下载掌阅APP,畅读海量书库
立即打开




创建一个Scala IDEA工程,如图3-50所示。这里使用Non-SBT的方式,单击“Next”按钮,如图3-51所示,命名下工程,其他按照默认设置即可。
单击“Finish”按钮完成工程的创建,如图3-52所示。
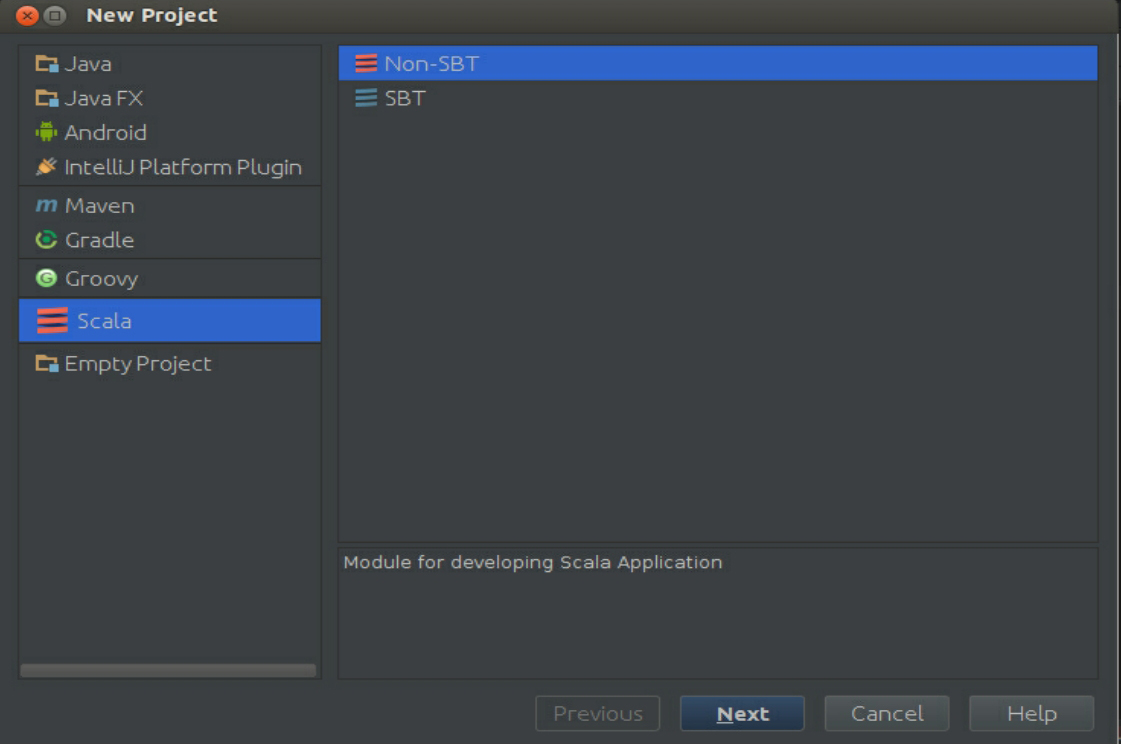
图3-50 创建一个Scala IDEA工程
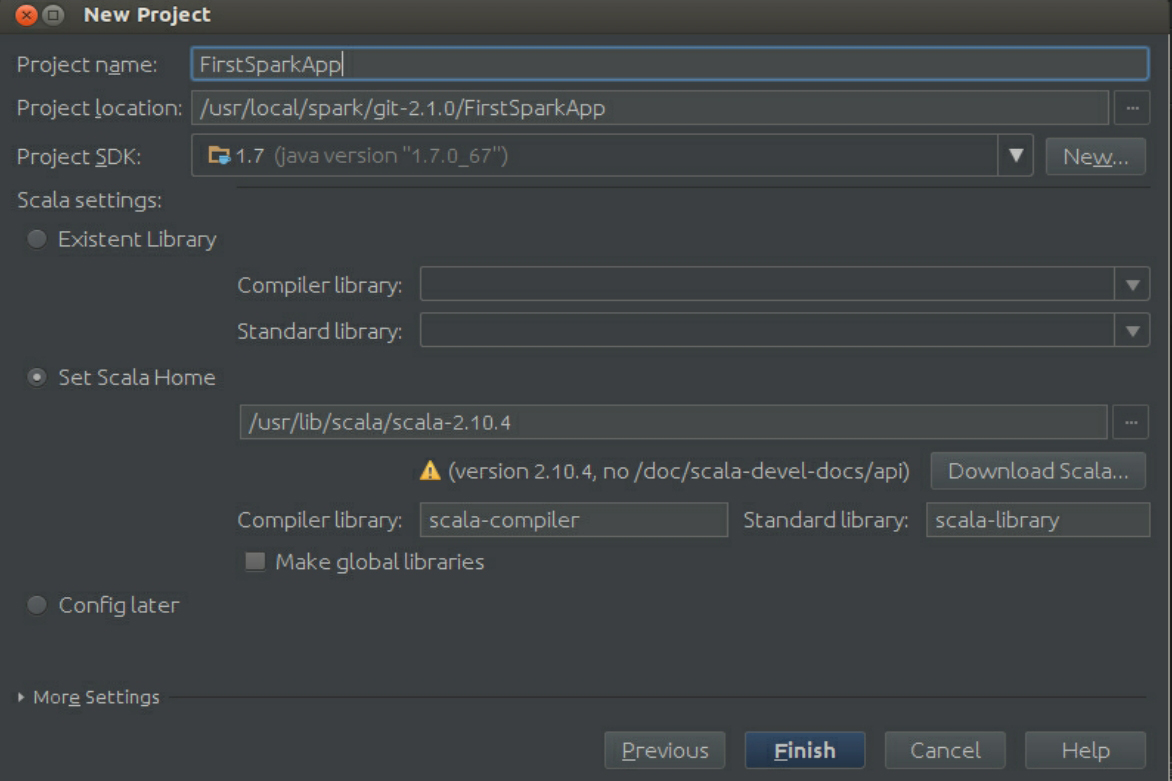
图3-51 命名工程
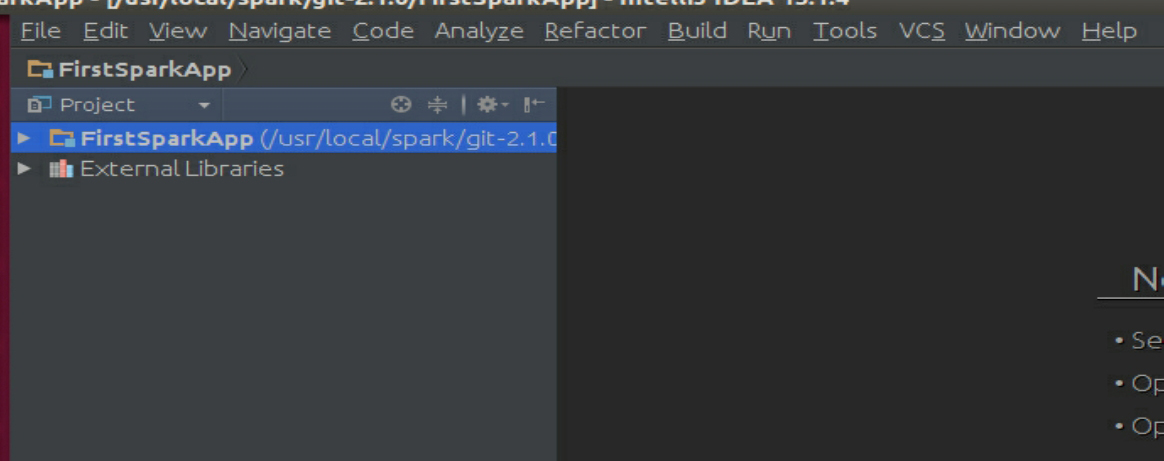
