
下载掌阅APP,畅读海量书库
立即打开



在Swift中最常用的集合类型非数组莫属。数组是一系列相同类型的元素的有序的容器,对于其中每个元素,我们可以使用下标对其直接进行访问(这又被称作随机访问)。举个例子,要创建一个数字的数组,我们可以这么写:
//斐波那契数列
let fibs=[0,1,1,2,3,5]
要是我们使用像是append(_:)这样的方法来修改上面定义的数组,则会得到一个编译错误。这是因为在上面的代码中数组是用let声明为常量的。在很多情景下,这是正确的做法,它可以避免我们不小心对数组做出改变。如果我们想按照变量的方式来使用数组,则需要将它用var来进行定义:
var mutableFibs=[0,1,1,2,3,5]
现在我们就能很容易地为数组添加单个或是一系列元素了:
mutableFibs.append(8)
mutableFibs.append(contentsOf:[13,21])
mutableFibs//[0,1,1,2,3,5,8,13,21]
区别使用var和let可以给我们带来不少好处。使用let定义的变量因为具有不变性,更有理由被优先使用。当你读到类似let fibs=...这样的声明时,你可以确定fibs的值将永远不变,这一点是由编译器强制保证的。这在你需要通读代码的时候会很有帮助。不过,要注意这只针对那些具有值语义的类型。使用let定义的类实例对象(也就是说对于引用类型)时,它保证的是这个 引用 永远不会发生变化,你不能再给这个引用赋一个新的值,但是这个引用所指向的对象却是 可以 改变的。我们将在结构体和类中更加详尽地介绍两者的区别。数组和标准库中的所有集合类型一样,是具有值语义的。当你创建一个新的数组变量并且把一个已经存在的数组赋值给它的时候,这个数组的内容会被复制。举个例子,在下面的代码中,x将不会被更改:
var x=[1,2,3]
var y=x
y.append(4)
y//[1,2,3,4]
x//[1,2,3]
var y=x语句复制了x,所以在将4添加到y末尾的时候,x并不会发生改变,它的值依然是[1,2,3]。当你把一个数组传递给一个函数时,会发生同样的事情;方法将得到这个数组的一份本地副本,所有对它的改变都不会影响调用者所持有的数组。
对比一下Foundation框架中NSArray在可变特性上的处理方法。NSArray中没有更改方法,想要更改一个数组,你必须使用NSMutableArray。但是,就算你拥有的是一个不可变的NSArry,但是它的引用特性并 不能 保证这个数组不会被改变:
let a=NSMutableArray(array:[1,2,3])
//我们不想让b发生改变
let b:NSArray=a
//但是事实上它依然能够被a影响并改变
a.insert(4,at:3)
b//(1,2,3,4)
正确的方式是在赋值时,先手动进行复制:
let c=NSMutableArray(array:[1,2,3])
//我们不想让d发生改变
let d=c.copy()as!NSArray
c.insert(4,at:3)
d//(1,2,3)
在上面的例子中,显而易见,我们需要进行复制,因为a的声明毕竟是可变的。但是,当把数组在方法和函数之间来回传递的时候,事情可能就不那么明显了。
而在Swift中,相比于NSArray和NSMutableArray两种类型,数组只有一种统一的类型,那就是Array。使用var可以将数组定义为可变的,但是区别于NS的数组,当你使用let定义第二个数组,并将第一个数组赋值给它,也可以保证这个新的数组是不会改变的,因为这里没有共用的引用。
创建如此多的复制有可能造成性能问题,不过实际上,Swift标准库中的所有集合类型都使用了“写时复制”这一技术,它能够保证只在必要的时候对数据进行复制。在我们的例子中,直到y.append被调用的之前,x和y都将共享内部的存储。在结构体和类中我们也将仔细研究值语义,并告诉你如何为自己的类型实现写时复制特性。
