
下载掌阅APP,畅读海量书库
立即打开



XSS的防御是复杂的。
流行的浏览器都内置了一些对抗XSS的措施,比如Firefox的CSP、Noscript扩展,IE 8内置的XSS Filter等。而对于网站来说,也应该寻找优秀的解决方案,保护用户不被XSS攻击。在本书中,主要把精力放在如何为网站设计安全的XSS解决方案上。
HttpOnly最早是由微软提出,并在IE 6中实现的,至今已经逐渐成为一个标准。浏览器将禁止页面的JavaScript访问带有HttpOnly属性的Cookie。
以下浏览器开始支持HttpOnly:
 Microsoft IE 6 SP1+
Microsoft IE 6 SP1+
 Mozilla Firefox 2.0.0.5+
Mozilla Firefox 2.0.0.5+
 Mozilla Firefox 3.0.0.6+
Mozilla Firefox 3.0.0.6+
 Google Chrome
Google Chrome
 Apple Safari 4.0+
Apple Safari 4.0+
 Opera 9.5+
Opera 9.5+
严格地说,HttpOnly并非为了对抗XSS——HttpOnly解决的是XSS后的Cookie劫持攻击。
在“初探XSS Payload”一节中,曾演示过“如何使用XSS窃取用户的Cookie,然后登录进该用户的账户”。但如果该Cookie设置了HttpOnly,则这种攻击会失败,因为JavaScript读取不到Cookie的值。
一个Cookie的使用过程如下。
Step1:浏览器向服务器发起请求,这时候没有Cookie。
Step2:服务器返回时发送Set-Cookie头,向客户端浏览器写入Cookie。
Step3:在该Cookie到期前,浏览器访问该域下的所有页面,都将发送该Cookie。
HttpOnly是在Set-Cookie时标记的:

需要注意的是,服务器可能会设置多个Cookie(多个key-value对),而HttpOnly可以有选择性地加在任何一个Cookie值上。
在某些时候,应用可能需要JavaScript访问某几项Cookie,这种Cookie可以不设置HttpOnly标记;而仅把HttpOnly标记给用于认证的关键Cookie。
HttpOnly的使用非常灵活。如下是一个使用HttpOnly的过程。

在这段代码中,cookie1没有HttpOnly,cookie2被标记为HttpOnly。两个Cookie均被写入浏览器:
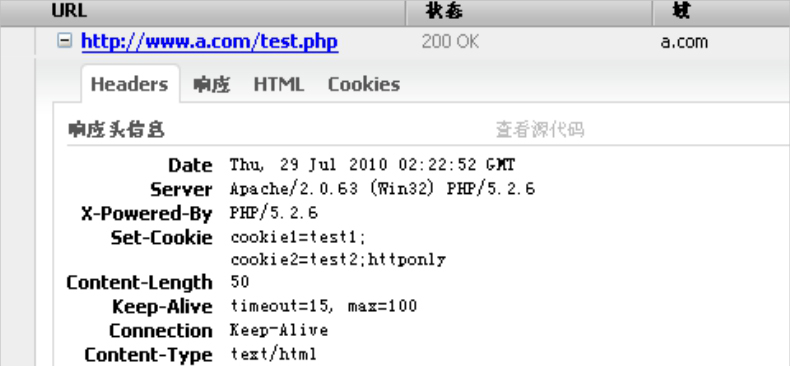
测试页面的HTTP响应头
浏览器确实接收了两个Cookie:

浏览器接收到两个Cookie
但是只有cookie1被JavaScript读取到:
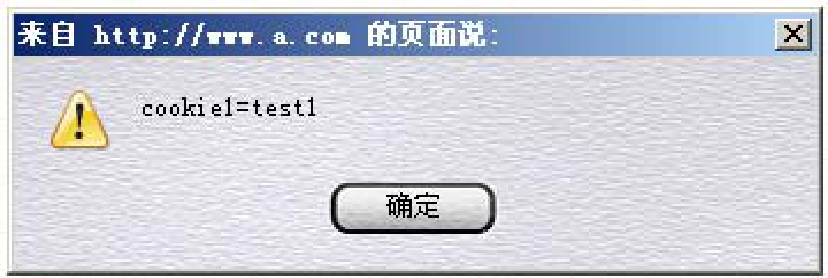
cookie1被JavaScript读取
HttpOnly起到了应有的作用。
在不同的语言中,给Cookie添加HttpOnly的代码如下:
Java EE

