
下载掌阅APP,畅读海量书库
立即打开



最初,结构化分析方法仅讨论数据流建模,目标系统被表示成如图2.10所示的数据流程图。系统的功能体现在核心的数据变换中,系统的输入源于用方框表示的外部实体,这种输入引发系统的数据变换,产生传递给外部实体的输出。
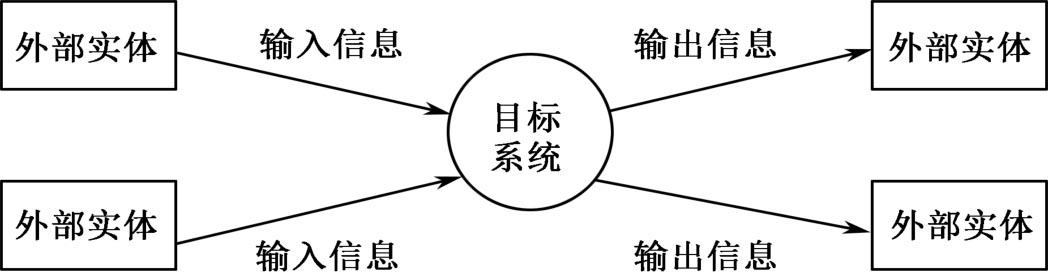
图2.10 数据流程图
功能建模的思想就是用抽象模型的概念,按照软件内部数据传递、变换的关系,自顶向下逐层分解,直到找到满足功能要求的所有可实现的软件为止。根据DeMarco的论述,功能模型使用了数据流程图来表达系统内数据的运动情况,而数据流的变换则用结构化语言、判定表与判定树来描述。
1.数据流程图
结构化分析的核心部分是数据流程图(Data Flow Diagram,DFD)。数据流程图是一种用来表示信息流程和信息变换过程的图解方法,它把系统看成由数据流联系的各种功能的组合。在需求分析中用它来建立现存或目标系统的数据处理模型,当数据流程图用于软件需求分析时,这些处理或转换,在最终生成的程序中将是若干个程序功能模块。图 2.11 所示为会计账务处理系统的数据流程图。
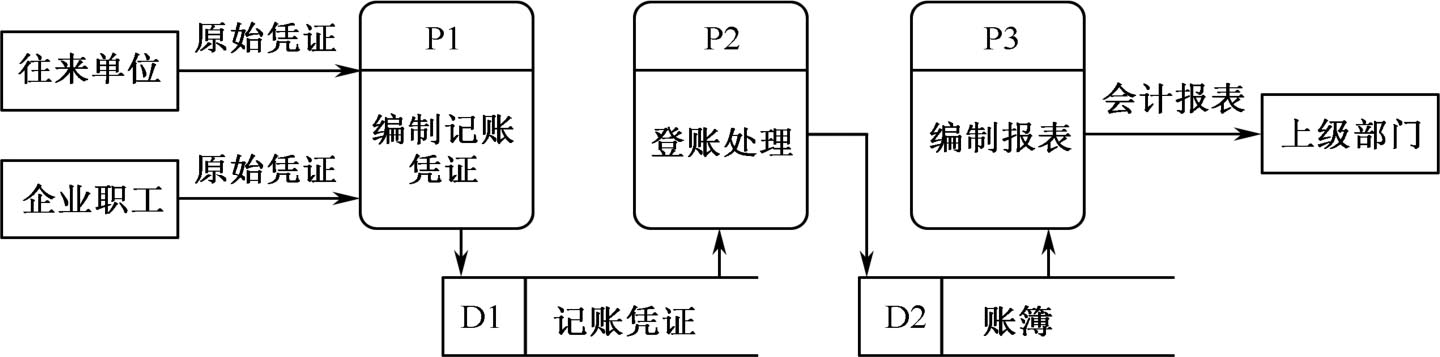
图2.11 会计账务处理系统的数据流程图
数据流程图包括 4 种基本成分,分别用 4 种基本符号表示,如图 2.12所示。
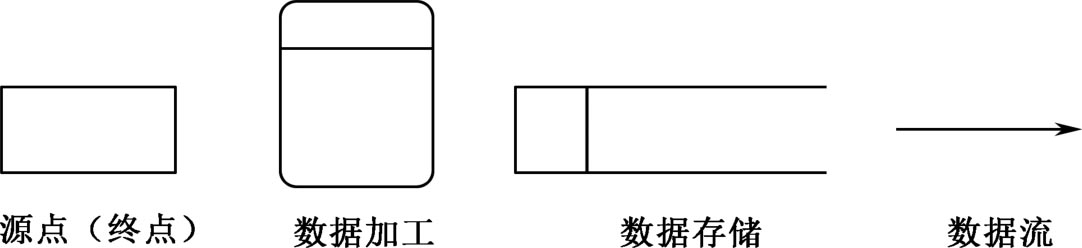
图2.12 数据流程图的基本符号
从图2.11可以看出数据流有原始凭证、会计报表、记账凭证、账簿等。数据存储包括记账凭证和账簿信息。加工处理有编制记账凭证、登账处理和编制报表。而源点和终点则是往来单位、企业职工和上级部门。
(1)数据流。数据流是描绘数据流程图中各种成分的接口。数据流的方向可以从加工流向加工;从加工流向数据存储;从数据存储流向加工;从源点流向加工或从加工流向终点。数据流的含义如下:
① 数据流是一组成分已知的信息包。信息包中可以有一个或多个已知信息。
② 两个加工间可以有多个数据流,当数据流之间毫无关系,也不是同时流出时,如果强制合成一个数据流,则会使问题更为含糊不清。
