
下载掌阅APP,畅读海量书库
立即打开




MapReduce是Hadoop的一个核心组成框架,使用该框架编写的应用程序能够以一种可靠的、容错的方式并行处理大型集群(数千个节点)上的大量数据(TB级别以上),也可以对大数据进行加工、挖掘和优化等处理。
一个MapReduce任务主要包括两部分:Map任务和Reduce任务。Map任务负责对数据的获取、分割与处理,其核心执行方法为map()方法;Reduce任务负责对Map任务的结果进行汇总,其核心执行方法为reduce()方法。MapReduce将并行计算过程高度抽象到了map()方法和reduce()方法中,程序员只需负责这两个方法的编写工作,而并行程序中的其他复杂问题(如分布式存储、工作调度、负载均衡、容错处理等)均可由MapReduce框架代为处理,程序员完全不用操心。
MapReduce的设计思想是,从HDFS中获得输入数据,将输入的一个大的数据集分割成多个小数据集,然后并行计算这些小数据集,最后将每个小数据集的结果进行汇总,得到最终的计算结果,并将结果输出到HDFS中,如图5-1所示。
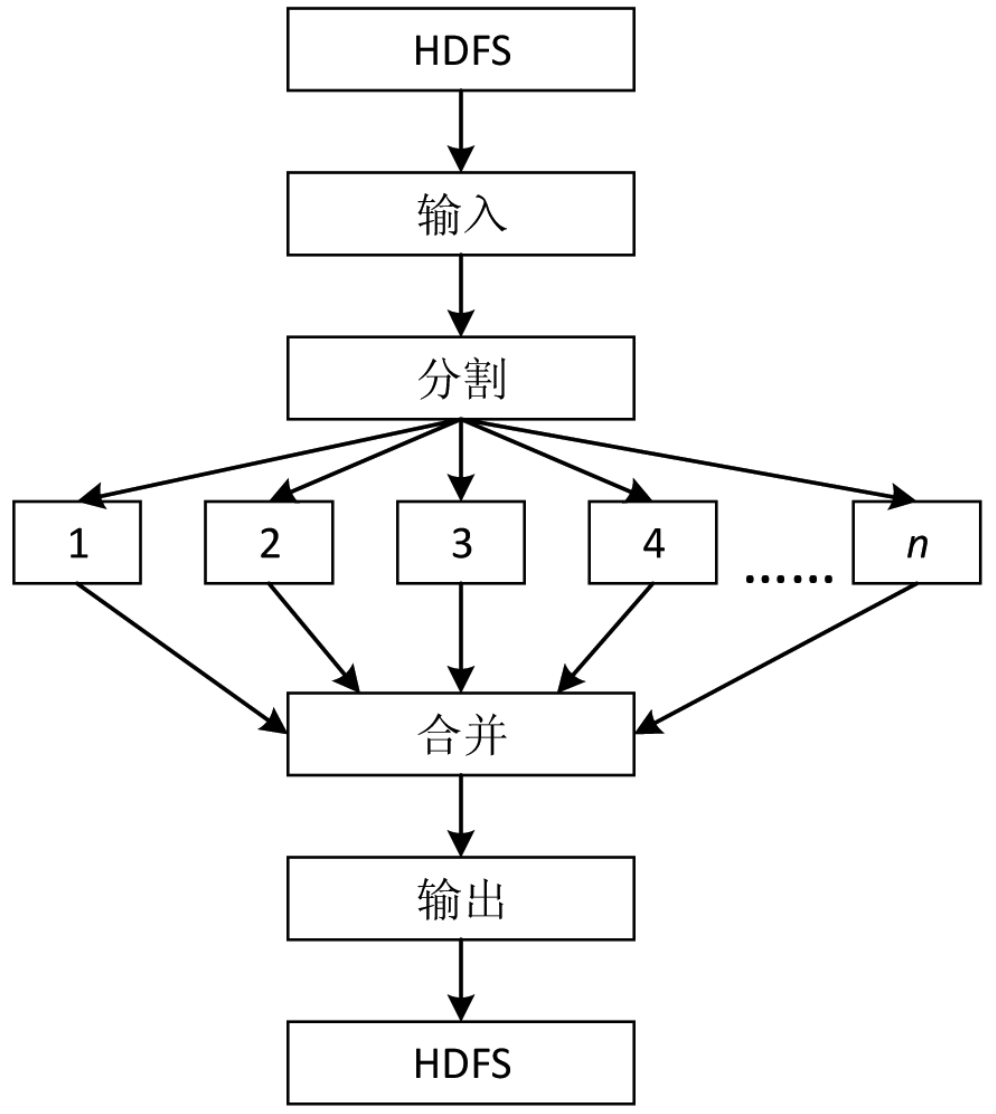
图5-1 MapReduce设计思想流程图
在MapReduce并行计算中,对大数据集分割后的小数据集的计算,采用的是map()方法,各个map()方法对输入的数据进行并行处理,对不同的输入数据产生不同的输出结果;而对小数据集最终结果的合并,采用的是reduce()方法,各个reduce()方法也各自进行并行计算,各自负责处理不同的数据集合。但是在reduce()方法处理之前,必须等到map()方法处理完毕,因此在数据进入到reduce()方法前需要有一个中间阶段,负责对map()方法的输出结果进行整理,将整理后的结果输入到reduce()方法,这个中间阶段称为Shuffle阶段。
此外,在进行MapReduce计算时,有时候需要把最终的数据输出到不同的文件中。比如,按照省份划分的话,需要把同一省份的数据输出到一个文件中;按照性别划分的话,需要把同一性别的数据输出到一个文件中。我们知道,最终的输出数据来自于Reduce任务,如果要得到多个文件,意味着有同样数量的Reduce任务在运行。而Reduce任务的数据来自于Map任务,也就是说,Map任务要进行数据划分,对于不同的数据分配给不同的Reduce任务执行。Map任务划分数据的过程就称作分区(Partition,本章5.1.3节的MapReduce工作原理中会详细讲解)。
从编程的角度来看,将图5-1进一步细化,可以得到图5-2所示的流程。
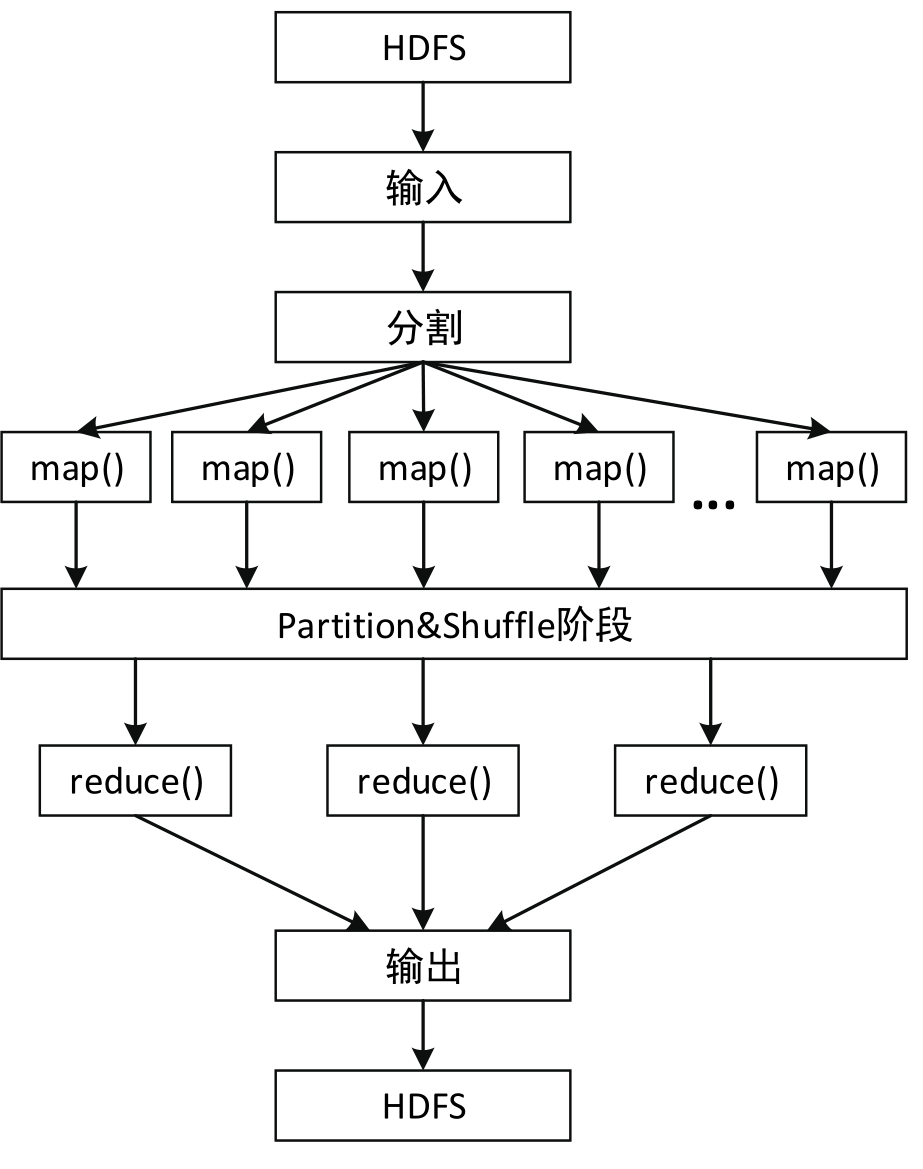
图5-2 MapReduce设计思想流程图(编程角度)
总结来说,MapReduce利用了分而治之的思想,将数据分布式并行处理,然后进行结果汇总。举个例子,有一堆扑克牌,现在需要把里面的花色都分开,而且统计每一种花色的数量。一个人清点可能耗时4分钟,如果利用MapReduce的思想,把扑克牌分成4份,每个人对自己的那一份进行清点,4个人都清点完成之后把各自的相同花色放到一起并清点每种花色的数量,那么这样可能只会耗时1分钟。在这个过程中,每个人就相当于一个map()方法,把各自的相同花色放到一起的过程就是Partition,最后清点每一种花色的数量的过程就是reduce()方法。
MapReduce程序运行于YARN之上,使用YARN进行集群资源管理和调度。每个MapReduce应用程序会在YARN中产生一个名为“MRAppMaster”的进程,该进程是MapReduce的ApplicationMaster实现,它具有YARN中ApplicationMaster角色的所有功能,包括管理整个MapReduce应用程序的生命周期、任务资源申请、Container启动与释放等。
客户端将MapReduce应用程序(jar、可执行文件等)和配置信息提交给YARN集群的ResourceManager,ResourceManager负责将应用程序和配置信息分发给NodeManager、调度和监控任务、向客户端提供状态和诊断信息等。
图5-3所示为MapReduce应用程序在YARN中的执行流程。
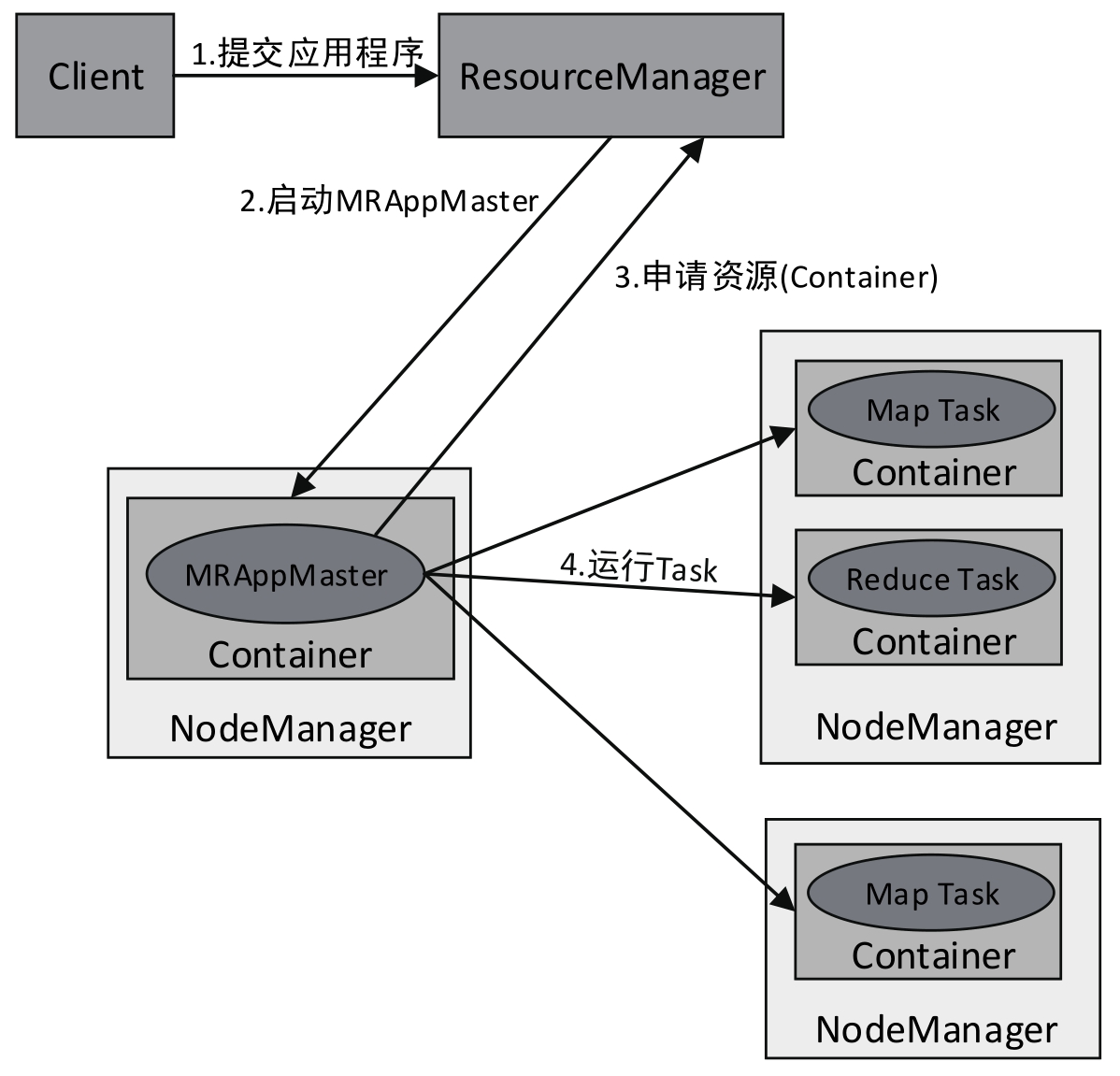
图5-3 MapReduce 应用程序在YARN中的执行流程
(1)客户端提交MapReduce应用程序到ResourceManager。
(2)ResourceManager分配用于运行MRAppMaster的Container,然后与NodeManager通信,要求它在该Container中启动MRAppMaster。MRAppMaster启动后,它将负责此应用程序的整个生命周期。
(3)MRAppMaster向ResourceManager注册(注册后客户端可以通过ResourceManager查看应用程序的运行状态)并请求运行应用程序各个Task所需的Container(资源请求是对一些Container的请求)。如果符合条件,ResourceManager会分配给MRAppMaster所需的Container。
(4)MRAppMaster请求NodeManager使用这些Container来运行应用程序的相应Task(即将Task发布到指定的Container中运行)。
此外,各个运行中的Task会通过RPC协议向MRAppMaster汇报自己的状态和进度,这样一旦某个Task运行失败时,MRAppMaster可以对其重新启动。当应用程序运行完成时,MRAppMaster会向ResourceManager申请注销自己。
MapReduce计算模型主要由三个阶段组成:Map阶段、Shuffle阶段、Reduce阶段,如图5-4所示。
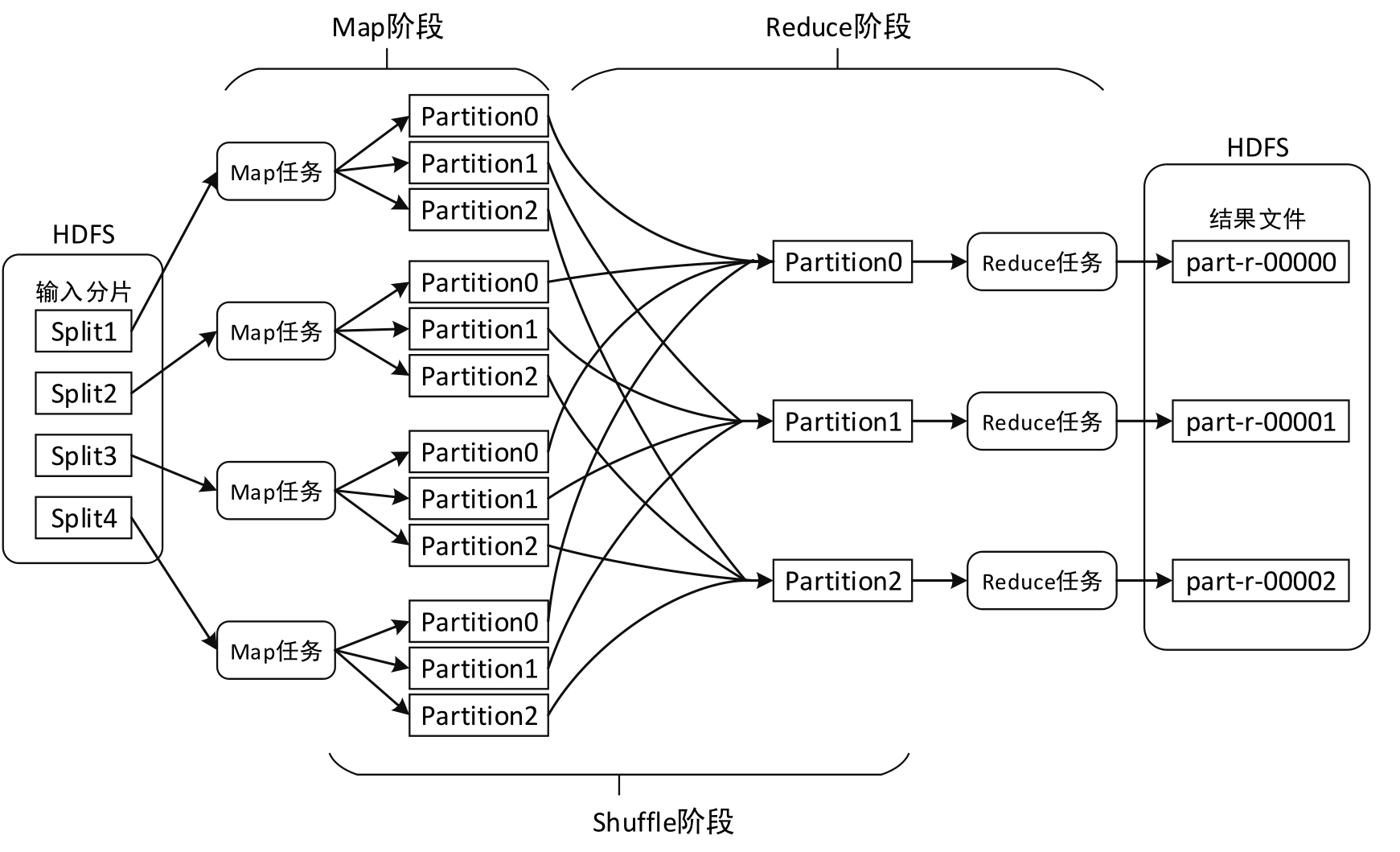
图5-4 MapReduce计算模型
Map阶段的工作原理如下:
将输入的多个分片(Split)由Map任务以完全并行的方式处理。每个分片由一个Map任务来处理。默认情况下,输入分片的大小与HDFS中数据块(Block)的大小是相同的,即文件有多少个数据块就有多少个输入分片,也就会有多少个Map任务,从而可以通过调整HDFS数据块的大小来间接改变Map任务的数量。
每个Map任务对输入分片中的记录按照一定的规则解析成多个<key,value>对。默认将文件中的每一行文本内容解析成一个<key,value>对,key为每一行的起始位置,value为本行的文本内容,然后将解析出的所有<key,value>对分别输入到map()方法中进行处理(map()方法一次只处理一个<key,value>对)。map()方法将处理结果仍然是以<key,value>对的形式进行输出。
由于频繁的磁盘I/O会降低效率,因此Map任务输出的<key,value>对会首先存储在Map任务所在节点(不同的Map任务可能运行在不同的节点)的内存缓冲区中,缓冲区默认大小为100 MB(可修改mapreduce.task.io.sort.mb属性调整)。当缓冲区中的数据量达到预先设置的阈值后(mapreduce.map.sort.spill.percent属性的值,默认0.8,即80%),便会将缓冲区中的数据溢写(spill)到磁盘(mapreduce.cluster.local.dir属性指定的目录,默认为${hadoop.tmp.dir}/mapred/local)的临时文件中。
在数据溢写到磁盘之前,会对数据进行分区(Partition)。分区的数量与设置的Reduce任务的数量相同(默认Reduce任务的数量为1,可以在编写MapReduce程序时对其修改)。这样每个Reduce任务会处理一个分区的数据,可以防止有的Reduce任务分配的数据量太大,而有的Reduce任务分配的数据量太小,从而可以负载均衡,避免数据倾斜。数据分区的划分规则为:取<key,value>对中key的hashCode值,然后除以Reduce任务数量后取余数,余数则是分区编号,分区编号一致的<key,value>对则属于同一个分区。因此,key值相同的<key,value>对一定属于同一个分区,但是同一个分区中可能有多个key值不同的<key,value>对。由于默认Reduce任务的数量为1,而任何数字除以1的余数总是0,因此分区编号从0开始。
MapReduce提供的默认分区类为HashPartitioner,该类的核心代码如下:

getPartition()方法有三个参数,前两个参数指的是<key,value>对中的key和value,第三个参数指的是Reduce任务的数量,默认值为1。由于一个Reduce任务会向HDFS中输出一个结果文件,而有时候需要根据自身的业务,将不同key值的结果数据输出到不同的文件中。例如,需要统计各个部门的年销售总额,每一个部门单独输出一个结果文件,这个时候就可以自定义分区(关于如何自定义分区,在本章的5.6节将详细讲解)。
分区后,会对同一个分区中的<key,value>对按照key进行排序,默认升序。
Reduce阶段的工作原理如下:
Reduce阶段首先会对Map阶段的输出结果按照分区进行再一次合并,将同一分区的<key,value>对合并到一起,然后按照key对分区中的<key,value>对进行排序。
每个分区会将排序后的<key,value>对按照key进行分组,key相同的<key,value>对将合并为<key,value-list>对,最终每个分区形成多个<key,value-list>对。例如,key中存储的是用户ID,则同一个用户的<key,value>对会合并到一起。
排序并分组后的分区数据会输入到reduce()方法中进行处理,reduce()方法一次只能处理一个<key,value-list>对。
最后,reduce()方法将处理结果仍然以<key,value>对的形式通过context.write(key,value)进行输出。
Shuffle阶段所处的位置是Map任务输出后,Reduce任务接收前。Shuffle阶段主要是将Map任务的无规则输出形成一定的有规则数据,以便Reduce任务进行处理。
总结来说,MapReduce的工作原理主要是:通过Map任务读取HDFS中的数据块,这些数据块由Map任务以完全并行的方式处理;然后将Map任务的输出进行排序后输入到Reduce任务中;最后Reduce任务将计算的结果输出到HDFS文件系统中。
Map任务中的map()方法和Reduce任务中的reduce()方法需要用户自己实现,而其他操作MapReduce已经帮用户实现了。
通常,MapReduce计算节点和数据存储节点是同一个节点,即MapReduce框架和HDFS文件系统运行在同一组节点上。这样的配置可以使MapReduce框架在有数据的节点上高效地调度任务,避免过度消耗集群的网络带宽。