C#

VB.NET

但是在.NET 1.1中需要手动添加:
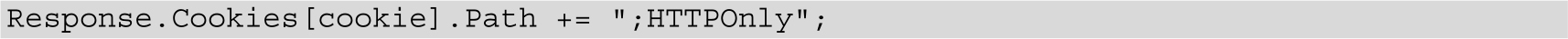
PHP 4
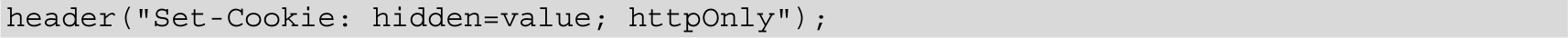
PHP 5

最后一个参数为HttpOnly属性。
添加HttpOnly的过程简单,效果明显,有如四两拨千斤。但是在部署时需要注意,如果业务非常复杂,则需要在所有Set-Cookie的地方,给关键Cookie都加上HttpOnly。漏掉了一个地方,都可能使得这个方案失效。
在过去几年中,曾经出现过一些能够绕过HttpOnly的攻击方法。
Apache支持的一个Header是TRACE。TRACE一般用于调试,它会将请求头作为HTTP Response Body返回。
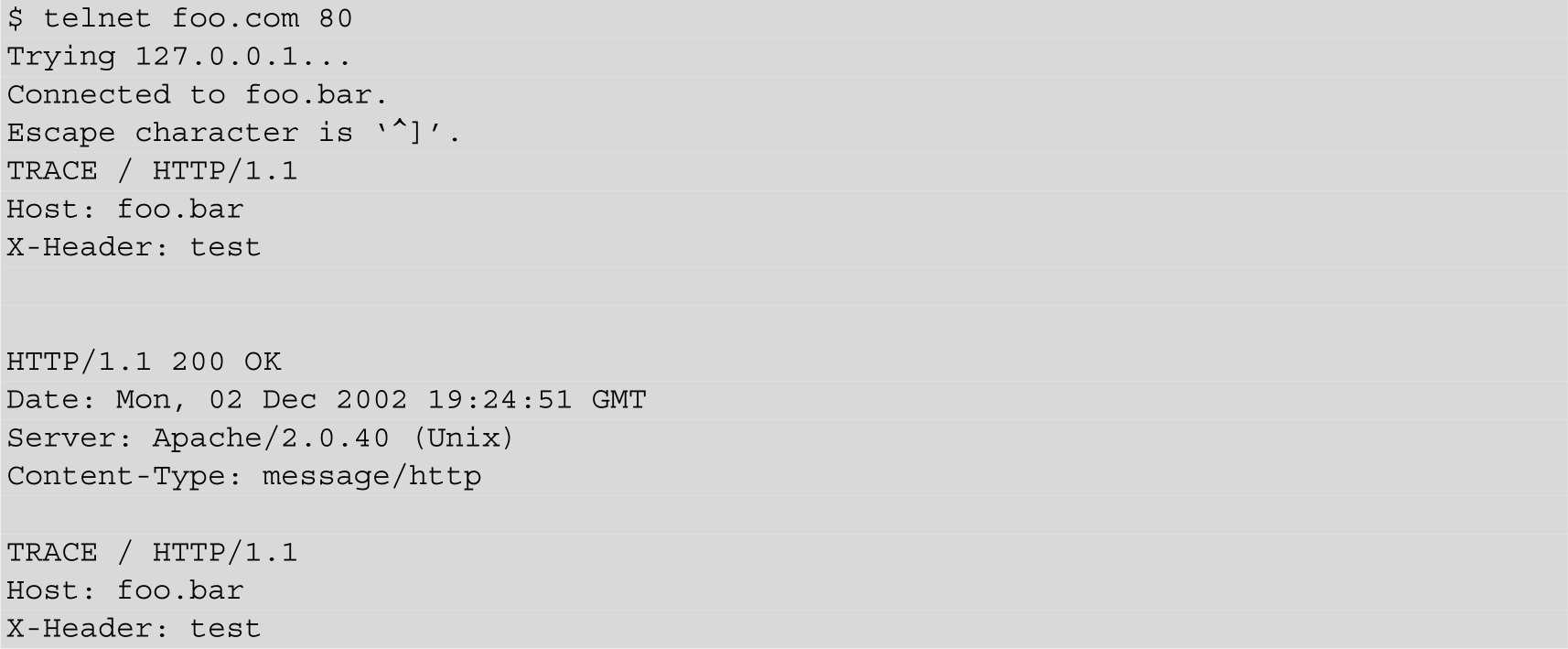
利用这个特性,可以把HttpOnly Cookie读出来。
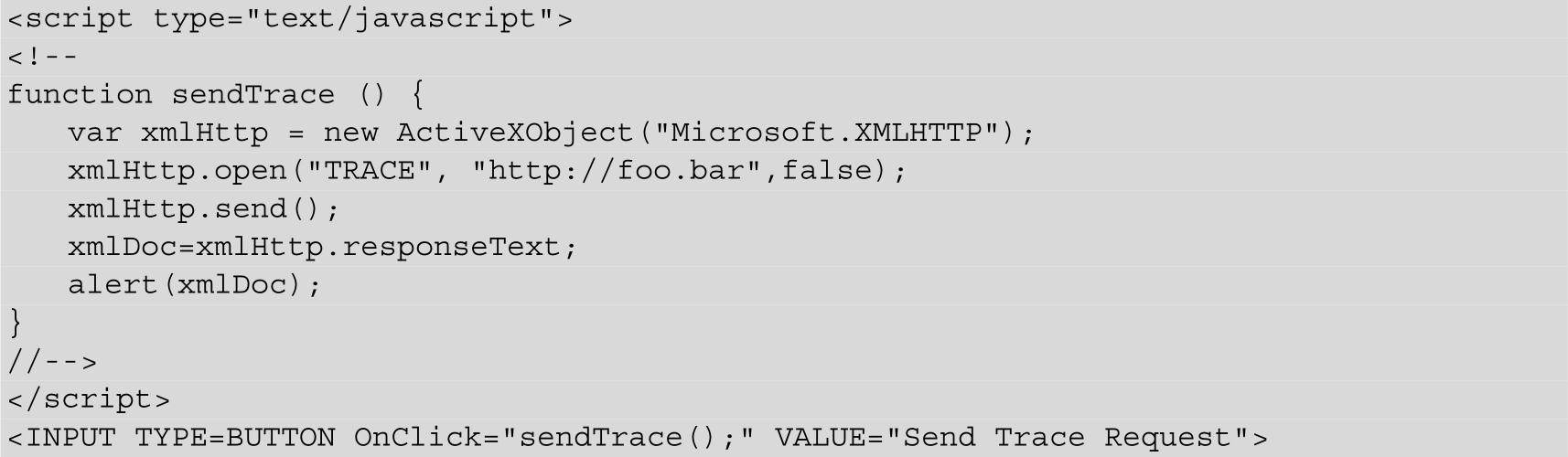
结果如下:
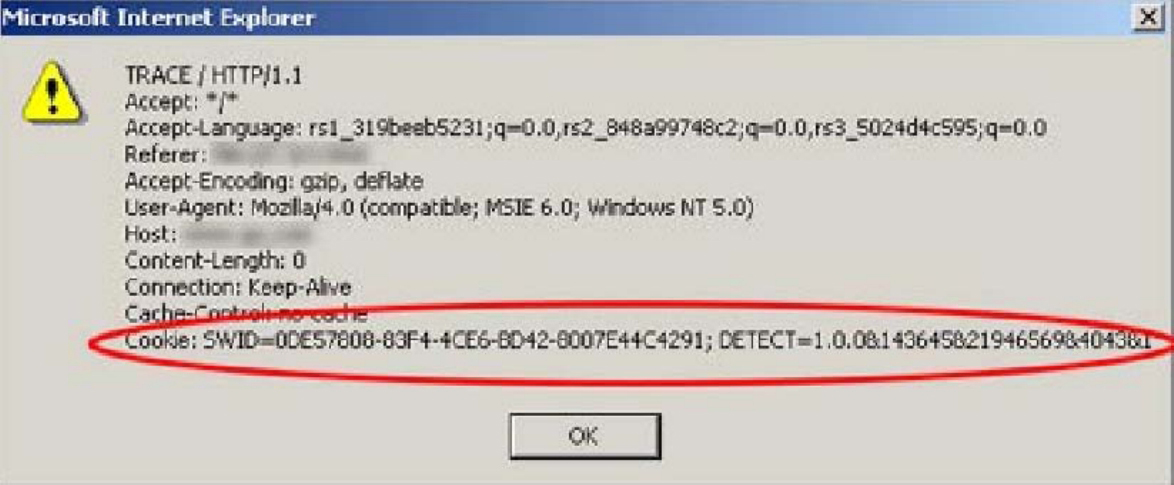
JavaScript读取到cookie
目前各厂商都已经修补了这些漏洞,但是未来也许还会有新的漏洞出现。现在业界给关键业务添加HttpOnly Cookie已经成为一种“标准”的做法。
但是,HttpOnly不是万能的,添加了HttpOnly不等于解决了XSS问题。
XSS攻击带来的不光是Cookie劫持问题,还有窃取用户信息、模拟用户身份执行操作等诸多严重的后果。如前文所述,攻击者利用AJAX构造HTTP请求,以用户身份完成的操作,就是在不知道用户Cookie的情况下进行的。