Swift数组提供了你能想到的所有常规操作方法,像isEmpty或是count。数组也允许直接使用特定的下标直接访问其中的元素,像fibs[3]。不过要牢记,在使用下标获取元素之前,你需要确保索引值没有超出范围。比如获取索引值为3的元素,你需要保证数组中至少有4个元素。否则,你的程序将会崩溃。
这么设计的主要原因是我们可以使用数组切片。在Swift中,计算一个索引值这种操作是非常罕见的:
·想要迭代数组?for x in array
·想要迭代除第一个元素以外的数组其余部分?for x in array.dropFirst()
·想要迭代除最后5个元素以外的数组?for x in array.dropLast(5)
·想要列举数组中的元素和对应的下标?for(num,element)in collection.enumerated()
·想要寻找一个指定元素的位置?if let idx=array.index{someMatchingLogic($0)}
·想要对数组中的所有元素进行变形?array.map{someTransformation($0)}
·想要筛选出符合某个标准的元素?array.filter{someCriteria($0)}
Swift3中传统的C风格的for循环被移除了,这是Swift不鼓励你去做索引计算的另一个标志。手动计算和使用索引值往往可能带来很多潜在的bug,所以最好避免这么做。如果这不可避免,那么我们可以很容易地写一个可重用的通用函数来进行处理,在其中你可以对精心测试后的索引计算进行封装,你会在泛型一章里看到这个例子。
但是有些时候你仍然不得不使用索引。对数组索引来说,当你这么做时,你应该已经对背后的索引计算逻辑进行过认真思考。在这个前提下,如果每次都要对获取的结果进行解包就显得多余了——因为这意味着你不信任你的代码。但实际上你是信任你的代码的,所以你可能会选择将结果进行强制解包,因为你 知道 这些下标都是有效的。这一方面十分麻烦,另一方面也是一个坏习惯。当强制解包变成一种习惯后,很可能你会不小心强制解包了本来不应该解包的东西。所以,为了避免这个行为变成习惯,数组根本没有给出可选值的选项。
无效的下标操作会造成可控的崩溃,有时候这种行为可能会被叫作不安全,但是这只是安全性的一个方面。下标操作在内存安全的意义上是完全安全的,标准库中的集合总是会执行边界检查,并禁止那些越界索引对内存的访问。
其他操作的行为略有不同。first和last属性返回的是可选值,当数组为空时,它们返回nil。first相当于isEmpty?nil:self[0]。类似地,如果数组为空时,则removeLast将会导致崩溃,而popLast将在数组不为空时删除最后一个元素并返回它,在数组为空时,它将不执行任何操作,直接返回nil。你应该根据自己的需要来选取到底使用哪一个:当你将数组当作栈来使用时,你可能总是想要将empty检查和移除最后元素组合起来使用;而另一方面,如果你已经知道数组一定非空,那么再去处理可选值就完全没有必要了。
我们会在本章后面讨论字典的时候再次遇到关于这部分的权衡。除此之外,关于[可选值]本书会有一整章的内容对它进行讨论。
Map
对数组中的每个值执行转换操作是一个很常见的任务。每个程序员可能都写过上百次这样的代码:创建一个新数组,对已有数组中的元素进行循环依次取出其中的元素,对取出的元素进行操作,并把操作的结果加入到新数组的末尾。比如,下面的代码计算了一个整数数组里的元素的平方:
var squared:[Int]=[]
for fib in fibs{
squared.append(fib*fib)
}
squared//[0,1,1,4,9,25]
Swift数组拥有map方法,这个方法来自函数式编程的世界。下面的例子使用了map来完成同样的操作:
let squares=fibs.map{fib in fib*fib}
squares//[0,1,1,4,9,25]
这种版本有三大优势。首先,它很短。长度短一般意味着错误少,不过更重要的是,它比原来更清晰。所有无关的内容都被移除了,一旦你习惯了map满天飞的世界,你就会发现map就像是一个信号,一旦你看到它,就会知道即将有一个函数被作用在数组的每个元素上,并返回另一个数组,它将包含所有被转换后的结果。
