
下载掌阅APP,畅读海量书库
立即打开



关系数据库规范化(Normal Form)的目的是建立正确、合理的关系,规范化的过程是一个分析关系的过程。
实际上设计任何一种数据库应用系统,不论是层次、网状或关系模型,都会遇到如何构造合适的数据模式即逻辑结构问题。由于关系模型有严格的数学理论基础,并且可以向其他数据模型转换,因此人们往往以关系模型为背景来讨论这一问题,形成了数据库逻辑设计的一个有力工具—关系数据库规范化理论。
1 . 函数依赖及其对关系的影响
函数依赖是属性之间的一种联系,普遍存在于现实生活中。例如,银行通过客户的存款账号,可以查询到该账号的余额。又例如,表2-3是描述学生情况的关系(二维表格),用一种称为关系模式的形式表示为
STUDENT1(学号,姓名,性别,出生日期,专业)
由于每个学生有唯一的学号,一个学号只对应一个学生,一个学生只就读于一个专业,因此学号的值确定后,姓名及其所就读专业的值也就被唯一地确定了。属性间的这种依赖关系类似于数学中的函数。因此称账号函数决定账户余额,或者称账户余额函数依赖于账号;学号函数决定姓名和专业,或者说姓名和专业函数依赖于学号,记作:学号→姓名,学号→专业;同样有学号→性别,学号→出生日期。
表2 -3 STUDENT1关系

如果在关系STUDENT1的基础上增加一些信息,例如学生的“学院”及“院长”信息,如表2-4所示,有可能设计出如下关系模式:
STUDENT2(学号,姓名,性别,出生日期,专业,学院,院长)
函数依赖关系是:学号→学院,学院→院长。
表2 -4 STUDENT2关系
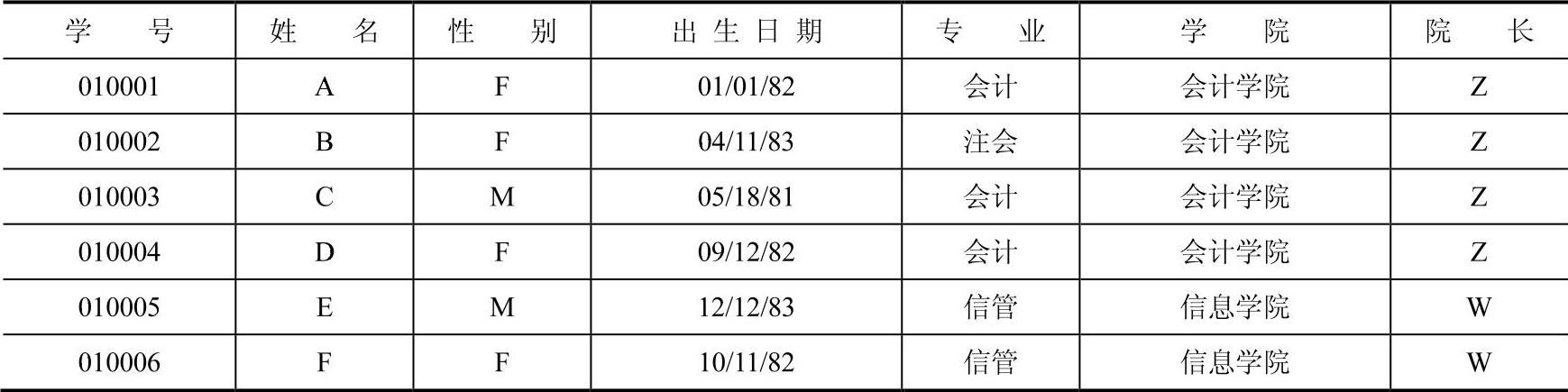
上述关系模式存在如下4个问题。
1)数据冗余太大。例如,院长的姓名会重复出现,重复的次数与该学院学生的人数相同。
2)更新异常(Update Anomalies)。例如,某学院更换院长后,系统必须修改与该学院学生有关的每一个元组。
3)插入异常(Insertion Anomalies)。例如,一个学院刚成立,尚无学生,则这个学院及其院长的信息就无法存入数据库。
4)删除异常(Deletion Anomalies)。例如,某个学院的学生全部毕业了,在删除该学院学生信息的同时,也把这个学院的信息(学院名称和院长)全部删除了。如果删除一组属性,带来的副作用可能是丢失了一些其他信息。
一个关系之所以会产生上述问题,是由于关系中存在某些函数依赖引起的。通常,如果把太多的信息放在一个关系中时,出现的诸如冗余之类的问题称为“异常”。
规范化是为了设计出“好的”关系模型。规范化理论正是用来改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决更新异常、插入异常、删除异常和数据冗余问题。
2 . 规范化范式
每个规范化的关系只有一个主题。如果某个关系有两个或多个主题,就应该分解为多个关系。规范化的过程就是不断分解关系的过程。
人们每发现一种异常,就研究一种规则防止异常出现。由此设计关系的准则得以不断改进。20世纪70年代初期,研究人员系统地定义了第一范式(Fist Normal Forms,1NF),第二范式(Second Normal Form,2NF)和第三范式(Third Normal Form,3NF)。之后人们又定义了多种范式,但大多数简单业务数据库设计中只需要考虑第一范式、第二范式和第三范式。每种范式自动包含其前面的范式,各种范式之间的关系是:
5NF⊂4NF⊂BCNF⊂3NF⊂2NF⊂1NF
因此符合第三范式的数据库自动符合第一、第二范式。
(1)1NF
关系模式都满足第一范式,即符合关系定义的二维表格(关系)都满足第一范式。列的取值只能是原子数据;每一列的数据类型相同,每一列有唯一的列名(属性);列的先后顺序无关紧要,行的先后顺序也无关紧要。
(2)2NF
关系的每一个非关键字属性都完全函数依赖于关键字属性,则关系满足第二范式。
第二范式要求每个关系只包含一个实体集的信息,所有非关键字属性依赖于关键字属性。每个以单个属性作为主键的关系自动满足第二范式。
(3)3NF
关系的所有非关键字属性相互独立,任何属性其属性值的改变不应影响其他属性,则该关系满足第三范式。一个关系满足第二范式,同时没有传递依赖,则该关系满足第三范式。
由1NF、2NF和3NF,总结出规范化的规则如下。
1)每个关系只包含一个实体集,每个实体集只有一个主题。
2)每个关系有一个主键。
3)属性中只包含原子数据。
4)不能有重复属性。
经过不断总结,人们归纳出规范化的规则如下。
● 每个关系只包含一个实体集;每个实体集只有一个主题,一个实体集对应一个关系。
● 属性中只包含原子数据,即最小数据项;每个属性具有数据类型并取值于同一个值域。
● 每个关系有一个主关键字,用来唯一地标识关系中的元组。
● 关系中不能有重复属性;所有属性完全依赖关键字(主关键字或候选关键字);所有非关键字属性相互独立。
● 元组的顺序无关,属性的顺序无关。