
下载掌阅APP,畅读海量书库
立即打开




RDD是Spark抽象的基石,整个Spark的编程都是基于对RDD的操作完成的。
官方对RDD的解释是:弹性分布式数据集,全称为Resilient Distributed Datasets。RDD 只读、可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。所谓弹性,是指在内存不够时可以与磁盘进行交换。这涉及了RDD的另一特性:内存计算,就是将数据保存到内存中。同时为了解决内存容量限制问题,Spark为我们提供了最大的自由度,所有数据均可由我们来进行cache的设置,包括是否cache和如何cache。
RDD有如下特征:
(1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算。
(2)由一个函数计算每一个分片,这里指的是下面会提到的compute函数。
(3)对其他RDD的依赖列表,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。
(4)可选:key-value型的RDD是根据哈希来分区的,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce。
(5)可选:每一个分片的优先计算位置(preferred locations),比如HDFS的block的所在位置应该是优先计算的位置。
基于RDD这个统一的抽象,使得Spark可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce、Streaming、SQL、Machine Learning以及Graph等。正是RDD使得Spark具有了无可比拟的大数据处理平台的优势,如图4-1所示。
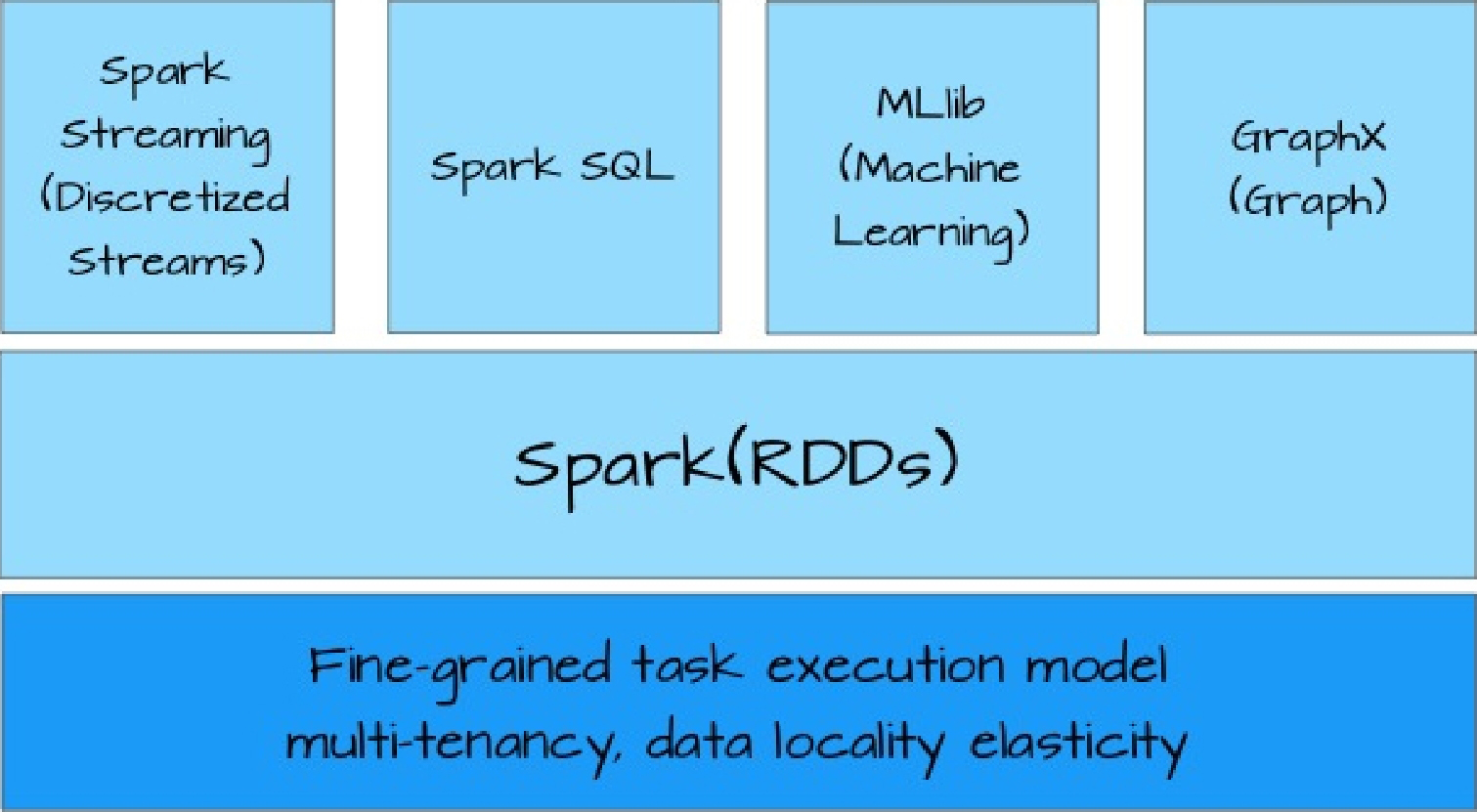
图4-1 以一致的方式应对不同的大数据处理场景
RDD是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据,如map、flatMap、filter等。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作,以支持常见的数据运算。