③ 数据流应有良好的名字,它不仅作为数据的标识,而且有利于深化对系统的认识,便于进一步了解系统。
④ 同一数据流可以流向不同的加工,不同的加工可以流出相同的流(合并与分解)。
⑤ 流入或流出到存储的数据流不需要命名,因为数据存储的名字已经有足够的信息来表达数据流的意义。
⑥ 数据流不代表控制流。数据流反映了处理的对象,控制流是一种用来选择或影响加工的性质,而不是对它进行加工的对象。
(2)数据加工。数据加工是对数据执行某种操作或变换,是把输入数据变成输出数据流的一种变换。每个加工应有一个名字来概括、代表它的意义。(3)数据存储。数据存储并不等同于一个文件,它可以表示文件、文件的一部分、数据库的元素或记录的一部分等。数据可以存储在磁盘、磁带、存储器和其他介质上。应该认真对数据文件进行命名。在数据流程图中,要注意指向数据文件箭头的方向,读数据的箭头是指向加工处理的;写数据的箭头是指向数据存储的;如果既有读又有写,则是双向箭头。
(4)源点和终点。源点和终点代表系统之外的人、物或组织。它们发出或接收系统的数据,使用起来不严格,其作用是提供系统和外界环境之间关系的注释性说明。一般来说,表示一个系统只要有数据流、加工和文件就够了。但是为了有助于理解,有时可以加上数据流的源点和终点,以此说明数据的来龙去脉,使数据流程图更加清晰。而源与源之间的关系则不予考虑。
画数据流程图的方法是:首先识别出主要输入、输出;然后从输入向输出推进,找出通道上的主要变换。在大多数情况下,原则上是由外向里、自顶向下去模拟问题的处理过程,通过一系列的分解步骤,逐步求精地表达出整个系统功能的内部关系。
画数据流程图的步骤如下:
步骤1 在图的边缘标出系统的输入、输出数据流,从而决定研究的内容和系统的范围。
步骤2 画出数据流程图的内部。将系统的输入、输出用一系列处理连接起来,可以从输入数据流画向输出数据流,或从中间画出。
步骤3 仔细为数据流命名。
步骤4 根据加工的输入、输出内容,为加工命名——“动词+宾语”。
步骤5 不考虑初始化和终点,暂不考虑出错路径等细节,不画控制流和控制信息。
步骤6 反复与检查。思维过程是一种迭代的过程。
