
下载掌阅APP,畅读海量书库
立即打开



我们如何认识过去,又将如何确定过去的日期?什么能够帮助我们窥见古代生命的剧院,重建消逝许久的场景和演员,看见它们的离场和入场?传统上,人类历史研究有三种主要方法,而我们将会见到这些方法在进化的大时间尺度上的变体。首先是考古学方法,研究遗骨、箭头、陶片、贝丘(shell mound)
 、小雕塑和其他遗物与遗迹,这些遗存都是来自过去的实体证据。在进化史上,最明显的实体遗存就是骨头和牙齿,还有它们最终形成的化石(fossil)。其次是再生遗存(renewed relics),记录本身也许并不古老,但它包含或承载着某种古老信息的代表或副本。人类历史上那些书面或口头的记述代代相传,不断重复、重印或以别的方式复制更新,从过去一直流传至今。我觉得DNA是进化上最主要的再生遗存,等价于书面复制的记录。第三种方法是三角推断法(triangulation)。这个名字来自一种通过测量角度来判断距离的方法:先测量目标的方位角,然后朝侧面走出一定距离,再测量一次方位角,通过两角的截距便可计算出目标的距离。某些照相机的测距仪用的就是这个原理,而地图测绘员传统上凭借的也是这个方法。通过对某个古代物种传至今天的两种或多种后代进行比较,进化学家们可以推断出该物种的生存年代,可以说这也是一种三角推断法。我将依次介绍这三种实证研究对象或方法,首先从实体遗存开始,具体而言就是化石。
、小雕塑和其他遗物与遗迹,这些遗存都是来自过去的实体证据。在进化史上,最明显的实体遗存就是骨头和牙齿,还有它们最终形成的化石(fossil)。其次是再生遗存(renewed relics),记录本身也许并不古老,但它包含或承载着某种古老信息的代表或副本。人类历史上那些书面或口头的记述代代相传,不断重复、重印或以别的方式复制更新,从过去一直流传至今。我觉得DNA是进化上最主要的再生遗存,等价于书面复制的记录。第三种方法是三角推断法(triangulation)。这个名字来自一种通过测量角度来判断距离的方法:先测量目标的方位角,然后朝侧面走出一定距离,再测量一次方位角,通过两角的截距便可计算出目标的距离。某些照相机的测距仪用的就是这个原理,而地图测绘员传统上凭借的也是这个方法。通过对某个古代物种传至今天的两种或多种后代进行比较,进化学家们可以推断出该物种的生存年代,可以说这也是一种三角推断法。我将依次介绍这三种实证研究对象或方法,首先从实体遗存开始,具体而言就是化石。
有时候尸体或遗骨不知怎的躲过了鬣狗(hyena)、埋葬虫(burying beetle)
和细菌的侵害得以保存下来,从而引起了我们的注意。意大利蒂罗尔(Tyrol)的“冰人”(Ice Man)
在冰川里保存了5 000年,而被包裹在琥珀(即石化的树胶)里的昆虫历经亿年而不朽。没有冰或琥珀的帮助,最有可能被保存下来的只是牙齿、骨头和贝壳这样的硬物,其中牙齿最耐保存,道理显而易见:为了发挥它在生活中的作用,它必须比主人可能食用的任何食物都更坚硬。出于不同的原因,骨头和贝壳也必须坚硬才行,因而它们也能保存很长时间。偶尔这些坚硬部件会被石化形成化石,从而保存上亿年,甚至在极其幸运的情况下,柔软的组织也可以变成化石。近年来,科学家甚至可以利用跟医院检查扫描人体类似的技术,直接扫描包含化石的岩石,为化石分析开辟了一个全新的领域。
