
下载掌阅APP,畅读海量书库
立即打开



前文介绍过的资产扫描和漏洞扫描主要面向的是硬件和软件资产,而网站扫描针对的对象则是以网站应用为主,它相当于对企业的网站业务进行黑盒扫描。当然,如果需要的话,代码扫描可以对网站应用进行代码级的白盒扫描。与资产扫描、漏洞扫描不同的是,网站扫描虽然也属于漏洞扫描的一种,但它关心的是由企业开发人员在编程过程中引发的漏洞,或者是由于业务逻辑设计不合理而产生的漏洞。
由于是针对网站应用进行的扫描,所以利用爬虫遍历网站中的所有页面就变得必不可少了。在网站扫描领域,利用爬虫主要是希望对网站的资产能够进行全面了解和梳理,因为在多数情况下,我们并不需要把网站的页面内容抓取下来,只要能够遍历所有的页面即可。
在网页遍历过程的某些场景下,还需要进行登录扫描,主要是因为在企业网站中,有些页面只有在成功登录后才能访问到。常见的网站登录扫描方式有两种,一种是把在登录页面中需要填写提交的内容记录下来,然后模拟登录过程,另一种是把登录后的Cookie提取出来,用作登录凭证。
有关爬虫技术的相关文档及自动化的工具大家可以自行了解,此处不再赘述。下面提供一个简单的爬虫。
import java.io.IOException;
import java.net.SocketTimeoutException;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.UnknownHostException;
import java.util.ArrayList;
import org.jsoup.HttpStatusException;
import org.jsoup.Jsoup;
import org.jsoup.UnsupportedMimeTypeException;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawler {
static String initial_uri_string = "http://news.sina.com.cn";
static String domain = "sina.com.cn";
public static void main(String[] args) {
URI newURI;
URI baseURI = null;
int index = 0;
String uriString;
ArrayList<String> uriStringAL = new ArrayList<String>();
uriStringAL.add(initial_uri_string);
do {
uriString = uriStringAL.get(index++);
System.out.println("(" + index + "/" + uriStringAL.size() + ") Crawling " + uriString + " ... ");
try {
baseURI = new URI(uriString);
Document doc = Jsoup.connect(uriString).userAgent("Mozilla/5.0").get();
Elements es = doc.getElementsByTag("a");
for (Element e:es) {
newURI = baseURI.resolve(e.attr("href"));
if (newURI.getHost().endsWith(domain)) {
if (!uriStringAL.contains(newURI.toString()) && !newURI.toString().isEmpty()) {
uriStringAL.add(newURI.toString());
}
}
}
} catch (SocketTimeoutException e) {
System.out.println("SocketTimeoutException");
} catch (UnknownHostException e) {
System.out.println("UnknownHostException");
} catch (IllegalArgumentException e) {
System.out.println("IllegalArgumentException");
} catch (HttpStatusException e) {
System.out.println("HttpStatusException");
} catch (UnsupportedMimeTypeException e) {
System.out.println("UnsupportedMimeTypeException");
} catch (IOException e) {
System.out.println("IOException");
} catch (URISyntaxException e) {
System.out.println("URISyntaxException");
} catch (NullPointerException e) {
System.out.println("NullPointerException");
}
} while (uriStringAL.size() > index);
}
}
2017年的OWASP Top 10报告( https://owasp.org/www-project-top-ten )中,列举了针对Web应用的十大安全风险,如下所示。有关OWASP的具体内容会在后面的章节中进行详细介绍。
·A1:Injection。
·A2:Broken Authentication。
·A3:Sensitive Data Exposure。
·A4:XML External Entities(XXE)。
·A5:Broken Access Control。
·A6:Security Misconfiguration。
·A7:Cross-Site Scripting(XSS)。
·A8:Insecure Deserialization。
·A9:Using Components with Known Vulnerabilities。
·A10:Insufficient Logging and Monitoring。
如图1-4所示,在网站扫描过程中,首先要利用爬虫技术对企业的Web应用进行一个全面的了解,相当于对网站应用做了一次全面的资产扫描。其次,再对网站的所有页面进行有针对性的漏洞扫描,这里所说的漏洞包括了Web应用中常见的各种漏洞类型,例如SQL Injection、Cross-Site Scripting(XSS)、XML External Entities(XXE)等。网站应用中是否存在漏洞?漏洞在哪里?漏洞能不能被利用?这些问题都是网站扫描需要回答的,也是网站扫描需要解决的问题。
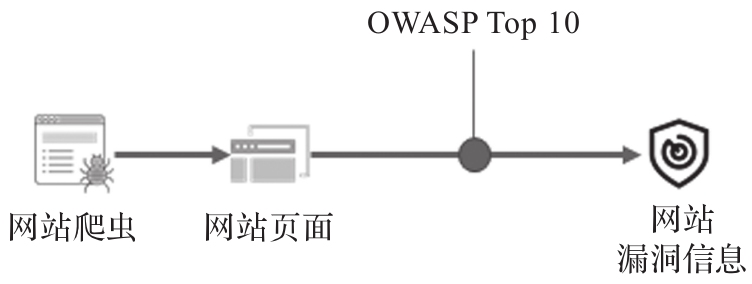
图1-4 网站漏洞扫描过程