应该指出,在需求分析阶段中的数据处理并不一定是一个程序或程序模块,而是反映了系统的功能。如何实现,就要考虑在一定约束条件下软件设计方案的选择和编程问题。另外,它除了代表计算机处理过程,还可以代表人工处理过程,如由专业人员对输入的数据进行正确性检查等。类似地,一个数据的存储也不一定代表一个实际文件,实际数据可以存储在包括人脑在内的任何介质上。
2.分层数据流程图
为了表达数据处理过程的数据加工情况,用一个数据流程图是不够的。稍为复杂的实际问题,在数据流程图上常常出现十几个甚至几十个加工。这样的数据流程图看起来很不清楚,层次结构的数据流程图能很好地解决这一问题。按照系统的层次结构进行逐步分解,并以分层的数据流程图反映这种结构关系,能清楚地表达和理解整个系统。
图2.13为分层数据流程图示例,数据处理 S 包括3个子系统1、2、3。顶层下面的第 1 层数据流程图为 DFD/L1,第 2 层数据流程图 DFD/L2.1、DFD/L2.2及DFD/L2.3分别是子系统1、2和3的细化。对任何一层数据流程图来说,我们称它的上层图为父图,在它下一层的图则称为子图。
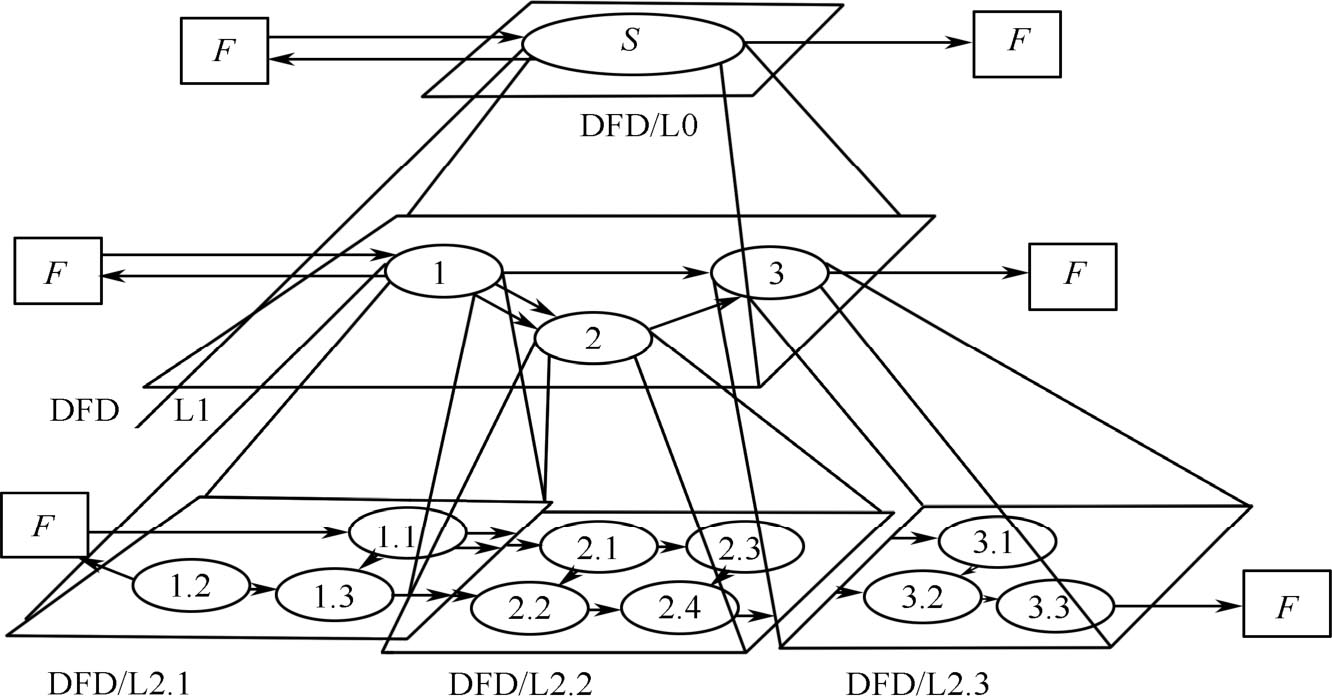
图2.13 分层数据流程图示例
在多层数据流程图中,需要区分顶层流图、底层流图和中间层流图。顶层流图仅包含一个加工,它代表被开发系统。它的输入流是该系统的输入数据,输出流是系统的输出数据。顶层流图的作用在于表明被开发系统的范围,以及它和周围环境的数据交换关系,为逐层分解打下基础。底层流图是指其加工不需要再做分解的数据流程图,它处在最底层,有时也称其加工为原子加工。中间层流图则表示对其上层父图的细化,它的每个加工可能继续细化,形成子图,中间层的多少视系统的复杂程度而定。
画数据流程图的基本步骤概括地说,就是自外向内,自顶向下,逐层细化,完善求精:
(1)首先确定系统的输入和输出,以反映系统与外界环境的接口。
(2)第0层数据流程图将软件系统描述为一个加工,以反映最主要的业务处理流程,它代表系统本身。但它并未明确表达数据加工的要求,需要进一步细化。
(3)从输入端开始,根据系统业务工作流程,画出数据流流经的各加工框,以反映数据的实际处理过程,逐步画到输出端,得到第1层数据流程图。图中的加工分别编号。
