
下载掌阅APP,畅读海量书库
立即打开




如果我是你的老板,你对我说,我的脑子简直跟海参没什么两样,我会因为你侮辱我而炒掉你,还是会因你证明了自己真正理解人类怎样思考和行为而把你提拔成营销部门的头头?
如果我说,不管你对人类的形成秉持什么样的信仰,有一件事得到了一次次的验证,那就是人类的学习方式的确非常像海参(海参只有两万个神经元),你怎么想?倘若我再进一步说,我们的学习模式甚至类似原生动物这样的单细胞生物,你又会怎么想呢?
我的意思是说,单细胞生物具有简单的二元生存机制:冲向营养,远离毒素。事实证明,海参拥有目前已知最基本的一种神经系统,利用同一套二选一的方法来留下记忆。2000年,埃里克·坎德尔因为这一发现获得诺贝尔生理学或医学奖。那么,我们是怎么样的呢?
倒不是说可以把我们人类简化成海参。然而,有没有可能,我们并未完全摆脱祖先进化的影响,我们的的确确从“低级”生物体继承了许多行为取向呢?我们的一些(或者说很多)行为能不能归因于“接近富有吸引力或令人愉悦的东西,躲避讨厌或不快的东西”这一深植的模式呢?如果是这样,这一类知识能否帮助我们改变个人日常习惯模式,比如单纯的怪癖,或是根深蒂固的瘾头呢?说不定,我们还能找到一种自己与他人建立关联的新方式,超越上述的生物本能。
一旦迷上手机里最新的电子游戏,或是自己最喜欢的冰激凌口味,人就进入了目前科学已知进化上最为保守的一种学习过程,这一学习过程,存在于无数物种身上,可追溯到人所知最为基本的神经系统。基本上,这种基于奖励的学习过程是这样的:我们看见某种看起来还挺不错的食物。我们的大脑说,卡路里,生存的必需品!我们就把食物吃了。我们品尝它,它味道好(尤其是在吃糖的时候),身体向大脑发出信号:记住你吃的东西,记住你是从哪儿找到它的。我们根据经验和地点(术语叫作“情境依赖记忆”)保留这一记忆,学会下一次重复此过程:看到食物,吃掉食物,感觉不错,重复。触发因素,行为,奖励。很简单,对吧?
过了一会儿,我们富有创造力的大脑说:嘿!你不光可以用它来记住食物在哪里。碰到下一次你感觉不好,何不吃点好吃的,让自己感觉好起来呢?我们感谢大脑冒出的这个好主意,并且很快学习到,如果在生气或悲伤的时候吃冰激凌或巧克力,真的会感到好很多。这是相同的学习过程,但使用了不同的触发因素:不是来自胃部的饥饿信号,而是情绪信号(感觉不好)触发了吃的冲动。
又或者,我们在青春期的时候,看到叛逆的孩子在学校外抽烟,样子很酷,我们想,嘿,我也想要那样,于是我们开始抽烟。看到酷,抽烟酷,感觉好,重复。触发因素,行为,奖励。每当我们执行该行为,都会强化大脑的这一通路,它说:棒极了,再来一次。于是我们照做,它变成了习惯。习惯形成循环。
后来,感觉压力太大,触发了吃甜食或抽烟的冲动。依靠相同的大脑机制,我们从学习生存,过渡到了用这些习惯“自杀”——字面意义,不折不扣。肥胖和吸烟是全世界疾病、死亡的头号可预防原因。
我们是怎么被这团乱麻给缠住的?
19世纪晚期,一位名叫爱德华·桑代克(Edward Thorndike)的绅士发表了对这种“触发因素—行为—奖励”习惯循环的最早描述。
 他懊恼于一种十分奇怪的现象(这类故事简直无穷无尽):迷路的狗,总能一次次地找到回家的路。桑代克认为,通常的解释缺乏科学严谨性,便着手研究动物怎样学习的细节。他在一篇题为《动物智力》(Animal Intelligence)的文章中向同事们表示质疑:“大部分这些书并未向我们解释动物的心理,而是对它们唱赞歌。”他断言,当时的科学家“只看到聪明和反常,却忽视了愚蠢和正常”。他说的“正常”,指的是日常生活中可以观察到的正常习得联想(不光见于狗,也见于人类)。比如,早晨听到前廊上轻微的玻璃碰撞声,就联想到了当天送牛奶来的工人。
他懊恼于一种十分奇怪的现象(这类故事简直无穷无尽):迷路的狗,总能一次次地找到回家的路。桑代克认为,通常的解释缺乏科学严谨性,便着手研究动物怎样学习的细节。他在一篇题为《动物智力》(Animal Intelligence)的文章中向同事们表示质疑:“大部分这些书并未向我们解释动物的心理,而是对它们唱赞歌。”他断言,当时的科学家“只看到聪明和反常,却忽视了愚蠢和正常”。他说的“正常”,指的是日常生活中可以观察到的正常习得联想(不光见于狗,也见于人类)。比如,早晨听到前廊上轻微的玻璃碰撞声,就联想到了当天送牛奶来的工人。
为着手填补这一空白,桑代克把狗、猫和小鸡(小鸡似乎不大成功)关在各种笼子里,不给它们东西吃。笼子里装有不同类型的简单逃生机制,例如“拉绳子、压杠杆、站到平台上”。一旦笼子里的动物逃跑成功,就会得到食物。他记录动物怎样成功地逃脱,以及花了多长时间。接着,他一遍又一遍地重复该实验,记下各类动物学会将特定行为与逃脱、食物挂钩需要尝试多少次。桑代克说:“一旦联系完美建立,逃跑所需时间就几乎不会变,而且非常短。”
桑代克表明,动物可以学习简单的行为(拉动一条绳子)来获得奖励(食物)。他琢磨出了奖励式学习!有必要指出,他的方法弱化了观察者的影响,以及其他可能混淆实验的因素。他总结说:“故此,一名研究员所做的工作,另一名研究员应该可以重复、验证或修正。”这就把该领域从描写出人意料的故事(神奇的小狗做了某件事),带到了我们怎样训练所有的狗(或者猫、鸟和大象)做甲事、乙事或丙事。
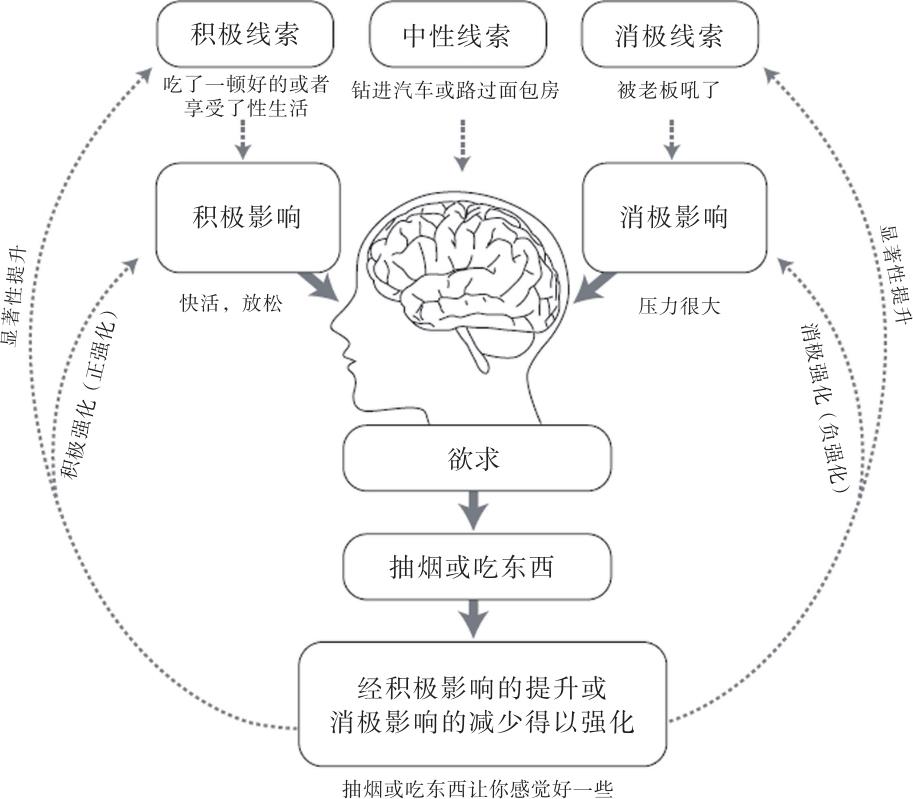
奖励式学习。Copyright © Judson Brewer, 2014.
21世纪中期,斯金纳对鸽子和老鼠做了一系列实验,精心测量了动物对单一条件变化(如室内颜色的变化,这种环境日后称为“斯金纳箱”)的反应,巩固了上述观察。
比方说,只要给一只动物在黑色小屋里喂食,在白色小屋里施加小幅电击,就可以轻松地训练它偏好前者多于后者。他和其他科学家扩大了这些研究结果,表明动物接受训练执行某一行为,不光是为了获取奖励,也是为了避免惩罚。这些接近和回避行为很快就得名为正强化和负强化,日后又成为操作性条件反射(奖励式学习的另一个“科学”味更浓的名字)这一更大概念的一部分。
凭借这些见解,斯金纳引入了一个简单的解释模型,不仅可以重复,还能有力地解释大量行为:我们接近之前跟愉悦之事(奖励)关联的行为,避免之前跟不愉悦之事(惩罚)关联的刺激。他将奖励式学习从角落推到了聚光灯下。这些概念,正负强化(奖励式学习),如今已进入了世界各地大学基础心理学的课程范围。这是一项突破。
斯金纳常被誉为奖励式学习(操作性条件反射)之父,他相信,除了简单的生存机制之外,人类的大部分行为都可以用这个过程来解释。事实上,1948年,斯金纳以梭罗的名作《瓦尔登湖》为原型,写了一本名为《瓦尔登湖第二》的小说,描写了一个乌托邦社会,一步步地运用奖励式学习来训练人们和睦相处。这部小说属于哲学小说范畴,书中有个名叫弗雷泽(Frazier,明显是斯金纳的代言人)的主角,使用苏格拉底式的方法,教育一小队来拜访的游客,试图说服他们,人类天生的奖励式学习能力可以有效地用于促进繁荣,克服愚蠢。
小说中,这个虚构社群的公民从出生开始就用“行为科学”(奖励式学习)来塑造行为。例如,幼儿学到合作带来的奖励多过竞争,因此,一旦出现二选一的情况,他们会条件反射般习惯性地选择前者。如此一来,整个社群都经条件性操作,为了个人和社会的福祉,采用更高效、更和谐的行为,因为人人都存在千丝万缕的联系。《瓦尔登湖第二》考察社会和谐条件的途径之一,是科学地调查社会规范和主观偏差(也即奖励式学习建立起来的个人条件反射)。
让我们暂停一下,对主观偏差稍作解释,因为这是本书的关键一环。简而言之,一种行为重复得越多,我们就越是学会以一种特定的方式看待世界,也即基于从前行为带来的奖惩,通过一个存在偏差的镜头来看待世界。我们形成了一种习惯,这就是习惯性观看镜头。举个简单的例子:如果我们吃巧克力,它很好吃,那么,以后要是碰到机会在巧克力和其他我们不怎么喜欢的甜食里做出选择,我们恐怕就会倾向于巧克力。我们学会了戴上“巧克力很好”的眼镜;我们养成了对巧克力的偏爱,这种偏爱是主观的,因为它是我们的味觉所独有的。按同样的道理,我们可能会偏爱冰激凌,而不是巧克力,依此类推。随着时间的推移,我们越发习惯戴一组特定的眼镜,越来越多地认同特定的世界观,简直忘了自己是戴着眼镜的。它们成了我们的延伸,也即习惯。由于主观偏差源于我们的核心奖励式学习过程,它远远超出了食物偏好的范畴。
举例来说,20世纪30年代长大的许多美国人都知道,属于女人的位置是家庭。他们很可能是全职妈妈抚养长大的,如果他们发问,为什么是妈妈在家、爸爸上班,甚至会遭到呵斥和“教育”(“宝贝儿,你爸爸要赚钱供我们吃饭呀”),接受负面强化。随着时间的推移,我们的观点形成了习惯,对自己下意识的“膝跳”反射毫不怀疑:属于女人的位置当然是家庭!“膝跳”一词来自医学:医生用小锤敲打连接膝盖和小腿的肌腱,她(如果你看到“她”的时候愣了一下,或许暗示你存在“医生应该是男性”这一主观偏差)是在测试只在脊髓层面(从不进入)上传递的神经环。它只需要三个细胞来完成回路(一个感知到小锤的敲击,向脊髓发送信号;一个对脊髓里的信号进行中继;一个将信号传递到肌肉,让它收缩)。类似地,在生活的大多数时候,我们盲目且反射性地做出符合自己主观偏差的反应,忽视了自己和环境的变化已不再支持习惯行为,这会带来麻烦。如果我们能够理解主观偏差怎样形成和运作,就可能学会优化它的效用,尽量减少它招致的损害。
例如,《瓦尔登湖第二》里的社群调查了女性除了既定的家庭主妇或小学教师工作,是否还能履行其他的工作角色(请记住,他的这本书写于1948年)。跳出了“女性在社会上扮演x和y角色”的主观偏差之后,人们发现,女性完全有能力执行与男性相同的工作,故此应该加入劳动力大军(同时也让男性承担更多的育儿任务)。
斯金纳认为,行为工程有助于防止社会变得主观偏差太强,进而导致社会结构功能失调,或政治太过刻板。如果奖励式学习不加控制,少数关键岗位上的人用它们来操纵群众,这类社会内部失调显然也会出现。随着我们阅读本书,我们会看到,斯金纳的想法是否太过牵强,它们能多大限度地扩展到人类行为上。
正如《瓦尔登湖第二》的哲学发问,不管我们是销售代表、科学家还是股票经纪人,到底有没有一种方法,可用来消除或至少减少一部分影响我们行为的主观偏差呢?理解了人的偏见怎样塑造又怎样强化,能否改善我们的个人和社交生活,甚至帮助我们克服上瘾呢?一旦我们走出固有的海参习惯模式,会显现出什么样的能力和生存之道呢?
我创办耶鲁治疗神经科学诊所时,第一项临床研究是确定正念训练是否有助于人们戒烟。如今,我承认自己当时颇为焦虑。不是我认为正念不管用,而是担心自己的信誉。你看,是这样:我从来不抽烟。
我们在康涅狄格州的纽黑文地区派发火柴盒,为诊所招募研究参与者。火柴盒上写着:“无须药物,即可戒烟。”烟民们参加第一轮小组会议时,在椅子里坐立不安,不知道自己将碰到些什么。这是一项随机单盲研究,也就是说,他们只知道自己会得到某种治疗,但不知道具体是什么样的治疗。此时,我会介绍怎样叫他们给予关注,帮助戒烟。我的介绍常常会引发奇怪的表情,给人们招来新一轮的烦恼。一定会有人打断我,问:“布鲁尔医生,那个……您抽烟吗?”他们尝试了其他所有的戒烟法门,如今居然跑来听一个耶鲁来的白人书呆子胡说八道(这家伙显然没法解决他们的问题),可想而知是走投无路了。
我会回答说,“没有,我从没抽过烟,但我有其他各种上瘾。”他们的眼睛会绝望地四处打量,寻找出口。我努力宽慰他们:“如果今天晚上这轮活动之后你们还觉得没效果,请告诉我。”接着,我会走到白板前面(挡住出口,让他们无路可逃),带他们疏理吸烟的习惯是怎样建立并得以强化的。因为我曾对付过自己的成瘾习惯,也从斯金纳那里了解到许多经验,我能够列举出各种上瘾(包括吸烟)的常见因素。
写板书只需要5分钟,但到了最后,他们全都会点头附和。人们的烦躁逐渐平息下来。他们终于明白,我真的知道他们在跟什么做斗争。多年来,“您抽烟吗”这个问题经常出现,但参与者从未怀疑过我能否理解他们的苦恼。因为我们对上瘾感同身受。这只是一个“发现模式”的问题。
事实证明,除了抽烟,烟民跟其他人没有什么不同。这就是说,我们所有人都使用同样的基本大脑过程来形成习惯:学习早晨梳洗打扮,检查推特更新,抽烟。这是个喜忧参半的消息。忧的是,我们中任何人都有可能养成整天过度查收电子邮件或Facebook账户的习惯,降低自己的生产力(减少个人幸福感)。喜的是,如果我们能够从核心去理解这些过程,就能学会放弃坏习惯,培养好习惯。
理解潜在的心理和神经生物学机制,或许有助于让上述再学习过程变成一桩比我们想象中更简单(但不见得会更容易)的任务。我的实验室发现了正念(以特定的方式关注自己的瞬时体验)怎样帮助我们对付自己的坏习惯,这些发现为怎么做到上面一点提供了一些线索。还有一些线索来自参加了我们为期8周的正念减压课程(马萨诸塞州大学医学院正念中心举办)的20000多名学员。
还记得吃巧克力或抽烟的例子吗?我们会建立起各种习得性关联,它们无助于解决人承受压力或感觉不大好时渴求感觉更好的核心问题。我们并不去追究问题的根源,而是强化过去条件反射所助长的主观偏差:“哎呀,我就是想要更多的巧克力,吃完我就会感觉好些。”最终,等尝试完所有东西(包括吃过量的巧克力),我们会变得消沉。死马当成活马医只会让事情变得更糟糕。我们焦躁迷惘,不知道该看哪个方向,该转到哪个方向。人们从医生、家人或朋友处听说,或是了解到压力和上瘾基础科学的一些东西,然后来到我的诊所上课。
来参加我们正念减压课程的许多学员,对付的是这样那样的急性或慢性健康问题,但总的来说,他们都患有某一类型的疾病。他们的生活里有些事不太对劲,他们正在寻找应对之道。他们往往尝试了各种做法,却没能找到东西弥补问题。一如上面巧克力的例子,有些东西短时间有效,可叫人懊恼的是,过上一阵,它的效力就消失了,或者完全不管用了。为什么这些临时补救的法子只能暂时对付一阵呢?
如果我们通过奖励式学习的简单原则来强化习惯,但改变习惯的努力却让事情变得更糟糕了,那么,从我们最初的假设开始审视问题或许是个好的入口。停止和重新审视为缓解困境而建立的主观偏差和习惯,有助于我们理解哪些事情会叫人更颓唐,更迷失。
正念怎样帮我们找到自己的路呢?在大学学习野外徒步时,要求不能使用智能手机等定位技术,在荒野里度过几个星期,而我学会的第一项也是最关键的一项技能便是阅读地图。重要的是,如果我们不知道怎样定位,那么地图就毫无用处。换句话说,只有我们把地图跟指南针相配合,判断出北方是哪一边,才能使用地图。给地图定了位,地标也就一一就绪,变得有了意义。直到这时,我们才能在野外导航。
同样道理,如果我们一直抱着“这不太对劲”的不安情绪,没有指南针帮助我们定位它到底来自何方,那么,这种脱节就会导致相当大的压力。有时候,不安以及对成因缺乏意识,严重时会让人产生青年或中年危机。我们跌跌撞撞,采用极端的手段来摆脱挫折和不安感,跟秘书或助理离家出走就是典型的反应(一个月之后,当我们从兴奋中清醒过来,会忍不住感叹自己到底做了些什么)。那么,要是我们并不尝试撼动它、击败它,反而加入它,那会怎么样呢?换句话说,把压力或不安的感觉当作指南针如何呢?目标不是寻找更多的压力(所有人都有一大堆压力),而是把现存的压力作为导航工具。压力究竟是什么感觉,它跟兴奋等其他情绪有什么不同?如果我们能够清楚地判断出自己是朝向“南”(压力)还是朝向“北”(远离压力),就可以用它来指导生活了。
正念的定义有很多。最常为人引用的,或许是乔恩·卡巴金在各地正念减压课堂传授的操作性定义(也写进了他《多舛的生命》一书):“因为有意识地关注当下而产生的非判断性觉知。”
斯蒂芬·巴彻勒(Stephen Batchelor)最近写道,这一定义指出了“学习怎样稳定注意力、栖息在非反应性觉知的清醒空间”的“人类能力”。
换句话说,正念就是更清楚地看待世界。如果我们因为自己的主观偏差而迷失,不停地兜圈子,那么,正念能让我们意识到这些偏差,看出自己是怎么走向歧途的。只要我们看到自己在原地打转,哪儿也没去成,就可以停下来,扔掉不必要的包袱,重新对自己定位。用个比喻的说法,正念就是帮助我们在生活疆域里导航的地图。
非判断性或非反应性觉知,是什么意思呢?本书中,我们会首先解释奖励式学习怎样带来主观偏差,这种偏差怎样扭曲人对世界的看法,使得我们无法看清现象本质,直接做出习惯性反应(也即根据先前的反应,顺着自动驾驶仪,驶向“营养”,避开毒素)。我们还将探索这种带有偏差的观点为什么会引发更多的混乱,以及“这感觉太糟糕了,我得做点什么”的反应,为什么会让问题变得更加复杂。人要是在森林里迷了路,开始感到恐慌,本能就会让人更快速地移动。而这样做,自然会叫人迷路迷得更厉害。
如果我在野外旅行时迷路了,导师会让我停下来,深吸一口气,拿出地图和指南针。只有做了重新定位,并获得了清晰的方向感,我才应该开始再次移动。这有违我的直觉,但这真的能救命。同样,我们要把“看得清楚”和“非反应性”这两个概念放到一起,了解哪些做法有可能加剧不安,以及怎样导航才能摆脱这种局面,更有技巧性地进行处理。
此前的10年,我的实验室收集了来自“正常”(姑且不管它是什么意思)个人、患者(多伴随上瘾)、参加正念中心减压课程的学员,以及冥想新人和资深人士的数据。我们研究了各种各样的上瘾、不同类型的冥想和冥想人士(包括基督教的“归心祈祷”和禅宗),以及提供正念训练的各种方式。不管是通过古代佛教的正念视角,还是更现代的操作性条件反射的视角(或两者相结合),我们所得的结果都跟这一理论框架相吻合,并支持了这一框架。
我们参考古代和现代科学之间的相似之处,探讨正念怎样帮助我们看清自己的习得性联想、主观偏差和由此产生的反应。一如巴彻勒所说:“关键是,对于能影响你生活质量的行为,要获得能实现改变的实践知识;反过来说,理论知识,对你一天天地怎样在这世上生活,可能没什么作用。放开以自我为中心的反应,人便逐渐带着充满关爱、善意、同情、无私的喜悦和平静的意识,栖居在整个世界里。”
这听上去似乎好得不像是真的,但如今,我们有了充分的数据可提供支持。
我们将探讨正念怎样帮助我们解读并进而借助压力指南针,在迷路的时候(不管是反应性地冲着伴侣吼叫,为了排解无聊习惯性地观看网络视频,还是沾染毒瘾后跌到人生低谷)找到正路。我们可以从像海参那样被动地做出反应,过渡到像个完完全全的人那样做事。