
下载掌阅APP,畅读海量书库
立即打开




总结一下到目前为止的争论:大数据既不是行业特有的,也不是一种特定的技术。它是由技术发展引起的一种文化现象的总称,这种文化现象已经形成了一个似乎没有尽头的循环,围绕这一术语的广泛宣传刺激了进一步的技术发展,这些发展反过来又助长了炒作。大数据的好坏取决于项目的背景和目标。但它永远不可能真正中立,因为总是有人决定如何处理数据和它产生的信息。此外,需要注意的是,大数据不一定涉及个人数据,而且它通常对个人用户不感兴趣。

由于前文的评论和定义的模糊性,了解大数据的实际情况非常重要,而非执着于讨论模糊和有争议术语本身的法律含义。因为不可能对“大数据”这样一个抽象的、多重解释面向的术语的影响或监管作出明确或概括的表述,这种探讨仍有必要从法律和规范的视角出发。通过将大数据视为一个流程,我们有可能发现问题是什么、这些问题在哪里出现、监管框架如何适用于这些问题,以及哪些法律工具最适合应对这些问题。从法律的角度来看,将大数据作为一个单一的概念来监管,忽视了大数据处理流程中存在许多单独的(法律)行为。这些行为催生了大相径庭的价值观和忧虑,需要截然不同的方法和解决方案。例如,大数据不能仅仅被视为一个可以通过数据保护立法来解决的概念,因为大数据可以在不需要收集个人数据的情况下影响人们的私人生活。
下文会将大数据划分为三个不同的阶段,从而将其用于规范和法律分析。
大数据流程的简单示意图如图2.1所示,将大数据分为获取、分析和应用三个阶段。
这幅示意图并不是对大数据在实践中如何运作的最终解释。它简化了复杂的迭代过程,将其划分为与大数据的法律维度具有特别关联性的几个阶段。第一阶段是收集数据的阶段。第二阶段即分析阶段,对获得的数据进行分析和处理,例如通过自主学习算法,
创建一个模型或大数据项目需要的知识。第三阶段是应用所收集知识的阶段。在前述大数据和信用评分的例子中,知识的应用是通过给申请贷款的个人分配一个特定的分数,从而作出提供贷款或拒绝申请的决定。在医疗方面,它意味着给某人一套个性化的治疗方案,或者在研究的基础上改变处方指南或药物说明。就线上个性化而言,它是指对个人收到的在线信息和选择进行个性化处理。然而,如前所述,在具体的流程中各个阶段可能有所重叠。例如,大数据通常包含一个响应新数据输入的自主学习算法。换句话说,大数据项目通常是连续的、非静态的流程,在这个流程中,某些行为可以被区分出来,并总结在三阶段模型中。下文将进一步解释这三个独立的阶段。
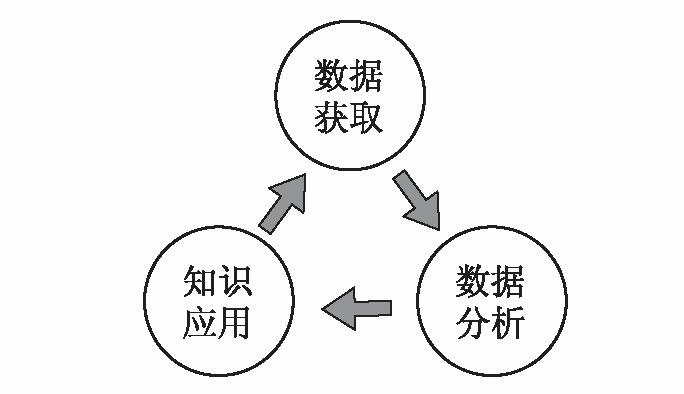
图2.1
获取阶段是运作大数据项目的个人、项目或组织获取数据的阶段。大数据项目的启动需要数据,但在整个进程中也会收集数据。在实践中,应用阶段在整个流程中重复出现或贯穿始终。大数据通常包括一个响应新数据输入的自主学习算法。数据可以直接从个人处收集,比如在信用评分或生物银行的实例中,个人被要求向公司或医生提供数据。数据还可以通过传感器收集,传感器不仅可以收集关于人的信息,还可以收集关于事物和过程的信息。另一种获取新数据的可能途径是从数据经纪人处购买数据,
数据经纪人是收集个人数据并将其出售给第三方的公司。