不提化石本身的魅力,即便没有它们,我们也依然会对自身的进化史有相当程度的了解,这一点很让人惊奇。假如有神奇的魔法让所有化石都消失,那么通过比较现代生物的相似性,尤其是基因序列相似性在不同物种之间的分布规律,以及比较不同物种在大陆和岛屿之间的分布差异,我们依然能够应对所有合理的怀疑,证明自身的进化史,证明所有现存生物都有血缘联系。神创论者总是不厌其烦地喋喋不休于所谓化石记录的“空缺”,但我们应该记住,化石的存在是一种额外的福利,我们当然乐于接受这样一种福利,但它不是必需的。哪怕化石记录有巨大的空缺,支持进化的证据依然具有压倒性的优势。反过来,如果我们只有化石记录而没有其他证据,进化的事实也依然有不可抗拒的证据支持。实际情况是,两方面的证据我们都有。
按照惯例,“化石”一词指的是任何超过1万年的遗存。这不是一个很有帮助的约定,因为像1万年这样的约数没有任何特别之处,如果人类的手指少于或多于十根,那么我们就会把另外一组不同的数字用作约数。当我们说起“化石”时,通常意味着原先的物质已经被另一种化学成分不同的矿物质渗入或取代,也可以说它们因此从死亡那里获得了新的租约。原先的生物形态留下的印迹在石头里可以保存很久,甚至可能还混合了一些原先的生物物质。化石形成的途径多种多样,在技术上被称为埋葬学(taphonomy),我把其中的细节留给《匠人的故事》,这里先不涉及。
在化石刚被发现和标定地点的时候,其年代还是未知的,这时候我们最多只能对其古老程度进行相对排序,而年代排序依据的是叠覆原理(Law of Superposition)。很显然,如果没有特殊情况,年轻的地层总会覆盖在古老地层的上面。尽管有时候会有例外情形的出现并造成一时的困扰,但通常其成因都相当明显,因而易于识别。比如,一块包含化石的古老岩石,可能因为冰川滑移而被抛到年轻地层的上面,或者一连串地层有可能整体翻转,造成其垂直顺序彻底逆转。只要跟世界其他地方对应的岩石进行比较,就可以识别处理这些异常现象。这一步完成之后,古生物学家就可以利用来自世界各地的重叠交错的化石序列信息,以一种锯齿状的方式拼出全体化石记录的真正顺序。原理虽然并不复杂,但由于世界地理格局本身在随着时间变迁,实际操作起来要复杂得多,我们将会在《树懒的故事》里阐明这一点。
为什么必须是锯齿状的拼接?为什么不可以直接往下挖掘,不管挖多深都把它看作在逆着时间匀速上溯?时间本身的流逝或许是匀速的,但这并不意味着世界任何地方的沉积层都平缓连续地贯穿整个地质史。化石层的沉积是断断续续的,只有条件合适的时候才有可能发生。
如果任意指定一个地点和一段时间,很可能找不到沉积岩,也就不会有化石。但如果只是任意指定一段时间,则非常可能在世界某个地方找到化石沉积。世界上不同的地方会有不同的地层碰巧接近地表方便挖掘,古生物学家就可以从一个地方来到另一个地方,有望拼出一个近乎连续的记录,为相对地质年代立下名副其实的基石。当然,没有哪个古生物学家可以遍历所有化石沉积地点逐个挖掘。他们或者穿梭于博物馆之间,考察抽屉里的样本,或者翻阅大学图书馆里的期刊,研读关于化石的书面记录,这些记录还会含有化石发现地点的详细标注。凭借这些描述信息,他们就可以把来自世界各地的碎片拼成一张完整的图。
事实上,岩石特征明确易识别且总是包含同一类化石的地层会在不同地区反复出现,这让古生物学家的工作变得更简单了。举个例子,下页图左下部分标注的“泥盆纪”(Devonian)得名于美丽的德文郡(Devon)出产的古老红色砂岩,同样的岩石也出现在不列颠群岛、德国、格陵兰岛、北美等许多其他地方。不管来自哪里,泥盆系岩石总会被认为属于泥盆纪,部分是因为岩石自身的特点,同样也是因为它们内部所包含的化石证据。这听起来像是循环论证,但其实并不是。就像学者利用《死海古卷》(Dead Sea Scroll)中的内部证据来论证它是《撒母耳记上》(First Book of Samuel)残篇一样,某些特征性化石的存在也能可靠地标记出泥盆系岩石的身份。
