
下载掌阅APP,畅读海量书库
立即打开



本节介绍的相关概念在后面的内容中会被多次提及,所以,读者最好花一些时间认真阅读并理解这些概念的含义,为以后的进阶学习夯实基础。本节主要介绍的概念有:数据库概念、数据表关系、数据库浏览、BI工具。
OLTP(On-Line Transaction Processing),即联机事务处理。在OLTP系统中,用户数据由前台被传送到计算应用程序中并在短时间内完成处理。举一个例子,某个顾客于2018年10月在超市买了1箱珠江啤酒,这笔交易记录会马上被从POS机传回超市的后台系统中。超市的销售记录中增加了1箱珠江啤酒,对应的珠江啤酒库存记录相应地减少了1箱,此信息也同时被传递到供应链系统中,从而影响超市下一次采购珠江啤酒的数量。这一系列活动就是OLTP机制。SAP ERP系统就是具有代表性的OLTP系统。
OLAP(On-Line Analytic Processing),即联机分析处理。其功能是从OLTP系统产生的海量业务数据中提取出对企业决策分析有用的信息并加以分析和利用。简单地概括,OLAP系统是对OLTP系统的分析,因为直接在OLTP系统中建立决策支持分析会使其性能大受影响,所以OLAP系统作为独立分析系统发展了起来。Power BI和Tableau 属于OLAP系统。
数据仓库(Data Warehouse)的主要功能是分析及整理数据。在ERP(企业资源计划)系统中,OLTP系统将产生大量数据资料。这些数据资料被读取到数据仓库中,并根据不同的分析方法(如OLAP、数据挖掘)的要求,对数据资料进行系统的清洗、归类,从而获得最终数据以搭建商业智能模型。
注意: 数据仓库中的数据资料通常是原始数据,有极强的参考意义和很长的使用寿命。因此,操作者应尽量避免对这些数据资料进行修改或删除。
ETL(Extract Transform Load)是数据仓库中重要的一环,可以被理解为数据准备或数据清洗。经过数据抽取和清理之后,在原有数据仓库的基础上,使用ETL系统对数据进行系统的加工、汇总和整理,使数据最终按照预先定义好的数据仓库模型进行准备。
数据集市(Data Mart)是企业级数据仓库的一个子集,主要面向部门级业务,或者某一特定业务主题,例如销售、物流。数据集市的出现解决了灵活性与工具性能之间的矛盾,可以被视为小型的部门级别的数据仓库。在数据集市中存储了为特定用户预先计算好的数据,既能满足用户对性能的需求,也不影响对数据的读取和调用。使用数据集市可以在一定程度上缓解数据仓库的访问压力。例如,当销售部门需要查询及分析数据时,可以单独通过数据仓库抽取到上一级的销售数据子集。
数据集(Data Set)是数据之间的集合,其结构类似关系型数据库——由公开表、行和列的分层对象模型构成。另外,它还包含了为数据集定义的约束和关系。Power BI/Tableau通过连接数据源读取数据集。
IT人员需要遵从一定的规范及要求,设计出合理的关系型数据库。这些规范及要求被称为范式,范式越高数据库冗余越小。
第一范式(1NF):在关系模型中,所有的域都应该是原子性的,即在数据库中表的每一列都是不可分割的原子数据项。举一个例子,名为“城市省份”的字段是一个可分割的数据项,包含该字段的数据表就不是第一范式。只有将该字段拆分成“城市”字段和“省份”字段后,原数据表才满足第一范式的要求。
第二范式(2NF):在关系模型中,要求实体的属性完全依赖于主关键字,不能仅依赖主关键字一部分的属性。第二范式构建在第一范式的基础上,各第二范式表之间的关系通过关键字联接。例如,在第二范式中,满足第一范式的所有与“客户”相关的字段需要被移到新创建的客户表中,客户表与销售表以客户ID联接。换言之,一张表只放一种类别的信息。