通常来讲,针对数据处理有几种常见模型,包括Iterative Algorithms、Relational Queries、MapReduce、Stream Processing。例如Hadoop MapReduce采用了MapReduces模型,Storm则采用了Stream Processing模型。RDD混合了这四种模型,使得Spark可以应用于各种大数据处理场景。
RDD作为数据结构,本质上是一个只读的分区记录集合。一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为shuffle(wide)dependency。不同的操作依据其特性,可能会产生不同的依赖。例如map操作会产生narrow dependency,而reduceByKey操作则产生shuffle(wide)dependency。
Spark之所以将依赖分为narrow与shuffle,基于两点原因:
首先,narrow dependencies可以支持在同一个cluster node上以pipeline形式执行多条命令,例如在执行了map后,紧接着执行filter。相反,shuffle dependencies需要所有的父分区都是可用的,可能还需要调用类似MapReduce之类的操作进行跨节点传递。
其次,则是从失败恢复的角度考虑。narrow dependencies的失败恢复更有效,因为它只需要重新计算丢失的parent partition即可,而且可以并行地在不同节点进行重计算。而shuffle dependencies牵涉RDD各级的多个Parent Partitions。图4-2说明了narrow dependencies与wide dependencies之间的区别。
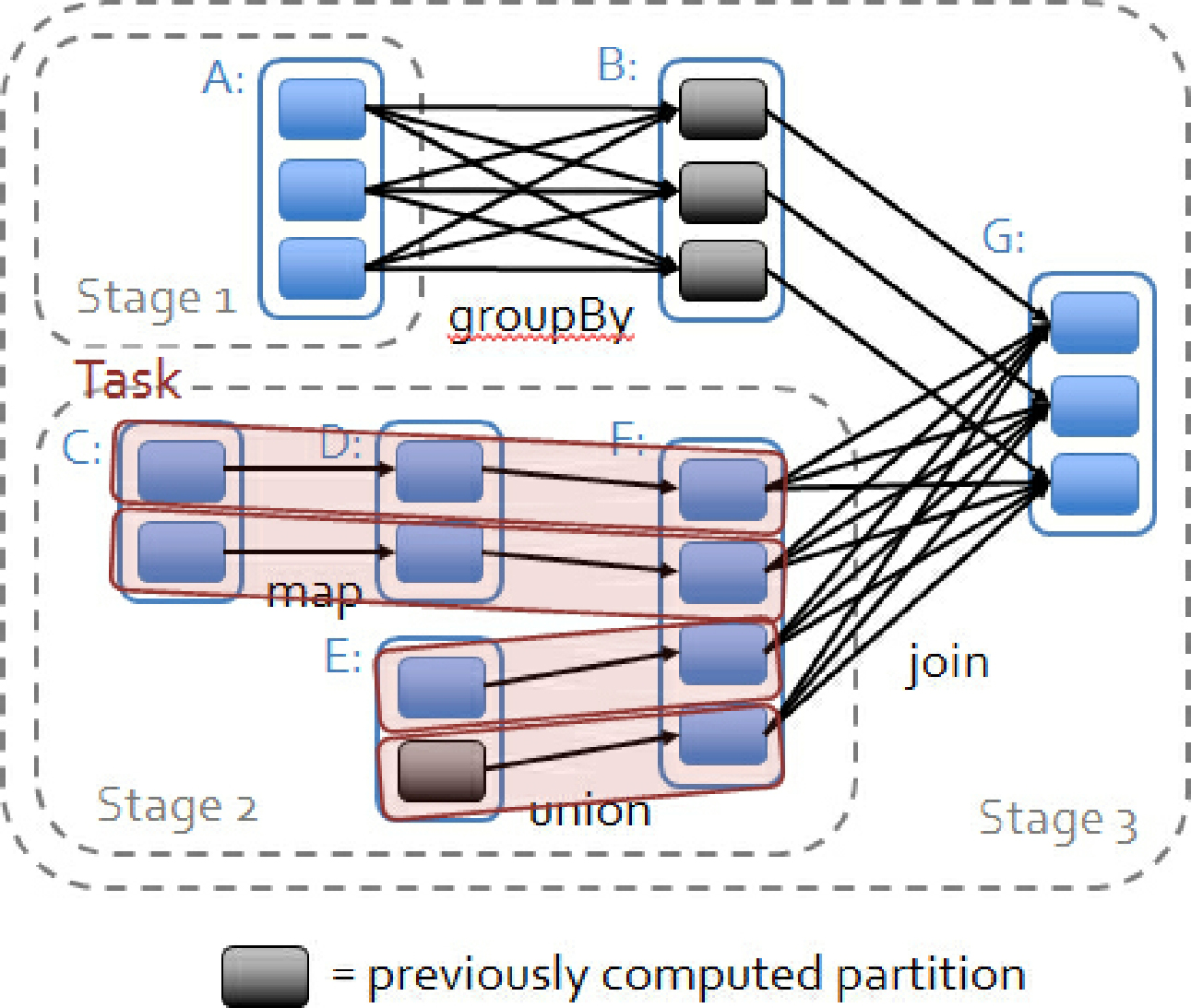
图4-2 narrow dependencies与wide dependencies之间的区别
在图4-2中,一个box代表一个RDD,一个带阴影的矩形框代表一个partition。
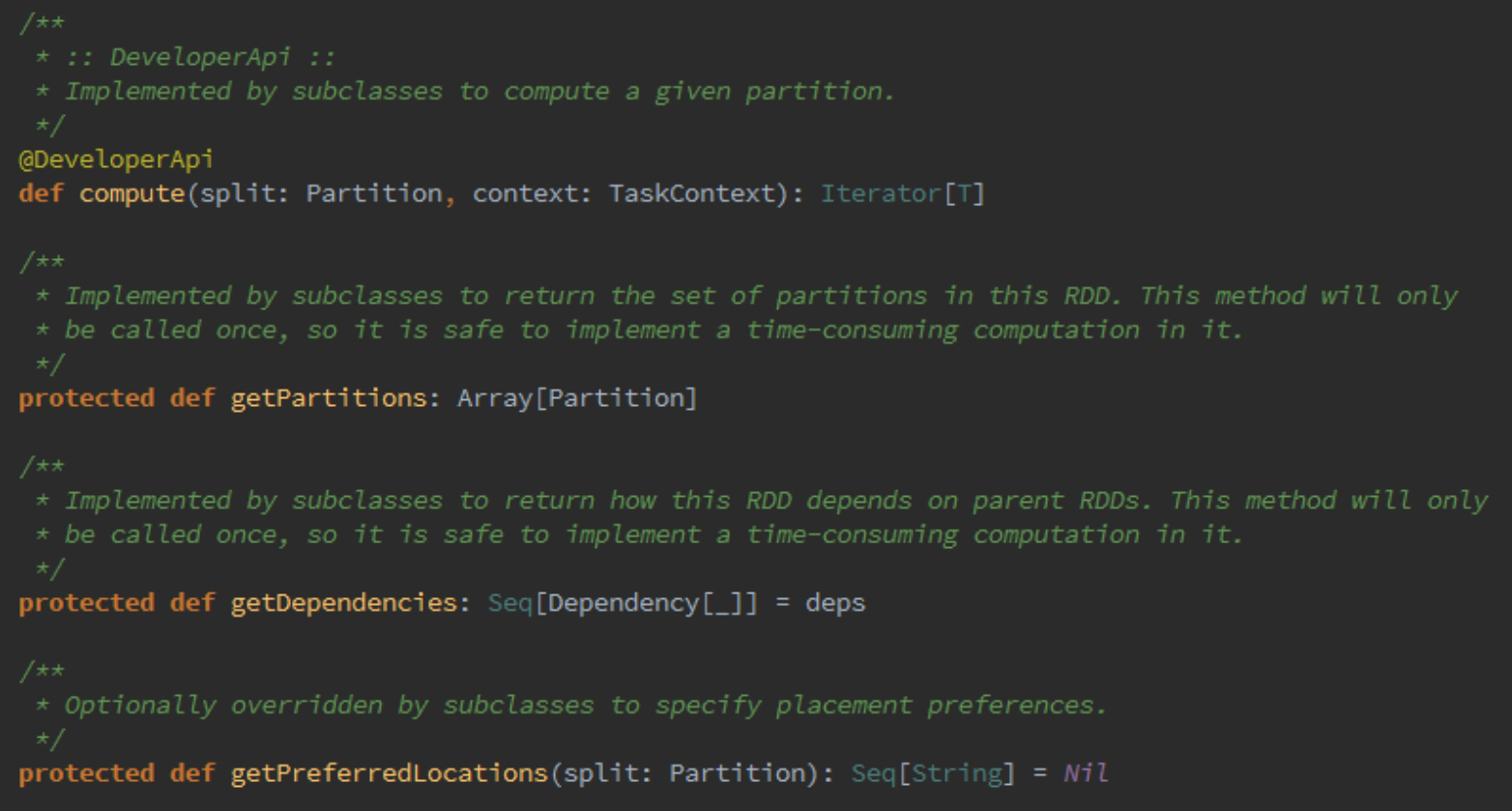
每个RDD的核心方法如下所示。
RDD主要分为两种,如图4-3所示。