其次,squared将由map的结果得到,我们不会再改变它的值,所以也就不再需要用var来进行声明了,我们可以将其声明为let。另外,由于数组元素的类型可以从传递给map的函数中推断出来,我们也不再需要为squared显式地指明类型了。
最后,创造map函数并不难,你只需要把for循环中的代码模板部分用一个泛型函数封装起来就可以了。下面是一种可能的实现方式(在Swift中,它实际上是Sequence的一个扩展,我们会在之后关于编写泛型算法的章节里继续Sequence的话题):
extension Array{
func map<T>(_transform:(Element)->T)->[T]{
var result:[T]=[]
result.reserveCapacity(count)
for x in self{
result.append(transform(x))
}
return result
}
}
Element是数组中包含的元素类型的占位符,T是元素转换之后的类型的占位符。map函数本身并不关心Element和T究竟是什么,它们可以是任意类型。T的具体类型将由调用者传入给map的transform方法的返回值类型来决定。
实际上,这个函数的签名应该是:
func map<T>(_transform:(Element)throws->T)rethrows->[T]
也就是说,对于可能抛出错误的变形函数,map将会把错误转发给调用者。我们会在错误处理一章里覆盖这个细节。在这里,我们选择去掉错误处理的这个修饰,这样看起来会更简单一些。如果你感兴趣,那么可以看看GitHub上Swift仓库的Sequence.map的源码实现 [1] 。
使用函数将行为参数化
即使你已经很熟悉map了,也请花一点时间来想一想map的代码。是什么让它可以如此通用而且有用?
map可以将模板代码分离出来,这些模板代码并不会随着每次调用发生变动,发生变动的是那些功能代码,也就是如何变换每个元素的逻辑代码。map函数通过接受调用者所提供的变换函数作为参数来做到这一点。
纵观标准库,我们可以发现很多这样将行为进行参数化的设计模式。标准库中有不下十多个函数接受调用者传入的闭包,并将它作为函数执行的关键步骤:
·map和flatMap——如何对元素进行变换。
·filter——元素是否应该被包含在结果中。
·reduce——如何将元素合并到一个总和的值中。
·sequence——序列中下一个元素应该是什么。
·forEach——对于一个元素,应该执行怎样的操作。
·sort,lexicographicCompare和partition——两个元素应该以怎样的顺序进行排列。
·index,first和contains——元素是否符合某个条件。
·min和max——两个元素中的最小值/最大值是哪个。
·elementsEqual和starts——两个元素是否相等。
·split——这个元素是否是一个分割符。
所有这些函数的目的都是为了摆脱代码中那些杂乱无用的部分,比如像创建新数组,对源数据进行for循环之类的事情。这些杂乱代码都被一个单独的单词替代了。这可以重点突出那些程序员想要表达的真正重要的逻辑代码。这些函数中有一些拥有默认行为。除非你进行过指定,否则sort默认会把可以做比较的元素按照升序排列。contains对于可以判等的元素,会直接检查两个元素是否相等。这些行为让代码变得更加易读。升序排列非常自然,因此array.sort()的意义也很符合直觉。而对于array.index(of:"foo")这样的表达方式,也要比array.index{$0=="foo"}更容易理解。不过在上面的例子中,它们都只是特殊情况下的简写。集合中的元素并不一定需要可以做比较,也不一定需要可以判等。你可以不对整个元素进行操作,比如,对一个包含人的数组,你可以通过他们的年龄进行排序(people.sort{$0.age<$1.age}),或者检查集合中有没有包含未成年人(people.contains{$0.age<18})。你也可以对转变后的元素进行比较,比如通过people.sort{$0.name.uppercased()<$1.name.uppercased()}来进行忽略大小写的排序,虽然这么做的效率不会很高。
