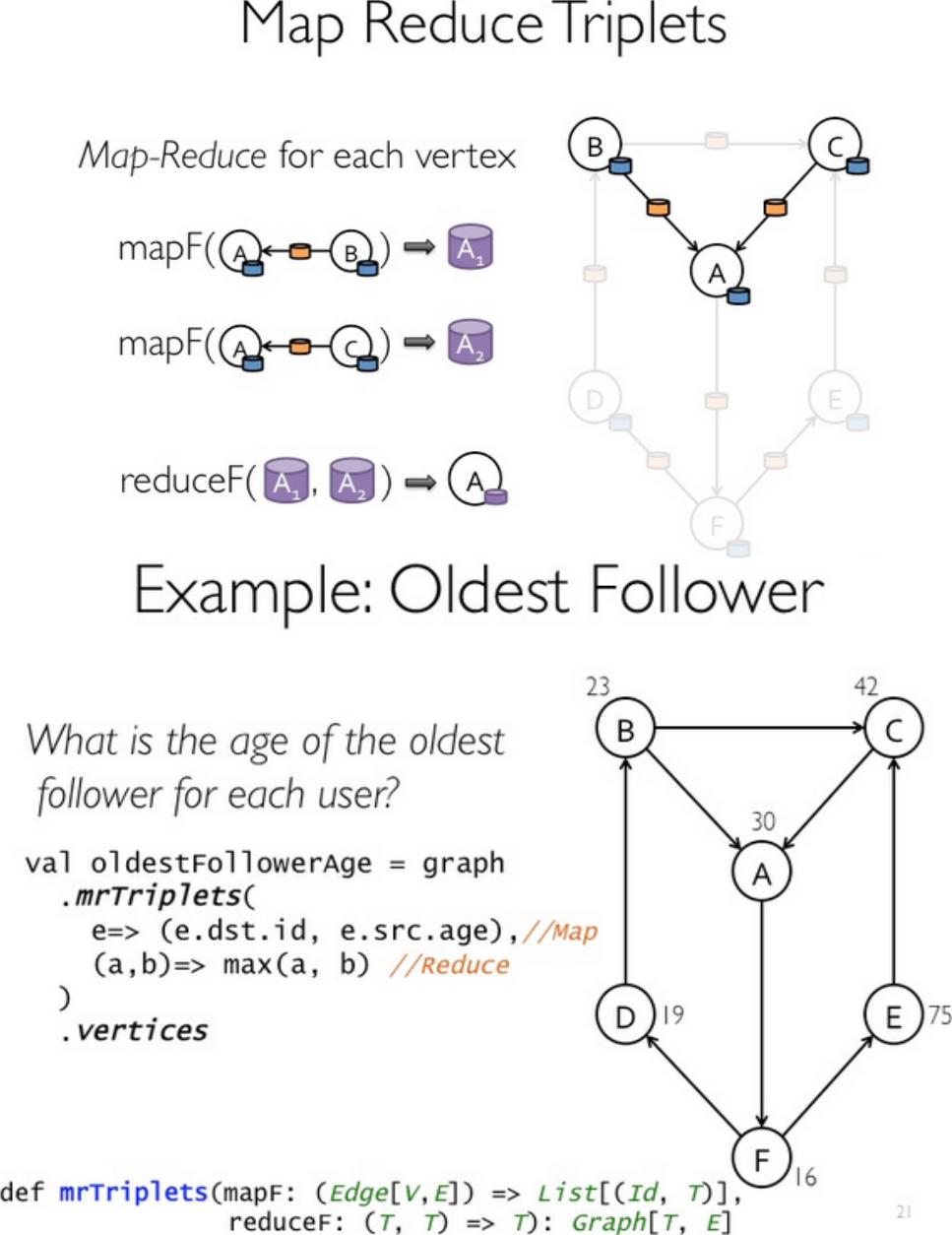
图1-39 mrTriplets的用法
3.优化
点分割:Graphx借鉴powerGraph,使用vertexcut(点分割)方式来存储图。这种存储方式的特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上。当点被分割到不同机器上时是相同的镜像,但是有一个点作为主点(master),其他的点作为虚点(ghost)。当点B的数据发生变化时,先更新点B的master的数据,然后将所有更新好的数据发送到B的ghost所在的所有机器,更新B的ghost。这样做的好处是在边的存储上是没有冗余的,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律,比如求邻居权重的和,求点的所有边的条数这样的操作,可以在不同的机器上并行进行,只要把每个机器上的结果进行汇总就可以了,网络开销也比较小。代价是每个点可能要存储多份,更新点要有数据同步开销。
Routing Table:vertex Table中的一个partition对应着Routing Table中的一个partition,Routing Table指示了一个vertex会涉及哪些Edge Table partition,如图1-40所示。
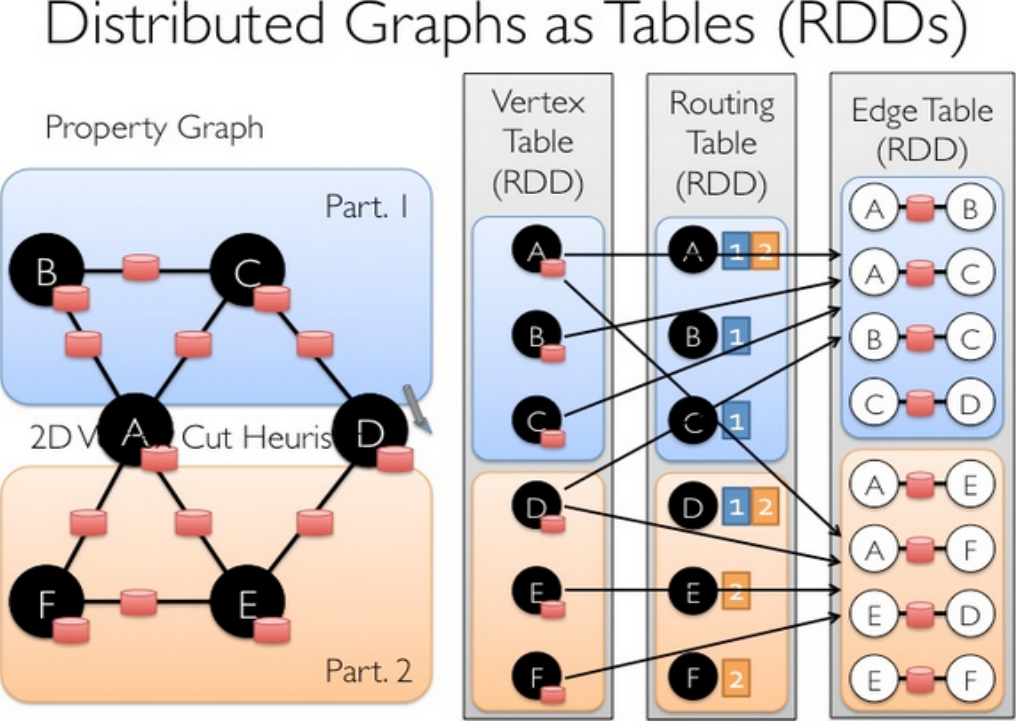
图1-40 Routing Table
Caching for Iterative mrTriplets&Indexing Active Edges:在迭代的后期,只有很少的点有更新,因此对没有更新的点使用local cached能够大幅降低通信所耗,如图1-41所示。
Join Elimination:在PR计算中,一个点值的更新只跟邻居的值有关,而跟它本身的值无关,那么在mrTriplets计算中,就不需要Vertex Table和Edge Table的3-way join,而只需要2-way join,如图1-42所示。
此外,还有一些Index和Data Reuse的查询优化。

图1-41 使用local cached能够大幅降低通信所耗
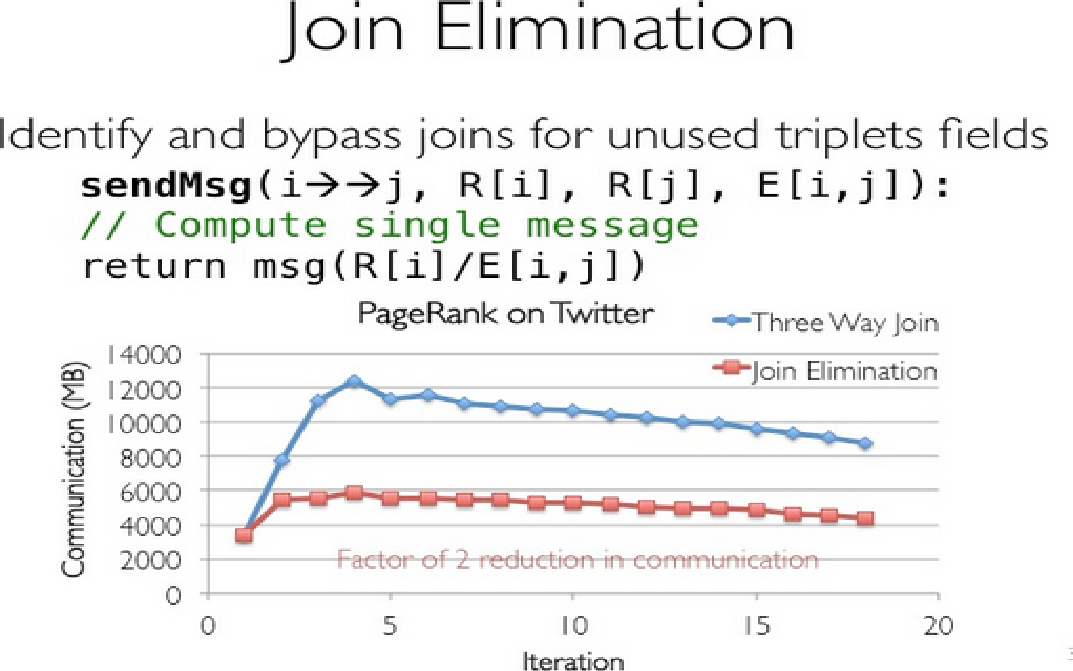
图1-42 Join Elimination
4.性能
GraphX整体上比GraphLab慢2~3倍,有两方面的原因:GraphX跑在JVM上,没有C++快是显然的;GraphLab不受Spark框架的限制,可以通过Threads来共享内存,而GraphX就算在同一台机器上都有communication cost,如图1-43所示。GraphX即使是计算位于同一台机器上同数据分片的数据协同工作也要进行完整的网络堆栈间的通信过程。
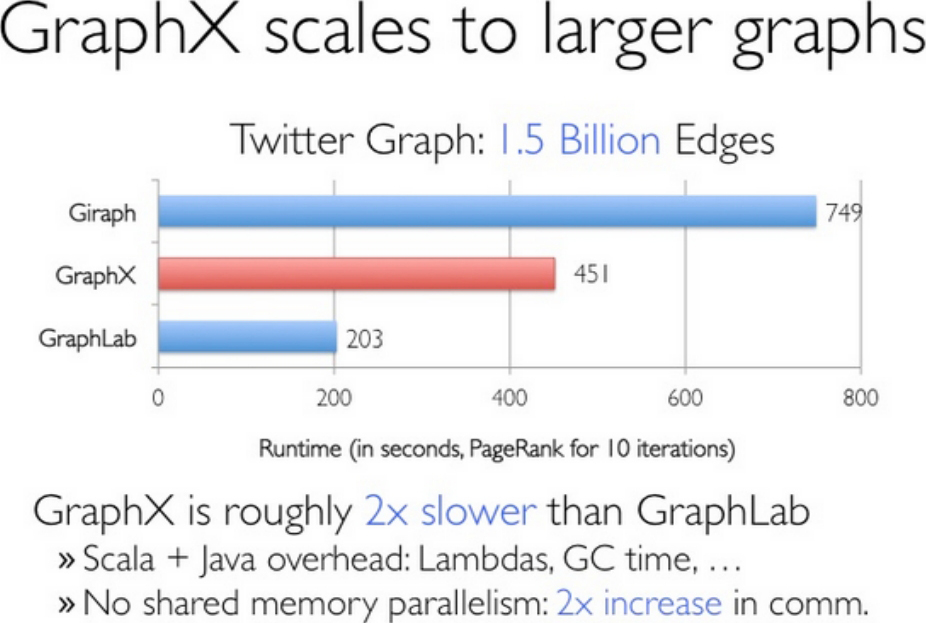
图1-43 GraphX与GraphLab的比较
GraphX在超大规模数据下,Runtime的增长比GraphLab要慢,scalability要好一些。
从整个图计算Pipeline来说,GraphX的总体Runtime少于GraphLab+Spark。
代码量如图1-44所示。
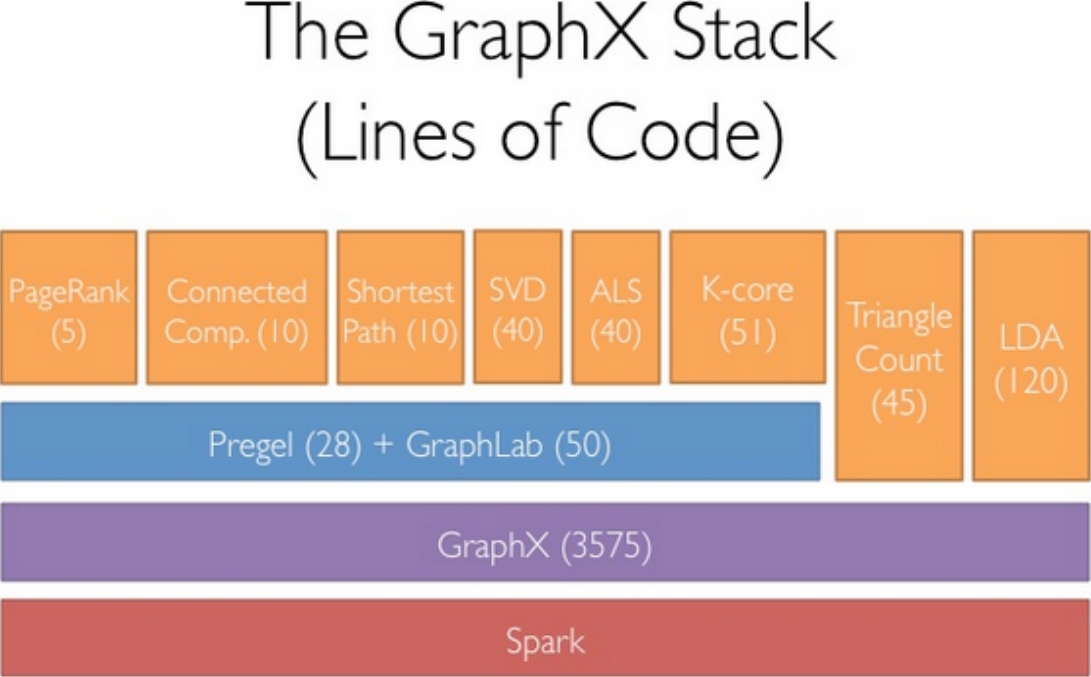
图1-44 代码量
5.GraphX的图运算符
如同Spark一样,GraphX的Graph类提供了丰富的图运算符。可以在官方GraphX Programming Guide中找到每个函数的详细说明,本文仅讲述几个需要注意的方法。
GraphX的运算符结构如图1-45所示。

图1-45 GraphX的运算符结构
6.图的cache
每个图由3个RDD组成,所以会占用更多的内存。相应图的cache、unpersist和checkpoint,更需要注意使用技巧。出于最大限度复用边的理念,GraphX的默认接口只提供了unpersistVertices方法。如果要释放边,需要调用g.edges.unpersist()方法,这给用户带来了一定的不便,但为GraphX的优化提供了便利和空间。参考GraphX的Pregel代码,对一个大图,目前最佳的实践是:

