
下载掌阅APP,畅读海量书库
立即打开



正确安装Scrapy框架后,就可以创建Scrapy项目,实现第一个网络爬虫了。
现要获取起点中文网中小说热销榜的数据(网址为 https://www.qidian.com/rank/hotsales?style=1&page=1 ),如图3-6所示。每部小说提取内容为:小说名称、作者、类型和形式。
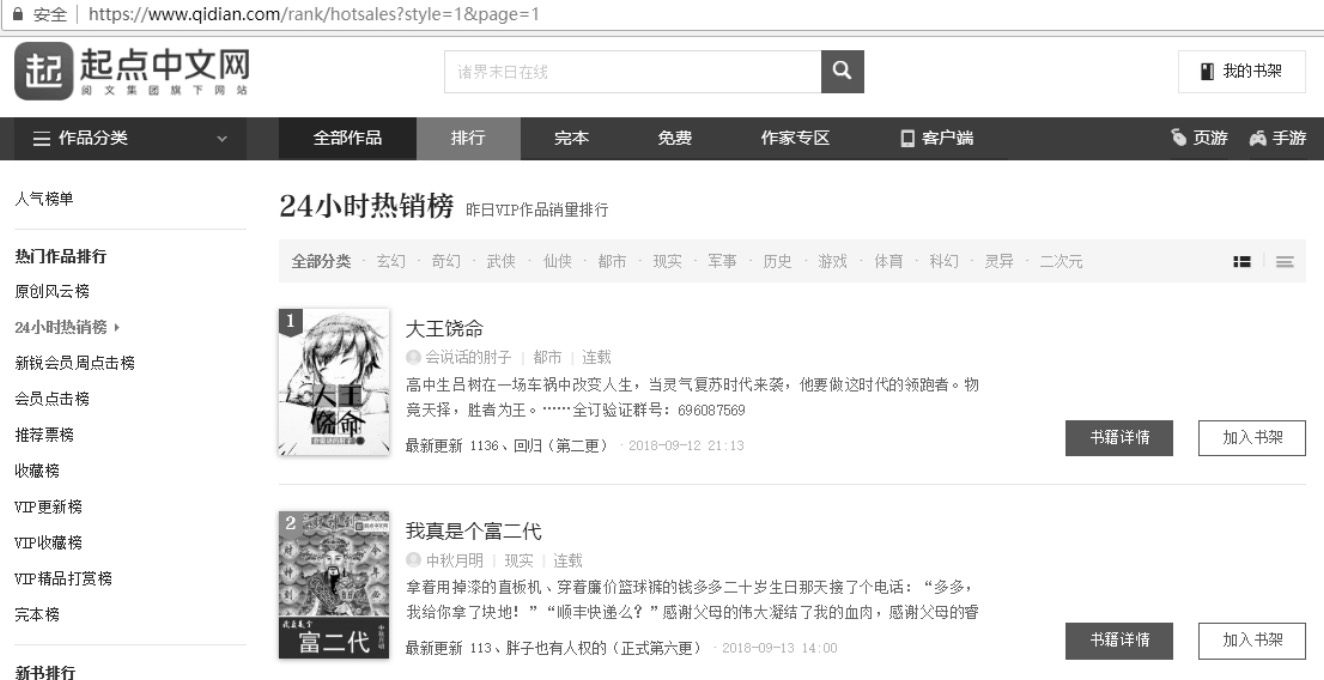
图3-6 起点中文网中24小时热销榜
首先,创建一个爬取起点中文网小说热销榜的Scrapy项目步骤如下:
(1)通过命令行定位到存放项目的目录(如D盘的scrapyProject文件夹)。
>d: >cd d:\scrapyProject
(2)创建一个名为qidian_hot的项目,命令如下:
>scrapy startproject qidian_hot
回车,得到如图3-7所示的创建成功信息。
图3-7 生成Scrapy项目
(3)查看项目结构。
在D盘的scrapyProject目录下,自动生成了qidian_hot项目。使用PyCharm打开项目,如图3-8所示为Scrapy项目的目录结构,它对应于图3-2中Scrapy的框架结构。
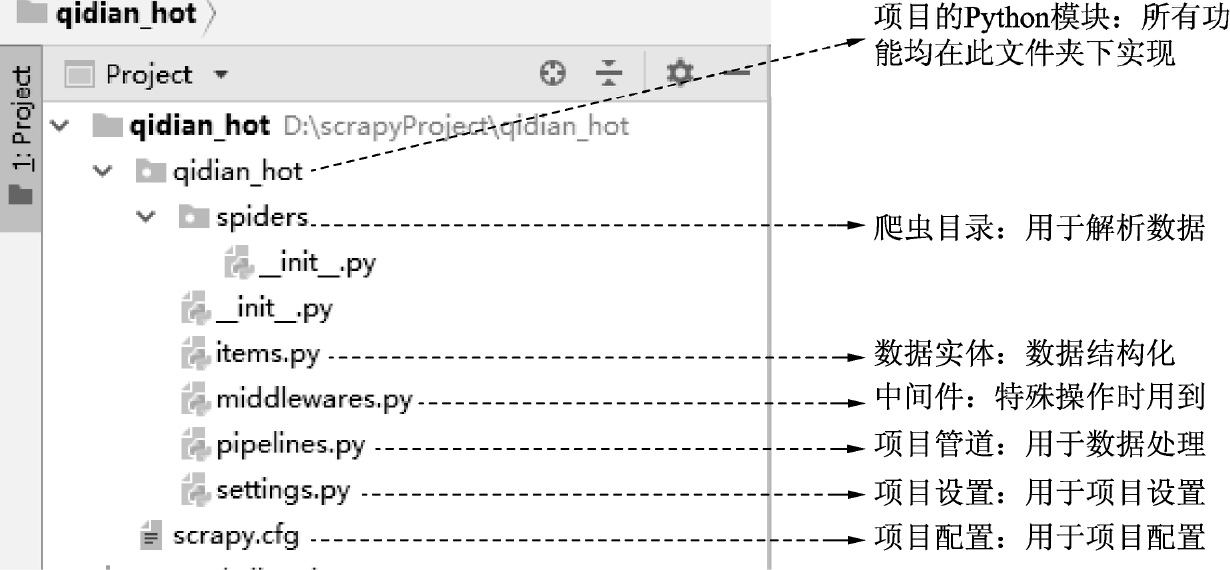
图3-8 Scrapy项目框架
Scrapy中组件的本质是一个个Python源文件,只要在源文件中实现各自的功能,爬虫功能就能自动实现了。
通过Chrome浏览器的“开发者工具”,分析页面的HTML代码,确定数据解析的XPath方法步骤如下:
