
下载掌阅APP,畅读海量书库
立即打开



鉴于读者可能分布在不同的知识水平阶段,所以首先要做的是对号入座,将自己对Linux的掌握与Linux相对全貌对比。有一些人是某一些领域的技术专家,有一些读者可能是接触Linux不久,还有人可能是找不到前进的方向。在学习Linux的过程中,最大的问题不是自己学不会,也并不存在由于智力问题导致自己无法提高的现象。所出现的问题主要有两个:一个是不知道学什么;另外一个是学习的内容没有实际应用的场景,从而导致无法透彻地领悟。第一个问题是本书希望解决的,第二个问题则需要各自在工作岗位上不断练习。
想要以Linux谋生的,下面介绍的“专家级”之前的知识一般都要学会,因为在工作中都会用到,但是也绝对不是说有的知识点没有掌握就没法工作。这里的定级也限于对Linux操作系统的使用,一般是软件和系统特性,也并没有涉及太多的编程要求。编程是另外的一个层面,编程能力不好不代表Linux的使用水平不行,所以这里的定级不怎么考虑编程水平。并且这里所列举的条件和分级都不全面,只是一个难度的代表,也并不是详细规范的分级制度,仅仅具有参考价值。并且本分级偏向从零开始自学Linux,然后使用Linux去实际完成工作的人。有的人一毕业就开始开发Linux内核也完全可以,甚至可以更加深刻快速地学习和理解整个系统。但是并不是所有人都有这个机会。所以本定级用由浅入深的自学流程进行分级。
1.未入门
大部分学习信息技术的人几乎不可能没有听说过Linux系统,大部分人也都使用过Linux系统,很可能第一次接触的是ls等命令接口,或者是Ubuntu的友好桌面环境。这些人不能被认为已经对Linux的知识达到了入门级的水平,也统一归到“未入门”的水平。如果是自己研究Linux,未入门这个级别需要额外突破以下两个条件。
· 不会安装操作系统。
· 不会用虚拟机(安装和使用)。
2.入门级
大部分希望学习Linux的人首先接触的都是一些基本的命令,随着图形化的发展,很多初次接触Linux的人可能首先接触的是图形界面的使用。不像早期接触Linux的人,只要使用图形界面就会遇到无数的问题,需要自己去解决。早期的Linux使用者,刚使用Linux的时候就是以一个Linux系统问题解决者的姿态开始的,而且早期发行版没有在市场上决出胜负,大家很可能使用的是各种奇奇怪怪的发行版。例如我使用的第一个发行版就是Everest,现在的大部分人都没听说过这个发行版。但是即使是现在,专用发行版依然有良好的存续空间,但是随着几个主流发行版的发展,这个现象很可能会快速改变,所以目前要达到入门级水平,要求做到以下两点。
· 熟悉常见的发行版。
· 会一些最基础的命令(例如cd、ps、top、ls、ifconfig等这个级别的)。
3.基础级
当我们使用Linux系统时不再是一直在执行ls、cd这些命令,感叹于命令行的黑科技的时候,我们就会深一步挖掘一些Linux的用法。
· 可以使用一些常见的命令(touch、tail、date、find、du、fdisk、less、pidof等这个级别的命令),使用这些命令标志着你知道了Linux操作系统的核心工作是资源管理。
· 对图形界面操作得比较熟练,并且能够对应一部分的后台命令。
· 知道一些常用的配置文件的作用(如/etc/hosts、/etc/resolv.conf、/etc/passwd+、/etc/mtab等)。
对Linux系统的加深理解是随着自己对操作系统知识的加深而加深的。毕竟Linux只是工具,对Linux系统理解的加深也是对操作系统理论知识理解加深的过程。很多人学习Linux并不是学习操作系统原理,而是通过知道一个命令,然后看看这个命令能干什么,从而来逐步了解操作系统。这种属于搜索式的学习方法,也是比较符合初学者学习思路的方法。但是最有效的方法却是在读英语书时经常能读到的思路,就是系统性地把“大部头”“啃”下来,然后根据书里的内容快速加深自己的认知,但是初学很容易迷失在一大堆的定义之中,不如实际的操作来得深刻。
由于属于基础级水平的命令特别多,这里不可能全部列出来。这个级别的命令在你学习了更高级的命令时就知道有什么区别了。例如你不会把lsusb、setarch等命令列入基础级,因为它们的专用性非常强。属于基础级的命令通常是无论是谁都要掌握的基本命令。
4.中级
一般自学Linux系统不会产生这个级别知识的需求,而在工作中就会频繁遇到,这些工作中需要的目标相对明确的知识就是中级的知识。
· 掌握一些运维时常用的命令(如iftop、iptraf、rsync、ngrep、sar、acct、sg系列、inotail、nmap、lsof、ip、dig、wall、write、mkfs、grub系列、awk、sed、cron、ldconfig、chrt、renice、nohup、socat、ethtools等)。这些命令的显著特点是你需要使用Linux去完成一定的任务。我初学Linux时买过一本《Linux命令速查手册》,我认为这里面的命令大都属于这个级别需要掌握的。
· 熟悉一些高级配置文件的使用(如ld.conf配置、sshd配置、samba配置、PAM配置,vsftp 配置等)。《鸟哥的私房菜——服务器架设篇》这本书里面的内容相对基础,适合处于这个级别的读者进行阅读。但是这个级别的配置文件的知识并不限于此。
· 熟悉Proc、Sys文件系统(进行诸如TCP调优、Core Dump目录和文件更改、PCI设备的bind与unbind、电梯算法调整等工作),这些操作并不容易用到,但是如果你完整地掌握了Proc、Sys文件系统的用法,你将会非常出色。