大致的意思是根据GraphX中Graph的不变性,对g做操作并赋回给g之后,g已不是原来的g了,而且会在下一轮迭代使用,所以必须cache。另外,必须先用prevG保留对原来图的引用,并在新图产生后,快速将旧图彻底释放掉。否则,十几轮迭代后,会有内存泄漏问题,会很快耗光作业缓存空间。
7.mrTriplets——邻边聚合
mrTriplets(mapReduceTriplets)是GraphX中最核心的一个接口。Pregel也基于它而来,所以对它的优化能很大程度上影响整个GraphX的性能。mrTriplets运算符的简化定义是:

它的计算过程为:map应用于每一个Triplet上,生成一个或者多个消息,消息以Triplet关联的两个顶点中的任意一个或两个为目标顶点;reduce应用于每一个Vertex上,将发送给每一个顶点的消息合并起来。
mrTriplets最后返回的是一个VertexRDD[A],包含每一个顶点聚合之后的消息(类型为A),没有接收到消息的顶点不会包含在返回的VertexRDD中。
在最近的版本中,GraphX针对它进行了一些优化,对于Pregel以及所有上层算法工具包的性能都有重大影响。主要包括以下几点:
● Caching for Iterative mrTriplets&Incremental Updates for Iterative mrTriplets:在很多图分析算法中,不同点的收敛速度变化很大。在迭代后期,只有很少的点会有更新。因此,对于没有更新的点,下一次 mrTriplets计算时 EdgeRDD无须更新相应点值的本地缓存,大幅降低了通信开销。
● Indexing Active Edges:没有更新的顶点在下一轮迭代时不需要向邻居重新发送消息。因此,mrTriplets 遍历边时,如果一条边的邻居点值在上一轮迭代时没有更新,则直接跳过,避免了大量无用的计算和通信。
● Join Elimination:Triplet 是由一条边和其两个邻居点组成的三元组,操作 Triplet 的map函数常常只需访问其两个邻居点值中的一个。例如,在PageRank计算中,一个点值的更新只与其源顶点的值有关,而与其所指向的目的顶点的值无关。那么在mrTriplets计算中,就不需要VertexRDD和EdgeRDD的3-way join,而只需要2-way join。
所有这些优化使GraphX的性能逐渐逼近GraphLab。虽然还有一定差距,但一体化的流水线服务和丰富的编程接口,可以弥补性能的微小差距。
8.进化的Pregel模型
GraphX中的Pregel模型并不严格遵循标准Pregel模型,它是一个参考GAS改进的Pregel模型。定义如下:

这种基于mrTrilets方法的Pregel模型与标准Pregel的最大区别是,它的第2段参数体接收的是3个函数参数,而不接收messageList。它不会在单个顶点上进行消息遍历,而是将顶点的多个Ghost副本收到的消息聚合后,发送给Master副本,再使用vprog函数来更新点值。消息的接收和发送都被自动并行化处理,无须担心超级节点的问题。
常见的代码模板如下所示。

可以看到GraphX设计这个模型的用意。它综合了Pregel和GAS两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算。另外值得注意的是,官方的Pregel版本是最简单的一个版本。对于复杂的业务场景,根据这个版本扩展一个定制的Pregel是很常见的做法。
9.图算法工具包
GraphX也提供了一套图算法工具包,方便用户对图进行分析。目前最新版本已支持PageRank、数三角形、最大连通图和最短路径等6种经典的图算法。这些算法的代码实现,目的和重点在于通用性。如果要获得最佳性能,可以参考其实现进行修改和扩展满足业务需求。另外,研读这些代码,也是理解GraphX编程最佳实践的好方法。