图3-52 完成创建
接下来,可修改项目的属性,如图3-53所示。
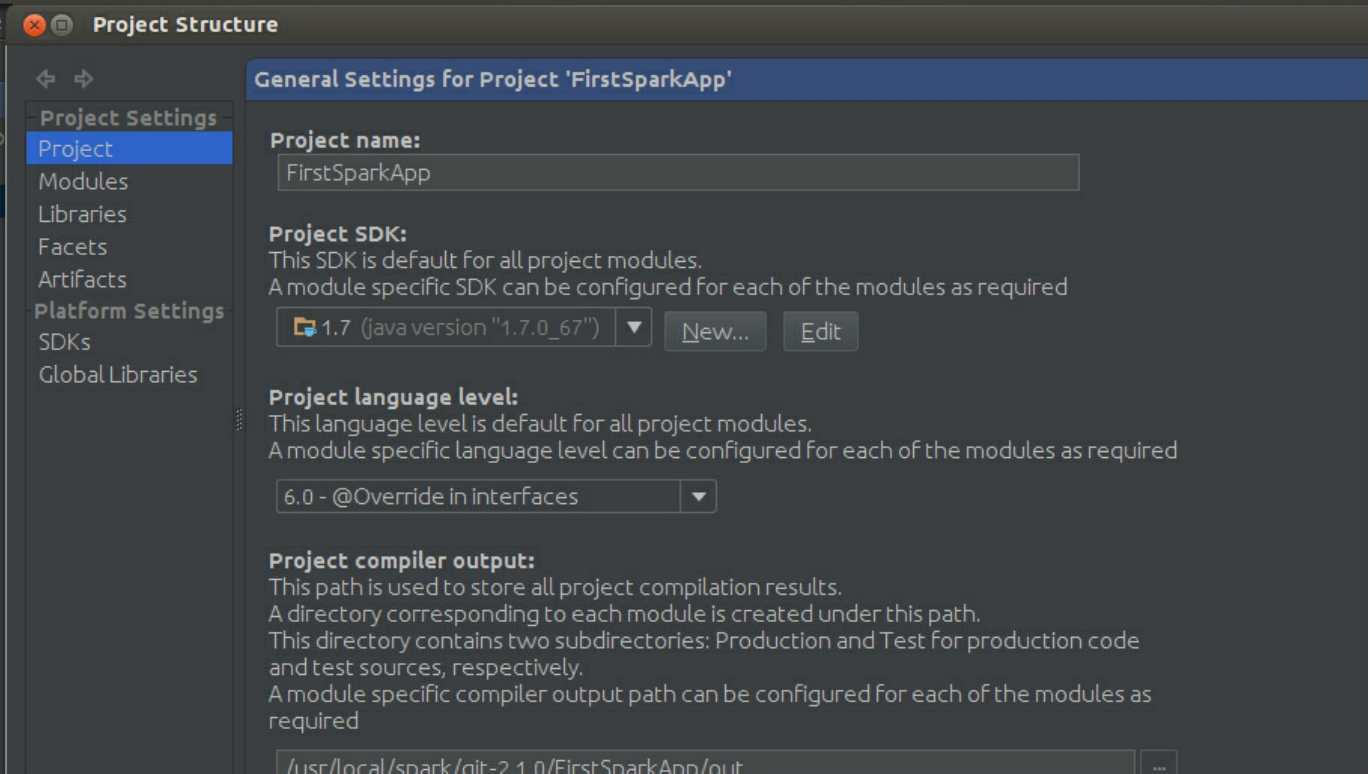
图3-53 修改属性
首先修改Modules选项,如图3-54所示,在src下创建两个文件夹,并把其属性改为source如图3-55所示。
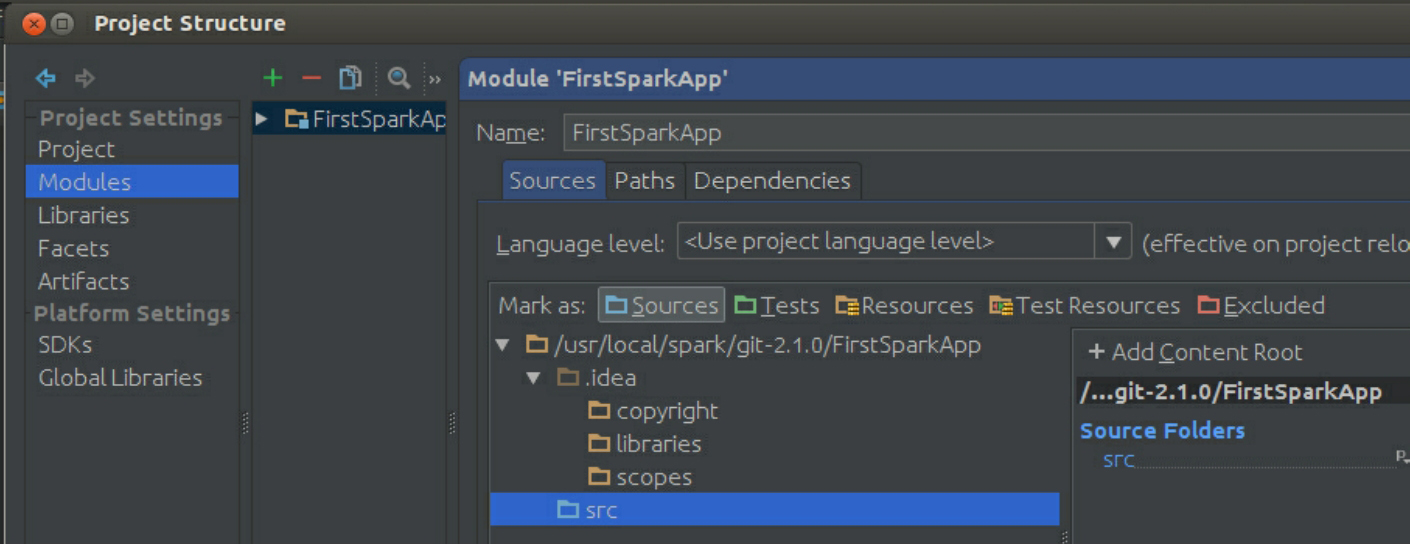
图3-54 Modules选项
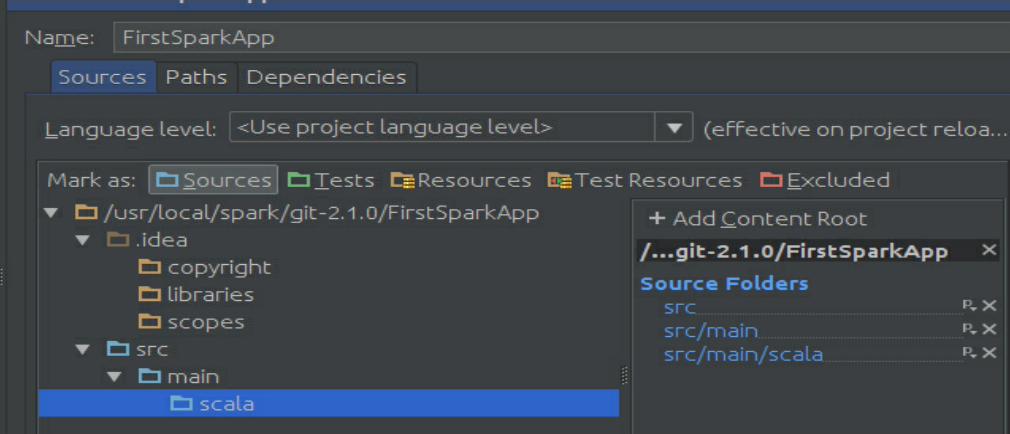
图3-55 创建文件夹
接下来修改Libraries,如图3-56所示。
