下载掌阅APP,畅读海量书库
立即打开



显然上面这篇博文运用了对比视角:图3-1通过对比,发现日访问量有波动;图3-4通过对比,知道原创博文比转载博文的访问量高;表3-1通过对比,看出还是名博推荐效果好。
凡事都是相对的,骑自行车比走路速度快,但与汽车相比速度则是慢的,参照物不同,则结论不同。因此,对比分析实际上是基于参照物得出的一种相对关系。
1.按照参照物:纵向对比与横向对比
按照所选参照物的不同,对比分为纵向对比与横向对比。
你可以和自己纵向对比,对比过去和现在,总结自己的发展变化,形成时间序列。
你可以和别人横向对比,对比各自表现,判断自己的优势和劣势,形成截面数据。
在上面这篇博文中,图3-1对比的是自己每天的访问量,为纵向对比;而表3-1把自己和其他博客进行对比,为横向对比。
企业会大量使用对比分析来支持运营决策。以业绩对比为例,通过纵向对比自己各年的业绩,进行规模预测;通过横向对比各部门的业绩,进行各部门考核;通过纵向对比营销活动前后的业绩,评估活动效果;通过横向对比自己和竞争者的业绩,判断市场地位。
2.按照对比指标性质:频数统计与均值分析
按照对比指标性质的不同,对比分为频数统计与均值分析。
例如,假设某调研列举出购买彩电的多种考虑因素,让受访者从中选出最关注的因素(见Q1题),则受访者的选择就构成分类型数据(每个选择是一类因素)。
Q1.您在购买彩电时,最关注下列哪种因素?【单选】
A外观 B功能 C耗电量 D价格 E品牌 F其他__________【请注明】
如果让受访者根据自己的考虑程度,对各因素打分(见Q2题),受访者给出的分数就构成数值型数据(每个分数是一个数值)。
Q2.您在购买彩电时,对下列因素的考虑程度如何?1~7分,分值越高表示越重视。

续表

分类型数据,运用频数统计(统计各因素被选的人数占比)进行对比;而数值型数据,运用均值分析(统计各因素的平均分值)进行对比(见图3-5)。
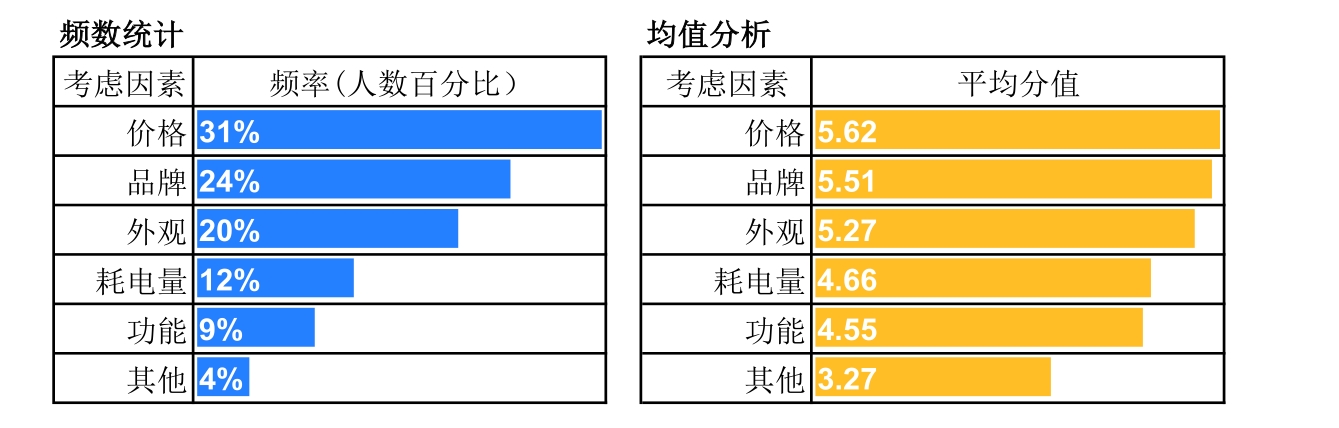
图3-5 频数统计与均值分析
在使用对比分析时,要注意对比的可信度。因为我们身边充斥着大量不具有可比性的对比分析。具体表现为时间上的不可比、空间上的不可比和数量关系上的不可比。
1.时间上的可比性
例如,某零售企业想计算2018年3月前10天的销量比2017年同期增长了多少。从表面上看,这两个数据的时间跨度一致,可以对比。但实际上,零售业每周具有明显的淡旺季之分:在一周之内,工作日为淡季;周六和周日为旺季。
翻开日历,你会发现2018年3月前10天比2017年同期多一个“星期六”,这个多出的“星期六”必然会抬高2018年3月的销量,造成对比结果的失真。所以,零售业的对比周期通常为周。这个例子说明,对比的对象在时间分布上要有可比性。
2.空间上的可比性
在美国和西班牙交战期间,美国海军的死亡率是9‰,美国居民的死亡率是16‰。于是,美国海军在征兵时就对比这两个数据证明参军更安全。但事实上,这两个数据不可比—海军死亡率的统计对象都是身强力壮的年轻人,居民死亡率的统计对象除年轻人以外,还有老人和小孩,而老人和小孩的自然死亡率要比年轻人高得多,这会把居民死亡率抬高。
统计口径的不同造成“参军更安全”这个错误的结论。正确的做法应是对比同样年龄段的海军和居民的死亡率。这个例子说明,对比的对象在空间(即外延)上要有可比性。
3.数量上的可比性
在数量上具有可比性有两层含义:
第一,对比指标要定量。
第二,对比对象要同量纲。
如何理解对比指标要定量?