新数据并不总是从个人、传感器或中间商处获取。数据也可以从诸如网站(web抓取)之类的公共数据源中获取,或者通过现有数据源的组合进行创建。此外,可以根据现有数据进行推断和预测,这种推测和判断又构成新的(个人)数据。这将影响欧盟数据保护法律制度的适用性,我们将在第四章,特别是第四章第二节中进一步探讨。总之,获取阶段的特征是数据的积累并将其作为进一步分析的资源,数据系个人还是非个人(通常是两者的结合)则在所不问。
在第二阶段,对获得的数据进行分析。在这个阶段,数据要么仍然与个人相关,要么被匿名化处理。
如本章第二节所述,处理是借助于数据库管理和数据处理软件进行的。分析阶段在这项工作中得到了广泛的解释。它包括数据的储存和处理;为分析准备数据的预处理技术,以及数据挖掘和支持技术。这些方法是多种多样的,并在不断改进和调整。
[25]
在数据挖掘中,使用并创建了统计、机器学习和人工智能等领域的各种方法,目的是在大型数据集中发现有用的模式。
[26]
目前广泛使用的对数据进行分组和发现有用模式的技术是集群、分类和模式挖掘(如回归)。
[27]
在这些技术中,数据被用来创建假设,与传统的统计方法相反,例如,在收集和/或分析数据之前,社会科学以假设开始。
这使得它看起来客观、真实、中立,但大数据分析不止于此。假阳性和假阴性
的风险与传统统计数据相似,
[28]
而过度拟合(即误将巧合的模式误认为实际上具有普遍意义)的风险也特别高。
[29]
无论数据集的大小,用于分析的数据总是一个选择:数据永远不可能完全、决定性地重现真实世界。数据也可以反映已经存在的社会偏见,例如,基于性别或种族的歧视,这在本章第五节中有更详细的讨论(特别是第五节第二(三)部分)。
此外,数据的选择取决于其对数据组织的实效性和目标,其效果和代表性无法完全预测或事后评估。更重要的是,正如本章第一节第一部分和第二节所解释的那样,大数据分析产生的是关于相关性的信息,而不是关于因果关系的信息。两个变量或事件之间的联系可能纯粹是巧合;
相关性并不意味着因果关系。
[30]
在分析阶段,处理也可能导致数据的变化,例如,通过组合创建新数据的数据集,或者通过剥离标识符或聚合标识符,将它们转换为“匿名”数据。这对于欧盟隐私和数据保护法律框架的适用性和保护潜力非常重要,我们将在后面的章节中看到这一点。此外,重要的是要认识到,这种分析是对从获取阶段获得的数据进行的,并将影响应用阶段的人群。这是两类不同的人群,即使人们发现自己同时属于这两类人,但这两类人并不总是重叠的。
大数据分析最典型和最受赞赏的例子之一是谷歌流感趋势。2009年,谷歌的研究人员发表了一篇论文,解释了谷歌的算法如何能够预测流感疫情。
通过在谷歌搜索引擎中输入与流感相关的查询,从谷歌所保存的难以置信的大量数据中寻找规律,该公司的预测与美国最终的流感高峰相吻合。最初,人们甚至认为谷歌在预测流感方面比美国疾病控制与预防中心做得更好。
[31]
但所有的赞许在2013年戛然而止。谷歌的算法连续三年高估了流感的爆发,同时漏掉了一些主要的流感爆发,其中包括2009年的墨西哥猪流感。
[32]
谷歌基于查询的预测并不能准确反映实际流感爆发的原因有很多。
[33]
在其他搜索结果中,被选择的查询结果显示与冬天有很大的联系,而不是流感本身,而媒体对流感病例的广泛报道可能会影响搜索行为。
[34]
