
下载掌阅APP,畅读海量书库
立即打开



在编写程序的时候,读者会不会被一个问题所困扰?有些功能多处要用到,实现时不得不复制和粘贴相同的代码。这不但会使程序代码冗余、容易出错,而且维护起来十分困难。因此,可以将这段重复使用的代码打包成一个可重用的模块,根据需要调用这个模块,而不是复制和粘贴现有的代码,这个模块就是Python的函数。
另外,我们有时希望将模块和模块所要处理的数据相关联,就跟Python内置的数据结构一样,能有效地组织和操作数据。Python允许创建并定义面向对象的类,类可以用来将数据与处理的数据功能相关联。
Scrapy爬虫框架正是基于Python模块化(函数和类)的设计模式进行组织和架构的。而且几乎所有爬虫功能的实现,都是基于函数和类的。可以说,Python模块化设计是理解Scrapy爬虫框架及掌握爬虫编程技术的重要前提。
函数是组织好的,可重复使用的,用来实现单一或相关联功能的代码段。它有一个入口,用于输入数据,还有一个出口,用于输出结果。当然,根据实际需求,入口和出口是可以省略的。下面先看几个例子。
(1)判断闰年的函数。
def is_leap(year): #函数定义
if (year % 4 == 0 and year % 100 != 0) or (year % 4 == 0 and year % 400 == 0):
return 1 #闰年
else:
return 0 #非闰年
【重点说明】
·函数以def关键字开头,后接函数名、圆括号(( ))和冒号(:)。
·圆括号内用于定义参数(也可以没有参数)。
·代码块必须缩进。
·使用return结束函数,并将返回值传给调用方。
需要注意的是,函数只有被调用才会被执行。以下代码实现了函数的调用:
year = int(input("请输入年份:")) #控制台输入年份
result = is_leap(year) #函数调用,传递参数year
if result == 1:
print("%d年是闰年"%year)
else:
print("%d年不是闰年"%year)
【重点说明】
·通过is_leap(year)调用函数,其中,year是传递给函数的参数(叫做实参)。
·当函数执行完后,会通过return返回结果,赋给result。
(2)实现打印任意同学信息的函数。
def print_student(name,age,sex="女"): #性别使用了默认值,必须放最后面
print("name:",name)
print("age:",age)
print("sex:",sex)
print_student("cathy",10) #函数调用,性别使用了默认设置
print_student("terry",20,"男") #函数调用
【重点说明】
·函数可以定义多个参数,用逗号隔开。
·参数可以设置默认值,但是必须放在最后。
·在调用函数时,要按定义时的顺序放置参数,函数会按照顺序将实参传递给形参。
(3)求任意几门功课的平均成绩的函数。
def get_avg(*scores): #scores前面加*,表示可变长参数
sum = 0 #总成绩,初始值为0
for one in scores:
sum+=one
return (sum/len(scores)) #计算出平均值,返回给调用方
avg = get_avg(80,90,95) #调用函数,求3门课的平均分
avg1 = get_avg(77,88) #调用函数,求2门课的平均分
print(avg) #结果:88.33333333333333
print(avg1) #结果:82.5
【重点说明】
·在参数个数不确定的情况下,可以使用可变长参数。方法是在变量前面加上*号。
·可变长参数类似于一个列表,无论输入多少个数据,都会被存储于这个可变参数中。因此,可以使用for循环遍历这个可变参数,获取所有的数据。
大家都知道,通过网络爬虫提取的数据,数据量往往都很大。如果将所有数据都保存到列表或字典中,将会占用大量的内存,严重影响主机的运行效率,这显然不是一个好方法。遇到这种情况,就需要考虑使用迭代器(iterator)了。
迭代器相当于一个函数,每次调用都可以通过next()函数返回下一个值,如果迭代结束,则抛出StopIteration异常。从遍历的角度看这和列表没什么区别,但它占用内存更少,因为不需要一下就生成整个列表。
能够使用for循环逐项遍历数据的对象,我们把它叫做 可迭代对象 。例如列表、字典和rang()函数都是可迭代对象。可以通过内置的iter()函数来获取对应的 迭代器对象 。例如,使用迭代器获取列表中的每个元素,代码如下:
cathy = ["cathy",10,138.5,True,None] iter1 = iter(cathy) #生成迭代器对象 print(next(iter1)) #得到下一个值:"cathy" print(next(iter1)) #得到下一个值:10
在Python中,把使用了yield的函数称为生成器(generator)。生成器是一种特殊的迭代器,它在形式上和函数很像,只是把return换成了yield。函数在遇到return关键字时,会返回值并 结束函数 。而生成器在遇到yield关键字时,会返回迭代器对象,但 不会立即结束 ,而是保存当前的位置,下次执行时会从当前位置继续执行。
下面来看一个著名的斐波那契数列,它以0、1开头,后面的数是前两个数的和,下面展示的是前20个斐波那契数列的数据。
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
下面分别使用普通函数和生成器实现斐波那契数列的功能,以此来说明它们的不同之处。
(1)定义普通函数。
#普通斐波那契函数定义
def get_fibonacci(max): #max:数量
fib_list =[0,1] #保存斐波那契数列的列表,初始值为0和1