截至最早有硬体化石出现的时期,同样的办法也适用于其他地质时期的岩石。从古老的寒武纪(Cambrian)到今天所在的第四纪(Quarternary),我们刚刚看过的地质年表中所列的各个地质时期大都是基于化石记录的变化进行分期的。因此,一个时期的结束和另一个时期的开始常常是根据明显打断了化石记录连续性的灭绝事件分界的。用斯蒂芬·杰伊·古尔德的话说,没有哪个古生物学家会分不清一块岩石是早于还是晚于二叠纪末的大灭绝,因为灭绝之前和之后的动物类型几乎不存在任何重叠。确实,化石(特别是微型化石)在岩石的标记和定年过程中作用巨大,这一方法的主要使用者甚至还包括了石油业和采矿业。
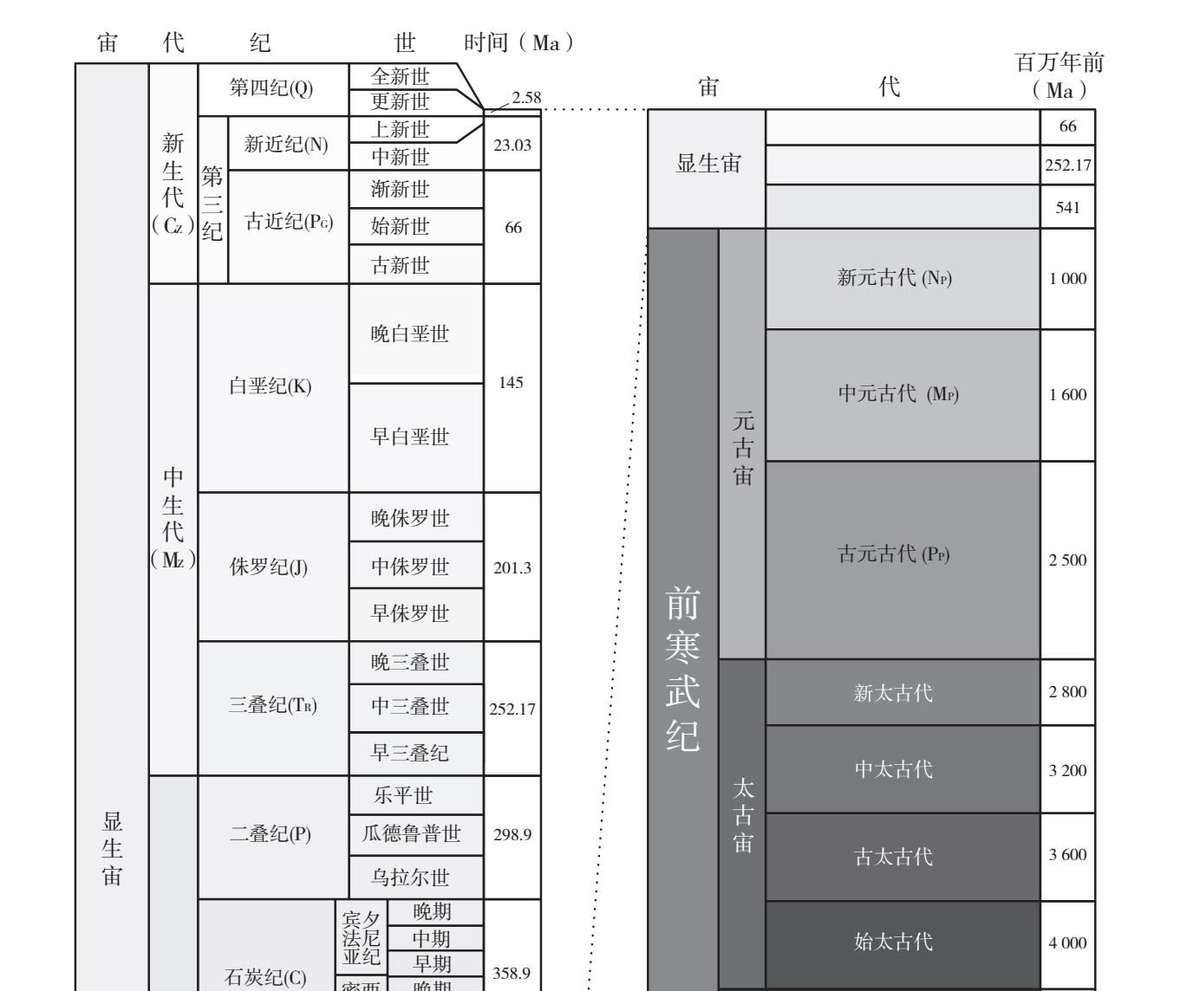
本图是国际地层委员会(International Commission on Stratigraphy)地质年代表的简化版本。 图中阴影代表的是年代的久远程度(颜色越浅距今越近,越深距今越远)。地质年代被分为宙(eon)、代(era)、纪(period)和世(epoch)。时间单位是“百万年前”(Ma)。请注意图中“第三纪”(Tertiary)已经不再是官方用语了,但有些地质学家认为应该重新将之投入使用,因此我们在这里也把它标了出来。“宾夕法尼亚纪”(Pennsylvanian)和“密西西比纪”(Mississippian)被美国地质学家用作石炭纪的代名词。该年表的下限仍然没有正式确定,尽管一般认为它远至46亿年前,即地球和太阳系其他部分初形成的时候。
通过将岩石记录以锯齿状垂直拼接,人们早就建立了测定岩石相对年龄的方法。在绝对定年技术出现之前,人们出于相对定年便利性的考虑,便为各个地质时期命名。相对定年法直到今天也依然有用。不过,对于所含化石比较稀少的岩石,相对定年就比较困难了,而这包括了所有形成于寒武纪之前的岩石,差不多相当于前九分之八的地球历史。
本书中的年代大多采用“百万年前”(millions of years ago)这一单位(希腊拉丁写法为“megaannums”,简写为Ma,这种写法不优雅,而且有误)。但这种绝对纪年法是相当晚期才出现的进展,靠的是最近物理学特别是放射物理学的发展。我们需要对这些方法做些解释,不过更多的细节需留待《红杉的故事》来展示,目前我们只要知道,现在有一系列可靠的方法给化石或者包裹化石的岩石标定绝对年龄。这些方法各有不同的灵敏度,覆盖了数百年(树木年轮)、数千年(碳–14定年法)、百万年、亿年(铀–钍–铅定年法)乃至数十亿年(钾–氩定年法)等全部年代范围。
就像考古标本一样,化石多多少少算是来自过去的直接遗存。我们接下来要转向第二类历史证据,即一代代复制传递的再生遗存。对研究人类史的历史学家来说,再生遗存指的可能是通过传统的口头叙事或书面文字记录流传下来的目击证词。要想了解生活在14世纪的英格兰是种什么体验,我们并没有活着的目击者可供咨询,但幸亏我们有包括乔叟作品在内的书面文件。这些文件包含的信息可以被复制,被印刷,被储藏在图书馆里,被重印分发,今天我们还可以读到它们。一个故事一旦被印刷,或者像今天这样被储存进某种计算机媒介,那么它的副本就有相当大的机会长存不朽,流传至遥远的未来。
书面记录和口头传承的可靠性有极大的差异,前者可靠得多。就像我们了解自己的父母一样,你也许认为每一代孩子都了解他们的父母,也会认真聆听父母讲述过往的故事细节,然后再转述给下一代。你大概会觉得,如此这般五代以后,会有大量口头传承保存下来。实际上,我虽然还清楚地记得自己的四位祖辈,但对自己的八位曾祖辈却只知道寥寥无几且支离破碎的几件逸事。我有一位曾祖父会习惯性地哼一支无名小调(我也会哼),而且只在系鞋带的时候哼。第二位非常贪吃奶油,而且输棋的时候会掀棋盘。第三位是一名乡村医生。这就是我所知的全部。八个完整的人生是如何被削减到只剩下这么一点的?即使我们跟当事人之间的传话链条是这么短,即使人类语言是如此丰富,组成八个完整人类生命的成千上万个私人细节还是这么快就被遗忘了,这是如何发生的?