· 熟悉uevent(hotplug)、inotify,iptables、启动时的保留内存(CMA)、key-ring、ACL、sg 等高级系统特性。中级水平的人应该在一定程度上使用到常用的系统特性了,而不是像做普通的后台开发那样并不太关心系统的特性只关心逻辑。合理地使用系统特性并配合Shell,可以出色地解决嵌入式开发和运维的一些相对高难度的需求。
· 懂得根据自己的需求配置编译内核,可以使用脚本编程。配置自己的内核的能力几乎是这个级别必备的素质。不详细配置内核,几乎不太可能对内核有通篇宏观的了解。而不会脚本,在Linux的世界里就像不会走路一样。
这个级别对于大部分国内专业使用Linux的运维工作者来说很多是没有逾越的。很多运维工作者甚至不知道inotify、uevent,甚至一些关于Proc和Sys的知识也只是知道一些常用的知识点。他们平时干的更多的是写Shell脚本,调用一些常见的命令,完成一些自动化的运维工作。这个阶段的学习是最有趣的,也是最能够深入了解Linux一个过程。运维如果能够熟练使用并且理解socat,就基本上达到了对系统知识的要求了。例如socat exec:"tailf/var/log/auth.log" TCP4:1.2.3.4:1234&一个命令就完成了一个日志收集的程序。
5.高级
属于高级水平的人员就有一定的专业化倾向了,但还称不上彻底专业化。这部分的知识是一个顶级的运维人员在突破了中级水平的同时需要掌握的内容。没有这部分知识的支撑,就不能很好地定制Linux系统。由于这个级别Linux的使用一般离不开网络,所以这一部分的网络进阶将是重点。
· 可以掌握系统的高级特性。如安全的Capabilities、suid、PAM、LSM;如详细的Kobject体系(可以通过查看Sys文件系统取代常用的命令)、Netfilter的Hook使用和BPF(tcpdump和eBPF的使用)。能够熟习中断系统、合理地绑定中断源、进程的优先级调度(几种实时优先级和非实时优先级的设置)、OOM 分数的调整、cgroup等。
· 可以自由地选择使用高级的文件系统以服务于自己的需求(如Squashfs、Gfs、Ecryptfs、Configfs、Overlayfs等)。
· 熟悉ssh(转发、反弹等高级操作)、nc、socks、tcp wrapper等远程访问相关知识,可以做深入一些的安全审计和配置,需要更加深入了解iptables的各个模块,例如xt_connlimit、ip_set等相关的几十个网络过滤模块的使用。
· 熟习TCP的内核内部实现原理,常见的拥塞算法,甚至常见的TCP Offpath攻击,还有对应的一些与TCP相关的RFC。要求几乎是完整地看过TCP相关的代码,读完了相关的RFC,并且理解其中的算法。
· 可以进行内核的高级定制编译(适当地修改内核代码,追踪解决内核BUG)。
· 可以编写基础的内核模块,使用常用的内核编程接口。
· 懂得二进制原理(ELF文件格式、objdump、ld、nm、strings、readelf等常用的二进制软件)。
· 各种Bootloader的制作和安装。
· 熟习GCC编译的选项和技巧,可以写链接脚本,自己安排Section、Segment等。
· 需要会使用更多的工具,比如slabtop、lttng、blktrace、perf、tc、tune2fs等。
6.专家级
系统的了解和预备知识的准备同样重要。例如TCP的深刻理解才会知道如何做SYN的DDOS防护(不是内核的那个简单的开关);对无线理论的深刻了解,才能会无线的内核和应用内容。对于这部分知识的掌握,核心的工作已经不在于掌握Linux是怎么做的了,而是掌握这部分知识本身,Linux只是实现了这部分知识的要求。类似Wi-Fi或者显卡这种至今仍旧采用闭源战略的企业方向,Linux实现了兼容就已经非常不错了,就不要挑剔性能和稳定性了。常见的专用子系统有内核虚拟化、内核存储逻辑(SCSI、PCI、USB等)、无线子系统、音频子系统、显卡子系统、电源管理子系统、网络子系统、电源管理子系统等。
本书会重点涉及存储和网络两部分专用子系统。内存管理虽然也可以说是子系统,但更多的内容是高级技能,很少有人是专业做内存管理方面工作的,类似的还有进程子系统。
在Linux的使用者中有用来替代Windows的普通桌面用户(如使用Startos、Deepin或Ubuntu Desktop)。使用者中也有命令使用者。这部分人涵盖了很多实际的工作岗位,典型的是运维人员。运维人员有很多细分的子岗位:系统管理、软件管理、后台服务器管理(例如数据库、Http Server)、软件部署等。Linux用好了可以谋生,目前几乎所有的后台开发都需要或多或少地掌握Linux相关知识,因为国内互联网后台几乎被Linux“统一”了。
1.桌面使用者
使用桌面可以只使用鼠标进行点击操作即可,但是桌面也可以被用得比较深入。也有专门的职业工作就是怎么把桌面用起来。例如嵌入式里的裁剪和启动桌面(比如让startx命令跑起来)。
Linux的桌面有很多。普通的使用者一般会直接使用几个常见桌面提供的环境和软件,而不同于Windows 的鼠标点击,桌面的使用还可以更加深入。
(1)发行版
Linux的发行版有很多,一般是不同风格或者是服务于不同目的的专用发行版。常见的通用的发行版有:Ubuntu、OpenSuse、Fedora、Debian、Mandriva、Mint。目前越来越多Linux的使用者和开发者转向Ubuntu,甚至以前在服务器领域常用的Centos也在慢慢地丢失市场,而Ubuntu Server的市场占比开始增长,甚至Kali这种专业性极强的安全渗透发行版,其安全能力也在逐渐被Ubuntu追赶。但是近期的Ubuntu放弃Unity事件,使得市场的未来前景仍然充满变数。