1.Spark Streaming的构架
计算流程 :Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。
Spark Streaming流程图如图1-46所示。
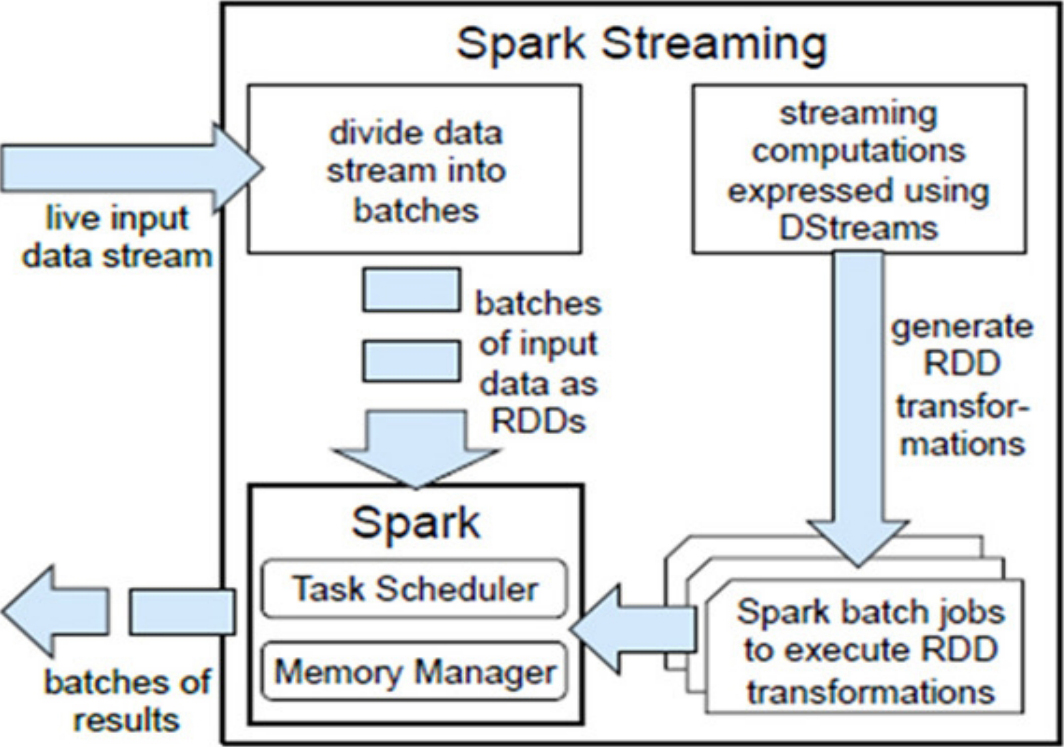
图1-46 Spark Streaming流程图
容错性 :对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
对于Spark Streaming来说,其RDD的传承关系如图1-47所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有3个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark Streaming输入数据可以来自于磁盘,例如HDFS(多份副本)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流复制两份到其他机器)都能保证容错性。所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
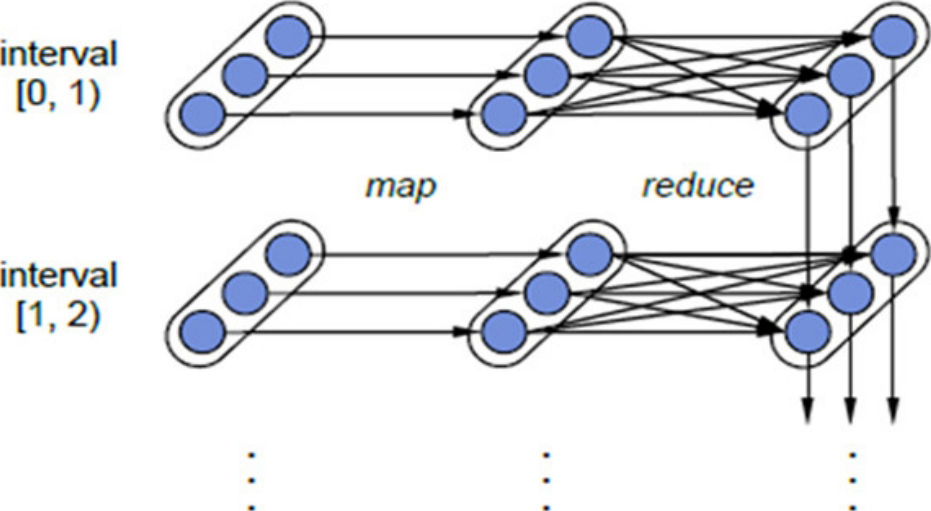
图1-47 Spark Streaming的RDD传承关系
实时性 :对于实时性的讨论,会牵涉流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解,以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒之间(Storm目前最小的延迟是100 ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
扩展性与吞吐量 :Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6 GB/s的数据量(60 MB records/s),其吞吐量也比流行的Storm高2~5倍。图1-48是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark Streaming中的每个节点的吞吐量是670 KB records/s,而Storm是115 KB records/s。
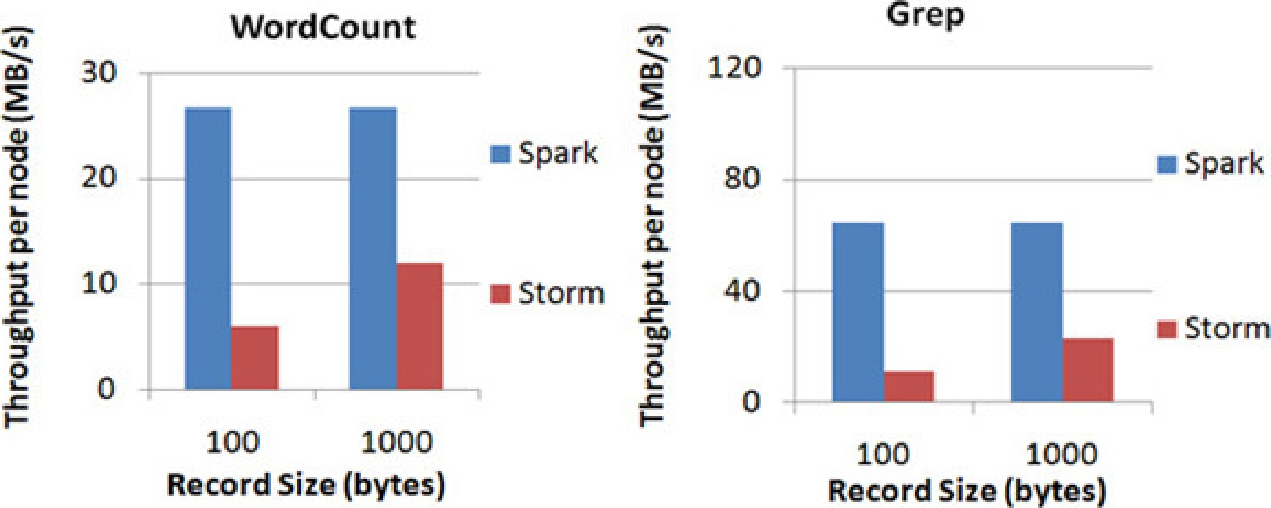
图1-48 Berkeley利用WordCount和Grep两个用例所做的测试
2.Spark Streaming的编程模型
Spark Streaming的编程和Spark的编程如出一辙,对于编程的理解也非常类似。对于Spark来说,编程就是对于RDD的操作;而对于Spark Streaming来说,就是对DStream的操作。下面将通过一个大家熟悉的WordCount的例子来说明Spark Streaming中的输入操作、转换操作和输出操作。
· Spark Streaming的初始化:在开始进行DStream操作之前,需要对Spark Streaming进行初始化并生成 StreamingContext。参数中比较重要的是第一个和第三个,第一个参数是指定Spark Streaming运行的集群地址,而第三个参数是指定Spark Streaming运行时的batch窗口的大小。在这个例子中,就是将1秒的输入数据进行一次Spark Job处理。
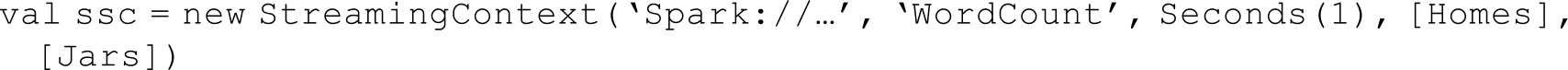
· Spark Streaming的输入操作:目前Spark Streaming已支持了丰富的输入接口。接口大致分为两类:一类是磁盘输入,如以batch size作为时间间隔监控HDFS文件系统的某个目录,将目录中内容的变化作为 Spark Streaming的输入;另一类就是网络流的方式,目前支持Kafka、Flume、Twitter和TCP socket。在WordCount例子中,假定通过网络socket作为输入流,监听某个特定的端口,最后得出输入DStream(lines)。