令人沮丧的是,口头传承往往很快消亡殆尽,除非被吟游诗人的词句神化,就像荷马写下的那些篇章一样,即便如此,关于那个时期的历史也很难称得上准确。它会渐渐退化为不知所云的虚假传说,而这个过程快得惊人,甚至用不了几代人的时间。关于真实存在的英雄和恶棍、动物和火山的历史事实会快速退化(或者升华——这取决于你的口味)为关于半神和恶魔、半人马和喷火龙的神话。
不过我们不必为口头传承及其不完美性耽搁太久,毕竟在进化史上没有类似口头传承的现象。
书写是一种巨大的进步。纸张、莎草乃至石板都可能会腐朽风化,但书面记录却有可能被准确复制无穷多代,尽管实际上复制并不是百分之百准确的。我需要解释一下,我所说的“准确”和“代”都有特定的含义。如果你手写一张便条给我,然后我抄了一份传给第三个人(即下一“代”复制者),我写的副本并不是原先版本的精确复制,因为我们的字体不一样。如果你写得足够细心,而我又煞费苦心地从我们共享的字母表里找到一个字母匹配上你每一个潦草的笔画,那你的信息有很大机会被完全准确地复制。理论上,这种准确性可以历经无穷多代传抄而依然保存,因为作者和读者有一份约定的字母表,而且字母表是离散的,所以复制才能使信息在原稿损毁之后依然存在。书写的这种性质被称为“自规范”(self-normalising)。书写之所以有这种性质,是因为字母表是非连续的。这种说法让人想起模拟信号和数字信号的区别,关于这一点,需要再多解释几句。
在英语硬辅音
c和g之间存在一个中间辅音(即法语的硬辅音c,如法语单词comme里的c)。但没人想着用一个看起来介于c和g之间的字符来表示这个发音。我们都知道英语的书面字母必须是字母表里26个字母中的一员,我们也知道法语使用的是同样的26个字母,但它们表示的发音却不完全一样,其中某个发音可能介于英语的两个发音之间。在各种语言乃至各种地方口音或方言中,字母表都“自规范”到不同的发音上。
自规范机制可以对抗“中国式耳语”(Chinese Whispers)
造成的信息代际衰减。一幅画也可以由一群艺术家进行一连串的仿制临摹,却没有同样的机制保护其中的信息免于衰减,除非这幅画的绘画风格包含了某种仪式化的传统来充当它的自规范机制。历史事件的目击证词不同于绘画,一旦书于纸面,就有很大的机会保持准确,甚至几个世纪之后的历史书依然能够准确地复述它。我们今天仍然可以大概准确地描述出庞贝城(Pompeii)在公元79年的毁灭
,这要归功于一个名叫普林尼(Pliny)的年轻目击者,他在寄给历史学家塔西陀
的两封信里记下了自己看到的景象。经过一代代的传抄,塔西陀的部分著作流传了下来,最终被印刷出版,使我们今天可以读到。哪怕是在谷登堡
之前的年代,文件的复制全凭抄写,跟记忆和口头传承比起来,书写依然代表着准确性的巨大进步。
不断复制却依然保持完美的准确性,这是只存在于理论中的理想情况。实际上抄写很容易犯错,更不必说抄写者会调整自己的抄本,使之能够更加“如实地”反映他所理解的原意。最著名的例子是对《圣经·新约全书》历史的修订,使之更符合《圣经·旧约全书》的预言,19世纪的德国神学家对此曾有不辞辛劳的详述。该研究涉及的那些抄本或许不是故意编造的谎言。那些福音的作者生活的年代距离耶稣之死已经很久了,而他们真心地相信耶稣是《圣经·旧约全书》中弥赛亚预言的化身,因此他“必须”出生于伯利恒(Bethlehem),“必须”是大卫(David)
的后代,如果文献居然莫名其妙地没有这么写,那么一个尽职尽责的抄写员就有义务纠正这一缺陷。我猜,就像我们会理所当然地更正一个拼写错误或语法不当,一个虔诚的抄写员也不会将这种“纠正”视为伪造。