专用的发行版如Kali(网络渗透)、Puppy、LUbuntu(精简)、Coreos、Ubuntu core(虚拟化)、Router OS(路由器)。这些专用发行版一般提供给专业用户,要发挥其全部威力,通常需要更多的行业知识。
(2)桌面环境
常见的桌面环境有很多:Ubuntu的Unity、Gnome、Kde、Cinnamon、Mate、Lxde、Xfce。一般各个发行版都会携带不同的桌面环境,每个桌面环境的窗口风格都是不一样的。包括随桌面管理器携带的配套软件一般也是不一样的(例如计算器、包管理器、音乐播放器等)。但是有的流行的软件还是会被移植到不同的桌面管理器上的。
Gnome、KDE、Unity的使用者最多。Unity目前只用于Ubuntu。Ubuntu也并不是只支持Unity,对于几乎所有的桌面环境,Ubuntu都有对应的支持版本。Ubuntu放弃Unity之后采用Gnome,也充分说明了未来对于桌面环境市场的预期变化。
高级的桌面使用者一般可以自由选择不同的桌面环境,理解每个桌面环境工作的原理,理解X系统,可以远程多终端使用X系统,自由选择启动,甚至不启动X系统或者X系统的一部分。理解X系统和桌面管理器与窗口管理器的区别。
存在如此多的桌面环境就导致发行版在选择桌面环境的时候的质量参差不齐,也由于Linux发行版的创作者大多数都是不盈利的小团队,甚至是个人。所以他们倾向于使用容易处理的小型桌面环境,所以你会发现大部分的发行版都是使用的比较原始脆弱的小众桌面环境,虽然他们的作者是一位很有能力的“Linuxer”。这种趋势随着Ubuntu等大型发行版的商业化运行被逐渐改变,分布式的自由发展,在遇到一个人工作量难以覆盖的大项目,并且缺少强有力的领导时,逐步让步于集中式的商业开发。
(3)FrameBuffer
FrameBuffer是Linux图形界面显示的兼容方法,但不是最高效的,因此这个机制一般作为最后的显示手段。一般的显卡驱动都有自己的专门机制来支持。FrameBuffer模式的显卡本身不具有任何运算数据的能力,它好比是一个暂时存放水的水池。CPU将运算后的结果放到这个水池,水池再将结果流到显示器。中间不会对数据做处理。在这种情况下,所有显示任务都由CPU完成,CPU的负担很重。从FrameBuffer这个名字我们就能猜测到它的功能了(侦缓冲)。
在Linux内核中也有FrameBuffer机制,模仿FrameBuffer显卡的这种功能。它的好处是把显卡的硬件结构抽象掉,把所有的显卡都当作一个”水池”来用。应用程序也可以直接读取这个水池的内容。FrameBuffer的设备名是/dev/fb。使用GPU的时候理论上确实可以把GPU的内存也映射到这个抽象设备上,但是很少人会这么做。
Linux字符界面在高分辨率下,启动时会有一个小企鹅的Logo,这个Logo就是用FrameBuffer功能写在屏幕上的,因为此时显卡尚未保证初始化。
(4)X协议
Linux内核给用户提供了显示FrameBuffer设备用于显示,所有要显示的东西写到FrameBuffer去就好了。也就是内核提供了显示的机制,但是没有提供显示的内容。所以显示内容需要操作系统去实现。
几乎所有的Linux显示的核心都是X协议,X是一种显示协议,实现这个协议的常用软件有Xfree86、Motif(商用)、Xorg、Xnest等。所以X协议也可以在Windows系统中实现,苹果操作系统也是用的X协议,只是是实现在内核中。现在的Linux发型版一般都默认使用Xorg。好多人都看到“X11”这个词,X11R6 实际上是 X Protocol version 11 Release 6(X协议第11版第六次发行)。
2.命令使用者
命令行是Linux的最出彩的API接口,从某种意义上说命令行就是面向组件的编程,并且这些组件就直接是一些可以单独运行的程序。我们知道编程只有复用了才会有最大的效率,而Shell就是把编程复用到了程序级别。应该说在编程思想上是非常先进的。
但是复用到程序级别就必然有一些程序上的开销损耗,导致Shell程序的性能不会太高,但是考虑到被复用的组件,例如grep、sed、awk都是有着极高的效率,所以这种复用通常会随着组件性能的提高和机器性能的提高而使得性能问题越来越可以被忽略。
命令使用者就像在写Python程序时候的交互式模式,只是Shell在交互式上做得更好。使用命令就是使用程序,只是在Linux上通常是指Shell脚本程序的文本形式,例如Busybox这种工具还可以在一个程序的内部集成本来由多个程序完成的组件级的复用。仅仅是一个一个地使用命令不能够体现Linux这个Shell模式的强大,更多的时候是使用Shell编程语言进行编程。这种程序本质上也是由一个一个的命令组成的。研究一下Shell编程就会有一个体会:你写的每一个语法本质上都是一个命令,只是语法层次上的命令都是直接集成到Shell程序内的。最常用的Shell程序和语法是Bash带来的,但是除此之外还有很多语法不同的Shell实现,例如csh、zsh等。
3.运维使用者
运维人员可以说是最专业的Linux使用者了,因为他们要关心Linux整个系统的运行状况,是对Linux系统的使用方面挖掘得最深的人。研发人员可能会更深入地研究Linux系统,但是在广度方面一般不如运维人员。运维一般是指互联网公司需要Linux服务器后台日常维护工作人员,与后台开发有本质的区别。