还有一些其他类似的很有用的函数,可以接受一个闭包来指定行为。虽然它们并不存在于标准库中,但是你可以很容易地定义和实现它们,我们也建议你尝试着做做看:
·accumulate——累加,和reduce类似,不过是将所有元素合并到一个数组中,而且保留合并时每一步的值。
·all(matching:)和none(matching:)——测试序列中是不是所有元素都满足某个标准,以及是不是没有任何元素满足某个标准。它们可以通过contains和它进行了精心对应的否定形式来构建。
·count(where:)——计算满足条件的元素的个数,和filter相似,但是不会构建数组。
·indices(where:)——返回一个包含满足某个标准的所有元素的索引的列表,和index( where:)类似,但是不会在遇到首个元素时就停止。
·prefix(while:)——当判断为真的时候,将元素滤出到结果中。一旦不为真,就将剩余的抛弃。和filter类似,但是会提前退出。这个函数在处理无限序列或者是延迟计算(lazily-computed)的序列时会非常有用。
·drop(while:)——当判断为真的时候,则丢弃元素。一旦不为真,则返回其余的元素。和prefix(while:)类似,不过返回相反的集合。
对于上面列表中的部分函数,我们在本书的其他地方进行了定义和实现。(prefix(while:)和drop(while:)已经在添加到标准库的计划之中 [2] ,它们没有来得及被添加到Swift3.0中,不过会在未来的版本中被添加。)
有时候你可能会发现你写了好多次同样模式的代码,比如想要在一个逆序数组中寻找第一个满足特定条件的元素:
let names=["Paula","Elena","Zoe"]
var lastNameEndingInA:String?
for name in names.reversed()where name.hasSuffix("a"){
lastNameEndingInA=name
break
}
lastNameEndingInA//Optional("Elena")
在这种情况下,你可以考虑为Sequence添加一个小扩展,将这个逻辑封装到last(where:)方法中。我们使用闭包来对for循环中发生的变化进行抽象描述:
extension Sequence{
func last(where predicate:(Iterator.Element)->Bool)->Iterator.Element?{
for element in reversed()where predicate(element){
return element
}
return nil
}
}
现在我们就能把代码中的for循环换成findElement了:
let match=names.last{$0.hasSuffix("a")}
match//Optional("Elena")
这么做的好处和我们在介绍map时所描述的是一样的,相比for循环,last(where:)的版本显然更加易读。虽然for循环也很简单,但是在你的头脑里你始终还是要去做一个循环,这加重了理解的负担。使用last(where:)可以减少出错的可能性,而且它允许你使用let而不是var来声明结果变量。
它和guard一起也能很好地工作,可能你会想要在元素没被找到的情况下提早结束代码:
guard let match=someSequence.last(where:{$0.passesTest()})
else{return}
//对match进行操作
我们在本书后面会进一步涉及扩展集合类型和使用函数的相关内容。
可变和带有状态的闭包
当遍历一个数组的时候,你可以使用map来执行一些其他操作(比如将元素插入到一个查找表中)。我们不推荐这么做,来看看下面这个例子:
array.map{item in
table.insert(item)
}
这将副作用(改变了查找表)隐藏在了一个看起来只是对数组变形的操作中。在上面这样的例子中,使用简单的for循环显然是比使用map这样的函数更好的选择。有一个叫作forEach的函数,看起来很符合我们的需求,但是forEach本身存在一些问题,后面会详细讨论。
这种做法和故意给闭包一个 局部 状态有本质的不同。闭包是指那些可以捕获自身作用域之外的变量的函数,闭包再结合上高阶函数,将成为强大的工具。举个例子,前面我们提到的accumulate函数就可以用map结合一个带有状态的闭包来进行实现:
extension Array{
func accumulate<Result>(_initialResult:Result,
_nextPartialResult:(Result,Element)->Result)->[Result]
{
var running=initialResult
return map{next in
running=nextPartialResult(running,next)
return running
}
}
}
这个函数创建了一个中间变量来存储每一步的值,然后使用map来从这个中间值逐步创建结果数组:
[1,2,3,4].accumulate(0,+)//[1,3,6,10]
要注意的是,这段代码假设了变形函数是以序列原有的顺序执行的。在我们上面的map中,事实确实如此。但是也有可能对于序列的变形是无序的,比如我们可以有并行处理元素变形的实现。官方标准库中的map版本没有指定它是否会按顺序来处理序列,不过看起来现在这么做是安全的。
Filter
另一个常见操作是检查一个数组,然后将这个数组中符合一定条件的元素过滤出来并用它们创建一个新的数组。对数组进行循环并且根据条件过滤其中元素的模式可以用数组的filter方法表示:
nums.filter{num in num%2==0}//[2,4,6,8,10]
我们可以使用Swift内建的用来代表参数的简写$0,这样代码将会更加简短。我们可以不用写出num参数,而将上面的代码重写为:
nums.filter{$0%2==0}//[2,4,6,8,10]
对于很短的闭包,这样做有助于提高可读性。但是如果闭包比较复杂,更好的做法应该是像我们之前那样,显式地把参数名字写出来。不过这更多的是一种个人选择,使用一眼看上去更易读的版本就好。一个不错的原则是,如果闭包可以很好地写在一行里,那么使用简写名会更合适。
通过组合使用map和filter,我们现在可以轻易完成很多数组操作,而不需要引入中间数组。这会使得最终的代码变得更短更易读。比如,寻找100以内同时满足是偶数并且是其他数字的平方的数,我们可以对0..<10进行map来得到所有平方数,然后再用filter过滤出其中的偶数:
(1..<10).map{$0*$0}.filter{$0%2==0}
//[4,16,36,64]
filter的实现看起来和map很类似:
extension Array{
func filter(_isIncluded:(Element)->Bool)->[Element]{
var result:[Element]=[]
for x in self where isIncluded(x){
result.append(x)
}
return result
}
}
如果你对在for中所使用的where感兴趣,则可以阅读可选值一章。
一个关于性能的小提示:如果你正在写下面这样的代码,请不要这么做!
bigArray.filter{someCondition}.count>0
filter会创建一个全新的数组,并且会对数组中的每个元素都进行操作。然而在上面这段代码中,这显然是不必要的。上面的代码仅仅检查了是否有至少一个元素满足条件,在这个情景下,使用contains(where:)更为合适:
bigArray.contains{someCondition}