while len(fib_list) < max:
fib_list.append(fib_list[-1]+fib_list[-2]) #最后两个值相加
return fib_list
#主函数
if __name__ == "__main__":
#函数调用,输出前10个斐波那契数列的值:0 1 1 2 3 5 8 13 21 34
for m in get_fibonacci(10):
print(m,end=" ")
因为函数只能返回一次,所以每次计算得到的斐波那契数必须全部存储到列表中,最后再使用return将其返回。
(2)使用带yield的函数——生成器。
#使用yield的斐波那契函数定义
def get_fibonacci2(max):
n1 = 0 #第一个值
n2 = 1 #第二个值
num = 0 #记录数量
while num < max:
yield n1
n1,n2 = n2,n1+n2
num+=1
#主函数
if __name__ == "__main__":
#输出前10个斐波那契数列的值:0 1 1 2 3 5 8 13 21 34
for n in get_fibonacci2(10):
print(n,end=" ")
yield一次返回一个数,不断返回多次。先来看一下程序执行的流程图,如图1-10所示。

图1-10 斐波那契数列流程图
【重点说明】
·通过函数get_fibonacci2()实现斐波那契数列时,没有将其保存于列表中,而是通过yield实时将其返回。
·在主函数中,使用for循环遍历生成器。执行第一次循环,调用生成器函数get_fibonacci2(),函数运行到yield时,返回n1,函数暂停执行,并记录当前位置,然后执行for循环的循环体print(n,end=" "),打印n1的值。下一次循环,函数从上次暂停的位置继续执行,直到遇到yield,如此往复,直到结束。
·使用yield可以简单理解为:对大数据量的操作,能够节省内存。
·在使用Scrapy实现爬虫时,为了节省内存,总是使用yield提交数据。
1.类和对象
我们希望尽量将函数和函数所要处理的数据相关联,就跟Python内置的数据结构一样,能有效地组织和操作数据。Python中的类就是这样的结构,它是对客观事物的抽象,由数据(即属性)和函数(即方法)组成。
就像函数必须调用才会执行一样,类只有实例化为对象后,才可以使用。也就是说,类只是对事物的设计,对象才是成品。
以下为描述人这个类的代码示例:
class People: #定义人的类
#构造函数,生成类的对象时自动调用
def __init__(self,my_name,my_age,my_sex):
self.name = my_name #姓名
self.age = my_age #年龄
self.sex = my_sex #性别
#方法:获取姓名
def get_name(self):
return self.name
#方法:打印信息
def get_information(self):
print("name:%s,age:%d,sex:%s"%(self.name,self.age,self.sex))
【重点说明】
·使用class关键字定义一个类,其后接类名People,类名后面接冒号(:)。
·__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法。注意,init两边分别有两个下划线。
·self代表类的实例。在定义类的方法时,self要作为参数传递进来,虽然在调用时不必传入相应的参数。
·类的属性有:name、age和sex。使用属性时要在前面要加上self。
·类的方法有:get_name(self)和get_information(self)。注意,这里要有参数self。
·类的方法与普通的函数只有一个区别,它们必须有一个额外的第一个参数名称,按照惯例它是self。
重申一遍,类只有实例化为对象后才可以使用。例如要生成同学cathy的对象,实现代码如下:
#主函数
if __name__ == "__main__":
#生成类的对象,赋初值
cathy = People("cathy",10,"女")
print(cathy.get_name()) #调用方法并打印,得到:"cathy"
cathy.get_information() #调用方法,得到:name:cathy,age:10,sex:女
【重点说明】
·使用类名People,生成该类的对象cathy,并传入参数cathy,10和“女”。
·实例化为对象cathy时,自动调用__init__()构造函数,并接收传入的参数。
·使用点号(.)来访问对象的属性和方法,如cathy.get_name()。
2.继承
刚才定义了人这个类,如果还想再实现一个学生的类,是否需要重新设计呢?显然这会浪费很多时间,因为学生首先是人,具有人的所有属性和功能,再加上学生独有的一些特性,如年级、学校等即可。因此,我们没有必要重复“造轮子”,只要将人的类继承过来再加上自己的特性就生成了学生的类,这种机制叫做继承,其中学生类叫做子类,人的类叫做父类。类似于“子承父业”,即子类继承了父类所有的属性和方法。
学生类实现代码如下:
class Student(People):
def __init__(self,stu_name,stu_age,stu_sex,stu_class):
People.__init__(self,stu_name,stu_age,stu_sex) #初始化父类属性
self.my_class = stu_class #班级
#打印学生信息
def get_information(self):
print("name:%s,age:%d,sex:%s,class:%s"%(self.name,self.age,self.