(4)细分每个加工框。如果加工框内还有数据流,可将这个加工框再细分成几个子加工框,并在各子加工框之间画出数据流。
(5)一次细化一个加工。数据流程图的细化可以连续进行,直到每个加工只执行一个简单操作为止。就是说,直到每个加工执行一个可以用程序实现的功能为止。
检查和修改数据流程图的原则如下:
(1)数据流程图上所有图形符号只限于前述4种基本图形元素。
(2)顶层数据流程图必须包括前述4种基本元素,缺一不可。
(3)顶层数据流程图上的数据流必须封闭在外部实体之间。
(4)每个加工至少有一个输入数据流和一个输出数据流。
(5)在数据流程图中,需要按层给加工框编号。编号表明该加工处在哪一层,以及上下层父图与子图的对应关系。
(6)规定任何一个数据流子图必须与它上一层的一个加工对应,两者的输入数据流和输出数据流必须一致,此即父图与子图的平衡。
(7)可以在数据流程图中加入物质流,帮助用户理解数据流程图。
(8)图上每个元素都必须有名字。数据流和数据文件的名字应当是名词或名词性短语,表明流动的数据是什么。加工的名字应当是名词+宾语,表明做什么事情。
(9)数据流程图中不可夹带控制流,整个图不反映加工的执行顺序。
(10)初画时可以忽略琐碎的细节,以集中精力于主要数据流。
父图与子图的平衡是分层数据流程图中的重要性质,它保证了数据流程图的一致性,避免分析出错,也便于分析人员阅读和理解。特别地,当某一层数据流程图中的数据存储对象不是父图相应加工的数据接口,而只是本层数据流程图中某些加工之间的数据接口时,这样的数据存储应是局部数据存储。只有当局部数据存储作为某些数据加工之间的数据接口或某个特定加工的输入/输出时,才把它画出来,这样做有利于实现信息隐蔽。
3.加工规格说明
加工规格说明用来说明DFD中数据加工的加工细节。加工规格说明描述了数据加工的输入、实现加工的算法及产生的输出。另外,加工规格说明指明了加工(功能)的约束和限制、与加工相关的性能要求,以及影响加工实现方式的设计约束。必须注意,写加工规格说明的主要目的是要表达“做什么”,而不是“怎么做”。因此它应描述数据加工实现加工的策略而不是实现加工的细节。目前用于写加工规格说明的工具有程序设计语言、判定表和判定树。