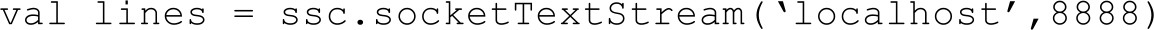
· Spark Streaming的转换操作:与Spark RDD的操作极为类似,Spark Streaming也是通过转换操作将一个或多个 DStream 转换成新的 DStream。常用的操作包括 map、filter、flatmap和join,以及需要进行shuffle操作的groupByKey/reduceByKey等。在WordCount 例子中,我们首先需要将 DStream(lines)切分成单词,然后将相同单词的数量进行叠加,最终得到的wordCounts就是每一个batch size(单词,数量)的中间结果。
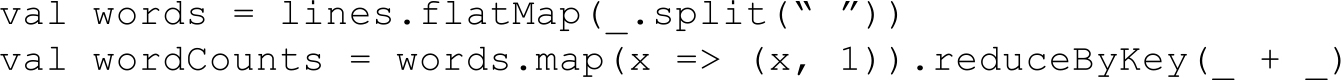
另外,Spark Streaming有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window Duration),另一个是窗口滑动的频率(Slide Duration)。这两个参数必须是batch size的倍数。例如以过去5秒为一个输入窗口,每1秒统计一下WordCount,那么我们会将过去5秒的每一秒的WordCount都进行统计,然后进行叠加,得出这个窗口中的单词统计。
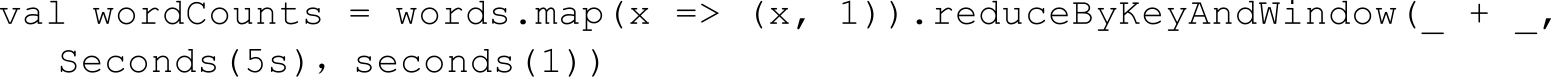
但上面这种方式还不够高效。如果我们以增量的方式来计算就更加高效。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,再减去[t-2,t-1]的统计量(如图1-49所示),这种方法可以复用中间三秒的统计量,提高了统计的效率。
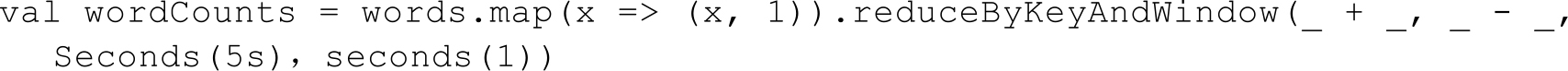
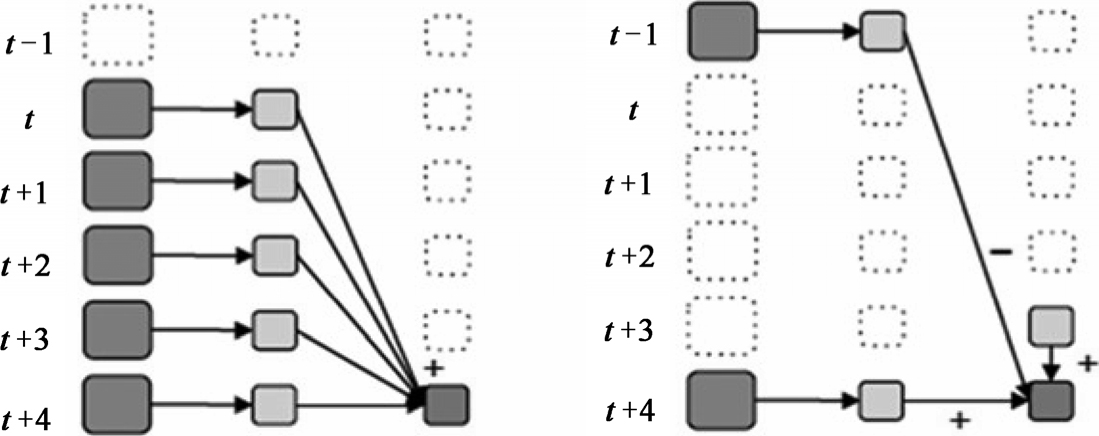
图1-49 Spark Streaming中滑动窗口的叠加处理和增量处理示意图
· Spark Streaming的输入操作:对于输出操作,Spark提供了将数据打印到屏幕及输入到文件中的功能。在WordCount中我们将DStream wordCounts输入到HDFS文件中。
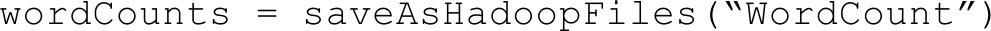
· Spark Streaming的启动:经过上述的操作,Spark Streaming还没有进行工作,我们还需要调用Start操作,Spark Streaming才开始监听相应的端口,然后收取数据,并进行统计。
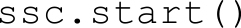
3.Spark Streaming案例分析
在互联网应用中,网站流量统计作为一种常用的应用模式,需要在不同粒度上对不同数据进行统计,既有实时性的需求,又需要涉及聚合、去重、连接等较为复杂的统计需求。传统上,若是使用Hadoop MapReduce框架,虽然可以容易地实现较为复杂的统计需求,但实时性却无法得到保证;反之若是采用Storm这样的流式框架,实时性虽可以得到保证,但需求的实现复杂度也大大提高了。Spark Streaming在两者之间找到了一个平衡点,能够以准实时的方式容易地实现较为复杂的统计需求。下面介绍一下使用Kafka和Spark Streaming搭建实时流量统计框架。
· 数据暂存:Kafka作为分布式消息队列,既有非常优秀的吞吐量,又有较高的可靠性和扩展性,在这里采用Kafka作为日志传递中间件来接收日志,抓取客户端发送的流量日志,同时接收Spark Streaming的请求,将流量日志按序发送给Spark Streaming集群。