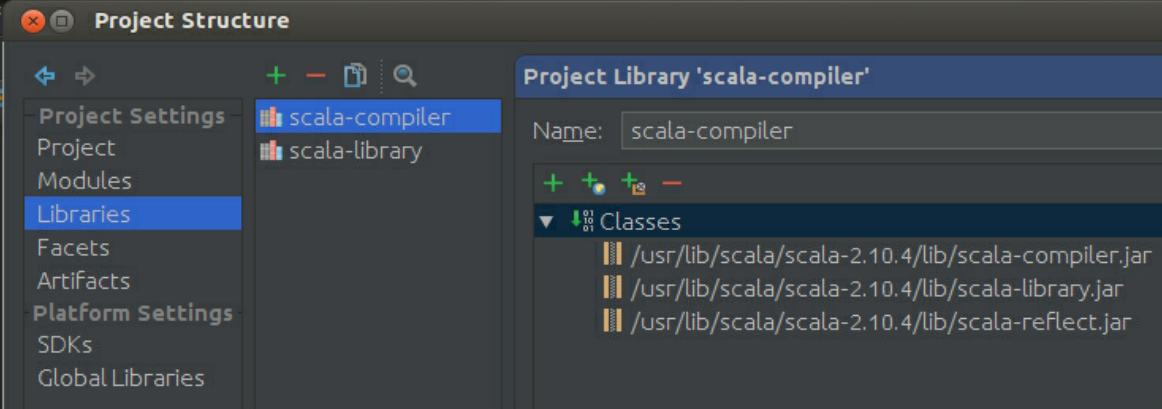
图3-56 修改Libraries
最后把Spark开发所需jar包导进来,如图3-57所示。
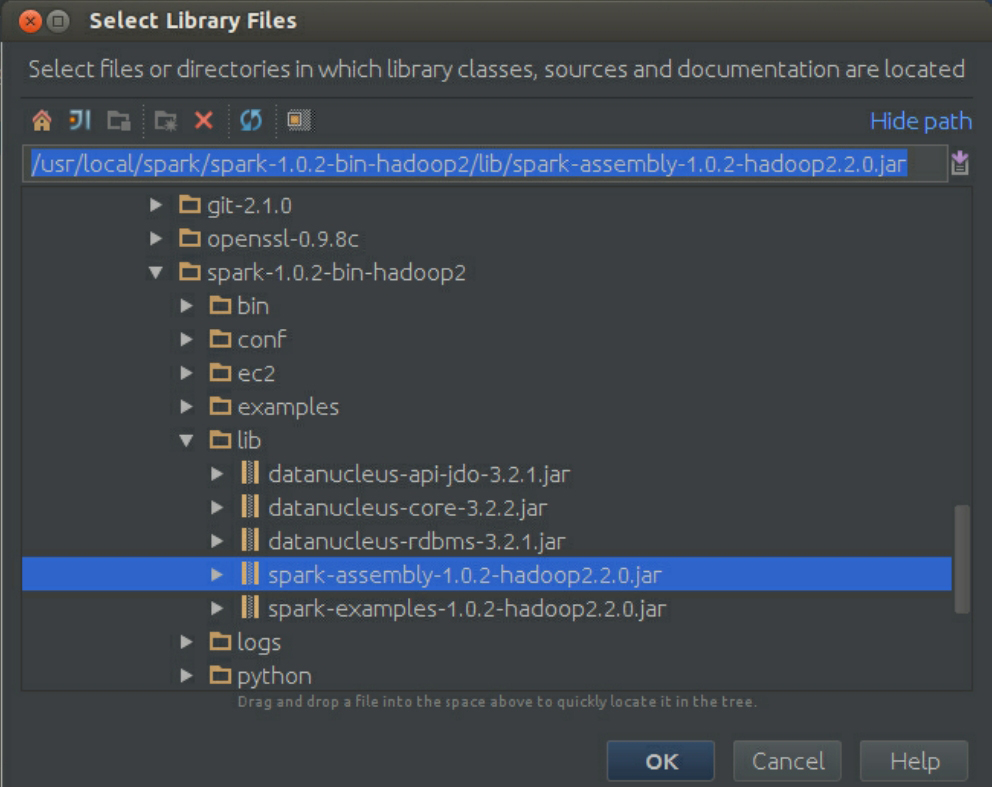
图3-57 导入Spark开发所需jar包
导入后的界面如图3-58所示。
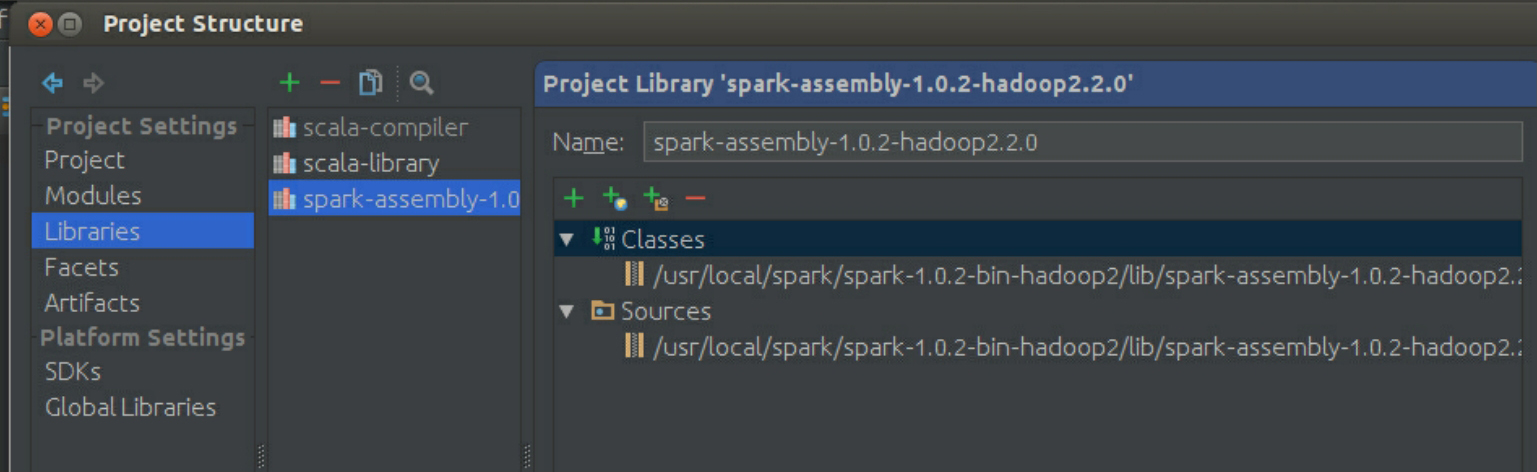
图3-58 导入完成的结果界面
导入包完成后,在工程的scala下面创建一个package,如图3-59所示。
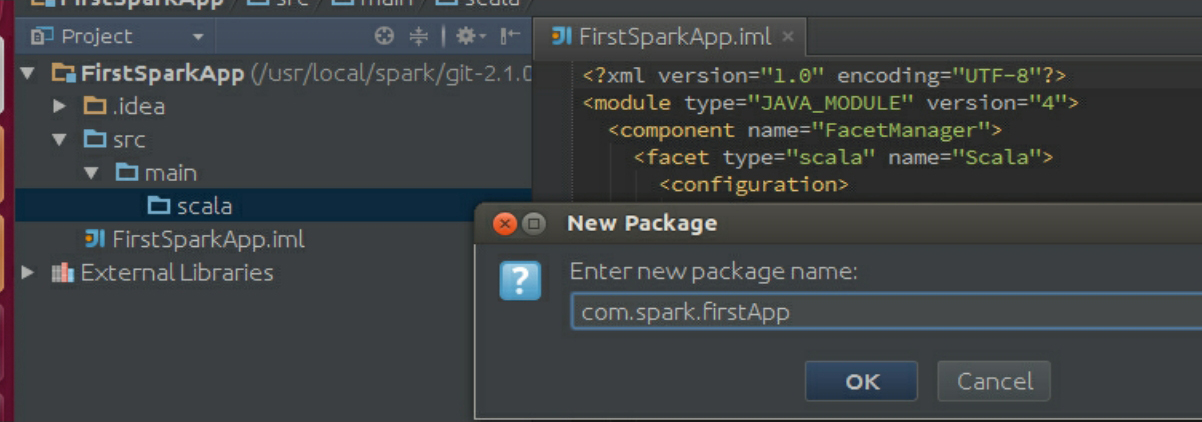