一个运维人员的基本功应该是查看Linux系统状态的命令和脚本的编写,深入一些的运维对Linux有更深刻的了解。有经验的运维人员除了掌握这些知识点之外,还可以处理Linux系统常见的问题和故障,会使用运维系统的设计和DevOps等先进的协作方法。以下几个知识点建议运维人员掌握。
(1)命令
基础的命令是每个命令行使用者都要掌握的,然而由于运维这个职业更多要关心的是机器的资源运行使用情况,所以有一些更专业的常用命令。由于运维工作的重点在于资源,而操作系统的资源大部分就是网络、内存、磁盘、CPU、文件句柄这几大类,所以运维的大部分工作就是用不同的命令监控这些不同类别的资源,并且做一些脚本化的操作。一些常用的基础命令,例如top、ps等就不属于运维这个职业的命令,而应该是属于使用Linux系统命令行都应该掌握的基础命令。以下列出的命令也相对基础,很多专用的高级命令会在书中给出,还有很多专用系统级的已经不能称作是命令的,例如Nagios工具也不在此列。并且必须要强调的是资源监控的命令大多数都是基于proc文件系统的内容,如果你深入研究了proc文件系统,你将可以自己独立写出很多专用命令。
① 网络
· iftop:查看连接流量。还可以交互地查看端口到端口,以及进行过滤。
· netstat(可以用ss或lsof替代):查看网络的连接状况。
· iptraf:图形化的观看IP流量。
· nethogs:类似网络的top工具。
· tcpdump:抓包直接打印或者保存为pcap文件,甚至可以生成bpf代码。
· ngrep:把网络数据包当成grep文件一样过滤。快速查看网络数据的好工具。
· mascan、hscan、nmap:扫描器。
· nping:具有很高灵活性,且功能广泛的网络调试工具。
② 内存与I/O
· vmstat:报告内存的使用情况。
· iostat、iotop:报告磁盘I/O的使用情况。
③ 进程
· htop:增强的top,界面更漂亮,功能也更多。
④ 其他
· sar:综合性地查看系统资源使用的工具。
· lsof:列出打开的文件。这个工具非常强大,这是因为在Linux系统下一切皆是文件。
· acct:用于监控用户。
· monit:一个比较全面的系统资源监控命令。
除上述之外,还有一些用起来比较方便的工具,例如nping、incron(使用inotify机制,当文件发生变化时自动执行注册脚本,对应于cron是基于时间的,incron是基于文件事件的)、rsync(远程文件同步)。这类工具是海量的,运维人员会在对它们越来越深入地使用中逐渐遇到新的需求。sleuthkit工具是典型的专用工具,这类的工具更强大,但较少用到,它是高级命令使用者需要掌握的工具。
(2)机制
系统机制主要是指一些系统目录和系统基础功能的使用。典型的系统目录是/proc和/sys目录。proc文件系统和sys文件系统可以作为运维人员的提高篇进行学习,可以从/proc/pid/下面的文件中看到在上述命令中看到的东西;从/proc/sys/中看到和修改系统当前的参数配置;从/sys/目录下看到系统当前的物理资源(例如通过rotational文件来判断一个存储设备是否是SSD),sys文件系统内部的Kobject、Ksystem、Kset机制和uevent、hotplug、udev等要熟悉。最好是手动遍历/proc目录和/sys目录下的所有文件,了解每一个文件的作用和使用方法。例如如果你想找系统启动的时间,除了ps命令之外,你可以直接查看/proc/pid/stats。
系统的基础功能与命令工具的边界比较模糊,实际上很多基础功能都是由一个个软件包组成的,各个软件包又分别对应着一系列的命令。一般比较优秀的运维人员可以自己升级Linux内核,能够熟练使用grub。可以熟悉使用inotify、rsync、ZoneKeeper、Ansible等基础设置软件进行发布和同步。基于对SCSI在Linux的重要性,需要了解sg系列命令的使用。例如一个典型的跳板机的配置,配置如下。

这看起来是ssh软件的使用,实际上还涉及nc命令,大型企业都会遇到跳板的实现原理,以及Ansible的使用配置等。你还可能在设置这个文件时跟iptables打交道。
(3)脚本
运维人员喜欢让自己的Shell尽量“帅”起来,例如使用Guake、Tmux、Zsh、Emacs等,还要熟练使用ssh远程管理系统,以及相关配置。通常大家都是编写Bash脚本。
cron命令和自动化脚本是管理每台机器必需的,除非非常大的公司有自己独立的运维系统。脚本的编写也将运维人员分为好几类,由于每种Shell的语法实现是不同的,所以不存在标准的Shell语法,只存在使用广泛与不广泛的区别。最常用的是Bash,但是最强大的当属zsh。你也完全可以自己用Python实现一个自己定义语法的Shell解析器,只要它能调用命令并且具备逻辑能力。
我们都知道当你只是使用一个工具的时候,你会希望那个工具越简单好用越好,但是如果当一个工具你要一辈子使用它的时候,你会更倾向于那个工具要尽可能的强大,甚至不惜为此付出很多的资金成本和时间成本,而复杂度通常和强大是同时出现的。Zsh用不好就会慢,并且难以找到懂行的人来维护。所以从社会的角度看,Zsh不能被广泛地传播是Bash这种良币驱逐了劣币。但是从技术的角度看,很多技术人员就会认为是劣币驱逐了良币。
4.系统管理员
系统管理员与运维人员很类似,不过运维人员一般出现在互联网企业,系统管理员一般出现在传统企业。系统管理员比运维人员更偏向于使用现有工具,而运维人员对系统的了解和脚本的使用会比系统管理员更熟悉。