使用HttpOnly有助于缓解XSS攻击,但仍然需要其他能够解决XSS漏洞的方案。
常见的Web漏洞如XSS、SQL Injection等,都要求攻击者构造一些特殊字符,这些特殊字符可能是正常用户不会用到的,所以输入检查就有存在的必要了。
输入检查,在很多时候也被用于格式检查。例如,用户在网站注册时填写的用户名,会被要求只能为字母、数字的组合。比如“hello1234”是一个合法的用户名,而“hello#$^”就是一个非法的用户名。
又如注册时填写的电话、邮件、生日等信息,都有一定的格式规范。比如手机号码,应该是不长于16位的数字,且中国大陆地区的手机号码可能是 13 x、15x开头的,否则即为非法。
这些格式检查,有点像一种“白名单”,也可以让一些基于特殊字符的攻击失效。
输入检查的逻辑,必须放在服务器端代码中实现。如果只是在客户端使用JavaScript进行输入检查,是很容易被攻击者绕过的。目前Web开发的普遍做法,是同时在客户端JavaScript中和服务器端代码中实现相同的输入检查。客户端JavaScript的输入检查,可以阻挡大部分误操作的正常用户,从而节约服务器资源。
在XSS的防御上,输入检查一般是检查用户输入的数据中是否包含一些特殊字符,如<、>、’、”等。如果发现存在特殊字符,则将这些字符过滤或者编码。
比较智能的“输入检查”,可能还会匹配XSS的特征。比如查找用户数据中是否包含了“<script>”、“javascript”等敏感字符。
这种输入检查的方式,可以称为“XSS Filter”。互联网上有很多开源的“XSS Filter”的实现。
XSS Filter在用户提交数据时获取变量,并进行XSS检查;但此时用户数据并没有结合渲染页面的HTML代码,因此 XSS Filter对语境的理解并不完整 。
比如下面这个XSS漏洞:

其中“$var”是用户可以控制的变量。用户只需要提交一个恶意脚本所在的URL地址,即可实施XSS攻击。
如果是一个全局性的XSS Filter,则无法看到用户数据的输出语境,而只能看到用户提交了一个URL,就很可能会漏报。因为在大多数情况下,URL是一种合法的用户数据。
XSS Filter还有一个问题——其对“<”、“>”等字符的处理,可能会改变用户数据的语义。
比如,用户输入:

对于XSS Filter来说,发现了敏感字符“<”。如果XSS Filter不够“智能”,粗暴地过滤或者替换了“<”,则可能会改变用户原本的意思。
输入数据,还可能会被展示在多个地方,每个地方的语境可能各不相同,如果使用单一的替换操作,则可能会出现问题。
比如用户的“昵称”会在很多页面进行展示,但是每个页面的场景可能都是不同的,展示时的需求也不相同。如果在输入的地方统一对数据做了改变,那么输出展示时,可能会遇到如下问题。
用户输入的昵称如下:

如果在XSS Filter中对双引号进行转义:

在HTML代码中展示时:

在JavaScript代码中展示时:

这两段代码,分别得到如下结果:

第一个结果显然不是用户想看到的。
既然“输入检查”存在这么多问题,那么“输出检查”又如何呢?
一般来说,除了富文本的输出外,在变量输出到HTML页面时,可以使用编码或转义的方式来防御XSS攻击。
编码分为很多种,针对HTML代码的编码方式是HtmlEncode。
HtmlEncode并非专用名词,它只是一种函数实现。它的作用是将字符转换成HTMLEntities,对应的标准是ISO-8859-1。
为了对抗XSS,在HtmlEncode中要求至少转换以下字符:
& --> &
< --> <
> --> >
" --> "
' --> ' ' 不推荐
/ --> / 包含反斜线是因为它可能会闭合一些HTML entity
在PHP中,有htmlentities() 和 htm lspecialchars() 两个函数可以满足安全要求。
相应地,JavaScript的编码方式可以使用JavascriptEncode。
JavascriptEncode与HtmlEncode的编码方法不同,它需要使用“\”对特殊字符进行转义。在对抗XSS时,还要求输出的变量必须在引号内部,以避免造成安全问题。比较下面两种写法:

如果escapeJavascript() 函数只转义了几个危险字符,比如‘、”、<、>、\、&、# 等,那么上面的两行代码输出后可能会变成:

第一行执行额外的代码了;第二行则是安全的。对于后者,攻击者即使想要逃逸出引号的范围,也会遇到困难:

所以要求使用JavascriptEncode的变量输出一定要在引号内。
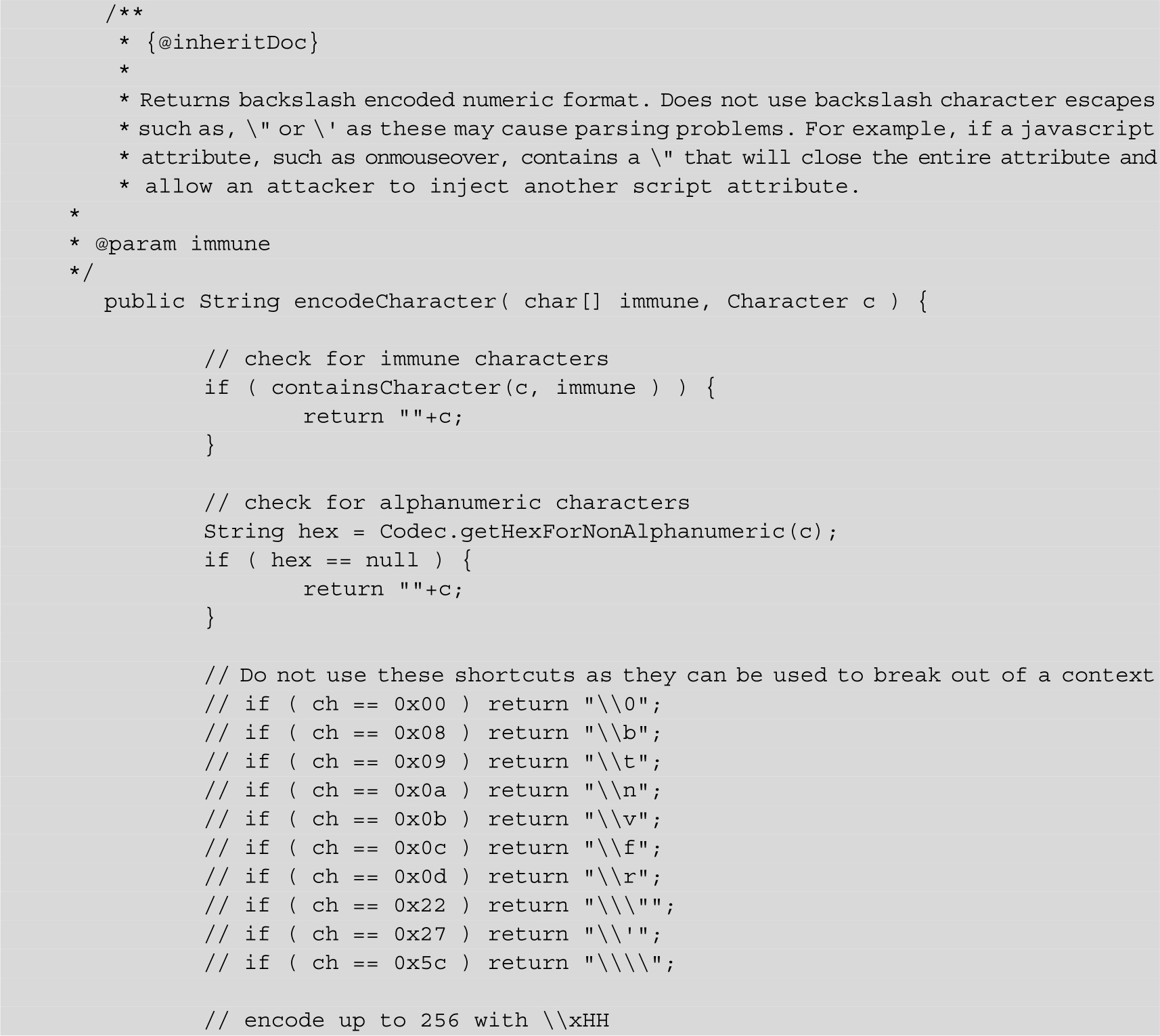
可是很多开发者没有这个习惯怎么办?这就只能使用一个更加严格的JavascriptEncode函数来保证安全——除了数字、字母外的所有字符,都使用十六进制“\xHH”的方式进行编码。在本例中:

变成了:

如此代码可以保证是安全的。
在OWASP ESAPI
 中有一个安全的JavascriptEncode的实现,非常严格。
中有一个安全的JavascriptEncode的实现,非常严格。