图3-59 创建一个package
接下来,创建一个Object对象,如图3-60所示。
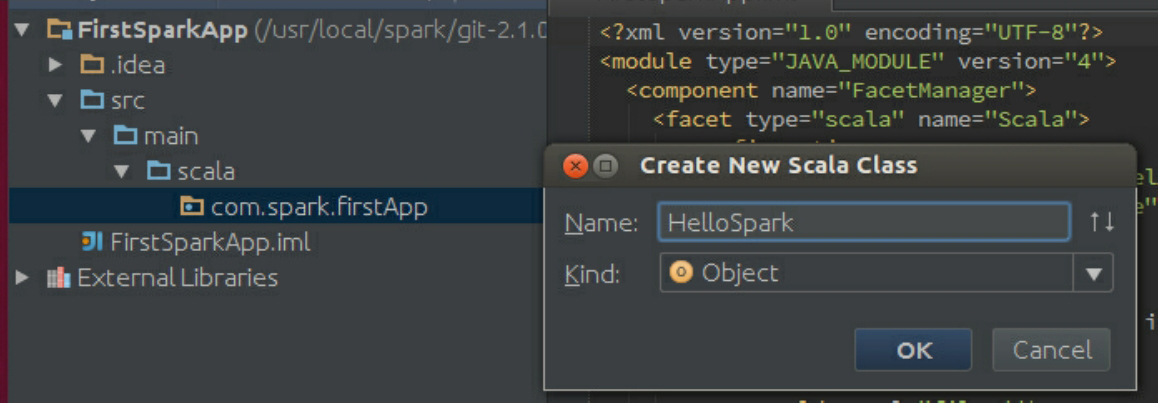
图3-60 创建一个Object对象
完成初始类的创建,如图3-61所示。
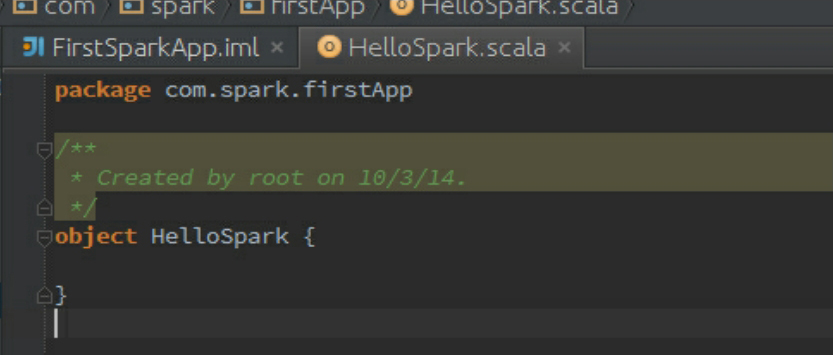
图3-61 完成初始类的创建
此时,首先要构建Spark Driver的模板代码,如图3-62所示。该程序是对本书第4章中提到的搜狗日志的处理代码,只不过这个时候在IDEA中编写而已。
接下来进行打包,使用Project Structure的Artifacts,如图3-63所示。