· 数据处理:将Spark Streaming集群与Kafka集群对接,Spark Streaming从Kafka集群中获取流量日志并进行处理。Spark Streaming会实时地从Kafka集群中获取数据并将其存储在内部的可用内存空间中。当每一个batch窗口到来时,便对这些数据进行处理。
· 结果存储:为了便于前端展示和页面请求,处理得到的结果将写入到数据库中。
相比于传统的处理框架,Kafka+Spark Streaming的架构有以下几个优点。
· Spark框架的高效和低延迟保证了Spark Streaming操作的准实时性。
· 利用Spark框架提供的丰富API和高灵活性,可以精简地写出较为复杂的算法。
· 编程模型的高度一致使得上手 Spark Streaming 相当容易,同时也可以保证业务逻辑在实时处理和批处理上的复用。
在基于Kafka+Spark Streaming的流量统计应用运行过程中,有时会遇到内存不足、GC阻塞等各种问题。下面介绍如何对Spark Streaming应用程序进行调优来减少甚至避免这些问题的影响。
优化运行时间:
· 增加并行度。确保使用整个集群的资源,而不是把任务集中在几个特定的节点上。对于包含shuffle的操作,增加其并行度以确保更为充分地使用集群资源。
· 减少数据序列化、反序列化的负担。Spark Streaming默认将接收到的数据序列化后存储以减少内存的使用。但序列化和反序列化需要更多的 CPU 时间,因此更加高效的序列化方式(Kryo)和自定义的序列化接口可以更高效地使用CPU。
· 设置合理的batch窗口。在Spark Streaming中,Job之间有可能存在着依赖关系,后面的Job必须确保前面的Job执行结束后才能提交。若前面的Job执行时间超出了设置的batch窗口,那么后面的Job就无法按时提交,这样就会进一步拖延接下来的Job,造成后续 Job 的阻塞。因此,设置一个合理的 batch 窗口确保 Job 能够在这个 batch窗口中结束是必须的。
· 减少任务提交和分发所带来的负担。通常情况下Akka框架能够高效地确保任务及时分发,但当batch窗口非常小(500 ms)时,提交和分发任务的延迟就变得不可接受了。使用 Standalone 模式和 Coarse-grained Mesos 模式通常会比使用 Fine-Grained Mesos模式有更小的延迟。
优化内存使用:
· 控制batch size。Spark Streaming会把batch窗口内接收到的所有数据存放在Spark内部的可用内存区域中,因此必须确保当前节点Spark的可用内存至少能够容纳这个batch窗口内所有的数据,否则必须增加新的资源以提高集群的处理能力。
· 及时清理不再使用的数据。上面说到 Spark Streaming 会将接收到的数据全部存储于内部的可用内存区域中,因此对于处理过的不再需要的数据应及时清理以确保Spark Streaming 有富余的可用内存空间。通过设置合理的 spark.cleaner.ttl 时长来及时清理超时的无用数据。
· 观察及适当调整GC策略。GC会影响Job的正常运行,延长Job的执行时间,引起一系列不可预料的问题。观察GC的运行情况,采取不同的GC策略以进一步减小内存回收对Job运行的影响。
1.SparkSQL解析
Spark SQL是Spark 1.0.0开始发布的,新发布的Spark SQL组件让Spark对SQL有了别样于Shark基于Hive的支持,Spark SQL的四个特点如下:
其一,能在Scala代码里写SQL,支持简单的SQL语法检查,能把RDD指定为Table存储起来。此外支持部分SQL语法的DSL。
其二,支持Parquet文件的读/写,且保留Schem。
其三,支持直接多JSON格式数据的操作。
其四,能在Scala代码里访问Hive元数据,能执行Hive语句,并且把结果取回作为RDD使用。