除了HtmlEncode、JavascriptEncode外,还有许多用于各种情况的编码函数,比如XMLEncode(其实现与HtmlEncode类似)、JSONEncode(与JavascriptEncode类似)等。
在“Apache Common Lang”的“StringEscapeUtils”里,提供了许多escape的函数。
可以在适当的情况下选用适当的函数。需要注意的是,编码后的数据长度可能会发生改变,从而影响某些功能。在写代码时需要注意这个细节,以免产生不必要的bug。
XSS攻击主要发生在MVC架构中的View层。大部分的XSS漏洞可以在模板系统中解决。
在Python的开发框架Django自带的模板系统“Django Templates”中,可以使用escape进行HtmlEncode。比如:

这样写的变量,会被HtmlEncode编码。
这一特性在Django 1.0中得到了加强——默认所有的变量都会被escape。这个做法是值得称道的,它符合 “Secure By Default”原则。
在Python的另一个框架 w eb2py 中,也默认escape了所有的变量。在web2py的安全文档中,有这样一句话:
web2py, by default, escapes all variables rendered in the view, thus preventing XSS.
Django和web2py都选择在View层默认HtmlEncode所有变量以对抗XSS,出发点很好。但是,像web2py这样认为这就解决了XSS问题,是错误的观点。
前文提到,XSS是很复杂的问题,需要“在正确的地方使用正确的编码方式”。看看下面这个例子:

开发者希望看到的效果是,用户点击链接后,弹出变量“$var”的内容。可是用户如果输入:

对变量“$var”进行HtmlEncode后,渲染的结果是:

对于浏览器来说,htmlparser 会优先于 Ja vaScript Pa rser执行,所以解析过程是,被HtmlEncode的字符先被解码,然后执行JavaScript事件。
因此,经过htmlparser解析后相当于:

成功在onclick事件中注入了XSS代码!
第一次弹框:
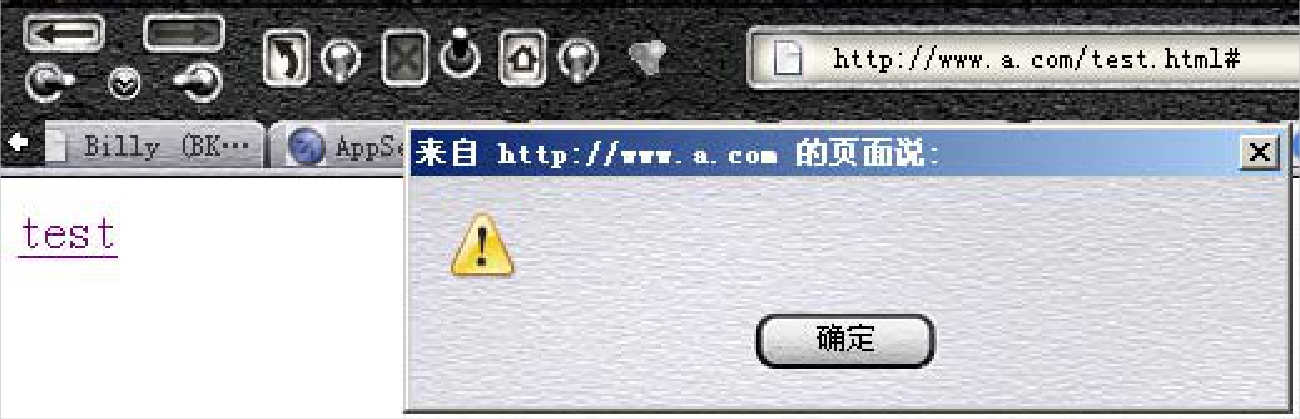
执行第一个alert
第二次弹框:
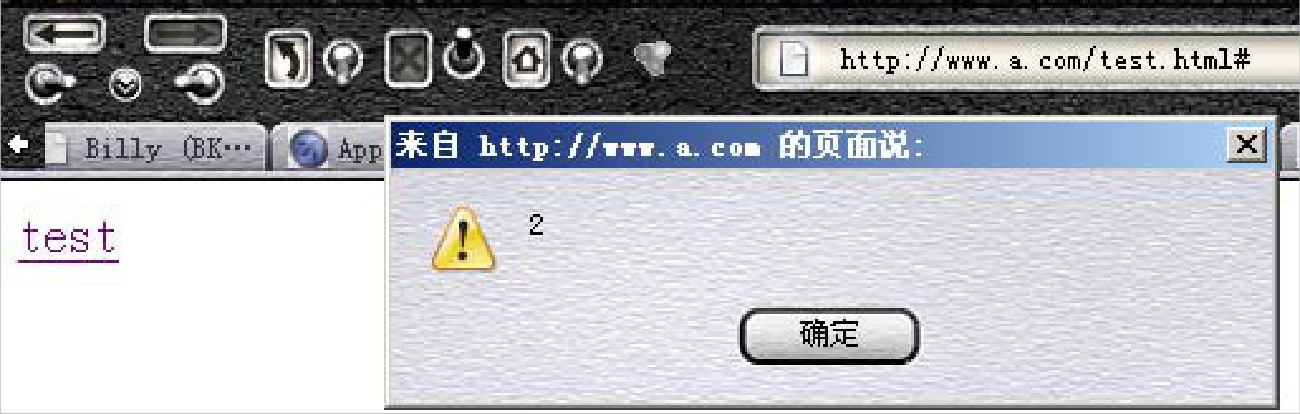
执行第二个alert
导致XSS攻击发生的原因,是由于没有分清楚输出变量的语境!因此并非在模板引擎中使用了auto-escape就万事大吉了,XSS的防御需要区分情况对待。
为了更好地设计XSS防御方案,需要认清XSS产生的本质原因。
XSS的本质还是一种“HTML注入”,用户的数据被当成了HTML代码一部分来执行,从而混淆了原本的语义,产生了新的语义。
如果网站使用了MVC架构,那么XSS就发生在View层——在应用拼接变量到HTML页面时产生。所以在用户提交数据处进行输入检查的方案,其实并不是在真正发生攻击的地方做防御。
想要根治XSS问题,可以列出所有XSS可能发生的场景,再一一解决。
下面将用变量“$var”表示用户数据,它将被填充入HTML代码中。可能存在以下场景。
在HTML标签中输出