第三范式(3NF):在满足第二范式的前提下,非主键列必须直接依赖于主键。例如,数据表中不能存在地理信息依赖于客户ID的情况。客户信息中的城市、省份、国家等地理信息会被分离出来成为地理表。客户表与地理表通过地理ID关联。
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常,但这并不意味着不符合范式要求的设计一定是错误的。当数据库的表中存在1∶1或1∶N这种较特殊的关系时,表之间合并导致的不符合范式要求的数据表反而是合理的。例如,地理表不需要再被拆分成城市表、省份表、国家表等。
数据立方(Data Cube)是一种用于数据分析与索引的技术架构。运用数据立方可以对元数据进行任意多关键字的实时索引,能大大加快数据的查询和检索效率。
元(Meta)是希腊词根,译为“之上”,代表事物的抽象概念。元数据也被称为主数据,就是用以描述数据的数据。
专门存放元数据的表被称为元数据表或主数据表(Master Table)。例如,“彼得”在“某超市”消费了100元,所有双引号里的信息都是对100元的描述,为特指这100元的元数据。
100元额度的交易是一条事实(Fact)。数据模型中专门存放事实数据的表被称为事实表(Fact Table)。在购买啤酒的例子中,顾客购买记录将被存储于销售事实表中。
维度(Dimension)是同类型元数据的集合。比如对于顾客购买啤酒这件事,时间维度是2018年10月,啤酒品牌维度是珠江。维度表也是主数据表。
度量(Measure)是衡量数据的计算,可以将其想象为一把尺子。假设超市需要查找年度购买啤酒金额超过1000元的顾客,并将其作为优质顾客来发展,相应的计算公式就是一种度量。
主关键字(Primary Key,也叫作主键)是表中的一个或多个字段,其值被用于唯一标识表中的某一条记录。在表关系中,主关键字用来从一个表中引用来自另一个表的特定记录。一个表的主键可以由多个关键字组成,比如这个顾客是某超市的会员,他的会员ID在会员表中是唯一的值,所以可以作为会员事实表的主键。但在销售事实表中,会员ID是可重复值,所以此时会员ID只能作为外关键字(Foreign Key,也叫作外键)。
关系(Relationship)是指表与表之间数据联接的关系,分为1∶1、1∶N、N∶M三种。
●1∶1可理解为公民与身份证号的关系,一个人只有一个身份证号,不重复。
●1∶N可理解为省份与城市的关系,一个省份有N个城市。
●N∶M可理解为病人与医生的关系,一个病人可以找多个医生看病,一个医生可以为多个病人看病。在处理多对多关系的查询时,往往需要添加中间表作为过渡。例如,可以添加挂号表作为病人信息表与医生信息表的中间表。
会员表与销售事实表之间的关系是1∶N,因此“1”端的会员表被称为1表(One Table)、父表或主表,多端(N端)的销售事实表被称为多表(Many Table)、子表或从表。
主键约束(Primary Key Constraint)使表中只能定义一个主键来确定每一行数据的标识符。主键约束确保了会员表中不会出现重复的会员ID。
为了防止不符合规范的数据进入数据库,在用户对数据进行插入、修改、删除等操作时,系统会自动按照一定的约束条件对更改后的数据进行监测,以确保数据库中存储的数据是正确、有效、相容的。这种提前设定好的约束条件被称为数据完整性约束(Data Integration Constraint)。由于它的存在,销售事实表中不能出现任何不存在于客户表中的客户ID,否则客户表与销售事实表将无法建立关系。