第一点对SQL的支持主要依赖了Catalyst这个新的查询优化框架,在把SQL解析成逻辑执行计划之后,利用Catalyst包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD的计算。虽然目前的sql parser比较简单,执行计划的优化比较通配,还有些参考价值,所以看了下这块代码。目前这个PR在昨天已经merge进了主干,可以在SQL模块里看到这部分实现,还有catalyst模块看到Catalyst的代码。下面会具体介绍Spark SQL模块的实现。
第二点对Parquet是非常重要的,Parquet是一个列式存储格式的文件系统,使用Parquet进行文件读/写可以极大地降低对CPU和磁盘I/O的消耗。
第三点对JSON的操作也是非常重要的,JSON是一种流行的数据存储和传输格式,Spark SQL提供的对JSON的操作丰富了Spark SQL的应用场景和数据来源。
第四点对Hive的这种结合方式尚未有什么核心的进展。与Shark相比,Shark依赖Hive的Metastore,解析器等能把hql执行变成Spark上的计算,而Hive的现在这种结合方式与代码里引入Hive包执行hql没什么本质区别,只是把Hive hql的数据与RDD的打通这种交互做得更友好了。
SparkSQL的前身是Shark,而Shark的前身是Hadoop中的Hive。
其中Shark是伯克利实验室Spark生态环境的组件之一,它修改了图1-50中右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10~100倍的提升。
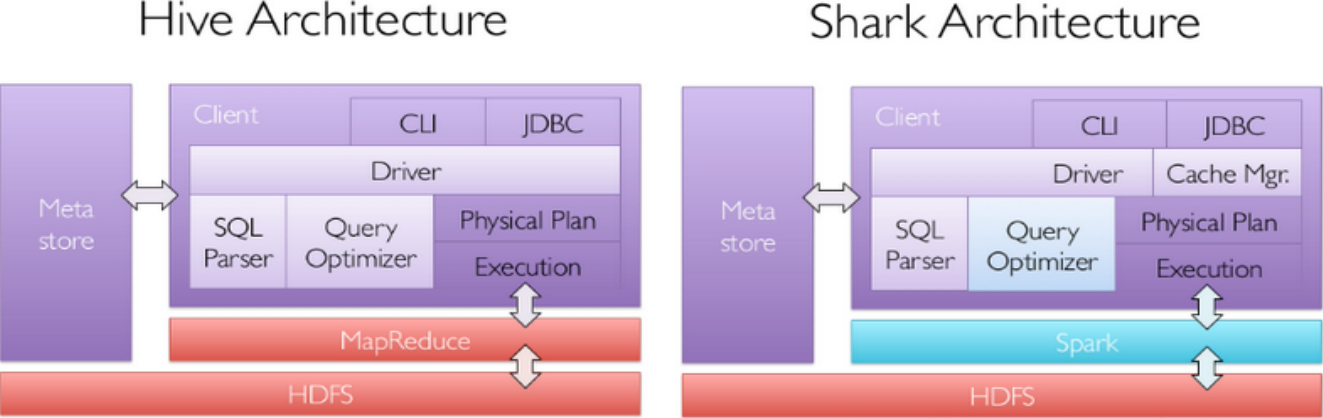
图1-50 Hive和Shark生态环境的组件
随着Spark的发展,Spark团队逐渐发现Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等),制约了Spark的One Stack rule them all的既定方针,制约了Spark各个组件的相互集成,所以提出了Spark SQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了Spark SQL代码。由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“一步海阔天空”
2014年6月1日,Shark项目和Spark SQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放Spark SQL项目上,至此,Shark的发展画上了句号,但也因此发展出两个分支:Spark SQL和Hive on Spark,如图1-51所示。
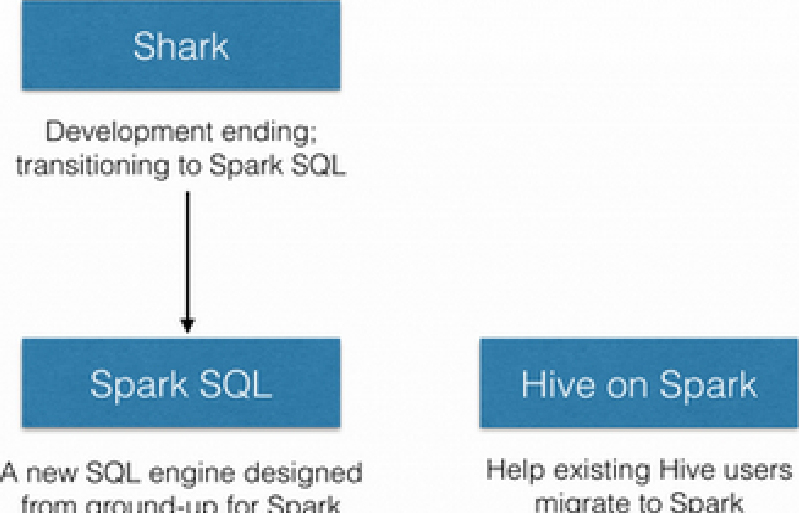
图1-51 Shark的发展
其中Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用map-reduce、Tez、Spark等引擎。
2.Spark SQL的性能
Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10~100倍的提高,如图1-52所示。
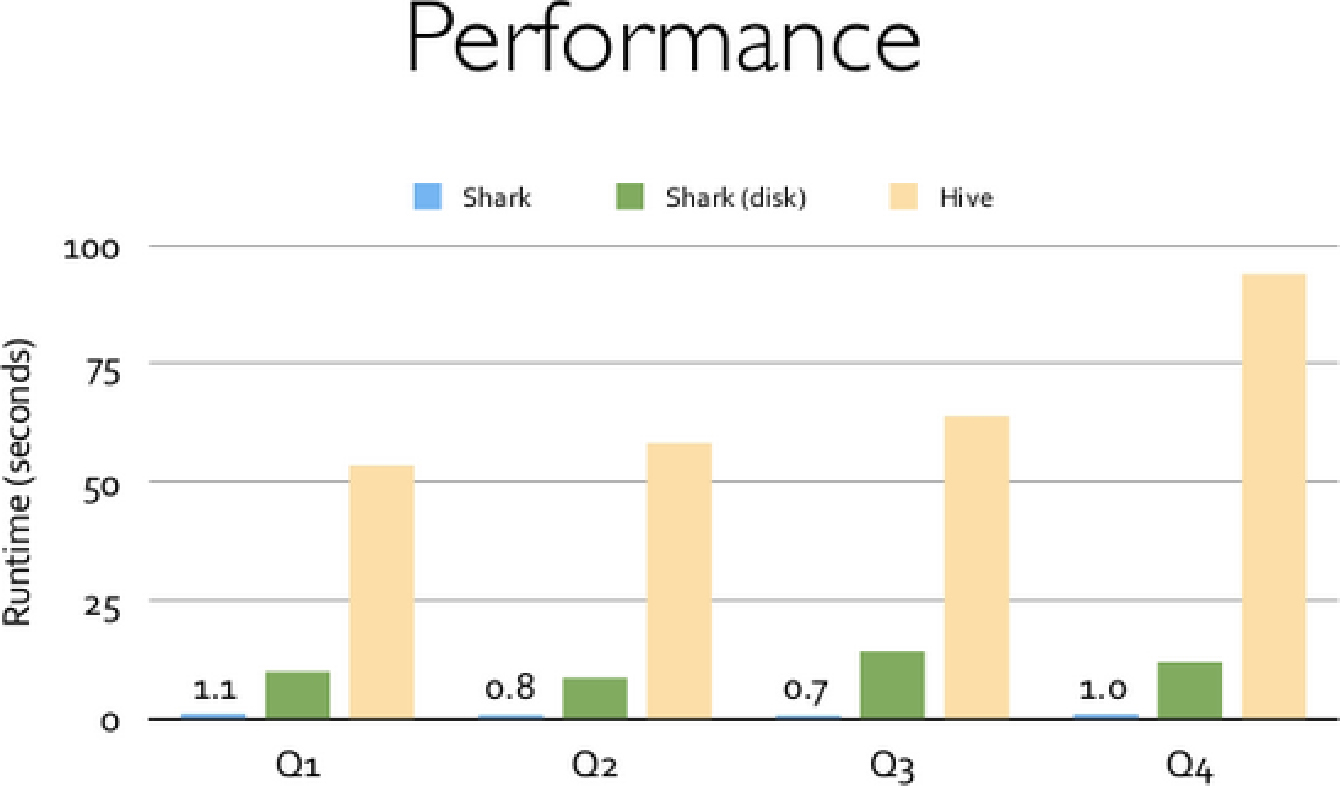
图1-52 Shark与Hive的性能对比
摆脱了Hive的限制,Spark SQL的性能提升也表现得非常优异,如图1-53所示。
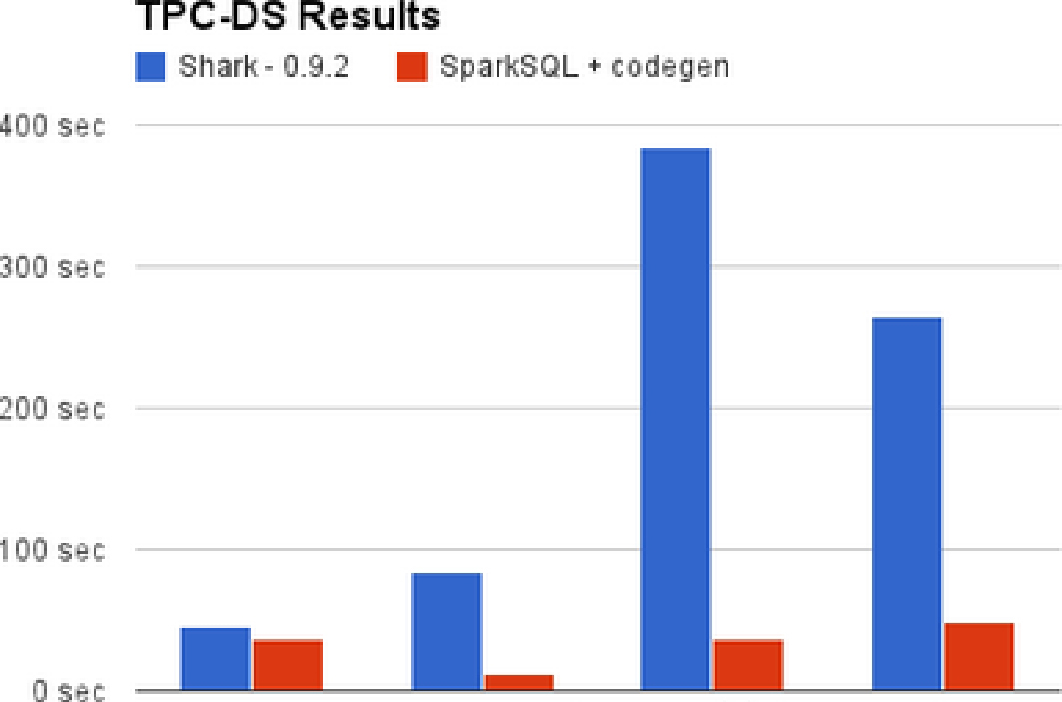
图1-53 Spark SQL和Shark的性能对比
MLlib 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。MLlib 目前支持4种常见的机器学习问题:二元分类、回归、聚类以及协同过滤,同时也包括一个底层的梯度下降优化基础算法。本节将会简要介绍 MLlib 中所支持的功能,并给出相应的调用 MLlib 的例子。
1.依赖
