
下载掌阅APP,畅读海量书库
立即打开




change buffer的主要目的是将对二级索引的数据操作缓存下来,以减少二级索引的随机I/O,并达到操作合并的效果。
工作原理是有一个或多个非聚集索引,且该索引不是表的唯一索引时,插入时数据会按主键顺序存放,但叶子节点需要离散地访问非聚集索引页,插入性能会降低;此时,插入缓冲生效,先判断非聚集索引页是否在缓冲池中,若在则直接插入;若不在,则先放入一个插入缓冲区,再以一定的频率执行插入缓冲和非聚集索引页子节点的合并操作。在MySQL 5.5之前的版本中,由于只支持缓冲insert操作,因此最初叫作insert buffer;后来的版本中支持了更多的操作类型缓冲,所以才改叫change buffer。
如图2-5所示,将对索引的更新记录存入insert buffer中,而不是直接调入索引页进行更新;择机进行merge insert buffer的操作,将insert buffer中的记录合并(merge)到真正的辅助索引中,大大提高了插入的性能。
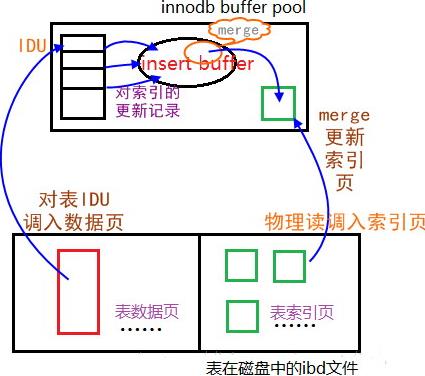
图2-5
二级索引通常是非唯一的,插入也是很随机的顺序,更新删除也都不是在邻近的位置,所以change buffer就避免了很多随机I/O的产生,将多次操作尽量变为少量的I/O操作。change buffer也是可以持久化的,将change buffer中的操作应用到原数据页、得到最新结果的过程称为merge。
change buffer合并在有大量的二级索引页更新或有很多影响行的情况下会花费很长的时间。注意,change buffer会占用InnoDB Buffer Pool的部分空间,在磁盘上change buffer会占用共享表空间,所以在数据库重启后,索引变更仍然被缓存。
如图2-6所示,参数innodb_change_buffering表示缓存所对应的操作,all值表示缓存insert、delete、purges操作;innodb_change_buffer_max_size参数用于配置change buffer在Buffer Pool中所占的最大百分比,默认是25%,最大可以设置为50%。
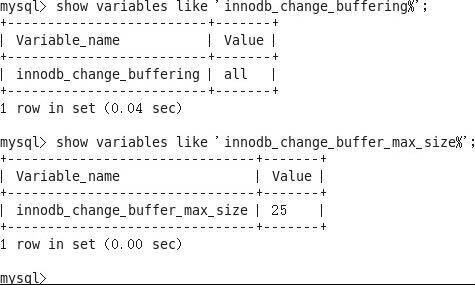
图2-6
可以在show engine innodb status\G命令结果中查看change buffer的信息。在insert buffer and adaptive hash index部分中,merged operations代表了辅助索引页与change buffer的合并操作次数。使用下面的语句也能监控:
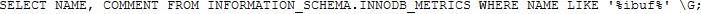
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好,常见的就是账单类、日志类的系统。