系统管理员一般对升级内核要求不多,但是升级系统版本还是有的,库的部署、部署环境(Docker)、解决环境问题、软件发布、配置管理等。一般对etc目录下的配置文件都要很熟,一个占用时间的工作很可能是修电脑。但是也有很多技术超群的系统管理员,可以管理高度复杂或高度定制化的系统。但是在现实中,通常系统管理员要承担的工作会超出界限,在实际中并没有完全精准定义的系统管理员的这个职业。例如追查黑客入侵、评估测试购买硬件、服务器权限管理等难以界定的工作,很多时候都是谁可以解决就找谁完成了。
5.后台服务管理员
后台服务管理员中最常见的职位是DBA,就是Database Administrator。数据库管理员是所有后台服务中最常见的,很多企业的数据库是外购的企业级的数据库。对于这些数据库的管理就相对简单,更多的侧重于使用。主要工作是安装、监控、备份、恢复。但是现在MySQL和一些开源的NoSQL数据库占领企业市场的比重越来越大,导致数据库的管理员多了很多技术人员的“味道”,这样就很难界定什么工作属于谁了。例如数据库的集群、分库分表、性能优化等工作就成为数据库管理员和后台开发人员共同关心的问题了。
诸如数据库管理、Http Server、NTP、DNS Server、FTP Server等各种常见的服务器的搭建和配置管理,说起来容易,但每个软件都有很多配置文件,并且大多数也都不像给用户使用的产品那样友好,而且都有一些“坑”要踩。只有详细阅读文档,多尝试,相关技能才会有提高。
6.安全使用者
Linux的安全系统发展至今很全面,但是还远远不够。Linux系统距离一个安全的操作系统还有很长的路要走。一般情况下,系统安全和业务安全是被纳入运维工作范畴的。大企业会有专门的安全系统开发人员,但几乎很少有专门的安全运维人员。这是一个专用领域,虽然目前重视程度不太高,但是在Linux中安全系统是一个很大型的系统。
系统安全也分为两部分,一部分是外部利用系统机制带来的威胁;另一部分是系统级的安全机制本身。
外部利用系统机制的典型代表是Webshell、木马、病毒、Rootkit等,还有一些人为的安全问题,例如弱口令、缺少安全意识的服务配置和端口开放等。这些也都需要专门的技能进行检查,也有很多关于这方面可以使用的工具。
系统级的安全是不针对特定的攻击类型的系统提供的机制。例如UGO文件权限,对于进程的能力限制Capbilities;针对文件的,例如mount文件系统,在针对文件时指定ACL就可以针对文件进行访问控制,还有一些程序级的组件一般会随着操作系统提供,这些组件也有一些是与内核耦合的。例如内核的安全框架LSM,以及在LSM下实现的各种防火墙,实现Flask框架的Selinux和Apparmor。Syslog也属于内核提供的组件,可以用来做安全审计,但是其不是安全专用的组件。还有一些每个Linux发行版都会提供的基础应用组件,最常用的是PAM系统,PAM系统的显著特点是可以把进程的认证工作由程序员转交给系统管理员,从而使得安全控制也变成运维的一部分。我们最常见的安全使用者的工作是权限配置,chown,chmod、chattr、chacl等基础命令可以用来做权限配置。安全使用者更重要的工作是对系统不安全的地方打补丁,例如关注CVE和Patch,检测自己的系统在不在漏洞影响范围,然后打补丁。得益于Pam和Apparmor良好的配置系统,安全系统的配置大部分都可以直接写文本配置,而不是实际的安全编程。此外,Netlink可以查阅和修改更加详细的内核信息,audit系统可以进行程序的追踪,这两者也是十分有用的技能。内核级别的安全工作对技能的要求相对较高,我们会需要bpf或者是kprobe钩子,懂得内核的细节技术,熟悉ktap和常用的模块开发和内核的入侵手法以定向检测等。
7.内核使用者
内核的使用者多见于嵌入式开发和运维的内核升级。但是运维的内核升级一般涉及的功能裁剪较少,涉及的漏洞更新和功能增强较多。运维升级配置内核更重要的是使用诸如zram等升级特性,并且强调不用重启机器的热更新。而嵌入式到目前为止还是基本停留在2.6的内核版本系列,最近几年博通等上游厂商已经升级到了3.0之后的内核版本。这里必须强调的一点是嵌入式行业使用的内核版本一般取决于上游厂商下发的BSP(板级支持包)的版本,也就是说内核版本的迭代大部分由上游解决方案厂商控制。运维人员做内核是为了升级和定制内核功能,嵌入式做内核大部分是为了定制内核的细节。
很重要的一点是Linux内核从2.6.32版本之后,很难适用于低端的嵌入式系统。虽然内核仍声称为嵌入式应用做了诸多优化,但是业界的嵌入式开发基本停步在2.6版本的内核。你可以看到内核的新功能和增强基本都是为了互联网而产生的,而针对这样的内核进行嵌入式裁剪也越来越难,甚至要高版本的内核在嵌入式板子上跑起来这个基本的工作也越来越复杂。这也从侧面反映出了互联网的活力和嵌入式行业的守旧,也导致了嵌入式内核版本的升级权力被越来越多的掌握到职业做内核定制的上游厂商手里。
最基本的内核裁剪工作并不要求对内核是如何实现的内容有太多的了解,但是需要知道内核实现的那些功能有什么,为什么内核需要这些功能。例如裁剪中你得先选择net设备,然后net功能才是可选的,并且net功能里面的子功能非常多,一个看重Flash大小的嵌入式设备是不需要net功能下的大部分子功能的。内核的编译排版很重要的一点是按照功能的层级划分的,而不是按照功能的重要性划分的。比如你会发现无线系统里RFID、LED、业余无线电和Wi-Fi是平级的,但是大部分人是不会使用前三者的,大部分人只需要Wi-Fi。但是内核的编译选项的组织并没有针对这种需求上的流行程度进行优化。