MLlib 将会调用 jblas 线性代数库,这个库本身依赖于原生的 Fortran 程序。如果你的节点中没有这些库,也许会需要安装 gfortran runtime library。如果程序没有办法自动检测到这些库,MLlib 将会抛出链接错误的异常。
如果想用 Python 调用 MLlib,你需要安装 NumPy 1.7 或者更新的版本。
2.二元分类
二元分类是一个监督学习问题。在这个问题中,我们希望将实体归类到两个独立的类别或其中的一个标签中,例如判断一个邮件是否是垃圾邮件。这个问题涉及在一组被打过标签的样例运行一个学习算法,例如一组由(数字)特征和(相关的)类别标签所代表的实体。这个算法将会返回一个训练好的模型,该模型能够对标签未知的新个体进行潜在标签预测。
MLlib 目前支持两个适用于二元分类的标准模型家族:线性支持向量机(SVMs)和逻辑回归,同时也包括分别适用于这两个模型家族的 L1 和 L2 正则化变体。这些训练算法都利用了一个底层的梯度下降基础算法。二元分类算法的输入值是一个正则项参数(regParam)和多个与梯度下降相关的参数(stepSize,numIterations,miniBatchFraction)。
目前可用的二元分类算法:

3.线性回归
线性回归是另一个经典的监督学习问题。在这个问题中,每个个体都有一个与之相关联的实数标签(而在二元分类中个体的标签都是二元的),并且我们希望在给出用于表示这些实体的数值特征后,所预测出的标签值可以尽可能地接近实际值。MLlib支持线性回归和与之相关的 L1(lasso)和 L2(ridge)正则化的变体。MLlib中的回归算法也利用了底层的梯度下降基础算法,输入参数与上述二元分类算法一致。
目前可用的线性回归算法:

4.聚类
聚类是一个非监督学习问题,在这个问题上,我们的目标是将一部分实体根据某种意义上的相似度和另一部分实体聚在一起。聚类通常被用于探索性的分析,或者作为层次化监督学习管道网(hierarchical supervised learning pipeline)的一个组件(其中每一个类簇都会用于训练不同的分类器或者回归模型)。MLlib目前已经支持作为最被广泛使用的聚类算法之一的 k-means聚类算法,根据事先定义的类簇个数,这个算法能对数据进行聚类。MLlib的实现中包含一个 k-means++方法的并行化变体 kmeans||。MLlib里面的实现有如下的参数:
● k 是所需的类簇的个数;
● maxIterations 是最大的迭代次数;
● initializationMode 这个参数决定了是用随机初始化还是通过 k-means||进行初始化;
● runs 是跑 k-means 算法的次数(k-mean 算法不能保证能找出最优解,如果在给定的数据集上运行多次,算法将会返回最佳的结果);
● initializiationSteps 决定了 k-means||算法的步数;
● epsilon 决定了判断 k-means 是否收敛的距离阈值。
目前可用的聚类算法:
KMeans
5.协同过滤
协同过滤常被应用于推荐系统。这一技术旨在补充用户—商品关联矩阵中所缺失的部分。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。为此,我们实现了交替最小二乘法(ALS)来学习这些隐性语义因子。在 MLlib中的实现有如下的参数:
● numBlocks 是用于并行化计算的分块个数(设置为-1为自动配置);
● rank 是模型中隐语义因子的个数;
● iterations 是迭代的次数;
● lambda 是ALS的正则化参数;
● implicitPrefs 决定了是用显性反馈ALS的版本还是用隐性反馈数据集的版本;
● alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
隐性反馈与显性反馈
基于矩阵分解的协同过滤的标准方法一般将用户商品矩阵中的元素作为用户对商品的显性偏好。