谷歌流感趋势从大数据的代言人变成了大数据出错的主要例证。它反复无常的预测表明,分析阶段是大数据的一个不稳定的环节。它是统计学、数据科学和算法,其结果取决于输入和选择。此外,输入的是数据,而数据总是对现实的简化部分的解释。数据与现实生活的匹配和对现实的影响应始终加以审视,特别是考虑到应用结果时分析所产生的影响,下文将对此进行解释。
[35]
在第三阶段,应用从数据分析中获得的信息,它们可能是知识、模型或预测。这可能形成通用的决定或针对个人的决定。例如,前者可以构成通过生物银行寻找疾病的风险因素,从而导致对医疗方案的新决策。使用数据作出针对个人的决策可能是通过自动化方法实现的,或者由个人或机构通过基于分析产生的知识作出决策。这些决策可以直接针对个人,但也有可能作出并不针对特定个体的通用决策。例如,由于通过大数据发现某些药品的效果有限,则不再将其列入处方药或医保目录。需要注意的是,这些决策基于多个来源的数据,而不仅仅是取自个人的数据。正如在分析阶段中所解释的,知识是通过汇集来自广泛来源的大型数据集而产生的。这是影响个人决策背后的知识。在大多数情况下,有关个人的有限数量的信息是得出结论和作为决策基础所必需的。在上述情况下,所作出的一般决策会影响到个人的私生活,甚至在不需要处理个人数据的情况下也会影响到私生活。
但是,当作出的决定是针对个人本身的时候,仍然主要是来自分析阶段的其他来源的数据,以及应用阶段的有限信息,决定了结果或决策。在行为定向中,通常只有IP地址、MAC地址或Cookie被用于根据浏览历史等信息向个人提供定向广告。定向基于得出的结论,例如,个人浏览历史中的特定网站,这些结论主要依赖于分析阶段其他人的历史数据。个人的姓名、地址和其他信息并不重要,通常也不会被收集。主要是来自他人的数据决定了针对个人的决策。综上所述,分析阶段的大量数据加上应用阶段的个人信息(通常很少),是大数据中刺激决策、预测和新信息的因素。对于规范和法律分析来说,应用形式的多样性,以及应用手段的多样性,即通用决定或针对个人的决定,不论是否使用大量个人数据,都是非常重要的。
大数据项目是一个复杂的流程。在本书中,根据实践情形以及规范和法律视角下的重要性,将大数据分为三个阶段。在获取阶段,大多数(个人)数据被收集。
在分析阶段,利用各种各样的技术从数据中提炼知识,对数据进行处理和分析。数据可能被修改或变动,从而实现去标识化,这对后面几章的法律分析非常重要。在应用阶段,个人数据可用于将分析阶段的结果应用于个人。虽然在这个阶段可能会收集个人数据,但知识和信息的主要来源并不总是或完全是来自个体的个人数据,而是来自其他来源的数据。这是大数据的一个关键方面,对随后的分析非常重要:获取阶段和分析阶段常常与应用阶段分离。
三个阶段的示意图显示大数据流程中出现了不同类型的数据处理,在某些阶段数据处理是关键,而在另一些阶段数据处理的意义不大。这已经暗示了在大数据中,不同的法律制度规制大数据流程的不同部分,不同的阶段需要关注不同的法律工具或解决方案。正如下节内容所示,每个阶段对个人权利和自由都有不同的影响。在随后的章节中,同样需要关注在每个阶段不同的行为,尤其对是否处理和如何处理(个人)数据,将影响欧盟隐私和数据保护法律制度的适用性,以及其他领域的法律在每个阶段保护个人权利和自由的重要性。这肯定了将大数据划分为不同阶段进行规范分析和法律分析的必要性和优势:大数据由不同的行为组成,不同的法律制度适用于不同的行为,不同的行为伴随着不同的风险。