这种做法会比原来快得多,主要因为两个方面:它不会为了计数而创建一整个全新的数组,并且一旦匹配了第一个元素,它就将提前退出。一般来说,你只应该在需要所有结果时才去选择使用filter。有时候你会发现你想用contains完成一些操作,但是写出来的代码看起来很糟糕。比如,要是你想检查一个序列中的所有元素是否全部都满足某个条件,则可以用!sequence.contains {!condition},其实你可以用一个更具有描述性名字的新函数将它封装起来:
extension Sequence{
public func all(matching predicate:(Iterator.Element)->Bool)->Bool{
//对于一个条件,如果没有元素不满足它,那么意味着所有元素都满足它:
return!contains{!predicate($0)}
}
}
let evenNums=nums.filter{$0%2==0}//[2,4,6,8,10]
evenNums.all{$0%2==0}//true
Reduce
map和filter都作用在一个数组上,并产生另一个新的、经过修改的数组。不过有时候,你可能会想把所有元素合并为一个新的值。比如,要是我们想将元素的值全部加起来,可以这样写:
var total=0
for num in fibs{
total=total+num
}
total//12
reduce方法对应这种模式,它把一个初始值(在这里是0)以及一个将中间值(total)与序列中的元素(num)进行合并的函数进行了抽象。使用reduce,我们可以将上面的例子重写为这样:
let sum=fibs.reduce(0){total,num in total+num}//12
运算符也是函数,所以我们也可以把上面的例子写成这样:
fibs.reduce(0,+)//12
reduce的输出值的类型可以和输入的类型不同。举个例子,我们可以将一个整数的列表转换为一个字符串,这个字符串中每个数字后面跟一个空格:
fibs.reduce(""){str,num in str+"\(num)"}
//0 1 1 2 3 5
reduce的实现是这样的:
extension Array{
func reduce<Result>(_initialResult:Result,
_nextPartialResult:(Result,Element)->Result)->Result
{
var result=initialResult
for x in self{
result=nextPartialResult(result,x)
}
return result
}
}
另一个关于性能的小提示:reduce相当灵活,所以在构建数组或者是执行其他操作时看到
reduce的话也不足为奇,比如,你可以只使用reduce就能实现map和filter:
extension Array{
func map2<T>(_transform:(Element)->T)->[T]{
return reduce([]){
$0+[transform($1)]
}
}
func filter2(_isIncluded:(Element)->Bool)->[Element]{
return reduce([]){
isIncluded($1)?$0+[$1]:$0
}
}
}
这样的实现符合美学,并且不再需要那些啰嗦的命令式的for循环。但是Swift不是Haskell,Swift的数组并不是列表(list)。在这里,每次执行combine函数都会通过在前面的元素之后附加一个变换元素或者是已包含的元素,并创建一个全新的数组。这意味着上面两个实现的复杂度是 O ( n 2 ),而不是 O ( n )。随着数组长度的增加,执行这些函数所消耗的时间将以平方关系增加。
flatMap
有时候我们会想要对一个数组用一个函数进行map,但是这个变形函数返回的是另一个数组,而不是单独的元素。