(1)在Chrome浏览器中,按F12键,显示“开发者工具”栏。
(2)输入网址 https://www.qidian.com/rank/hotsales?style=1&page=1 ,回车。
(3)此时将显示24小时热销榜页面。选择“开发者工具”栏,单击最左边的元素选择按钮,将光标移动到任一部小说内容上并选中,对应的HTML代码<div class="book-mid-info">就会被高亮显示,具体操作如图3-9所示。
(4)分析页面结构。
不难发现,每部小说都包裹在<div class="book-mid-info">元素中,逐层展开,就能定位到小说名称、作者、类型和形式。
·小说名称:div(class="book-mid-info")→h4→a→文本。
·作者:div(class="book-mid-info")→p(第1个)→a(第1个)→文本。
·类型:div(class="book-mid-info")→p(第1个)→a(第2个)→文本。
·形式:div(class="book-mid-info")→p(第1个)→span→文本。
使用XPath获取小说内容,语法如下:
·小说名称:div[@class="book-mid-info"]/h4/a/text()。
·作者:div[@class="book-mid-info"]/p[1]/a[1]/text()。
·类型:div[@class="book-mid-info"]/p[1]/a[2]/text()。
·形式:div[@class="book-mid-info"]/p[1]/span/text()。
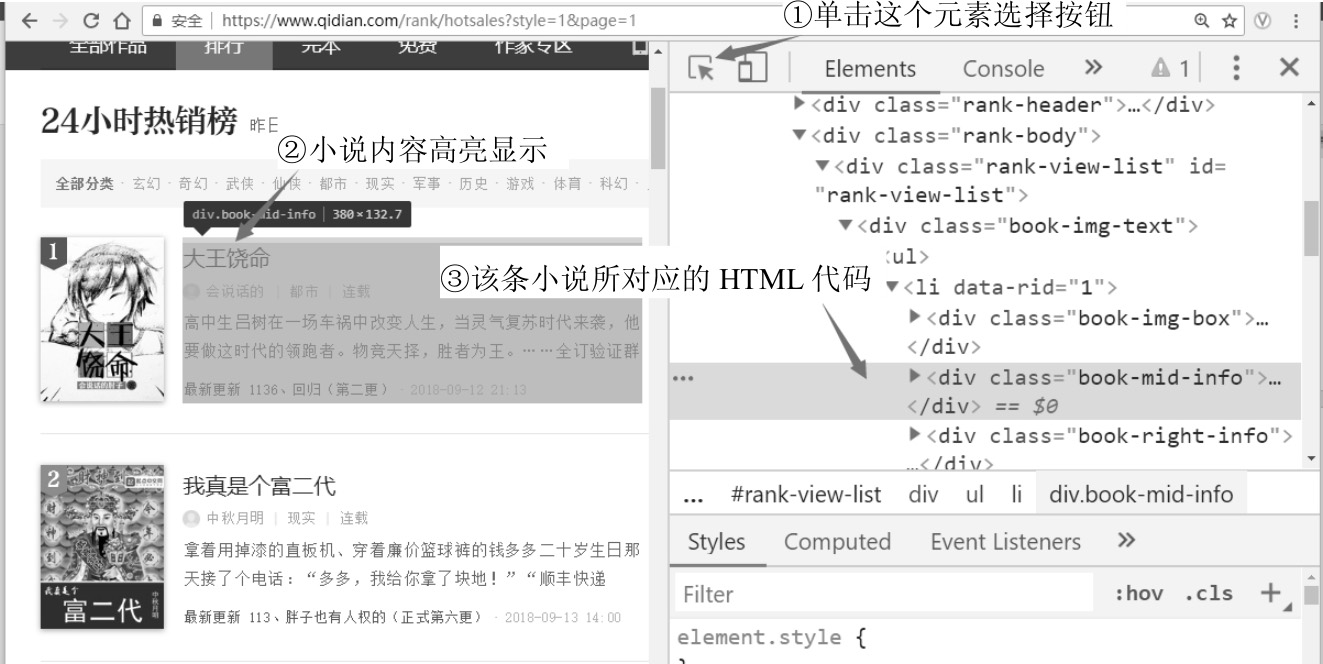
图3-9 获取小说内容对应的HTML代码
下面实现爬虫功能。由图3-8得知,爬虫功能是在spiders目录下实现的。实现的步骤如下:
(1)在spiders目录下新建爬虫源文件qidian_hot_spider.py。
(2)在qidian_hot_spider.py文件中定义HotSalesSpider类,实现爬虫功能。
实现代码如下:
#-*-coding:utf-8-*-
from scrapy import Request
from scrapy.spiders import Spider
class HotSalesSpider(Spider):
#定义爬虫名称
name = 'hot'
#起始的URL列表
start_urls = ["https://www.qidian.com/rank/hotsales?style=1"]
#解析函数
def parse(self, response):
#使用xpath定位到小说内容的div元素,保存到列表中
list_selector = response.xpath("//div[@class='book-mid-info']")
#依次读取每部小说的元素,从中获取名称、作者、类型和形式
for one_selector in list_selector:
#获取小说名称
name = one_selector.xpath("h4/a/text()").extract()[0]
#获取作者
author = one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#获取类型