跟有意的修改不同,一切重复、复制过程都难免发生一些诸如串行、漏词这样的低级错误。但不管怎样,我们不能指望书写资料带我们回到文字发明之前的时代,而文字的历史只有5 000年左右。标识符、计数符和图画更古老一些,大约有几万年的历史,但这些跟进化的时间尺度比起来依然是微不足道的。
幸运的是,涉及进化时有另一种复制信息,它也经历了许多代的重复拷贝,复制代数简直超乎想象,若以略带一点诗意的眼光去看它,我们可以认为它等价于书面文字:就像一份历史记录一样,它不断更新,传抄了许多亿代,却依然保持了惊人的准确度,因为就像我们的书写系统一样,它也有一份自规范的字母表。所有现存生物的DNA分子都来自远古的祖先,有着令人咋舌的保真度。DNA分子中的原子固然在不断更新,但它所编码的信息却被复制了数百万年,有时候甚至达到数亿年。我们可以凭借现代分子生物学技术直接读取这份记录,一个字母一个字母地逐字读出DNA的拼写序列,或者采用稍微间接的方法,读出它们编码的蛋白质的氨基酸序列。或者我们可以采用更间接一些的方法,就像隔着毛玻璃一样,研究DNA的胚胎产物,从中读取有关信息,包括个体的外形、器官以及生化反应。不需要依赖化石,我们同样可以窥见历史。由于DNA的代际改变非常缓慢,历史实际上以它独有的字符编码被铭刻编织进了现代动植物的脉络纤维里。
DNA信息的书写有一套名副其实的字母表。就像罗马、希腊和斯拉夫书写系统一样,DNA的字母表是一个严格限定的字符集,其中的字符是人为规定的,因此并没有不言自明的含义。人为选择的字符被组合起来之后能够表达无限复杂和无限量的信息。英语字母表里有26个字母,希腊字母表里有24个,但DNA的字母表只有4个字母。许多至关重要的DNA序列片段只包含3个字母组成的单词,而这些3个字母组成的单词又都来自一部仅有64个词的字典。字典里的每个词都是一个密码子(codon),这些密码子当中有一些是同义词。也就是说,这些遗传密码实际上是“简并的”
。
这部字典给这64个密码赋予了21种含义:20种生物体所需的氨基酸,加上一个万能的标点符号。人类语言数不胜数,而且在持续变化,字典里有数以万计的不同词汇,但DNA那个普适的字典只有64个单词,而且基本上一成不变(只在极其罕见的情况下有非常细小的变化)。这20种氨基酸连缀成串,每一串都是一个特定的蛋白质分子,长度通常为数百个氨基酸。尽管只有4个字母和64个密码子,但密码子的不同序列所能编码的蛋白质数目却是不计其数的,没有理论上限。一串密码子组成“一段话”,编码一个特定的蛋白分子,构成一个可识别的单元,这个单元通常被称为“基因”。一个基因和它的邻居(或许是另一个基因,或许是无意义的重复序列)之间并没有任何分隔符,其边界只能通过其序列本身来判断。但从这一点看,它们有点像缺少标点符号的电报报文,不过电报还会在词和词之间留空格,而DNA并没有。
跟书面语不同,DNA序列中有意义的片段好像孤岛一样被无意义的海洋隔开,那些无意义片段从来不会被转录(transcribe)
。有意义的外显子(exon)在转录过程中被组装成“完整的基因”,而无意义的内含子(intron)序列直接被阅读装置丢弃。在许多情况下,即便是有意义的DNA片段,其信息也从来不被读取,也就是说这些基因很可能已经作废了,虽然曾经有用,但它们现在只是待在那里而已,就像杂乱的硬盘里存放着某一书稿章节的早期版本。在阅读本书时把基因组想象成一个亟需整理的旧硬盘,确实会时不时有所帮助。