sex,self.my_class))
#主函数
if __name__ == "__main__":
#生成Student类的对象
cathy = Student("cathy",10,"女","三年二班")
#打印结果name:cathy,age:10,sex:女,class:三年二班
cathy.get_information()
·Student为学生类的类名,圆括号内是继承的父类。这样,Student类就继承了父类所有的属性和方法。
·在构造函数中,为学生类新增了一个属性my_class,其余属性自动从父类继承而来。不过,需要调用父类的构造函数来初始化父类的属性。
·新增的方法get_information(self)用于输出学生的信息。
1.文件操作
Python提供了文件操作的函数,用于将数据保存于文件中,或者从文件中读取数据。
以下代码实现了将学生列表数据保存到文件中的功能:
#学生列表
students=[["cathy",10,"女"],
["terry",9,"男"]]
#使用with…as…打开文件,文件会自动被关闭
with open("students.txt","a",encoding="utf-8") as f:
for one in students:
#以逗号隔开,连成一个长字符串
to_str = one[0]+","+str(one[1])+","+one[2]+"\n"
f.write(to_str) #将字符串写入文件
【重点说明】
·open()函数用于打开文件,参数有:
·文件名:students.txt。
·打开方式:a表示追加,r表示只读,w表示只写。
·编码方式:utf-8(支持中文)。
·正常情况下,打开文件后,需要手动关闭文件(使用close()函数)。如果使用with…as…打开文件,系统会自动关闭文件。f为open()函数返回的可迭代的文件对象,用于处理文件。
·如果文件不存在,会先自动生成一个空文件。程序运行后,在当前目录下就会生成students.txt文件,文件内容如图1-11所示。
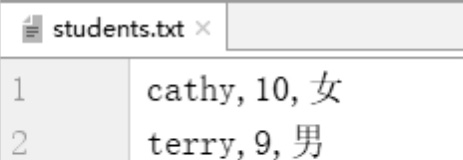
图1-11 文件内容
以下代码实现了从文件中读取数据到列表的功能:
students1 = []
with open("students.txt","r",encoding="utf-8") as f:
for one in f: #f为可迭代文件对象,使用for循环,依次遍历
# 将读取到的字符串去除换行符,再转换为列表
one_list = one.strip("\n").split(",")
one_list[1] = int(one_list[1]) #将年龄转为整型
students1.append(one_list) #增加到学生列表中
#输出结果:[['cathy', '10', '女'], ['terry', '9', '男']]
print(students1)
2.异常处理
上面的代码实现了从文件中读取数据到列表中的功能,但是,如果students.txt文件不存在,程序就会报错。这时可以使用try…except结构捕获异常,并对异常做出处理。
加入异常处理的代码如下:
students1 = []
try:
with open("students.txt","r",encoding="utf-8") as f:
for one in f: #f为可迭代文件对象,使用for循环,依次遍历
# 将读取到的字符串去除换行符,再转换为列表
one_list = one.strip("\n").split(",")
one_list[1] = int(one_list[1]) #将年龄转换为整型
students1.append(one_list) #增加到学生列表中
#输出结果:[['cathy', '10', '女'], ['terry', '9', '男']]
print(students1)
except FileNotFoundError:
print("文件不存在!")
except:
print("其他错误!")
【重点说明】
·当try中的代码模块运行出现异常时,将会执行except中的代码模块。
·except关键字可以有多个,FileNotFoundError代表文件不存在的异常。如果文件不存在,则输出“文件不存在!”;如果是其他错误,则输出“其他错误!”。