图4-3 RDD的种类
下面初步分析一下RDD的四个核心方法,首先看一下getPartitions方法的源码:

getPartitions返回的是一系列partitions的集合,即一个Partition类型的数组。
getDependencies表达式RDD之间的依赖关系如下所示。

getDependencies返回的是依赖关系的一个Seq集合,里面的Dependency数组中的下画线是类型的PlaceHolder。
每个RDD都会具有计算的函数,如下所示。

Compute方法是针对RDD的每个Partition进行计算的,其TaskContext参数的源码如下:
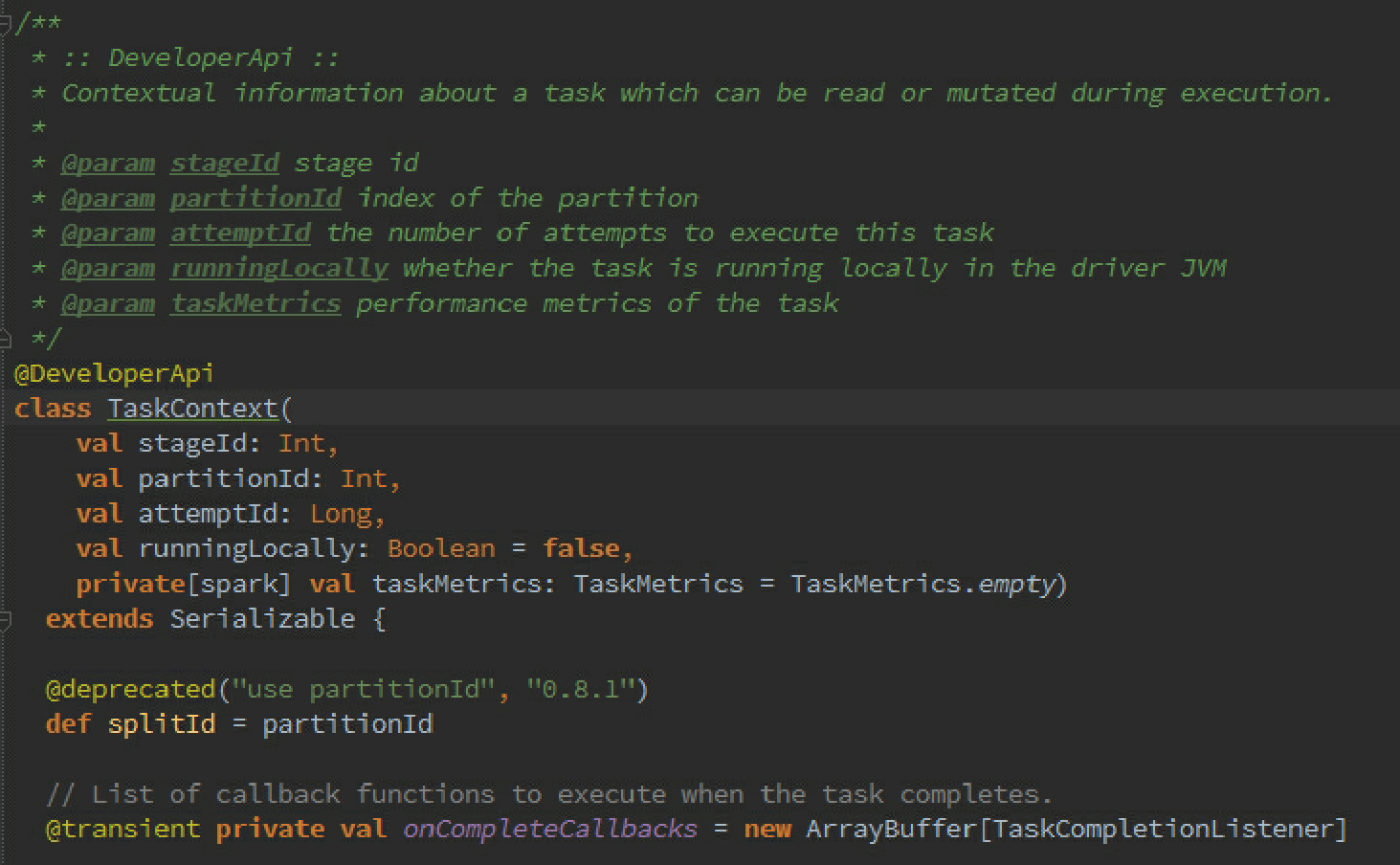
getPreferredLocations是寻找Partition的首选位置:

其实RDD还有一个可选的分区策略:

Partitioner的源码如下:
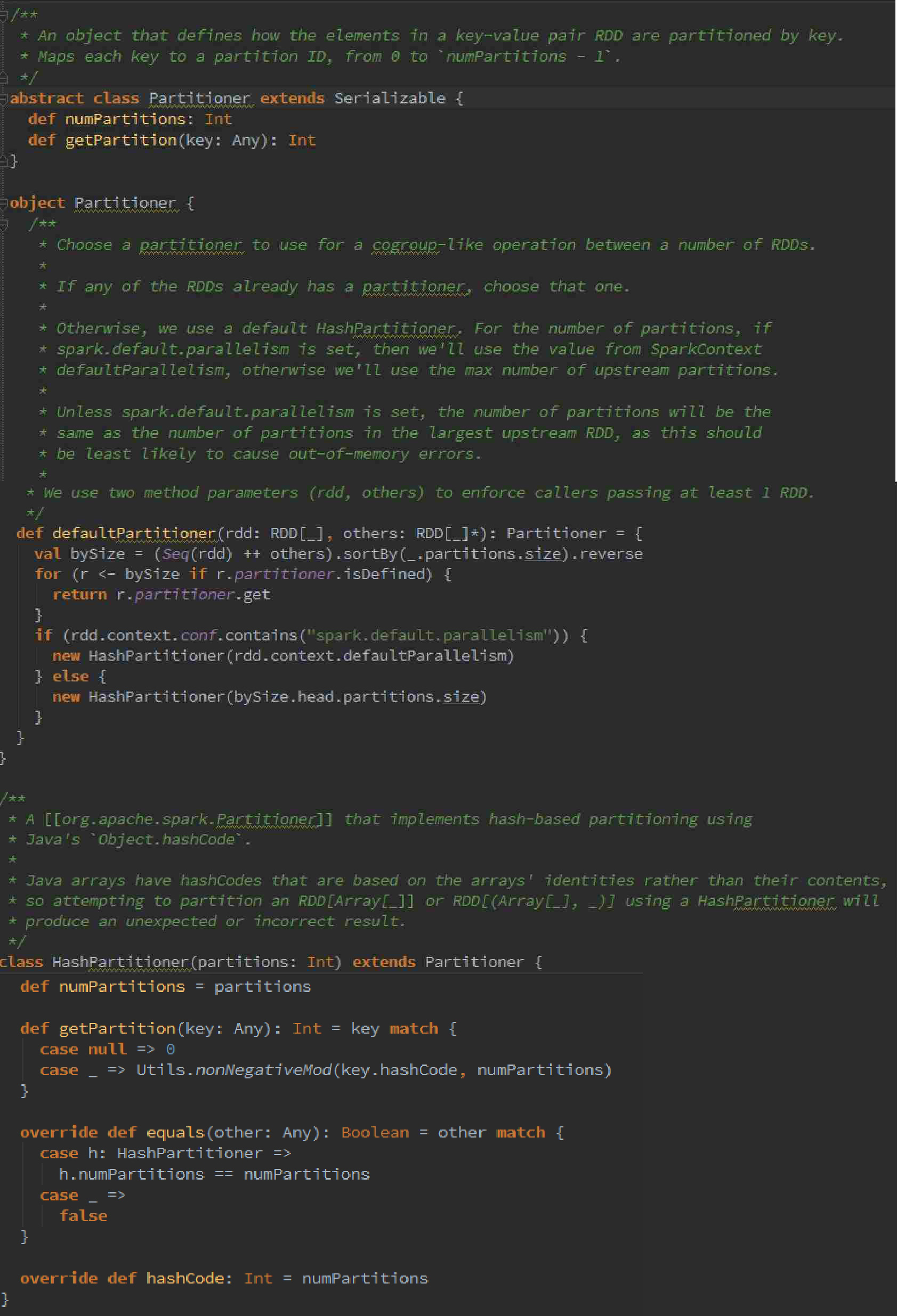
可以看出默认使用的是HashPartitioner,要注意key为Array的情况;