1)程序设计语言
程序设计语言(Program Design Language,PDL)也称为结构化语言,它是一种介于自然语言和形式化语言之间的半形式化语言。它是在自然语言基础上加了一些限制而得到的语言,它使用有限的词汇和有限的语句来描述加工逻辑。一般来说,对于顺序执行和循环执行的动作,用结构化语言描述;对于存在多个条件复杂组合的判断问题,用判定表和判定树。
结构化语言的结构分为外层和内层,外层用来描述语言正文。它将语言正文用基本控制结构进行分割,基本控制结构包括简单陈述句结构、判定结构(IF_THEN_ELSE_ENDIF或CASE_OF_ENDCASE)和重复结构(WHILE_DO或REPEAT_UNTIL)3种。
内层一般采用祈使语句的自然语言短语,使用数据词典中定义的名字和有限的自定义词。其动词含义要具体,尽量不用形容词和副词来修饰,还可以使用一些简单的算术运算和逻辑运算符号。
此外在书写时,必须按层次横向向右移行,续行也同样向右移行,对齐。下面是某商店业务处理系统中“检查发货单”的例子。
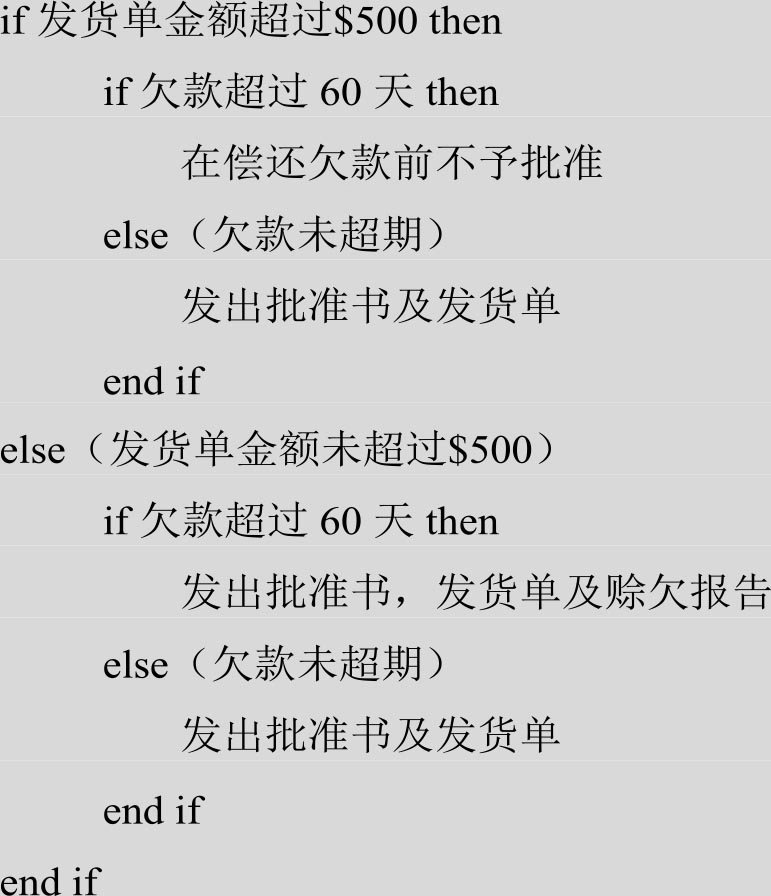
2)判定表(Decision Table)
在某些问题中,数据流程图中某个加工的一组动作依赖于多个逻辑条件的取值,就是说完成这一加工的一组动作是由于某一组条件取值的组合引发的。这时使用判定表来描述比较合适,它可以清楚地表示复杂的条件组合与应做动作之间的对应关系。
下面以检查发货单为例,说明判定表的构成,如图2.14所示。
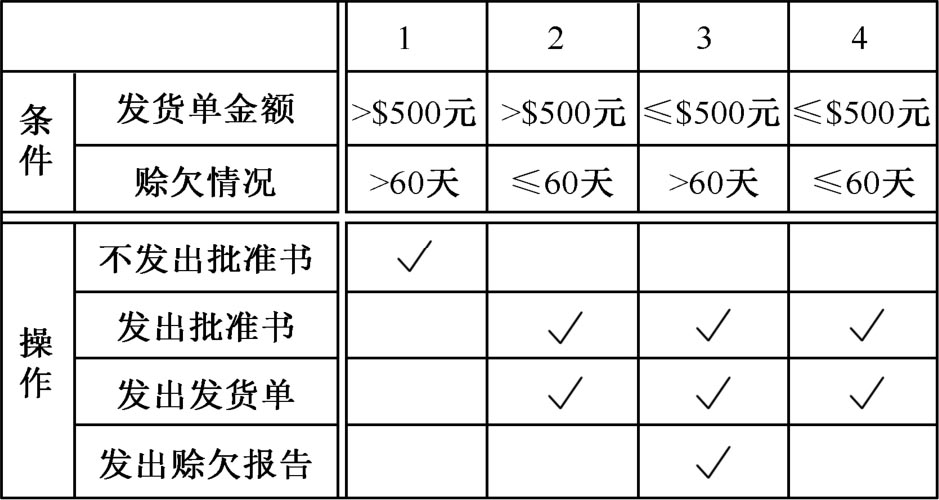
图2.14 检查发货单的判定表图
判定表由4个部分组成,如图2.15所示。双线分割开的4个部分是条件茬、动作茬、动作项和条件项。
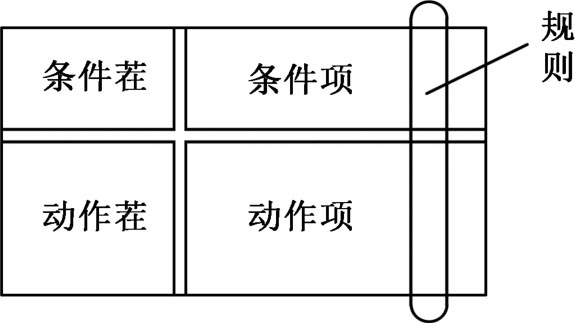
图2.15 判定表的结构
(1)条件茬。条件茬部分列出了各种可能的条件。除去某些问题中对各条件的先后次序有特定要求外,通常判定表中条件茬所列条件的先后次序无关紧要。条件项是针对各种条件给出的多组条件取值的组合。