定量是相对定性而言的。如果你说这个人真“高”,这是对身高指标的定性描述;如果你说这个人身高“2米”,这是对身高指标的定量描述。
要有效对比,指标需要定量。例如,假设你对某企业是否应该做跨境电商进行SWOT分析,列举出跨镜电商的机会有8个、威胁有6个,该企业做跨境电商的优势有9个、劣势有8个,那么你能否得出机会>威胁、优势>劣势,所以该企业应该做跨境电商的结论呢?
不能!因为每个机会和威胁的重要性和表现水平不同;同样,每个优势和劣势的重要性和表现水平也不同。SWOT分析是定性研究,只能用于战略梳理,不能用于战略选择。做战略选择就要定量,对SWOT分析中的机会、威胁、优势、劣势进行量化,根据最终量化的分值做出战略决策。这种对SWOT分析的量化方法叫作内外因素评价矩阵(具体操作见第4章)。
如何理解对比对象要同量纲?下面通过两个案例来说明。
某公司员工的月平均工资水平为5000元,标准差为800元;该公司员工的平均工龄为20年,标准差为5年。请比较该公司员工工资与工龄哪个差异更大?
该案例有两个指标:平均数()和标准差( σ )。对平均数我们并不陌生,那标准差是什么?
以工资为例,平均工资水平刻画的是所有员工工资的一般水平;而工资标准差则刻画的是各员工之间的工资差异。
于是,你会说,既然标准差用于刻画差异,那么直接比较员工工资和工龄的标准差就好了!

但是工资的标准差是800元,工龄的标准差是5年,单位都不统一,怎么对比?
单位不统一,这是量纲不同的一个表现。既然单位不统一,影响对比,那么就剔除单位吧!
如何剔除?计算变异系数 V 。
变异系数 V = σ /,刻画的是单位平均水平下的差异。由于 σ 和的单位相同(例如平均工龄和工龄标准差的单位都是“年”),两者做除法就剔除了单位,从而具有了可比性。工资的变异系数 V 1 =800/5000=16%,工龄的变异系数 V 2 =5/20=25%,于是,可以得出该公司员工的工龄差异大于工资差异的结论。
量纲不同,还表现为分类维度间的数量差异。我们来看案例2。
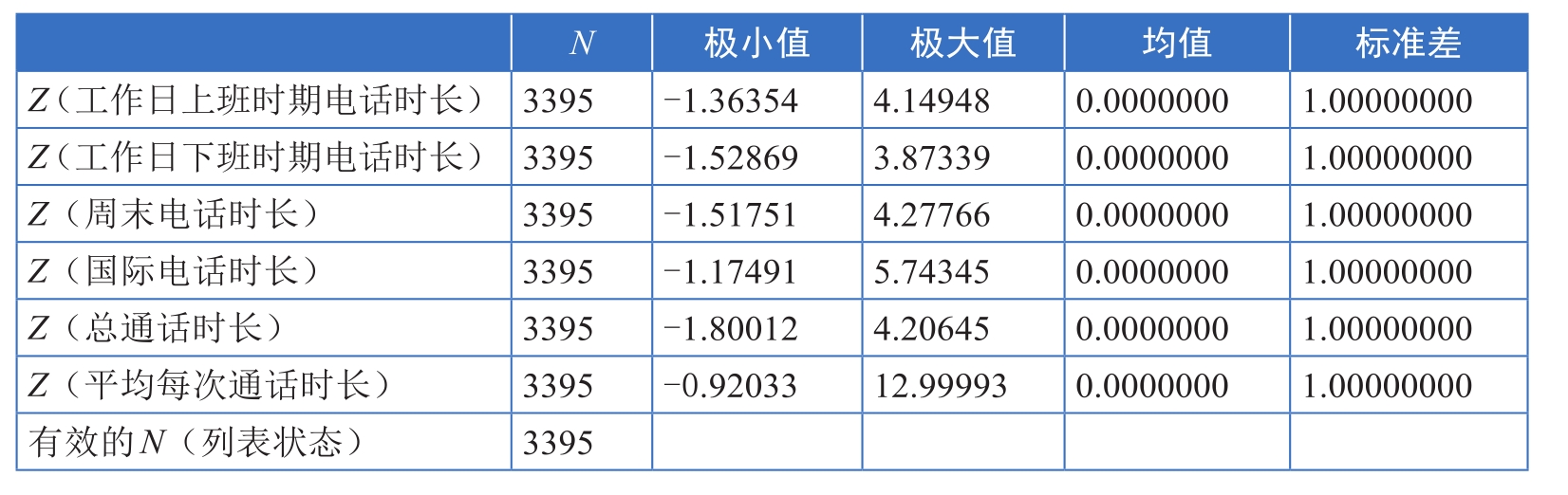
某运营商想对手机用户进行分类,为此其调查了3395个手机用户在各种场景中的通话时长:工作日上班时期电话时长、工作日下班时期电话时长、周末电话时长、国际电话时长、总通话时长和平均每次通话时长。通过描述统计,得到它们的数据特征(见图3-6)。请问能否直接以这6个变量为维度,对手机用户进行分类?