使用From modules with dependencies,如图3-64所示。
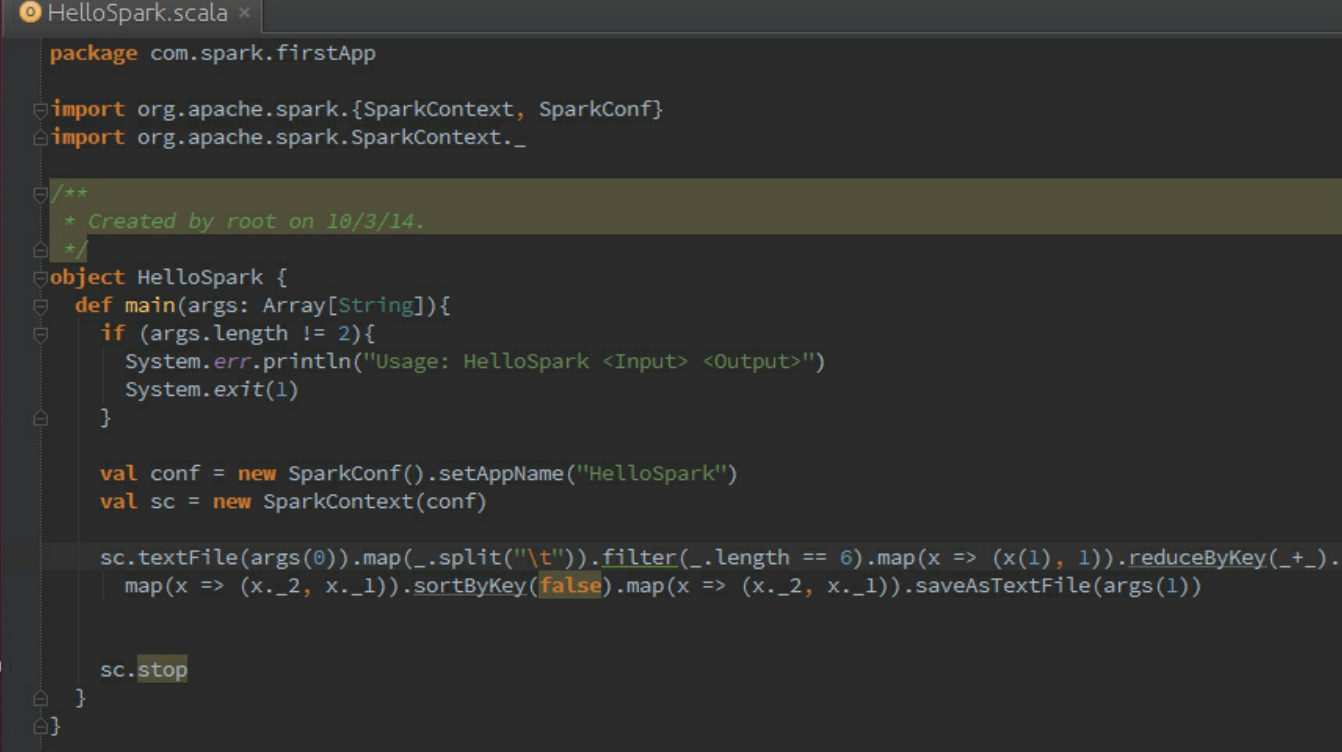
图3-62 构建Spark Driver的模板代码
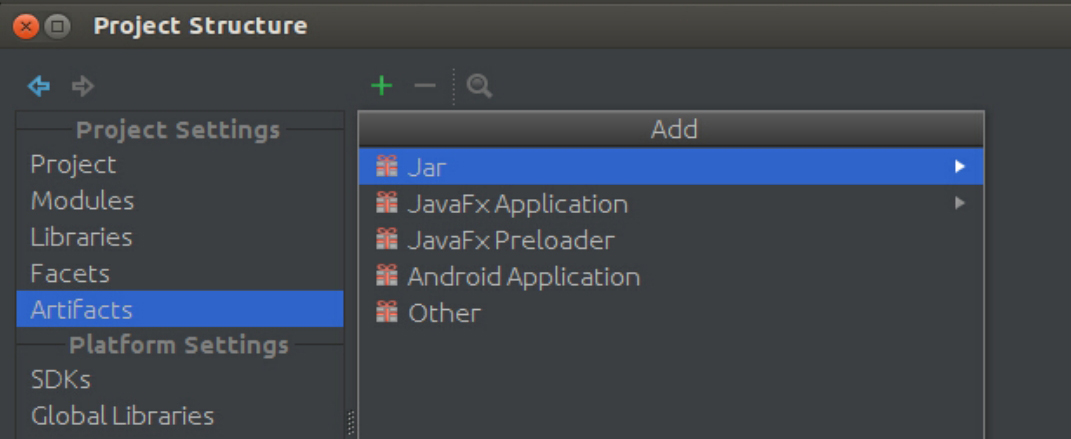
图3-63 打包
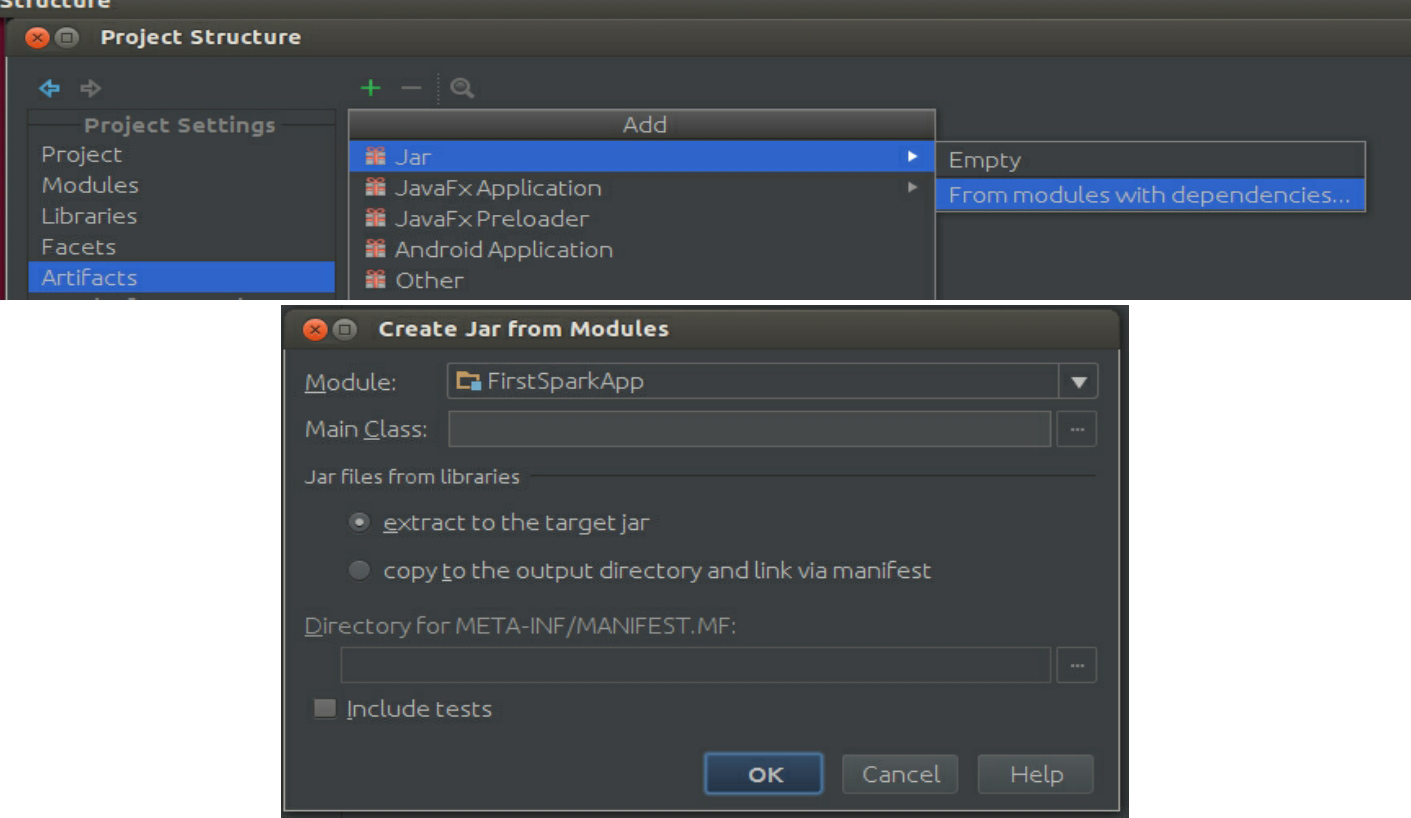
图3-64 From modules with dependencies
选择Main Class,Main Class是Jar文件中执行的入口函数所在的类:
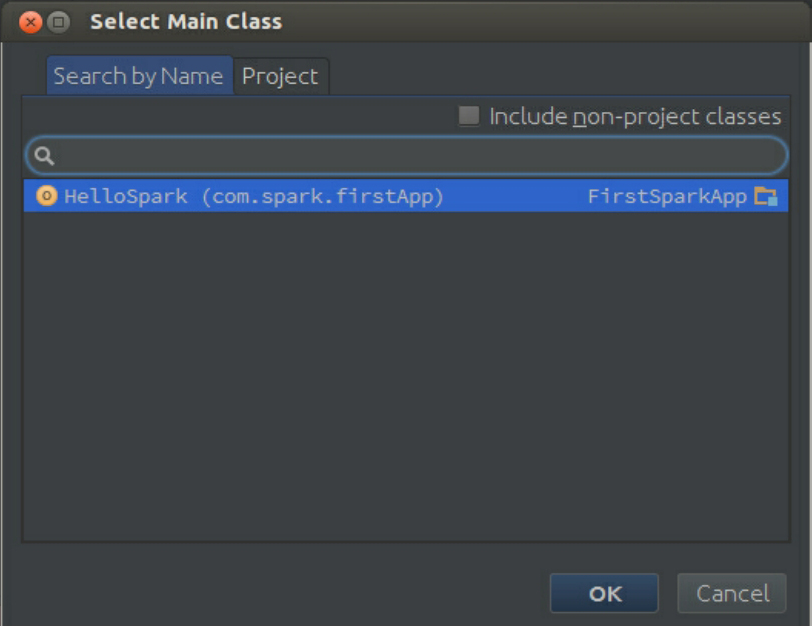
由于Main Class被设为HelloSpark,所以在此选择HelloSpark即可,其中他内容按照默认选项设置。
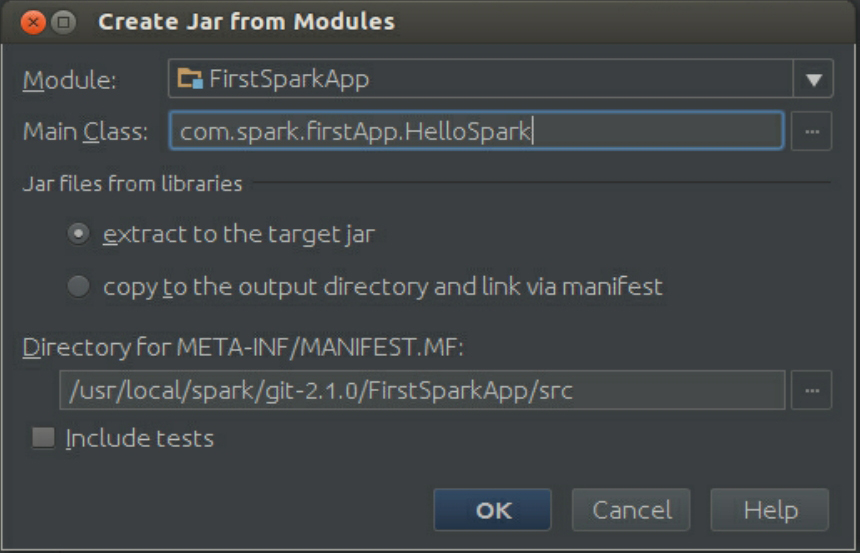
单点击“OK”按钮:
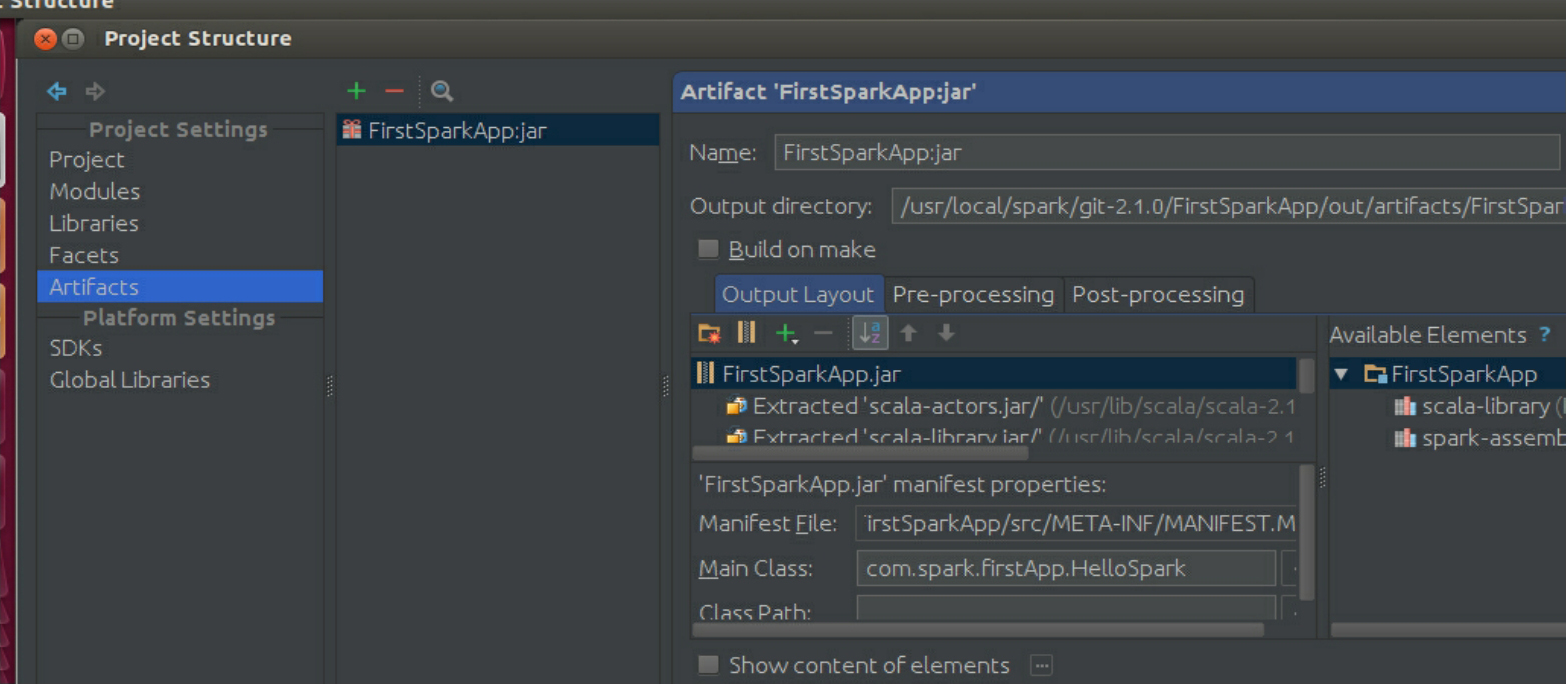
把名称改为FirstSparkAppJar:
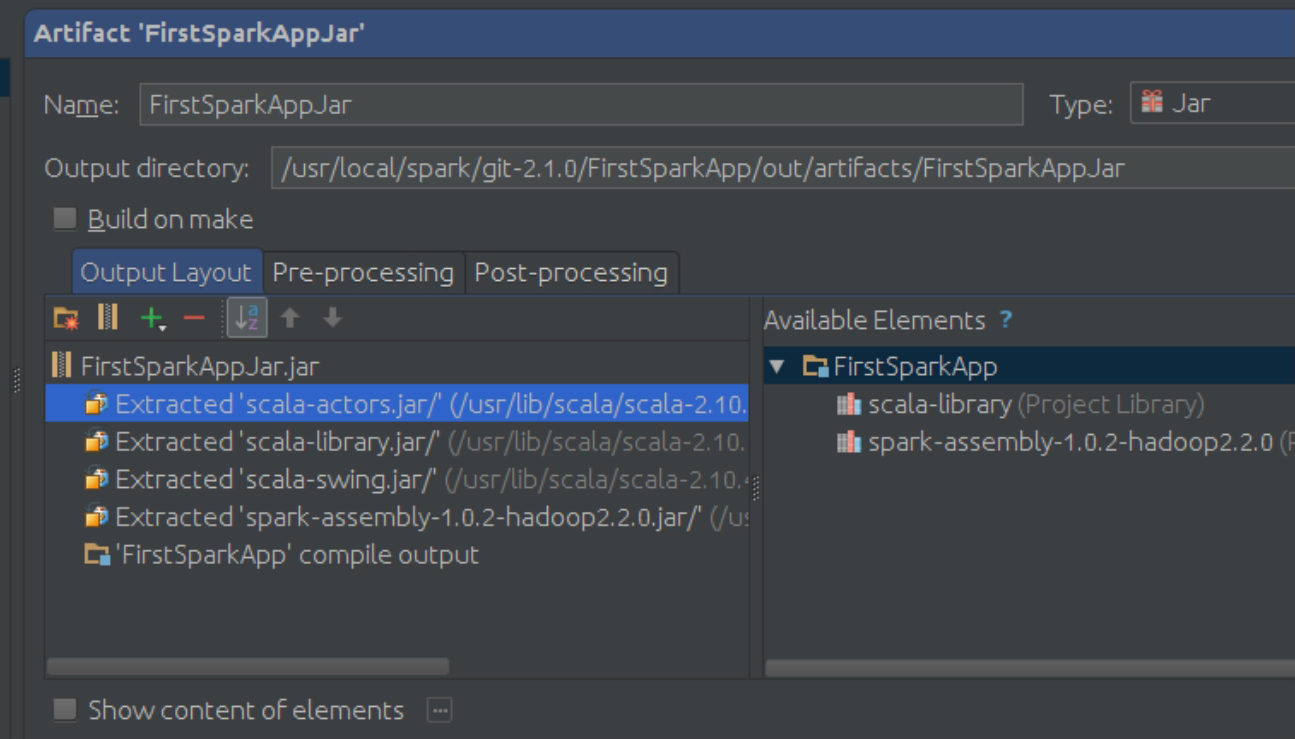