有必要再次重申,对于死亡很久的动物来说,其DNA分子本身并不会保存下来。可以永久保存的是DNA所包含的信息,而且其保存必须借助频繁的复制。《侏罗纪公园》的剧情设定虽然不无聪明,但在实践上却是不可行的。当然,吸了恐龙血的昆虫在被裹进琥珀之后的一小段时间里,其体内确实含有复活一只恐龙所需的必要信息,特别是化石证据表明恐龙的红细胞包含DNA(这一点跟它们的后裔鸟类一样,却和我们哺乳动物不同)。另外,有些生物分子确实有可能保存几千万年,比如,研究者从一只4 600万年前的蚊子化石里提取出了血红蛋白样的化学物质,甚至令人难以置信地从一根7 000万年前的恐龙骨头里提取出了胶原蛋白。但这都是些小而稳定的物质,脆弱的长链DNA完全是另外一回事。一旦缺少持续的维护,DNA就开始崩解破碎,用不了几年就衰败得一塌糊涂,对于一些软组织来说,甚至用不了几天就完全无法解读其中的DNA信息了。
DNA信息衰减直至消亡的过程难以逆转,但寒冷缺氧的条件确实可以在一定程度上减缓这一过程。目前有记录的最古老的基因组是从一根有70万年历史的马骨中提取出来的,加拿大的永久冻土使之得以保存。即使在冰点以上,冰冷而稳定的环境也可以将DNA保存数十万年之久。从冰冷洞穴中发掘出来的遗骨向我们提供了数量不等的古人类DNA,其中最为惊人的是5万年前一名近亲繁殖的尼安德特人的完整基因组(我们后面将会介绍)。想象一下如果有人成功把她克隆出来,将引起怎样的轰动!不过,虽然从人类生活的角度看,不管几十万年还是几万年都是相当长的时间跨度,但和我们前往过去的旅程比起来,它们只占了其中一小部分。唉,化学规律告诉我们,我们理论上能获得的可识别的古代DNA的年龄上限只有几百万年,显然不足以带我们回到恐龙时代。
关于DNA很重要的一点是,只要生物繁殖的链条没被打破,那么它所编码的信息就会在旧分子破坏之前被复制到一个新的DNA分子上去。通过这种方式,DNA编码的信息的寿命远远超出DNA分子本身。DNA之中的信息是可以复制更新的,而且每次复制时大多数字母都可以得到完美的复制,因此这些信息也就具备了无限保存的潜力。我们祖先的DNA信息有许多经由一代代活生生的个体传递至今,分毫未改,有些甚至经历了数亿年的光阴。
以这种方式去看DNA,它所记录的信息对于历史学家来说简直是一个丰盛得难以置信的馈赠。哪个历史学家敢于奢求这样一个世界,里面每个物种的每个个体都随身携带着一份代代相传的书面文档,冗长而详尽?甚至文档的内容还会发生随机的变化,变化发生的频率足够低,不至于把记录搞乱,又足够高,可以生成标新立异的新版本。其妙处还不止于此。文档的内容并不是任意的。我在《解析彩虹》( Unweaving the Rainbow )一书中提出了一个达尔文主义的观点,把动物的DNA看作“死者的遗传之书”,一部对祖先世界的描述性记录。这个说法依据的是一个事实,即在达尔文主义进化过程中,任何一个动物或植物的外形、先天行为乃至细胞生化活动都是一篇密文,其中包含了它的祖先所生存的世界的相关信息:它们寻觅什么样的食物,摆脱什么样的天敌,耐受什么样的气候,引诱什么样的配偶,等等,这一切信息最终都写入了DNA,又通过了一连串自然选择。我们知道海豚的祖先曾经在陆地上生活,向我们泄露秘密的是海豚特殊的解剖和生理特点。将来有一天等我们学会了正确地解读DNA包含的信息,也许它们的DNA会向我们再次确认这一点。4亿年前,所有陆生脊椎动物的祖先,包括陆生的海豚祖先,离开了生命自起源之时就一直栖居的海洋。毫无疑问,我们的DNA里记录了这个事件,只是我们还不懂得如何解读。任何一只现代动物,它的一切,它的肢体、心脏、大脑和繁殖周期,尤其是它的DNA,全都可以被看成一份文档,一部关于它的过去的编年史,尽管这部编年史是一部被复写了许多遍的抄本。
DNA的编年史也许是赠予历史学家的礼物,但它并不容易解读,需要有理有据地深入解读。若是能够跟我们的第三种历史重建方法结合起来,它会变得更为有力。所以我们现在来看看这种方法,而且我将再次以人类历史中的类似情况做类比,具体而言是和语言的历史相类比。