举个例子,假如我们有一个叫作extractLinks的函数,它会读取一个Markdown文件,并返回一个包含该文件中所有链接的URL的数组。这个函数的类型是这样的:
func extractLinks(markdownFile:String)->[URL]
如果我们有一系列的Markdown文件,并且想将这些文件中所有的链接都提取到一个单独的数组中,那么我们可以尝试使用markdownFiles.map(extractLinks)来构建。不过问题是这个方法返回的是一个包含了URL的数组的数组,这个数组中的每个元素都是一个文件中的URL的数组。为了得到一个包含所有URL的数组,你还要对这个由map取回的数组中的每一个数组用joined来进行展平( fl atten),将它归并到一个单一数组中去:
let markdownFiles:[String]=//...
let nestedLinks=markdownFiles.map(extractLinks)
let links=nestedLinks.joined()
flatMap将这两个操作合并为一个步骤。markdownFiles.flatMap(links)将直接把所有Markdown文件中的所有URL放到一个单独的数组里并返回。
flatMap的实现看起来也和map基本一致,不过flatMap需要的是一个能够返回数组的函数作为变换参数。另外,在附加结果的时候,它使用的是append(contentsOf:)而不是append(_:),这样它将能把结果展平:
extension Array{
func flatMap<T>(_transform:(Element)->[T])->[T]{
var result:[T]=[]
for x in self{
result.append(contentsOf:transform(x))
}
return result
}
}
flatMap的另一个常见使用情景是将不同数组里的元素进行合并。为了得到两个数组中元素的所有配对组合,我们可以对其中一个数组进行flatMap,然后对另一个进行map操作:
let ranks=["J","Q","K","A"]
let result=suits.flatMap{suit in
ranks.map{rank in
(suit,rank)
}
}
使用forEach进行迭代
我们最后要讨论的操作是forEach。它和for循环的作用非常类似:传入的函数对序列中的每个元素执行一次。和map不同,forEach不返回任何值。从技术上来说,我们可以不假思索地将一个for循环替换为forEach:
for element in[1,2,3]{
print(element)
}
[1,2,3].forEach{element in
print(element)
}
这没有什么特别之处,不过如果你想要对集合中的每个元素都调用一个函数,那么使用forEach会比较合适。你只需要将函数或者方法直接通过参数的方式传递给forEach就行了,这可以改善代码的清晰度和准确性。比如在一个view controller里,你想把一个数组中的视图都加到当前view上的话,那么只需要写theViews.forEach(view.addSubview)就足够了。
不过,for循环和forEach有些细微的不同,这值得我们注意。比如,当一个for循环中有return语句时,将它重写为forEach会造成代码行为上的极大区别。举个例子,下面的代码是通过结合使用带有条件的where和for循环完成的:
extension Array where Element:Equatable{
func index(of element:Element)->Int?{
for idx in self.indices where self[idx]==element{
return idx
}
return nil
}
}
我们不能直接将where语句加入到forEach中,所以我们可能会用filter来重写这段代码(实际上这段代码是错误的):
extension Array where Element:Equatable{