所以一个内核裁剪者需要知道几乎所有内核选项的作用,最好多试试。内核的实现大部分为了通用性,对效率和安全的考量是非常少的。如果你深入内核的代码层次进行研究,你会发现内核的实现大部分在你深入使用的场景中,你会有更优的算法,你会想去重新实现。这里体现出的Linux内核的哲学就是:全面之后再求精。
所以内核会覆盖尽可能多的功能,但是大部分功能的实现都不是企业级的。例如,如果你的产品要支持打印机,你一般不会用内核内置的功能,而会购买更产品化的内核模块(例如Kcodes的打印机模块)。如果你的产品要支持Samba,你会发现内核对NTFS的支持是非常低效的(在用户侧实现),还是会购买商用的NTFS内核模块(商用的和开源的是同一个公司开发的)。当你多关注内核的发展时,就会发现开源发展得最好的模块一般是企业支持的,而在这背后一般都有商用版本存在。这就是内核的本质,出发点是开源的、共享的,发展是靠利益驱动的,繁荣则是完全靠商业的。
内核移植工作考验的大部分不是内核本身的技能,而是对GCC的了解程度,尤其是内核使用的Makefile系统。所以想要做好嵌入式内核的移植工作,编译系统和看一遍链接的spec是基本的要求。
开发者其实就是常说的程序员,而且一般是后端程序员。刚开始入门的程序员会更注重语法,只要是服务于实际线上业务的开发人员就有了解Linux的需求。不同种类的程序员的知识需求是不一样的。例如写业务代码的程序员,需要拥有架构能力和懂得编码标准;写高性能程序的程序员则需要拥有关于数学、算法和高性能编程的硬件相关的知识;写实时代码的程序员又是需要另外一套理论体系。编程的语法是基础,但编程的核心从来都不是语法。
选择了一门好的(计算机)语言,基本就能确定你要用它来做的事情。不存在“万金油”的语言,注重效率的和注重快速开发的、注重工程管理、注重描述问题的都不是同样的语言(当然你要用C语言做Web后台开发也可以),甚至还存在专门擅长处理字符串的语言。对于Linux来说,开发高性能代码一般就得是汇编,例如C和C++。需要兼顾性能和开发效率时可以用Golang,脚本化的语言也都可以用在Linux上,这取决于业务。但是为了工程的需要,例如当要求工程有快速性和易用性的需求时,Python、Erlang也经常被用来做后端开发。
工程编程最重要的是库和架构,即代码的复用。一个成熟的程序员和一个入门级的程序员的最大区别不在于语法的熟练程度,而在于他们具有的架构能力和库的复用能力。内核使用的C语言看起来很容易,但是能写好的程序员基本要工作好多年,否则写的程序不稳定,可能存在安全问题,或不可读等项目管理的问题。
所以Linux对于开发者来说,不存在编程语言和库上的障碍。难点基本上是在内核所提供的功能上,以及你如何使用这种功能(利用epoll、inotify等)。
1.桌面应用开发者
Linux下常见的桌面主要是KDE和Gnome。从Linux桌面市场的占有率来看,在Linux上面投资是不值得的,比如国内的常用软件也都很少会出一个Linux版本的。照目前看来,Gnome占市场份额变得越来越大的概率很大,不排除日后会有越来越多的厂商愿意为Ubuntu的Gnome桌面系统开发图形界面的应用。目前在Linux系统上的产品级的应用的图形界面一般使用Qt、Java(swing)等成熟的,可移植的图形库。
所以目前来看,如果你是桌面程序员(Android系统除外),你可能要用Java或者Qt的C++了,否则对于自身知识的积累可能会存在过时的风险。由于Android的App开发也是使用的Java,所以目前最划算的选择是用Java(企业应用市场对Java有强大的热情,因为它是最早普及的工业化的编码语言,但不代表它是目前最好的)。所以学习Linux桌面应用开发基本上就是学习这两款产品的相关知识。H5和javascript也在比较快速的发展,但是目前对于桌面级别的开发并没有形成太大的冲击。
2.使用成熟库的后端开发者
后端开发者占据了很大一部分开发岗位的就业比例,并且后端开发的难度可深可浅,但是变化速度不会太快。界面、网站等前端开发人数最多,变化最快,技术沉淀最难。几乎所有面向市场发布的程序都有后台服务器(单机程序是没有的),几乎所有的后台服务器都要存储数据。所以后台开发者要面对的核心开发点就是:网络使用、传输编码、数据存储、多线程编程和业务逻辑。所以做后端开发对自身的技术要求比较高,而目前的服务器几乎被Linux“一统江湖”了,这个趋势还会愈演愈烈。Windows Server在发达国家应用比较广,但是Linux的免费和越来越成熟的稳定性,加大了对其的竞争力度。
最近Golang在后端开发的流行度迅速崛起,但是人们在大部分大型系统中还是选择使用C语言/C++。使用Python做后台开发的情况也有很多,也可以选择用PHP来做,但是在业内比较少见。由于相对新的高级语言大部分使用自带的网络库,所以本节就不涉及Golang、Python等语言的网络编程方法。
网络传输问题:网络常用的C语言/C++后端库有原生的epoll、libevent、libev、boost::asio、ACE,ACE一般产业界用得较少。libev理论上比libevent高效,但是在实际使用时要视具体情况和使用者的使用方法。部分工业级的开发使用libevent或者原生的epoll相对较多,也有使用C++的boost::asio。但是这种情况比较少见,因为C++难度高,而目前的现象是大部分网络基础服务是使用C语言开发的。