type = one_selector.xpath("p[1]/a[2]/text()").extract()[0]
#获取形式(连载/完本)
form = one_selector.xpath("p[1]/span/text()").extract()[0]
#将爬取到的一部小说保存到字典中
hot_dict = {"name":name, #小说名称
"author":author, #作者
"type":type, #类型
"form":form} #形式
#使用yield返回字典
yield hot_dict
以上代码虽然添加了不少注释,但相信大家理解起来还是有点困难。不用担心,下一章将会详细讲解,这里先成功运行一个爬虫,建立信心和整体认识即可。
下面简单说明HotSalesSpider的实现方法。
·爬虫所有的功能都是在类HotSalesSpider中实现的,它的基类为Spider。
·类中定义了两个属性:name和start_urls。其中,name为爬虫名称,运行爬虫时需要用到;start_urls中存储的是目标网址的列表。如想要爬取两页热销榜的小说信息,可以将start_urls修改为:
start_urls = ["https://www.qidian.com/rank/hotsales?style=1",
"https://www.qidian.com/rank/hotsales?style=1&page=3"]
类中定义了一个方法parse(),这是爬虫的核心方法,通常完成两个任务:
·提取页面中的数据。
·提取页面中的链接,并产生对链接页面的下载请求。
代码完成后,就可以使用命令执行爬虫了。
(1)通过命令行定位到qidian_hot项目目录下(很重要)。
>d: >cd D:\scrapyProject\qidian_hot
(2)输入爬虫执行命令(hot为爬虫名,hot.csv为保存数据的文件名)。
>scrapy crawl hot -o hot.csv
回车,爬虫程序开始执行,命令提示符中会不断显示爬虫执行时的信息。爬虫执行完后,数据会自动保存于hot.csv文件中。打开hot.csv文件查看数据,如图3-10所示。
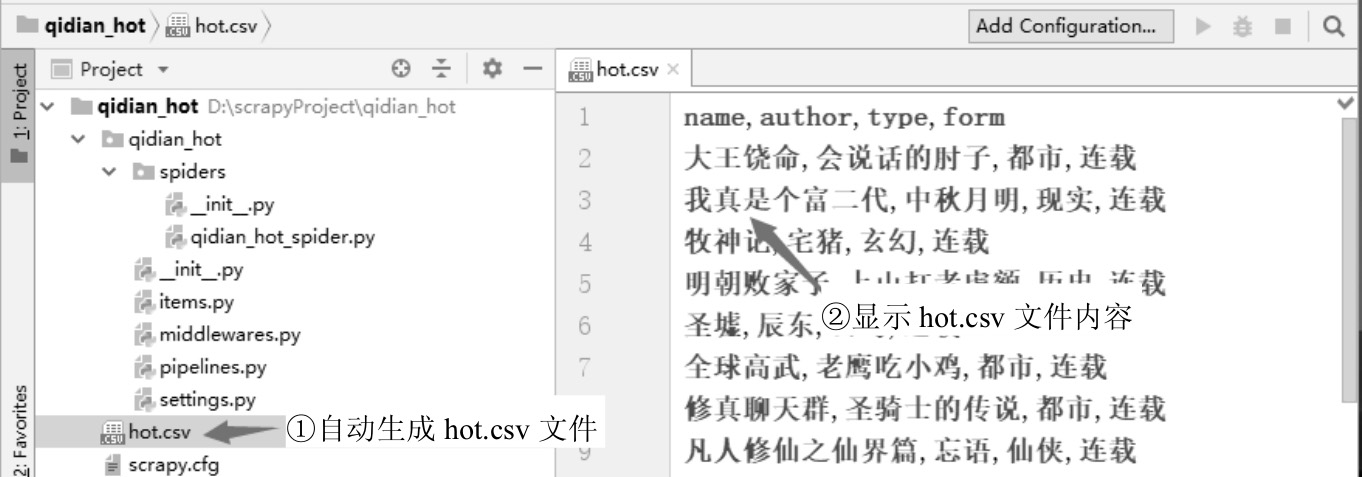
图3-10 生成的CSV文件
需要特别注意的是,爬虫程序不能频繁执行。因为网站一般都有反爬虫措施,如频繁执行会被认定是爬虫程序,网站就会封掉你的IP,禁止访问。关于这个问题,下一章会给出解决方案。
在生成的CSV文件中,有时会发现数据之间会有空行间隔,如图3-11所示。
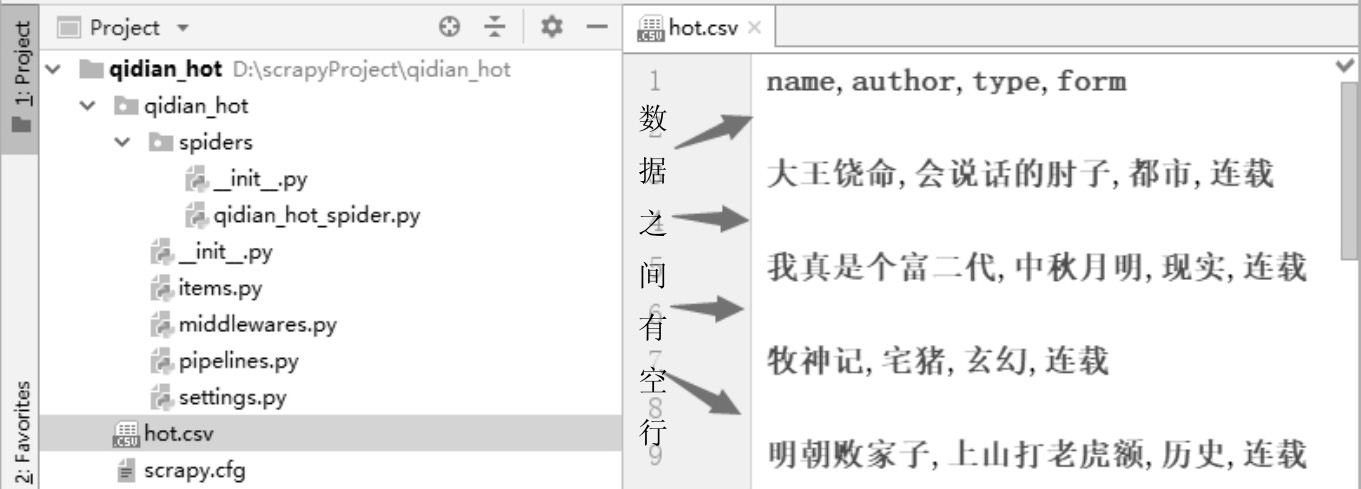
图3-11 有空行的CSV文件
原因:这是Scrapy框架默认的组织形式,即数据之间以空行间隔。
解决方法:修改默认的组织形式。在Anaconda中找到exporters.py(笔者的是在C:\Anaconda3\Lib\site-packages\scrapy目录下)。打开源文件,在类CsvItemExporter中添加一行代码,如图3-12所示。保存文件,重新运行爬虫程序。
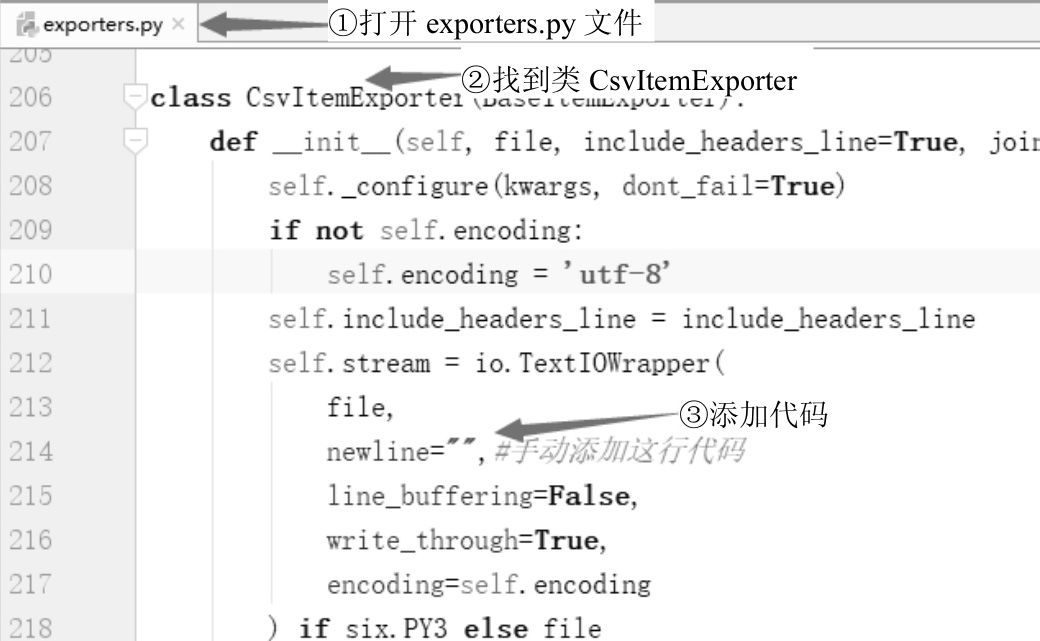
图3-12 手动添加换行形式