
下载掌阅APP,畅读海量书库
立即打开



分类(Classification)是一种重要的数据分析形式,它提取刻画重要数据类的模型。这种模型称为分类器,预测分类的(离散的、无序的)类标号。这些类别可以用离散值表示,其中值之间的次序没有意义。
分类可描述如下:从训练数据中确定函数模型y= f(x 1 ,x 2 ,…,x d ),其中x i (i=1,2,…,d)为特征变量,y为分类变量。当y为离散变量时,即dom(y)={y 1 ,y 2 ,…,y m ),被称为分类。
分类也可用如下定义。
分类的任务就是通过学习得到一个目标函数(Target Function)f,把每个属性集x映射到一个预先定义的类标号y中。
数据分类过程有两个阶段:
(1)学习阶段(构建分类模型)。
(2)分类阶段(使用模型预测给定数据的类标号)。
第一阶段,建立描述预先定义的数据类或概念集的分类器。这是学习阶段,其中分类算法通过分析或从训练集“学习”来构造分类器。训练集由数据库元组和与它们相关联的类标号组成。构成训练集的元组称为训练元组。
第二阶段,使用模型进行分类。首先评估分类器的预测准确率。如果使用训练集来度量分类器的准确率,则评估可能是乐观的,因为分类器趋向于过分拟合该数据。因此需要使用由检验元组和与它们相关联的类标号组成的检验集。它们独立于训练元组,即不用它们构造分类器。分类器在给定检验集上的准确率是分类器正确分类的检验元组所占的百分比。如果认为分类器的准确率是可以接受的,那么就可以用它对类标号未知的数据元组进行分类。图3-1展示了建立分类模型的一般方法。
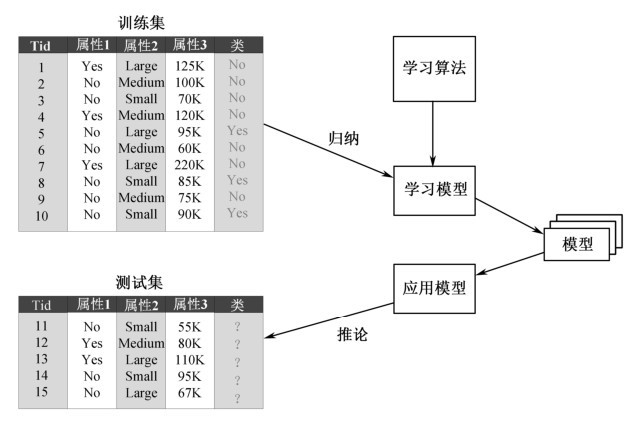
图3-1 建立分类模型的一般方法
一般方法是,首先需要一个训练集(Training Set),它由类标号已知的记录(Recorder)组成。使用训练集建立分类模型,该模型随后将运用于测试集(Test Set),测试集由类标号未知的记录组成 [1] 。
分类器的性能和所选择的训练集和测试集有着直接关系。一般情况下,先用一部分数据建立模型,然后再用剩下的数据来测试和验证这个得到的模型。如果使用相同的训练集和测试集,那么模型的准确度就很难使人信服。保持法和交叉验证是两种基于给定数据随机选样划分的、常用的评估分类方法准确率的技术 [2] 。
在保持法中,把给定的数据随机地划分成两个独立的集合:训练集和测试集。通常,三分之一的数据分配到训练集,其余三分之二的数据分配到测试集。使用训练集得到分类器,其准确率用测试集评估。
先把数据随机地分成不相交的n份,每份大小基本相等,训练和测试都进行n次。比如把数据分成10份,先把第一份拿出来放在一边用作模型测试,把其他9份合在一起来建立模型,然后把这个用90%的数据建立起来的模型用第一份数据做测试。这个过程对每一份数据都重复进行一次,得到10个不同的错误率。然后,把所有数据放在一起建立一个模型,模型的错误率为这10个错误率的平均值。
使用这些技术评估分类法的准确率增加了总体的计算时间,但是对于分类方法的选择是有意义的。