联接(Join)是基于这些表之间的共同字段(主键与外键),把来自两个或多个表的行结合起来。联接分为4种类型(见图1.5.1)。
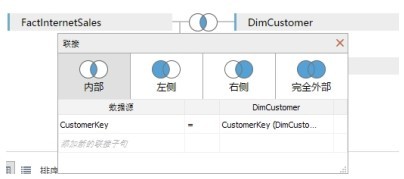
图 1.5.1
●内部联接(Inner Join):二表相交的数据行。
●左侧联接(Left Join):左表的集合,右表则只陈列与左表相关的数据行。
●右侧联接(Right Join):右表的集合,左表则只陈列与右表相关的数据行。
●完全外部联接(Outer Join):左表和右表共同的集合,无相交的记录另一侧以空值显示。
并集(Union)是指将不同的表合并成一张表的过程。例如,某超市的2017年各月度销售表可以被合并成一张2017年年度销售表。
在传统的Excel分析中,业务人员常常在销售事实表中使用VLOOKUP函数引用来自其他维度表的字段,例如引用其他维度表中的商品名称、销售区域,如图1.5.2所示。其中所使用的引用表被称为大表。大表的优势在于为少量数据的分析带来便利,劣势在于难以维护复杂的VLOOKUP函数引用,一旦行列错位则可能会导致公式错误。而且随着数据量的增加,查询性能变差,甚至会导致Excel崩溃。大表模式属于数据库第一范式。
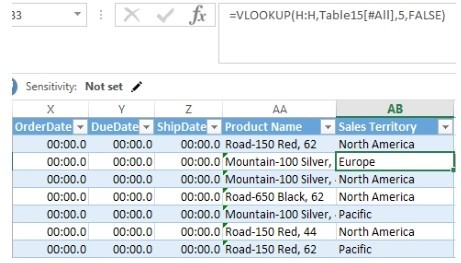
图 1.5.2
星型模式(Star Schema)也被称为数据立方体或多维模式,是数据仓库模型中最简单的样式。星型模式下的所有维度表都与事实表发生直接关联,属于数据库第二范式,如图1.5.3所示。
雪花模式(Snowflake Schema)属于高级星型模式,其中的维度表可以作为另一个维度表的延伸,而不直接与事实表发生关联,其形态颇像雪花,故得名“雪花”,如图1.5.4所示。雪花模式属于数据库第三范式。
形状复杂、有多层级的雪花模式又被形象地称为暴雪模式,此类模式灵活性最好。一般而言,业务人员只要掌握大表和星型模式,就能满足日常大部分的分析场景。
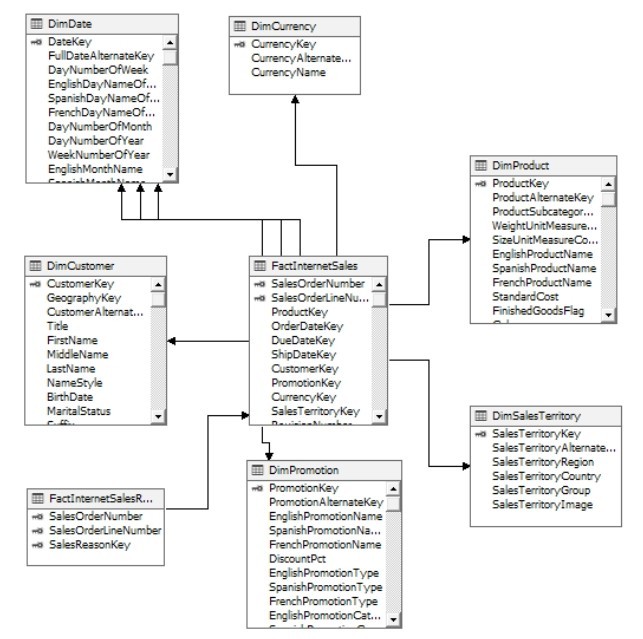
图 1.5.3
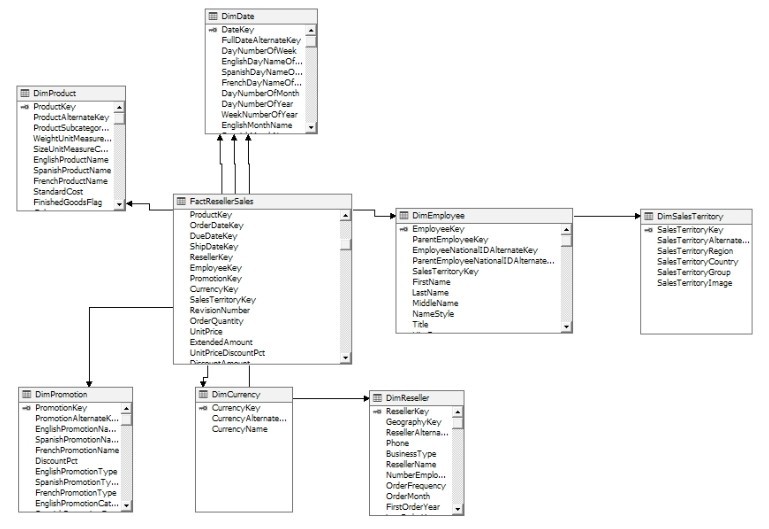
图 1.5.4
数据切片和切块(Slice and Dice)是指将整体的数据切成更小的数据切片或切块,以利于更加具体的分析。
举个通俗易懂的例子,假设现在有一张显示某超市全国销售额的报表,超市总经理需要查看每个省份的销售额。提取每个省份的销售额的过程就是向下钻取(Drill Down),向上钻取(Roll Up)则为相反方向的操作。
横向钻取(Drill Across)发生在两个及两个以上的事实表之间。例如,销售任务额度表和销售事实表是两张彼此独立的事实表,通过横向钻取,可以在一张表里同时呈现销售人员的销售任务额度及其销售金额。
钻透(Drill Through)指通过一张表中已有的筛选设置向下钻取另外一张表。其通常的用法是,先在汇总表中进行筛选,然后将汇总表作为筛选条件钻透明细表做特定的查询分析。例如,汇总表中显示了按颜色分类的服装销售总额,明细表按颜色、尺寸、服装款式显示销售额。分析人员可以在汇总表中选择红色作为筛选条件,再钻透至明细表,读取红色服装的销售额。