因为每台机器上都安装了Scala和Spark,所以可以把Scala和Spark相关的jar文件都删除掉:
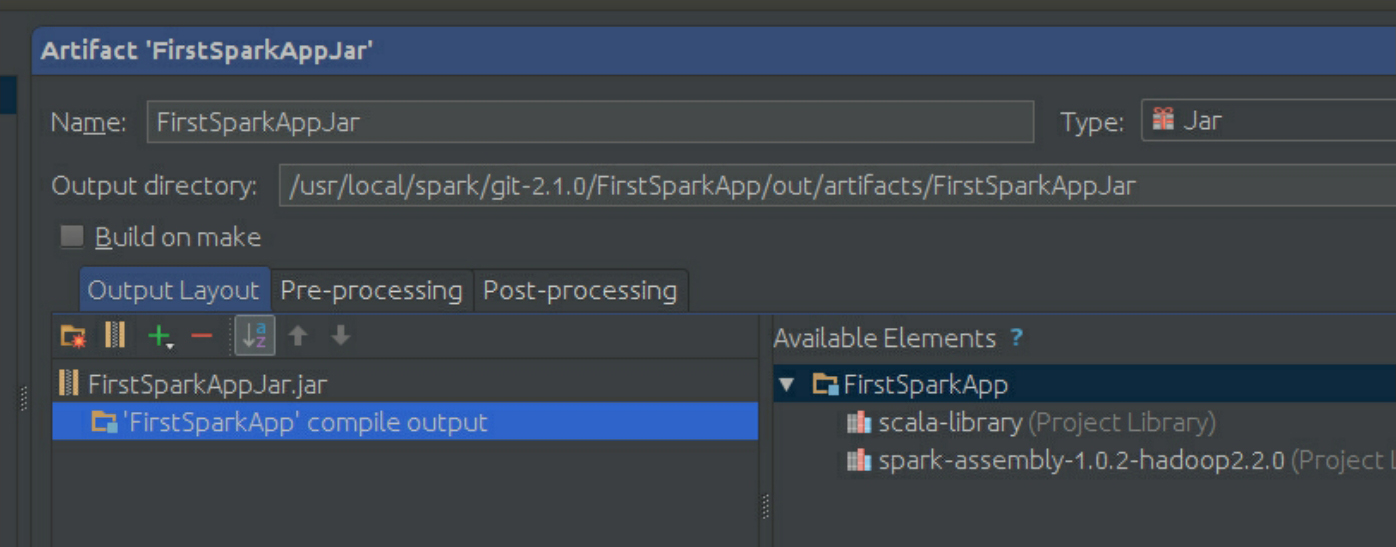
接下来进行Build:
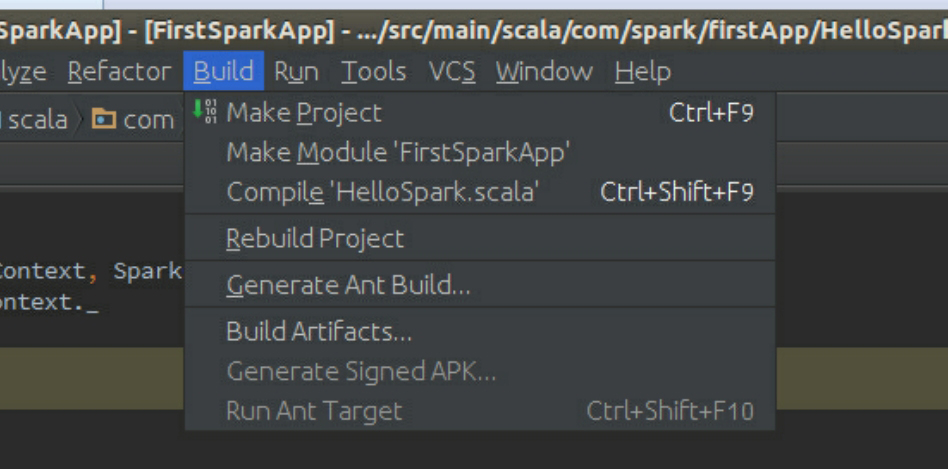
选择“Build Artifacts”:
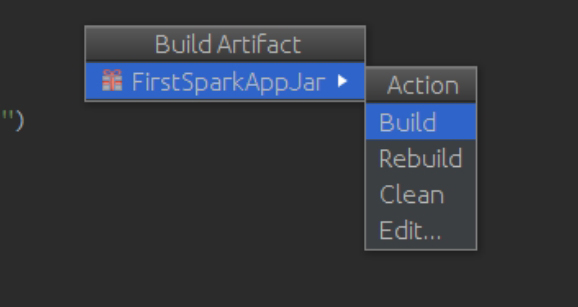
第一次是选择Build,以后同一个工程要选择Rebuild,然后等待编译完成:

进入其编译后目录查看编译完成的文件:

接下来使用spark-submit运行该程序:
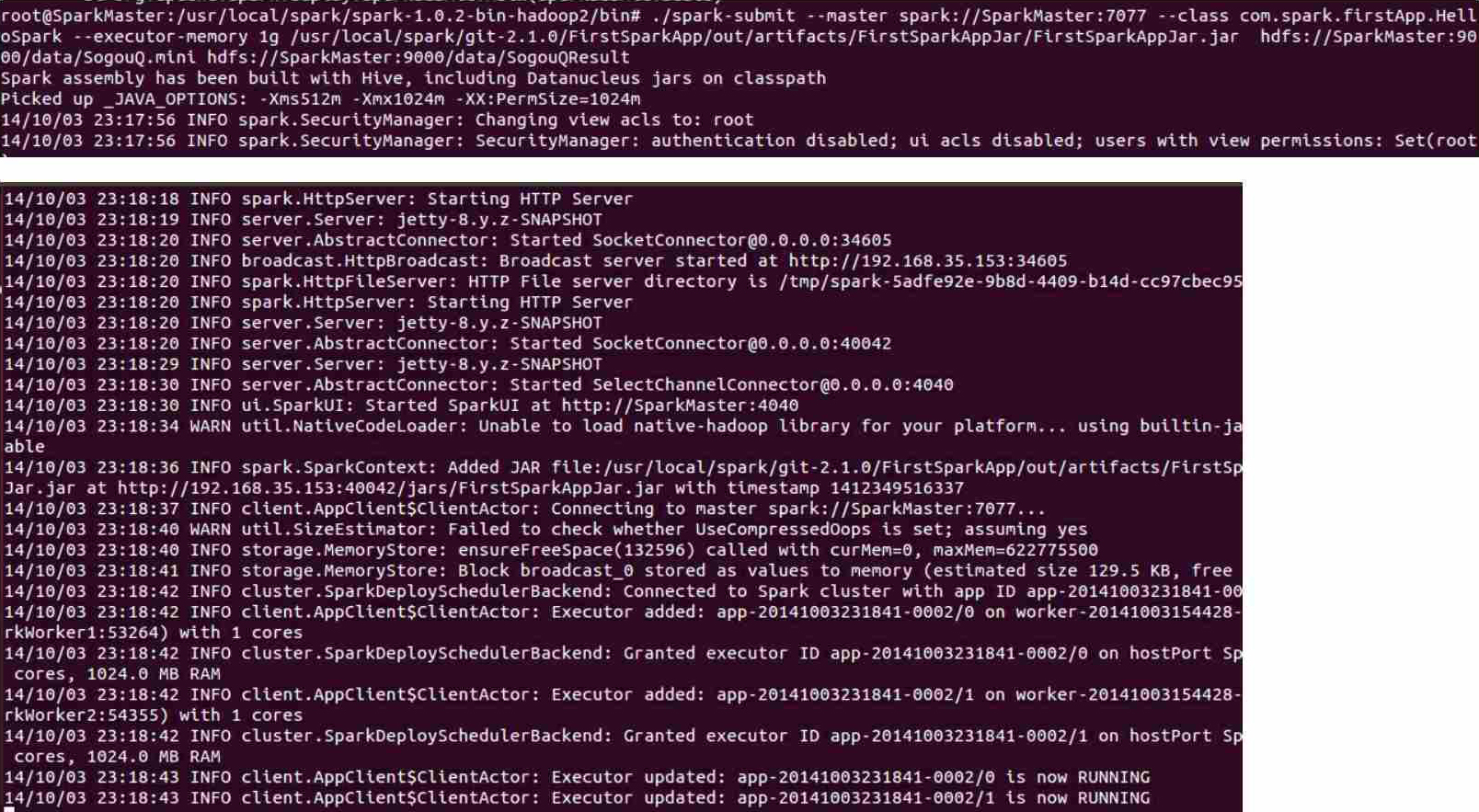
此时查看控制台:
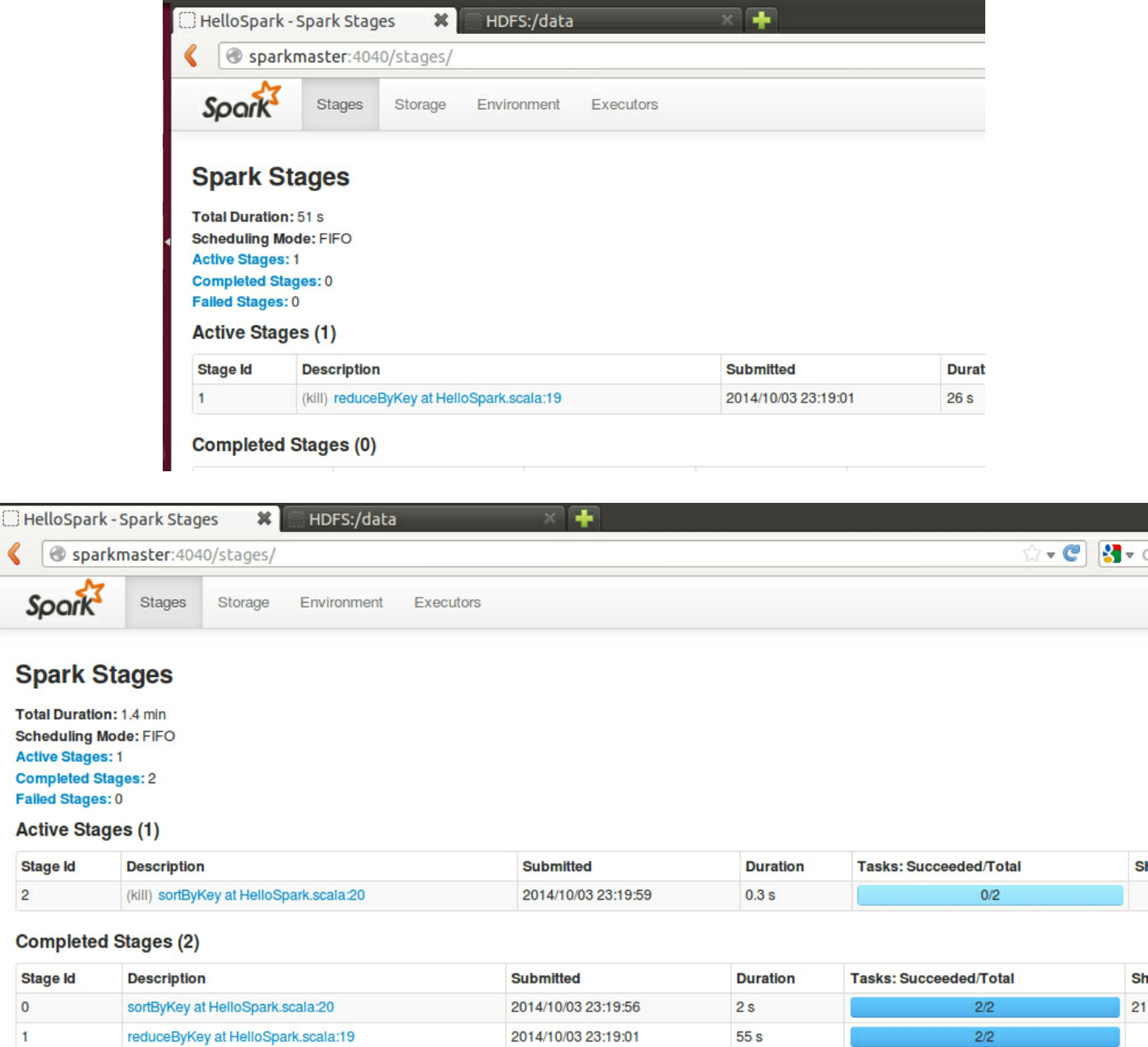
最后运行完成任务:
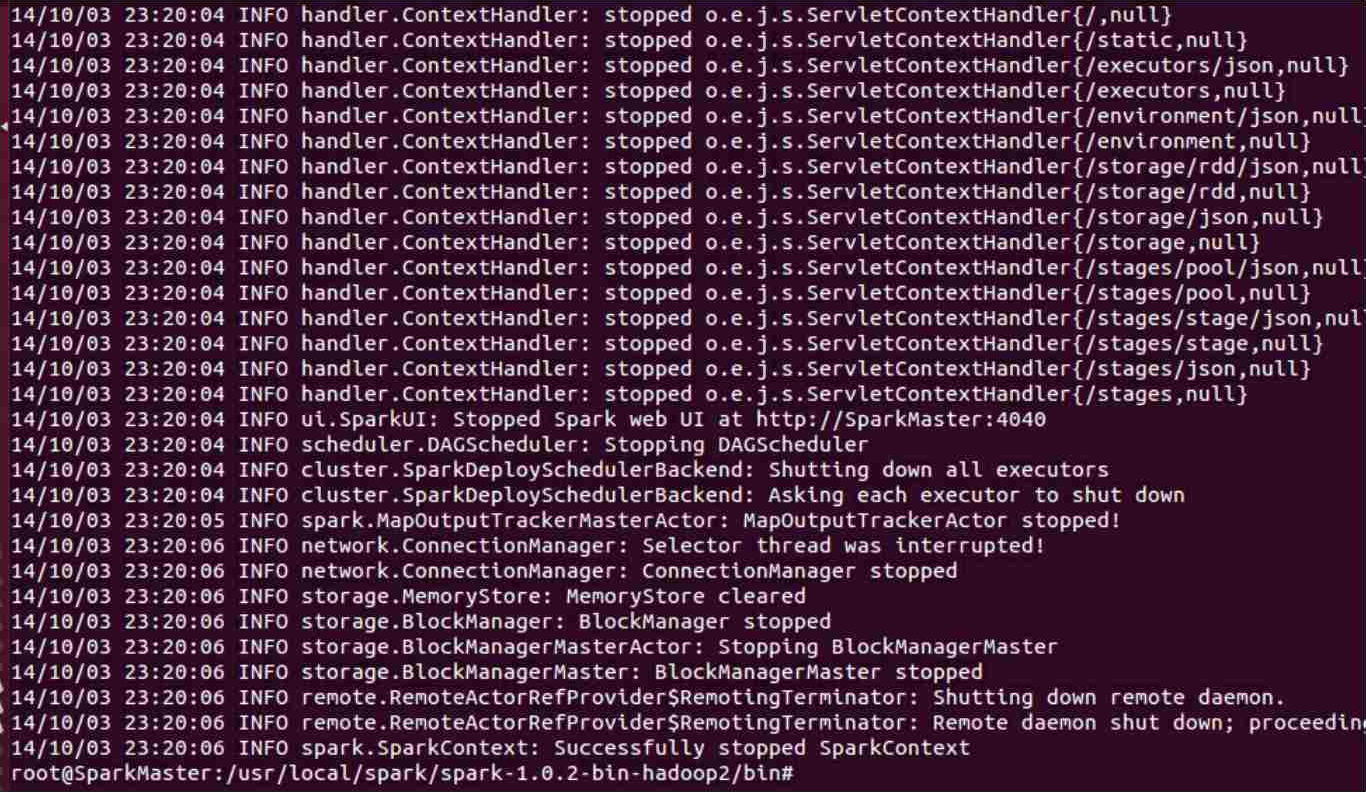
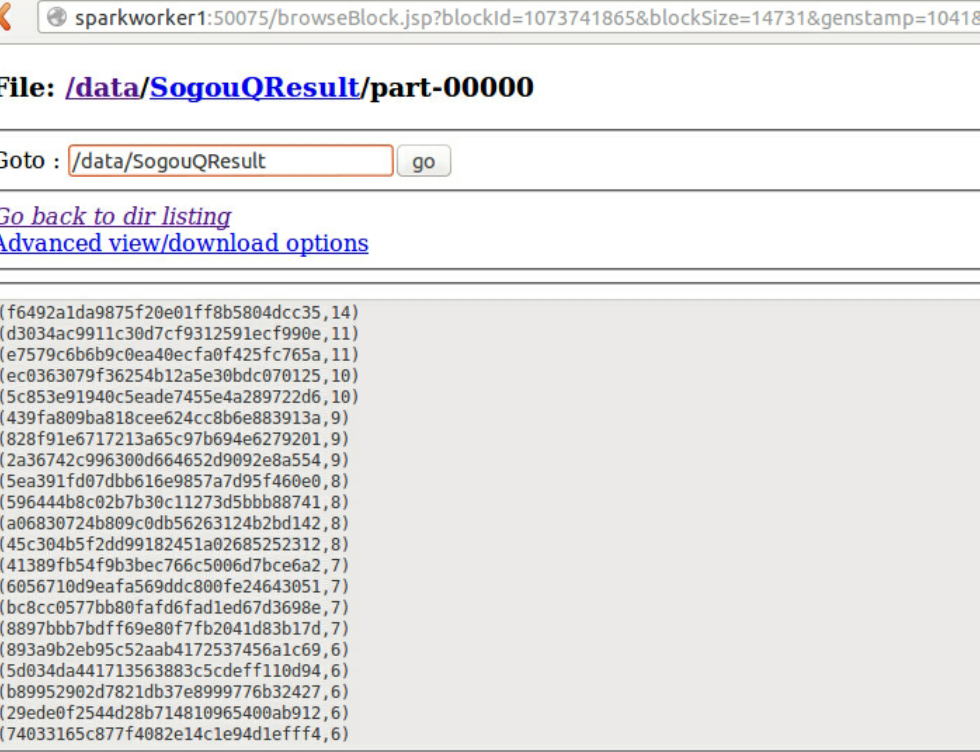
我们到HDFS控制台查看运行结果:
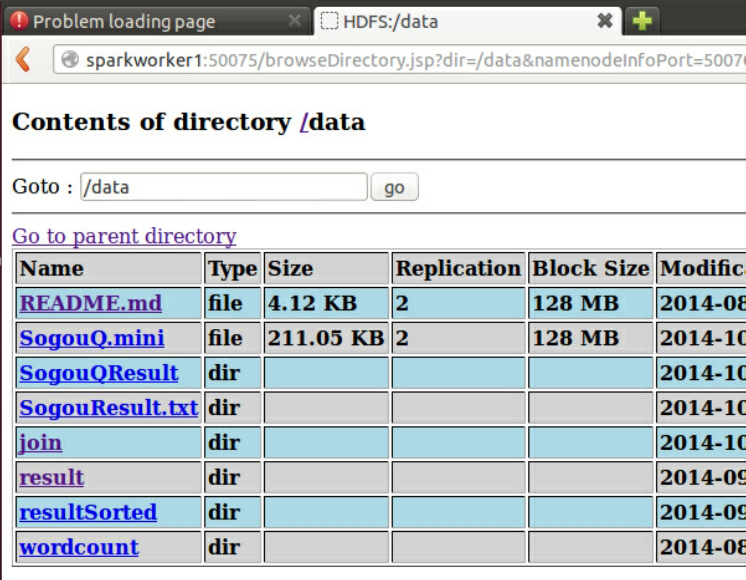
进入SogouQResult文件夹:
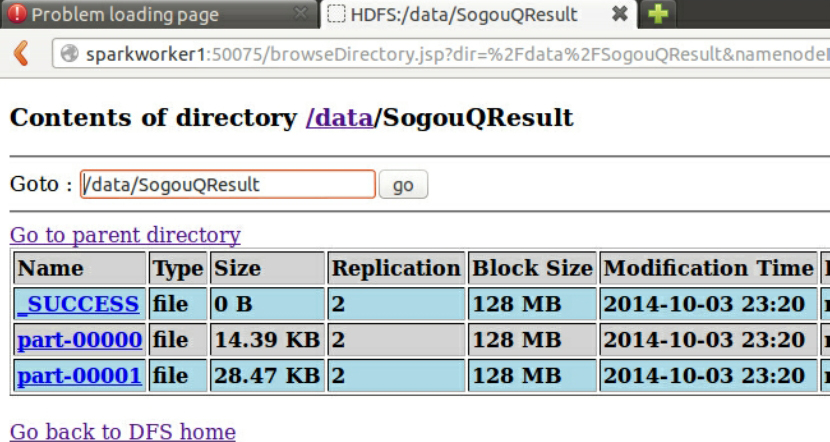
查看执行结果: