
下载掌阅APP,畅读海量书库
立即打开




在本章中,我们将了解什么是图像识别、图像在计算机中的表达、图像识别的流程以及图像识别中类别的表达方式。此外,我们将编写代码探索图像识别领域中的一些经典数据集。
图像识别,顾名思义就是识别图像的内容。严谨地讲,就是给计算机一张图像,让其判断出图像中的内容。例如给一张手写数字的图像,判断出它是数字几;或是给一张动物的图像,判断是猫还是狗;或是给一张班级里同学的照片,判断出他/她的名字。

识别数字/识别动物
为了让计算机识别图像,我们首先得让计算机“看”到图像。所以在学习图像识别的算法之前,我们要先了解计算机“眼”中的图像是怎样的。
对于用计算机处理图像,你可能并不陌生。使用Windows操作系统自带的画图软件,可以进行一些简单的图像处理工作。此外还有Lightroom、Photoshop之类功能更为强大的图像处理软件,可见计算机处理图像的能力非常强大。你可能听说过,计算机世界里的通用语言是二进制,在计算机的“眼”中,一切都是数字。那么,我们怎样把一张图像转化为机器能处理的数字形式呢?
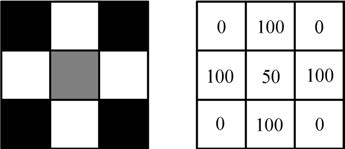
一张含有3×3=9个像素的黑白位图
计算机中的图像主要有两种—位图和矢量图(矢量图在本书中不做介绍)。其中位图是使用像素矩阵来表示图像的一种方法。我们可以把图像分割成一个个小方块,每一个小方块就是一个像素。我们常听到的广告语“2000万像素,照亮你的美”,所表达的就是图像含有2000万个小方块。每一个像素都可以描绘一些信息,通常像素越高,图像包含的信息就越多,图像也就越清晰。以黑白照片为例,对于其上每一个像素,都可以用一个数来描述它的灰度(或者亮度)。如果把纯白色记作100,纯黑色记作0,不同的灰色用一个1~99之间的数字表示,这样就把一张图像转化成了一个矩阵,如下图所示。通常灰度会用0~255中的一个数字来表示,这里为了方便理解所以我们用了0~100来举例。

三原色的叠加
根据光的三原色原理,我们知道任何颜色的光都可以通过红、绿、蓝三种原色叠加生成,因此我们可以通过描述颜色中红、绿、蓝三种成分的多少来唯一确定一种颜色。换句话说,对于图像中的每个像素,我们都可以用一个包含三个数的数组来描述它的颜色,这就是最常见的RGB色彩模型。RGB分别表示Red、Green和Blue,这三种颜色成分的多少可以分别用一个0~255的数字来表示,以下简记为(R,G,B)。例如(255,0,0),表示这种颜色中红色的成分最多,没有绿色和蓝色的成分,是纯红色,同理(0,255,0)就是纯绿色。我们知道红光和绿光可以叠加成为黄光,那么(255,255,0)就应该是纯黄色。(0,0,0)表示什么颜色都没有,就是黑色,(255,255,255)表示三种颜色的“光强”都达到最大,叠加成为白色。

用RGB色彩模型来表示一张位图中的颜色
【概念解析】
图像的存储方式涉及四个专业术语。
向量:用最简单的方式理解,一个向量其实就是一组数字。如下左图所示。
矩阵:矩阵也是一组数字,与向量有所不同,它由行与列构成。矩阵中的数字都可以用x行y列来定位。一个矩阵的形状由两个整数定义,如下中图的矩阵就是一个大小为(5,5)的矩阵。矩阵可以用来描述灰度图。
张量:张量是一种更广义的概念。如果我们希望排列方式不仅有行和列,还有更多的维度,那么就需要用到张量。向量实际上就是一阶张量,矩阵就是二阶张量,如下右图是一个三阶张量,它的大小是(5,5,3)。三阶张量可以用来描述RGB彩色图。
通道:一张彩色图像通常由一个三阶张量表示,而除了行与列的维度,另外一个维度称为通道。如下右图所示,一张RGB格式的图像,通道数量为3。
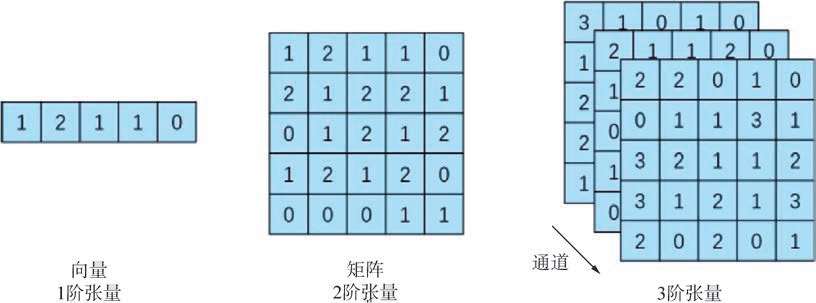
向量、矩阵、张量与通道
思考与实践
1.1 如果有一张100×100像素的RGB彩色图像,计算机存储这张图像需要存多少个数字呢?
1.2 除了RGB,每个像素中还可以存储什么信息?
1.3 一张灰度图能否用3阶张量表示?如果能的话,该张量的形状是怎样的?通道数量是几?
在学习如何让计算机识别图像之前,我们先花五分钟时间想一想自己是如何识别图像的。识别图像对人类来说似乎是一种天赋,完全是下意识的行为,识别过程在大脑中自动完成。环视一下你书桌上的各种物体,是不是感觉没有动脑就自动给出了每个物体的名称,因为这些物体对你来说很熟悉,所以识别过程很难被注意到。现在让我们来认真体验一下识别一个新图像的过程。我们将观察一组可能从未见过的图像以及它们的标号,然后为另一组新的图像标号,试着感受一下识别过程。下图是第一组图像。

1号 2号 3号第一组图像
现在观察第二组图像,为每张图打上编号(1号、2号、3号或者都不是)。感受一下自己识别图像的过程。

第二组图像
公布答案!从左到右分别是:都不是、都不是、3号、2号、1号。其实这些图像都是甲骨文。第一组图像中的1号是龙、2号是车、3号是火。第二组图像的第一张是鸟,第二张是车的另外一种写法。
回想一下刚才的识别过程,你是不是将第二组图像与第一组图像一一做比较,与1号、2号、3号哪个更像,就把它打上相应的标签?如果与这3个都不像,就认为这是一张未知的图像。那么具体怎样才算像呢?请你再尝试一次,感受一下判断像不像的过程。对于这几张甲骨文的图像,我们可能会注重形状上的相似,例如都是瘦瘦长长的,或者都有左右两个圆圈,圆圈中有一个十字,又或者都有三个尖的突起等。其实计算机识别图像的过程与人的判断过程十分类似。计算机也是通过与已有标签的图像做比较,来对新的图像作出判断。与人判断过程不同的是,计算机科学家们会设计算法,来捕捉与图像形状、颜色相关的各种特征,通过这些特征来判断图像的相似度。这个捕捉特征来判断相似程度的算法的效果,能够很大程度决定图像识别的效果。

独热编码示例
图像识别本质上是个分类问题,也就是给计算机一张图像,让其给出图像所属的类别。在计算机中,类别往往也是用数字表示的。例如一个二分类问题,类别的标签就是0和1,无论分的是猫和狗,还是苹果和香蕉,都可以把其中一种类别标记为0,另一种标记为1。如果类别不止两类,那么就要使用更多数字,例如一个十分类问题,类别的标签就是0~9这十个数字。但是直接使用数字作为标签会有个小问题,那就是数字之间有比较和算术关系,如2>1,5<7,3×3=9,而标签类别之间并没有这种比较关系,如苹果和香蕉是平级的,不存在苹果大于香蕉,或者梨是西瓜的2倍之类的关系。如果做分类问题时直接让计算机输出一个数字,数字自身的比较和算术关系会影响计算机的判断。所以通常我们会用一种叫独热编码(One Hot Encoding)的方法来代替数字。例如有10个类别,我们就会用10个0或1来表示任何一种类别,其中只有一个位置是1,其余位置都是0,哪一位是1就代表哪个类别,如上图所示。
我们知道计算机进行图像识别需要先有一些已知的图像,也就是已经被标注了类别的图像。这一节中我们将了解几个经典的图像数据集。
MNIST数据集是一个非常著名的数据集,很多教程都会使用它,新的分类算法也往往会先在MNIST数据集上做效果测试。MNIST数据集来自美国国家标准与技术研究所(National Institute of Standards and Technology)。该数据集中包含了由250个人手写的数字,其中50%是高中学生,50%来自人口普查局的工作人员。在MNIST数据集中的每张图像都由28×28个像素构成,每个像素用一个灰度值表示。下面我们利用代码对MNIST数据集进行可视化。
首先导入一些必要的库。
mnist:Keras库中的一个方便我们下载MNIST数据集的类。
pyplot:Python中常用的画图工具matplotlib的画图类。
numpy:Python中用于处理各种数值计算的库。


【延伸阅读】
Keras是一个专注于深度学习的库,它建立在一些更加复杂的深度学习框架之上,例如TensorFlow框架,并将其简化,提供了一套快速便捷地构建神经网络的方法。Keras库中还包含了深度学习相关的一些工具,例如常用数据集、数据预处理方法等。
使用Keras的mnist模块下载MNIST数据集,数据集已经被分为训练数据与测试数据,分别包含了输入x(图像)和输出y(对应的数字)。我们将四个数据集的形状打印出来。


【概念解析】
已知类别的数据往往会被分为两部分,训练数据与测试数据。其中训练数据是用来训练模型的,训练后得到的模型会在测试数据上进行测试,测试得到的准确性就可以认为是这个算法的效果。你可能会问,为什么不直接用全部数据训练,再用相同的数据测试呢?我们考虑这样一个例子,一个人学习乘法的时候,往往先学习“九九乘法口诀表”,可以靠死记硬背的方式把这81种答案都背下来,这样出任何一道个位数的乘法他都能答对。但是这并不代表他学会了乘法运算,一旦给他一个新的乘法算式,例如12×15,他就答不上来了。同样地,一个模型也可以靠“死记硬背”的方法把它“见过”数据的对应类别都记录下来,但是这并不能反应它的真实效果,我们需要用一些它没有“见过”的数据来测试。
从x_train和y_train的形状可以看出训练数据中包含了60000个数据点。其中输入x是60000张用28×28=784像素组成的图像。由于MNIST数据集是灰度图,所以每个像素仅由一个数字表示。输出y是60000个数字,代表了每一张图像对应的数字。测试数据x_test和y_test中则包含了10000个数据点。
我们将训练数据中的前10张图像画出来。(有关matplotlib库的详细用法在本书中不作展开,如果感兴趣可以搜索相关教程。)

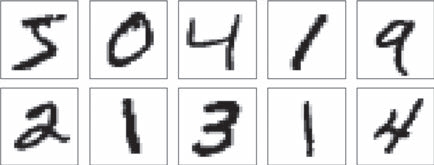
训练数据中的前10张图像
接下来,我们使用下列代码画出0~9的10张对应的手写数字图像。

运行结果如下页图所示,可以看到MNIST数据集中包含了笔画轻重各异、书写风格不同的图像。数据集中的数据多样性很重要,只有计算机“见过”的数据越多,分类才越准确。直观上理解,若计算机“见过”的数字都是右撇子写的,这时给它一个由左撇子书写的数字,那么它大概率会识别错误;如果计算机曾经“见过”左撇子写的数字,那么它识别正确的可能性就会提升。


手写数字图像
CIFAR—10数据集由10类大小为32×32的彩色图像组成,一共包含60000张图像,每一类包含6000图像。其中50000张图像作为训练集,10000张图像作为测试集。下面我们编写Python代码对CIFAR—10数据集实现可视化。
与前一节中处理MNIST数据集类似,首先导入一些必要的库。
cifar10:Keras库中的一个方便下载CIFAR—10数据集的类。
pyplot:Python中常用的画图工具matplotlib的画图类。
numpy:Python中用于处理各种数值计算的库。


使用Keras的cifar10模块下载CIFAR—10数据集。这个数据集已经被分为训练数据与测试数据,分别包含了输入x(图像)和输出y(对应的物体类别)。我们将四个数据集的图像打印出来。


从输出结果中,可以看出CIFAR—10数据集中包含了50000个训练数据与10000个测试数据。与MNIST数据集不同,CIFAR—10数据集中的图像是RGB格式的彩色图像,每张图像大小为32×32×3,即每张图像含有32×32=1024个像素点,而每个像素点由3个数字组成,分别代表红色、绿色、蓝色通道。输出的y依然由一个数字表示,0~9这10个数字分别代表10类物体。
0:飞机,1:汽车,2:鸟,3:猫,4:鹿,5:狗,6:青蛙,7:马,8:船,9:卡车
我们使用pyplot将训练数据中的前10张图像画出来。


训练数据集中的前10张图像
与前一小节中MNIST数据集相似,我们为每一类物体画出10张图像。


为每类物体分别画出10张图像
可以看到CIFAR—10数据集中的每一类物体都有形状、颜色、拍摄角度不同的图像,并且图像中还含有一些不相关的元素。
如果说MNIST数据集将初学者领进了深度学习领域,那么ImageNet数据集对深度学习的浪潮就起了巨大的推动作用。ImageNet数据集有1400多万张图像,涵盖2万多个类别,其中有超过百万的图像有明确的类别标注和图像中物体位置的标注。值得一提的是ImageNet数据集中的类别是层次化的,例如动物这个大类可分为哺乳动物、鸟类等子类,哺乳动物又可以往下细分子类。另外,ImageNet数据集中图像的平均分辨率为400×350,远远高于MNIST和CIFAR—10数据集。由于ImageNet数据集非常大,我们就不下载到本地用代码查看了,这里我们可以通过以下图像,对ImageNet数据有个基本的认识。

ImageNet数据样例