func index_foreach(of element:Element)->Int?{
self.indices.filter{idx in
self[idx]==element
}.forEach{idx in
return idx
}
return nil
}
}
在forEach中的return并不能返回到外部函数的作用域之外,它仅仅只是返回到闭包本身之外,这和原来的逻辑就不一样了。在这种情况下,编译器会发现return语句的参数没有被使用,从而给出警告,我们可以找到问题所在。但我们不应该将找到所有这类错误的希望都寄托在编译器上。
再思考一下下面这个简单的例子:
(1..<10).forEach{number in
print(number)
if number>2{return}
}
你可能一开始还没反应过来,其实这段代码会把输入的数字全部打印出来。return语句并不会终止循环,它做的仅仅是从闭包中返回。
在某些情况下,比如上面的addSubview的例子里,forEach可能会更好。它作为一系列链式操作使用时可谓适得其所。想象一下,你在同一个语句中有一系列map和filter的调用,这时候你想在调试时打印出操作链中间某个步骤的数组值,插入一个forEach步骤应该是最快的选择。
不过,因为return在其中的行为不太明确,我们建议大多数情况下不要用forEach。这种时候,使用常规的for循环可能会更好。
切片
除了通过单独的下标来访问数组中的元素(比如fibs[0]),我们还可以通过下标来获取某个范围中的元素。比如,想要得到数组中除了首个元素的其他元素,我们可以这么做:
let slice=fibs[1..<fibs.endIndex]
slice//[1,1,2,3,5]
type(of:slice)//ArraySlice<Int>
它将返回数组的一个切片(slice),其中包含了原数组中从第二个元素到最后一个元素的数据。得到的结果的类型是ArraySlice,而不是Array。切片类型只是数组的一种 表示方式 ,它背后的数据仍然是原来的数组,只不过是用切片的方式来进行表示。这意味着原来的数组并不需要被复制。ArraySlice具有的方法和Array上定义的方法是一致的,因此你可以把它们当作数组来进行处理。如果你需要将切片转换为数组,则可以通过将切片传递给Array的构建方法来完成(见图2.1)。
Array(fibs[1..<fibs.endIndex])//[1,1,2,3,5]
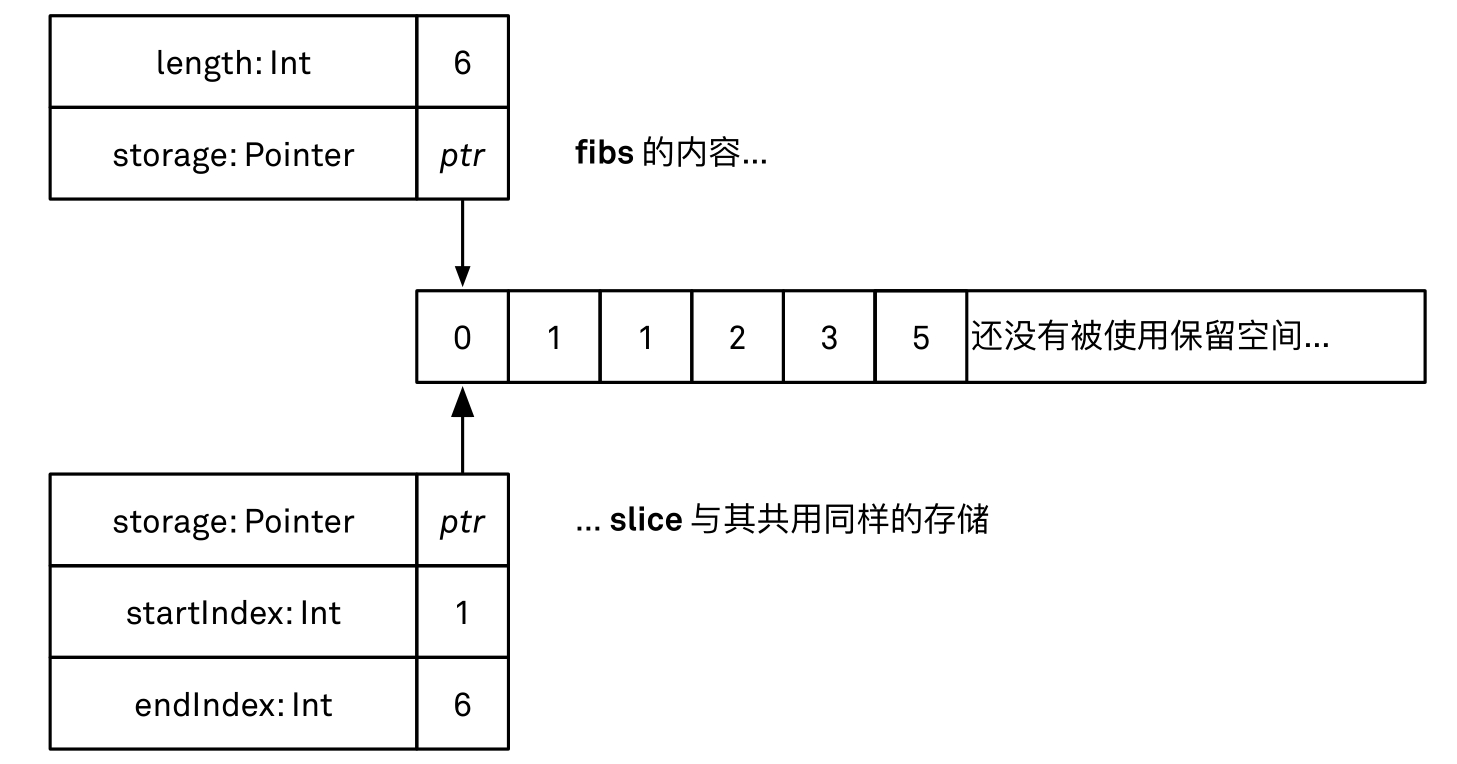
图2.1 数组切片
桥接
Swift数组可以桥接到Objective-C中。实际上它们也能被用在C代码里,不过本书稍后才会涉及这个问题。因为NSArray只能持有对象,所以对Swift数组进行桥接转换时曾经有一个限制,那就是数组中的元素需要能被转换为AnyObject——只有当数组元素是类实例或者是像Int、Bool、String这样的一小部分能自动桥接到Objective-C对应类型的值类型时,Swift数组才能被桥接。
不过在Swift3中,这个限制已经不复存在了。Objective-C中的id类型现在在导入Swift中时变成了Any [3] ,而不再是AnyObject,也就是说,任意的Swift数组都可以被桥接转换为NSArray了。NSArray本身仍旧只接受对象,所以,编译器在运行时将自动在后台把不适配的那些值用类来进行包装。反方向的解包同样也是自动进行的。
使用统一的桥接方式来处理所有Swift类型到Objective-C的桥接工作,不仅仅使数组的处理变得容易,像字典(dictionary)或者集合(set)这样的其他集合类型,也能从中受益。除此之外,它还为未来Swift与Objective-C之间互用性的增强带来了可能。比如,现在Swift的值可以桥接到Objective-C的对象,那么在未来的Swift版本中,一个Swift值类型完全有可能可以去遵守一个被标记为@objc的协议。