传输编码问题:以前是直接使用自定义的格式或者自定义的Json,后面加压缩来作为传输消息的载体,后来发展出了序列化。再后来序列化进一步发展形成了ProtocolBuffer、Thrift、Avro等大公司主导的传输格式。目前网络传输数据用得相对多的是ProtocolBuffer,因为有谷歌的“背书”,Thrift也在强势崛起。Avro则刚刚起步,但是特性不俗。很多工程负责人喜欢成熟的可以直接使用的消息队列组件,但这些消息队列的下层也是要在传输的格式上进行不同的选择。
数据存储问题:MySQL数据库几乎是大小系统的第一选择。非常小的系统可能会使用Sqlite,涉及非IT大型企业可能用商用的数据库比较多,Nosql里Mongodb被选择的频率比较高,它也是最接近关系型数据库的,类似HBase、CouchDB等相对常见的非关系型数据库也都风靡一时。近年也出现了很多特定用途的Nosql数据库,一般在实际的线上工程中在选择上都会相对谨慎,即使被选数据库与我们的需求恰好相符。例如有专门存放图的数据库(ArangoDB),也有分级存储数据内容的(Rocksdb),还有存储地理信息的,等等。如果你是专业方向的开发者,可能这些(专门的)数据库更适合你,但是也得始终持有谨慎和怀疑态度。
多线程编程,在C语言/C++的世界里没有太多的选择,大部分情况下使用pthread,C++可以用boost::thread或者C++11的thread,其后台也是pthread。pthread在Linux平台基本可以说是目前在工程上的唯一选择。
所以使用程序库的开发者只需要了解库的用法。当然更希望他们了解库后台是如何调用操作系统,如何具体实现的。boost::filesystem的很多函数使用系统的函数也并没有太大的难度。事实上,我们总是可以使用lstat函数来替代boost::filesystem的一系列文件存在性和类型的判断函数。因此boost很多库确实有过度封装的嫌疑,尤其是你只需要一个特定的平台时,例如值在Linux下运行。使用boost有时还需要单独考虑libc_nonshared.a中对stat系列调用的定义。但是其封装的,例如remove_all等方便的遍历删除和path这种方便操作的类定义还是有比较大的价值的。即便如此,熟习底层的程序员仍然会选用ftw这种函数调用。
3.系统级后端开发者
如果你打算看看你的Linux发行版上已经安装的库是用来干什么的,例如libncurses、libnss、libfuse等,而这些库在你平时开发应用程序时都用不到,那么你要做的就是系统级的后端开发。系统开发与操作系统的关联很大,学习系统开发就是在学习操作系统。
在系统开发时对内核信息的获取要通过Proc、Sys和Netlink,这是一定要熟练掌握的。Proc相对容易,但是内容很多。Sys则比较庞杂,内容会比Proc更多。例如你得清楚地知道/proc/sys/kernel/core_pattern里面存的是Core Dump的路径;ulimit-c可以用来设置Core文件的大小,默认是0。这些基础的背景知识以及整个文件系统衍生出来的知识点是系统级后端开发的基础。常用到的Netlink都会有对应的上层封装,但是封装的质量可能不理想。例如rtnetlink这个最常用的子接口最好自己学会编写,但是如Audit系统的Netlink就可以直接使用libaudit。
这些常用的开发内容包括但不限于:FIFO文件、uevent、inotify、Netlink、nice、cpu亲和度、cgroup、虚拟化、ptrace进程跟踪、子进程创建和控制、信号处理、文件锁、向量化的读写文件、文件描述符操作、socket调用、epoll、文件与目录链接控制、锁、磁盘配额校验、进程记账、权限控制、运行优先级、低级端口操作、sg直接发SCSI命令、交换分区控制、pdflush和kswapd等内核进程的调优、模块的装载与卸载、mmap和brk的内存映射、cache操作、网络设备操作、用户管理、消息队列、信号量与共享内存等。
系统级后端开发直接是面向内核的使用,也就是系统级后端的开发者基本就是内核的合格使用者。
4.运维开发者
运维开发者比较接近于系统开发者,但是运维开发者比较多的情况是使用现有命令、脚本,着重于系统资源的监控和划分。现在流行的devops,例如ansible工具让运维与开发一气呵成。运维开发者首先是一个运维使用者,运维系统,例如全网监控系统、包发布系统、主机探测系统、域名系统等都是运维开发者的发展方向。一个运维开发者不做具体业务,也不是直接为具体业务服务的,他是让具体业务可以专注于具体业务的。
5.安全开发者
防御型的安全开发者有两种,一种是如何让自己开发的软件更安全;另一种是开发安全防护软件,例如病毒扫描、防火墙、入侵检测、漏洞管理、权限控制等。除了对安全使用者的技能的掌握外,还需要更深入地了解白帽子们的安全防护细节和原理。通常能“防”的人也能“攻”,不知道别人怎么攻就在防方面基本做不深入,攻防是互动进步的。但是目前国内的安全系统大多数是由专门做安全防御的人做,很可能他们根本没有做过实际的攻击。主要原因是国内的网络安全环境太好了,基本在做坏事的都是“脚本小子”或者使用工具进行攻击的人,拥有特别高攻击水平的黑客的确存在,但是目标也基本不会是一般的防御系统,并且他们的入侵对于小企业都是无感知的。
内核里有很多针对安全开发的特性提供:内核加密接口和秘钥环、ASLR(进程启动栈随机化)、LSM机制。做安全开发对系统本身的特性利用不大,对攻防手法的理解要求比较大,例如对ELF格式的深入理解就可以在二进制加固与破解领域大展身手。另外,防御系统一般是在业务系统的前面,所以要求低延时和高吞吐。所以基本上只能使用C语言/C++,很难想象前端过滤的防火墙用Python写是什么样。