语言学家经常希望能够逆着历史追溯各种语言的演变。如果有现存的书面记录,那么这是一件相当容易的任务。语言历史学家可以用我们重建历史的第二种方法,追踪再生遗存的变化。借助连续的文学传承,从莎士比亚到乔叟再到《贝奥武甫》
,现代英语可以回溯到中古英语(Middle English)再到盎格鲁–萨克逊语(Anglo-Saxon)。很显然语言本身的历史远远早于书写的发明,更何况很多语言根本没有发展出文字。对于已经消亡的语言来说,语言学家研究它们的早期历史所借助的方法正是我所称的“三角推断法”的一个变体。他们比较现代语言的差异并对其分组,把它们分层级地归入不同的语系和语族。罗曼语族(Romance)、日耳曼语族(Germanic)、斯拉夫语族(Slavic)、凯尔特语族(Celtic)和其他一些欧洲语族、印度语族一起构成印欧语系(Indo-European)。语言学家相信,真实存在过一种原始印欧语(Proto-Indo-European),在大约6 000年前,它曾是某个部族的口语。他们甚至基于其现代后裔的共通之处进行逆推,试图复现这门语言的诸多细节。同样的方法还被用于回溯世界其他地方跟印欧语系同级别的各语系,比如阿尔泰语系(Altaic)、达罗毗荼语系(Dravidian)、乌拉尔–尤卡吉尔语系(Uralic-Yukaghir)等。有些语言学家持有一种乐观却颇有争议的观点,他们相信可以继续回溯,将所有这些主流语系纳入一个包容力更强的超语系。他们坚信通过这种方法可以重建出一种原始语言以及它的各个要素,他们称之为“诺斯特拉语”(Nostratic),认为它曾作为口语存在于1.5万年前到1.2万年前。
许多语言学家一方面乐于认可原始印欧语和同级别的其他古语言的存在,另一方面却怀疑是否真的可能重现像诺斯特拉语这样古老的语言。他们的专业质疑也加强了我本人作为业余者的怀疑。不过毫无疑问的是,类似的三角推断法可以用于研究进化的历史,以各种技术手段对现代生物进行比较,穿越亿万年的光阴。即便没有化石,通过对现代动物进行细致的比较,我们依然可以清楚可靠地重建出它们的祖先。语言学家可以依据现代语言复现已经消亡的语言,凭借三角推断法穿透历史,揭秘原始印欧语,我们也可以做同样的事,只不过将比较对象换成现代生物的外部特征、蛋白质或DNA序列。当世上的图书馆积累的物种精确DNA长序列越来越多,我们进行三角推断的可靠性也会随之提高,特别是这些DNA序列有着大面积的重叠,这对我们尤为有利。
请允许我解释一下我所说的“大面积的重叠”是什么意思。哪怕物种的关系极其疏远,比如人类和细菌,也依然能明确地找到大段相似的DNA。至于关系非常近的物种,比如人类和黑猩猩,相同DNA序列就更多了。如果你挑选分子进行物种间比较的时候足够精明,你会发现物种间共享DNA的比例随着血缘接近的程度而稳定连续上升,从不间断。远到人类和细菌,近到两种不同的蛙类,用于比较的分子需要覆盖整个比较的谱系。而两种语言之间的相似性就比较难判断了,除非这两种语言本身就很接近,比如德语和荷兰语。有些语言学家满怀希望地推论出诺斯特拉语的存在,可他们的推理链条过于细弱,其中所谓的联系正是另一些语言学家质疑的对象。拿人类和细菌去做三角推断得到的会不会是DNA版本的诺斯特拉语?人类和细菌的确有些共同的基因,自它们的“诺斯特拉”,即二者的共同祖先存在以来就几乎不曾改变。而且,既然遗传密码在所有物种之间几乎完全一样,那么生物共同的祖先所采用的必然也是相同的密码。也许你可以这么说,任何一对哺乳动物之间的相似性就好比德语和荷兰语之间的关系。而人类和黑猩猩的DNA是如此相似,就好比同样是英语,只是口音略微有些差异。而英语和日语之间或西班牙语和巴斯克语之间的差异太大,没有哪对活着的生物可以用来类比,就连人类和细菌都不行。人类和细菌的DNA序列相似到什么程度?就好比整段话每个词都一样。