数据聚合(Aggregation)是合并数据集的过程。例如,将万佳集团旗下各公司的销售额从不同数据集中进行汇总就是一种数据聚合的过程。从某种意义上说,任何度量计算,如平均数、中位数、标准方差等,其计算过程都要经过数据集的聚合才能完成。数据聚合度越高,其数据的维度就越少,但并非所有数据都可以聚合,例如一个员工每年的工资,这样的数据不可以直接聚合。
数据粒度(Granularity)描述的是仓库中数据的细化程度。细化程度越高,粒度越小;细化程度越低,粒度越大。
离散型(Discrete)数据是指数值只能以自然数或整数为单位进行计算,一般用计数的方法取得。例如,日期中的月份数为离散型数据。
连续型(Continuous)数据包含若干位小数,在一定区间内可以任意取值,其数值连续不断且相邻的两个数值可以进行无限分割。连续型数据的数值一般使用测量的方法取得。例如,万佳超市的占地规模、学生的身高和体重等都属于连续型数据。
值得注意的是,连续型数据和离散型数据可以互相转换,例如学生身高,当求平均数时为连续型数据,当求身高区间时为离散型数据。
总结:连续型数据属于定量数据,作为度量使用;离散型数据属于定性数据,作为维度使用。
SQL(Structured Query Language),即结构化查询语言,是一种数据库查询和程序设计语言,常被用于存取数据,以及查询、更新和管理关系数据库系统。标准SQL语言可以用于具有不同底层结构的不同数据库系统,这使它既有极大的灵活性,也拥有强大的功能。本书中的SQL产品是指微软SQL产品。
SSAS(SQL Server Analysis Services),即SQL分析服务,是微软研发的构建于SQL服务器之上的一种联机分析处理(OLAP)和数据挖掘工具,主要用于跨平台的数据分析。因为SSAS被封装在SQL服务器之上,其数据分析功能比SQL本身更加优化和简洁。SSAS有两种运行模式,多维模式(也称MDX)和表格模式(也称DAX)。注意,这两种模式不可以兼容使用,一个SQL服务器实体只能安装其中的一种模式。后文将介绍Analysis Services与Power BI/Tableau结合应用的实例。
DAX默认使用内存数据库访问数据模型,运行时整个模型都会被加载到内存中,从而增加计算速度,但其性能在很大程度上取决于服务器的内存空间。总的来讲,在实际中,DAX非常适合中小型数据库;MDX则更适合大型数据库,例如具有几个TB的数据库,一般规模的服务器很难有相匹配的内存配置。
MDX(Multidimensional Data Expression,模式多维数据表达式)是SSAS多维模式的表达式。Power BI不能直接使用MDX,但可以通过SSAS模式连接支持MDX。DAX(Data Analysis Expression,数据分析表达式)是SSAS表格模式的表达式。Power BI直接支持DAX,也支持通过SSAS使用DAX。
Power Query、Power Pivot和Power View被统称为Power系列“三剑客”,其功能分别对应数据准备、数据建模和数据展示(见图1.5.5)。在Excel 2013中它们是三个独立的部件,需要加载到Excel里使用,在Excel 2016之后的版本中,Power Query已经被融入Excel中,不独立存在。Power BI就是这“三剑客”的组合,一个具有完整数据挖掘功能的工具。对于没有太多基础知识的用户,一般将其解释为“Power BI技术”足矣,没有必要延伸具体的细节,以免产生困惑。

图 1.5.5
1.6节会介绍Adventure Works 数据库,后文介绍的商业智能报表都围绕此数据库创建,因此了解此数据库的结构非常必要。