所以安全开发的核心是业务和高效编程的能力。而高效编程,例如对DPDK、SSE指令集的使用就是一个专门的学科了,对业务上的要求就是需要掌握安全相关的知识点。安全编程更多的在于领域知识的掌握。相比于需要掌握的领域知识,学习Linux提供的安全机制是相对简单的。
6.应用后台开发者
对于大部分应用后台的要求有两个:开发快,问题少。所以现在的市面上你会见到很多用Golang、Python、Java做后台开发的案例。这种形式的后台开发基本与操作系统无关,懂得基本的Linux系统的使用即可,人们可以专注地面向业务。
7.内核开发者
对于内核开发者的技术要求是最高的,如果谁提交了一个Patch被内核接受了,那是很了不起的事情。因为内核本身进展就非常大,并且内核开发在市场上没有对应职业。最多的相关职业是驱动开发和内核裁剪小修改,另外文件系统开发和网络开发也涉及一些内核开发。由于内核的庞杂和耦合性比较重,学习本身就很难了,更别说开发了。
但是内核开发入手是相对很简单的,只是在实际的环境中缺少对应的职位,并且即使存在内核开发的需求也是使用的很老的内核版本进行稳定性开发,几乎没有机会可以去写一个新的机制。实际的内核开发的门槛是相对很高的。这里的开发者有的是开发内核机制的;有的是开发驱动的;有的是开发文件系统的,针对不同的开发有不同的知识侧重点。
驱动开发对uevent、kobject系统的了解需求比较多,明白udev程序和dev目录的工作原理、设备号的管理、基本的内存申请和使用。进阶的学习可以了解内核端socket编程、进程的控制等。内核驱动的编程最主要的还是业务逻辑,要知道你控制的设备的寄存器和对应的总线在内核中的逻辑,例如所有磁盘都使用SCSI命令,都要经过SCSI层。这时对SCSI的了解就显得比较重要了。
由于一切皆文件的思想,所以文件在Linux中特别重要。如果想要创建虚拟的设备,得学会利用/dev目录下的设备,重要的是你得学会使用fd文件句柄。这个fd就是简单的C语言里面open一个文件之后生成的返回值,但也是socket()调用之后生成的返回值,这个fd的值是内核分配的,你不能设置打开资源的请求获得的fd的值,但是可以推测。由于是系统资源,所以fd实际上是跨进程的,但是例如socket生成的handler,虽然是系统资源,但是其他进程就不能直接使用,因为这个系统资源有个所有者的概念,这个所有者就是创建它的进程。像0、1、2号的fd就是输入输出和错误,这个fd是在proc文件系统下可以看到的。由于子进程可以得到父进程的所有fd,所以通过shell其实可以做好多事情。例如常用的exec命令就是利用fd的典型方法。如图1-1和图1-2所示。
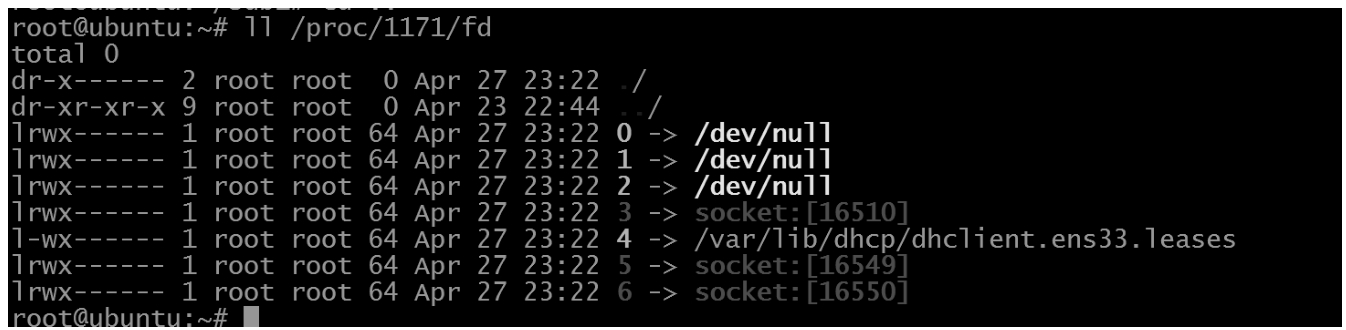
图1-1
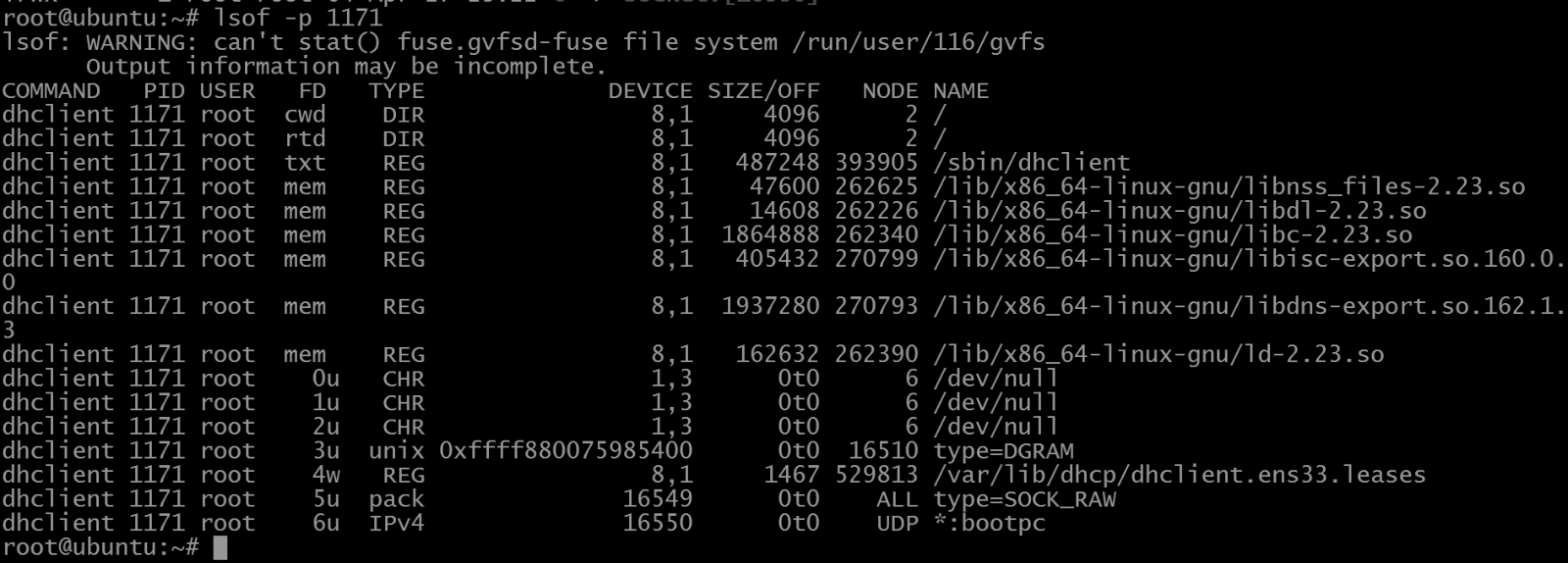
图1-2
这个文件列表比较典型,fd既有设备的映射,也有socket的映射,也有文件的映射。可以发现,如果不希望使用输入输出,典型的是不希望看到输出,这里的1号和2号fd就可以被重定向到/dev/null设备文件中。例如你可以使用Shell命令exec 1>outfile,就可以直接把当前打开的shell的输出重定向到outfile文件中,这种方法用于脚本中重定向当前脚本的fd。
内核中文件系统的开发,必须得了解文件使用的整个流程,一切皆文件的思想使得最上面的接口必然是VFS层,往下还有通用块层(在这里要进行重要的电梯算法)、SCSI层,要把对逻辑文件的访问变为对物理存储访问的命令,还要经过PCI层,如果是USB设备还要经过USB层。逻辑最终成真总要经过物理设备,所以了解物理协议的实现也是必要的。
内核中提供了很多默认的文件系统操作,很多实现的文件系统都直接使用默认的实现。有一类重要的文件系统是Fuse,文件系统驱动可以使用这个机制在用户端实现,像个普通的应用程序一样。这是内核为版权保护做的折中让步。内核现在越来越倾向于把功能让给用户空间,大内核的思想在收缩。
文件系统一般可以以模块的方式提供,可以很简单也可以很复杂。所以文件系统开发对内核的了解与其他的内核功能开发差别不大,但是对文件系统本身有比较高的知识储备要求。例如完整性校验、Extends大块、磁盘配额、磁盘访问控制ACL、热插播、B+树等。
8.网络开发者
Linux内核本身的网络协议栈相对低效(比如对比6WIND),但是可以应付绝大多数的使用情况。希望使用内核原生的协议栈做动作修改的用户,一般是使用Netfilter的Hook。我们可以使用内核的模块做很多事情,但是对内核代码本身的修改在工程中是不建议的。具体做安全还是包变换,很多时候Netfilter的Iptable本身就可以做,BPF更是提供了可编程的规则,所以内核层面的网络开发核心是Netfilter。
对于有高性能网络数据处理要求的情况,有新浪的Fastsocket和Intel的DPDK这两种常用的协议栈可以供选择。Fastsocket目前对长连接的支持说不上完善,但是Nginx这种短连接应用会从中收益良多。DPDK没有socket的概念,是纯粹的包处理,而且是在用户空间,完美地支持多CPU和NUMA系统。所以可以看到阿里、腾讯、谷歌、百度等都有用DPDK来做的数据包处理。
网络开发对于开发者的要求也大多数是业务算法上的,也不是内核的实现上。DPDK几乎是完全绕过了内核的网络实现,使用单独的接口(除了与内核的网络桥接KNI设备)。