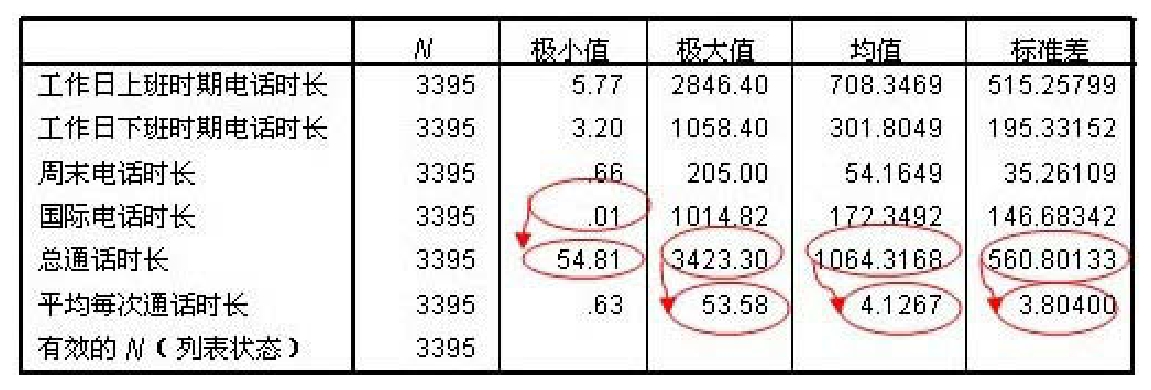
图3-6 各类通话时长描述统计输出结果
从图3-6可以看出,这6个变量的数量差异很大。以均值为例,平均每次通话时长的均值为4.1267分钟/月,而总通话时长的均值为1064.3168分钟/月,是平均每次通话时长均值的200多倍。该如何理解这种数量差异呢?
总通话时长=平均每次通话时长×通话次数。一年有上百次通话,当然总通话时长要高很多。所以,平均每次通话时长与总通话时长的数量差异是客观现实。
但问题是,现在对手机用户进行分类,依据是各个手机用户距离的远近,而距离远近要用这些变量的数量特征进行刻画,数量太小的变量对分类结果的影响就会很小。比如,对比其他变量,平均每次通话时长的均值太小,它对手机用户分类的影响微乎其微。但事实上,不同人的平均每次通话时长是不一样的,比如闺蜜间或情侣间常常爱“煲电话粥”,而男性或同事之间的通话时间则会短些。平均每次通话时长实际上是影响用户分类的。因此,若直接用这6个变量对手机用户进行分类,就会由于各变量在数量上的不可比造成分类结果的偏差。
因此需要剔除这6个变量的数量差异,使之在数量上具有可比性。那如何剔除呢?
如果你学过统计学就会知道,描述事物数量特征的指标有两个:反映一般水平的均值和反映变异水平的标准差。因此,要剔除数量差异,就要使各个变量的均值相等且标准差相等。如何实现呢?通过对变量的标准化来实现。
标准化的计算公式为:
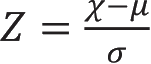 ,其中
Z
为标准化结果,
χ
为观察值,
μ
为平均值,
σ
为标准差。
,其中
Z
为标准化结果,
χ
为观察值,
μ
为平均值,
σ
为标准差。
本例6个变量的标准化结果为如图3-7所示的红框数据。
图3-7 6个变量的标准化结果(部分数据)
通过标准化,各变量的均值均为0,标准差均为1(见表3-2),从而消除了各变量的数量差异,实现了各变量在数量上的统一和可比。
表3-2 描述统计量