在现实生活的很多场景中,我们常常只能接触到隐性的反馈(例如游览、点击、购买、喜欢、分享等)。在 MLlib中所用到的处理这种数据的方法来源于文献:Collaborative Filtering for Implicit Feedback Datasets。本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分、矩阵直接进行建模。因此,评价就不是用户对商品的显性评分而是和所观察到的用户偏好强度关联了起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
目前可用的协同过滤的算法:
ALS
6.梯度下降基础算法
梯度下降(及其随机的变种)是非常适用于大型分布式计算的一阶优化方案。梯度下降旨在通过向一个函数当前点(当前的参数值)的负梯度方向移动的方式迭代地找到这个函数的本地最优解。MLlib以梯度下降作为一个底层的基础算法,在上面开发了各种机器学习算法。梯度下降算法有如下参数:
● gradient 这个类是用来计算要被优化的函数的随机梯度(如:相对于单一训练样本当前的参数值)。MLlib包含常见损失函数(hinge、logistic、least-squares)的梯度类。梯度类将训练样本、标签,以及当前的参数值作为输入值。
● updater 是在梯度下降的每一次迭代中更新权重的类。MLlib 包含适用于无正则项、L1 正则项和 L2 正则项3种情况下的类。
● stepSize 是一个表示梯度下降初始步长的数值。MLlib中所有的更新器第 t 步的步长等于 stepSize/sqrt(t)。
● numIterations 表示迭代的次数。
● regParam 是在使用L1、L2 正则项时的正则化参数。
● miniBatchFraction 是每一次迭代中用来计算梯度的数据百分比。
目前可用的梯度下降算法:
接下来用Scala调用MLlib,下面的4个机器学习算法中的代码段都可以在spark-shell中运行。
7.二元分类
下面的代码段演示了如何导入一份样本数据集,使用算法对象中的静态方法在训练集上执行训练算法,在所得的模型上进行预测并计算训练误差。

默认情况下,这个SVMWithSGD.train()方法使用正则参数为 1.0 的 L2 正则项。如果想配置这个算法,可以通过直接新建一个新的对象,并调用setter的方法,进一步个性化设置SVMWithSGD。其他 MLlib算法也是通过这样的方法来支持个性化的设置。比如,下面的代码给出了一个正则参数为0.1的 L1 正则化SVM变体,并且让这个训练算法迭代200遍。

8.线性回归
下面这个例子演示了如何导入训练集数据,将其解析为带标签点的RDD。然后,使用LinearRegressionWithSGD 算法来建立一个简单的线性模型来预测标签的值。最后我们计算了均方差来评估预测值与实际值的吻合度。
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.regression.LabeledPoint
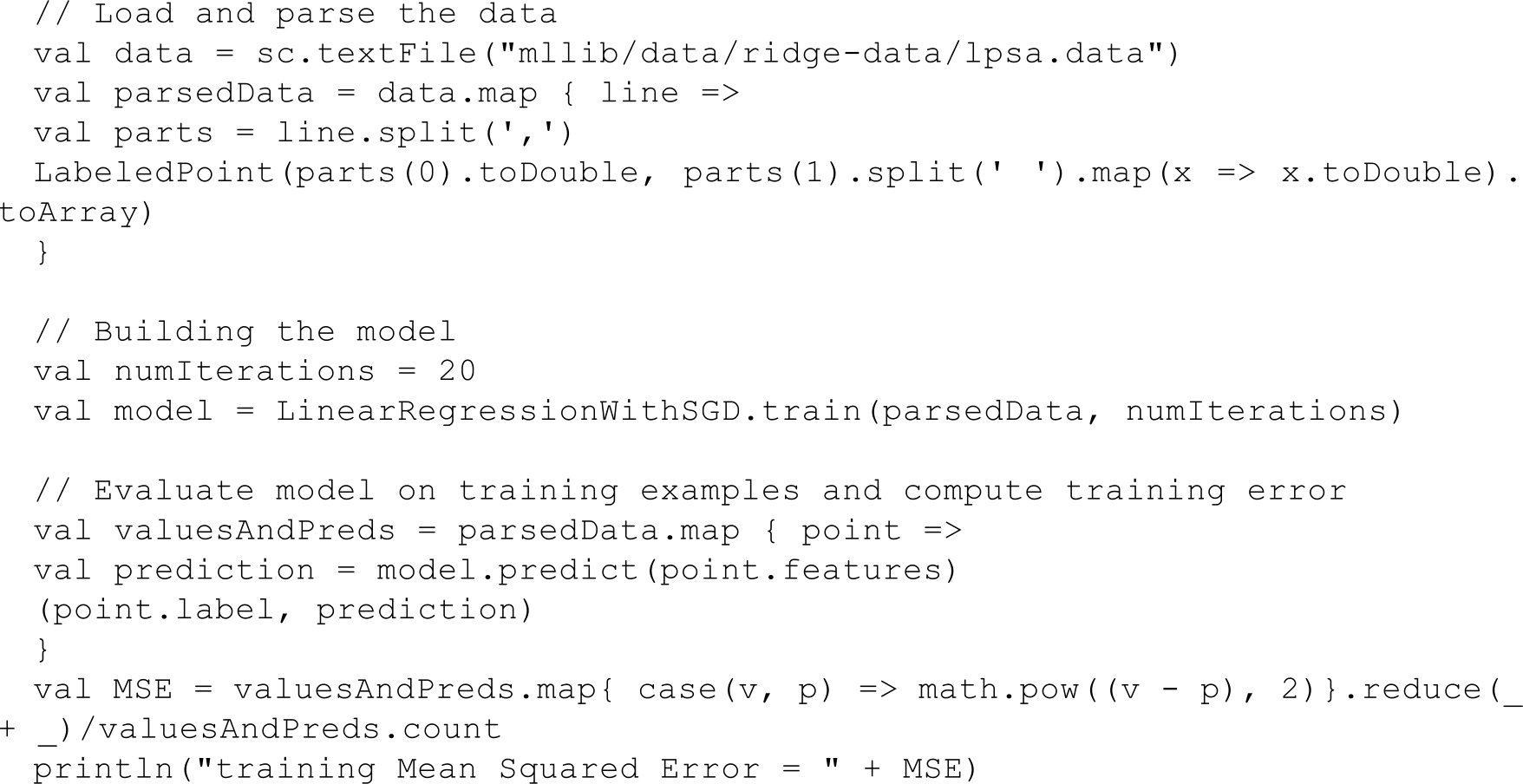
类似的,也可以使用 RidgeRegressionWithSGD 和 LassoWithSGD 这两个算法,并比较这些算法在训练集上的均方差。
9.聚类
在下面的例子中,在载入和解析数据之后,我们使用 KMeans 对象来将数据聚类到两个类簇当中。所需的类簇个数会被传递到算法中。然后我们将计算集内均方差总和(WSSSE)。你可以通过增加类簇的个数k 来减小误差。实际上,最优的类簇数通常是 1,因为这一点通常是WSSSE图中的“低谷点”。

10.协同过滤
在下面的例子中,我们导入的训练集中,数据每一行由一个用户、一个商品和相应的评分组成。假设评分是显性的,在这种情况下我们使用默认的ALS.train()方法。我们通过计算预测出的评分的均方差来评估这个推荐模型。

如果这个评分矩阵是通过其他信息来源(如从其他信号中提取出来的)所获得的,你也可以使用trainImplicit的方法来得到更好的结果。