我一直在讲DNA可以用于三角推断。理论上,用粗略的形态学特征也可以进行同样的推断,但缺少了分子层面的信息,推断出来的远祖就会像诺斯特拉语一样难以捉摸。跟用DNA推断一样,依据形态特征,我们也可以假设后代共有的那些特点很可能(或者稍微倾向于可能而非不可能)遗传自共同的祖先。比如,所有脊椎动物都有一根脊柱,我们假定它们都是从同一个远祖那里遗传了脊柱(严格来讲是遗传了那些负责形成脊柱的基因)。从化石记录来看,这位拥有脊柱的远祖大概生活在5亿多年以前。本书正是用这种形态学三角推断来帮助大家想象共祖的身体形态。尽管我情愿更多倚重DNA证据直接推断共祖的形态,但目前我们的能力尚不足以让我们根据一个基因的变化推断它对生物体形态的影响,因此也不足以完成这个任务。
纳入许多物种进行三角推断将会更加有效,但这要求我们采用许多细致的方法,而应用这些方法的前提是建立准确的系谱图。我们将在《长臂猿的故事》中介绍这些方法。三角推断本身还有助于建立另外一种技术,用来计算任何一次进化分支产生的年代,即“分子钟”(Molecular Clock)技术。简单来说,这种方法是对现存物种的分子序列差异性进行计量。血缘相近的物种有相对晚近的共同祖先,其序列差异就小于关系疏远的物种之间的差异。因此,两个物种共同祖先的年龄就跟二者的分子差异成正比,至少我们是这样希望的。借助几个年代已知的关键分支点,以及这个时期碰巧存留的化石,我们就可以对分子钟的时间尺度进行标定,把它转换成真实的年份。实践上并没有这么简单,《天鹅绒虫的故事》后记里讲的主要就是在这个过程中遇到的各种复杂情况、诸多困难和相关的争论。
乔叟在他著作的总序里逐个介绍了朝圣之旅的所有出场人物,可我的出场角色表实在太长了,没法逐一介绍。不管怎么说,这本书本身就是对40个会合点所做的一连串长长的介绍。不过,一个初步的介绍仍然是必要的,只是我采用的方式并不是乔叟式的。他的出场角色表里是一个个的人,我的则是一串类别。这里有必要介绍一下动植物的分类法。比如在第11会合点,会有大约2 000种啮齿目动物(rodent)和90种穴兔(rabbit)、野兔(hare)、鼠兔(pika)加入我们的朝圣,它们统称为啮齿动物(Glires)。我们对这些物种以层级的方式进行分组,并为每个组赋予独特的名字。比如,形态跟家鼠相似的啮齿目动物被归入鼠科(Muridae),而像松鼠的啮齿目被归入松鼠科(Sciuridae)。这种分组的每个层级都有自己的名字,鼠科和松鼠科都是科(family),而啮齿目(Rodentia)是它们所属的目(order)的名字。啮齿目再加上各种兔类就构成了一个统称为啮齿动物的总目(superorder)。这些分类组别共同构成一个层级系统,而科和目位于层级中间的位置。各个物种接近层级的底部,而从种往上有属、科、目、纲、门等,此外还有“亚”和“总”这样的前缀来填补各级中间的位置。
就像我们将在不同的故事中看到的那样,物种处于一个特殊的地位。每个物种都有一个独一无二的拉丁学名,由两个词组成。第一个词是首字母大写的属名,紧跟着是小写的种名,两个词都用斜体字。豹子、狮子和老虎都是豹属( Panthera )的物种,其学名分别为 Panthera pardus , Panthera leo 和 Panthera tigris 。豹属隶属于猫科(Felidae),后者又依次属于食肉目(Carnivora)、哺乳纲(Mammalia)、脊椎动物亚门(Vertebrata)和脊索动物门(Chordata)。关于分类学原理,我在这里不再赘述,而会在本书随后需要的时候详述。