(2)动作茬。动作茬列出了可能采取的动作。这些动作的排列顺序并没有什么约束,但为便于阅读也可令其按适当的顺序排列。
(3)动作项和条件项。动作项和条件项紧密相关,它指出了在条件项各组取值的组合情况下应采取的动作。
任一条件取值组合及其要执行的相应动作称为规则,它在判定表中是纵向贯穿条件项和动作项的一列。显然,判定表中列出了多少个条件取值的组合,也就有多少条规则,即条件项与动作项有多少列。
3)判定树(Decision Tree)
判定树也是用来表达加工逻辑的一种工具,有时候它比判定表更直观。用它来描述加工,很容易为用户接受。下面把前面的检查发货单的例子用判定树表示,如图2.16所示。

图2.16 判定树
在表达一个基本加工逻辑时,结构化语言、判定表和判定树常常被交叉使用,互相补充。这3种手段各有优缺点。从易学易懂的角度看,判定树最易学,易懂;结构化语言次之;判定表较难懂。判定表最易进行逻辑验证,因它考虑了全部可能的情况,逻辑清晰,能够澄清疑问;结构化语言次之;判定树较难验证。判定树的表达是直观的图形表示,一目了然,易于同用户讨论;结构化语言次之;判定表则不够直观。作为文档,结构化语言较好表达;判定表次之;判定树居后。从可修改的角度看,结构化语言较易修改;判定树次之;判定表较难修改。
没有一种统一的方法来构造判定树,也不可能有统一的方法,因为它是以用结构化语言,甚至是自然语言写成的叙述文作为构造树的原始依据的,但还是可以从中找出一些规律。首先,应从文字资料中分清哪些是判定条件,哪些是判定做出的结论。例如,在上面的例子中,判定条件是“金额>$500,欠款≤60 天的发货单”,要判定的结论是“发出批准书和发货单”。然后,从资料叙述中的一些连接词(如除非、然而、但、并且、和、或……)中,找出判定条件的从属关系、并列关系、选择关系等。
通过对以上情况的分析,可知对于不太复杂的判定条件,或者使用判定表有困难时,使用判定树较好。而在一个加工逻辑中,如同时存在顺序、判断和循环时,使用结构化语言较好。而对于复杂的判定,组合条件较多,则使用判定表较好。
总之,加工逻辑说明是结构化分析方法的组成部分,对每个加工都要加以说明。使用的手段,应当以结构化语言为主,对存在判断问题的加工逻辑,可辅之以判定表和判定树。