所有在标签中输出的变量,如果未做任何处理,都能导致直接产生XSS。
在这种场景下,XSS的利用方式一般是构造一个<script>标签,或者是任何能够产生脚本执行的方式。比如:

或者
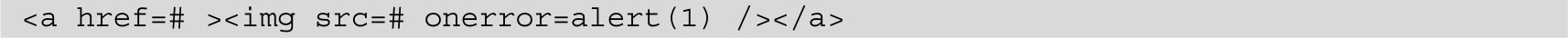
防御方法是对变量使用HtmlEncode。
在HTML属性中输出

与在HTML标签中输出类似,可能的攻击方法:

防御方法也是采用HtmlEncode。
在OWASP ESAPI中推荐了一种更严格的HtmlEncode——除了字母、数字外,其他所有的特殊字符都被编码成HTMLEntities。

这种严格的编码方式,可以保证不会出现任何安全问题。
在<script>标签中输出
在<script>标签中输出时,首先应该确保输出的变量在引号中:

攻击者需要先闭合引号才能实施XSS攻击:

防御时使用JavascriptEncode。
在事件中输出
在事件中输出和在<script>标签中输出类似:

可能的攻击方法:

在防御时需要使用JavascriptEncode。
在CSS中输出
在CSS和style、style attribute中形成XSS的方式非常多样化,参考下面几个XSS的例子。

所以,一般来说,尽可能禁止用户可控制的变量在“<style>标签”、“HTML标签的style属性”以及“CSS文件”中输出。如果一定有这样的需求,则推荐使用OWASP ES API中的encodeForCSS()函数。

其实现原理类似于 ESAPI.e ncoder().encodeForJavaScript() 函数,除了字母、数字外的所有字符都被编码成十六进制形式“\uHH”。
在地址中输出
在地址中输出也比较复杂。一般来说,在URL的path(路径)或者search(参数)中输出,使用URLEncode即可。URLEncode会将字符转换为“%HH”形式,比如空格就是“%20”,“<”符号是“%3c”。

可能的攻击方法:

经过URLEncode后,变成了:

但是还有一种情况,就是整个URL能够被用户完全控制。这时URL的Protocal和Host部分是不能够使用URLEncode的,否则会改变URL的语义。
一个URL的组成如下:

例如:

在 Prot ocal 与 Host中,如果使用严格的URLEncode函数,则会把“://”、“.”等都编码掉。
对于如下的输出方式:

攻击者可能会构造伪协议实施攻击:

除了“javascript”作为伪协议可以执行代码外,还有“vbscript”、“dataURI”等伪协议可能导致脚本执行。
“dataURI”这个伪协议是Mozilla所支持的,能够将一段代码写在URL里。如下例:

这段代码的意思是,以text/html的格式加载编码为base64的数据,加载完成后实际上是:

点击<a>标签的链接,将导致执行脚本。
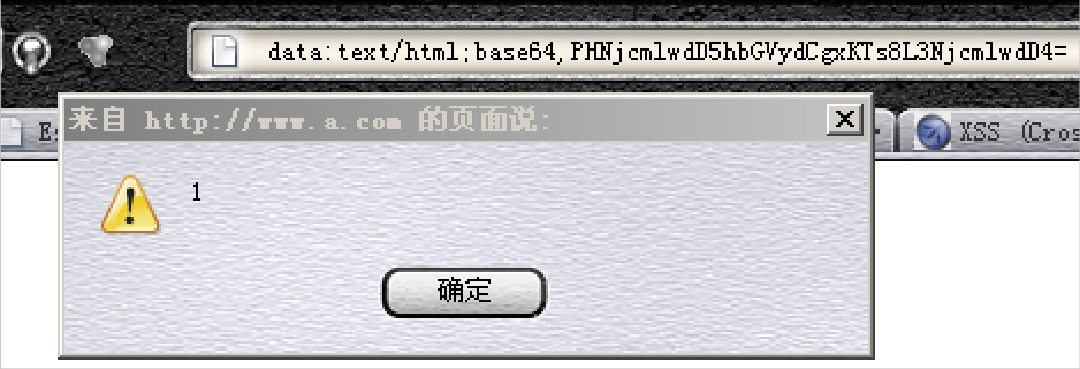
执行恶意脚本
由此可见,如果用户能够完全控制URL,则可以执行脚本的方式有很多。如何解决这种情况呢?
一般来说,如果变量是整个URL,则应该先检查变量是否以“http”开头(如果不是则自动添加),以保证不会出现伪协议类的XSS攻击。

在此之后,再对变量进行URLEncode,即可保证不会有此类的XSS发生了。
OWASP ESAPI中有一个URLEncode的实现(此API未解决伪协议的问题):
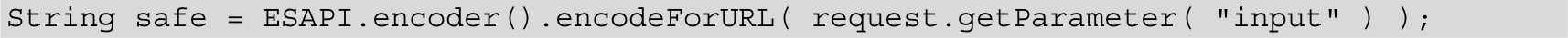
有些时候,网站需要允许用户提交一些自定义的HTML代码,称之为“富文本”。比如一个用户在论坛里发帖,帖子的内容里要有图片、视频,表格等,这些“富文本”的效果都需要通过HTML代码来实现。
如何区分安全的“富文本”和有攻击性的XSS呢?
在处理富文本时,还是要回到“输入检查”的思路上来。“输入检查”的主要问题是,在检查时还不知道变量的输出语境。但用户提交的“富文本”数据,其语义是完整的HTML代码,在输出时也不会拼凑到某个标签的属性中。因此可以特殊情况特殊处理。
在上一节中,列出了所有在HTML中可能执行脚本的地方。而一个优秀的“XSS Filter”,也应该能够找出HTML代码中所有可能执行脚本的地方。
HTML是一种结构化的语言,比较好分析。通过htmlparser可以解析出HTML代码的标签、标签属性和事件。
在过滤富文本时,“事件”应该被严格禁止,因为“富文本”的展示需求里不应该包括“事件”这种动态效果。而一些危险的标签,比如<iframe>、<script>、<base>、<form>等,也是应该严格禁止的。
在标签的选择上, 应该使用白名单,避免使用黑名单。 比如,只允许 <a>、<img>、<div>等比较“安全”的标签存在。
“白名单原则”不仅仅用于标签的选择,同样应该用于属性与事件的选择。
在富文本过滤中,处理CSS也是一件麻烦的事情。如果允许用户自定义CSS、style,则也可能导致XSS攻击。因此尽可能地禁止用户自定义CSS与style。
如果一定要允许用户自定义样式,则只能像过滤“富文本”一样过滤“CSS”。这需要一个CSS Parser对样式进行智能分析,检查其中是否包含危险代码。
有一些比较成熟的开源项目,实现了对富文本的XSS检查。
Anti-Samy
是OWASP上的一个开源项目,也是目前最好的XSS Filter。最早它是基于Java的,现在已经扩展到.NET等语言。

在PHP中,可以使用另外一个广受好评的开源项目:HTMLPurify
。
DOM Based XSS是一种比较特别的XSS漏洞,前文提到的几种防御方法都不太适用,需要特别对待。
DOM Based XSS是如何形成的呢?回头看看这个例子:

在button的onclick事件中,执行了test() 函数,而该函数中最关键的一句是:

将HTML代码写入了DOM节点,最后导致了XSS的发生。
事实上,DOM Based XSS是从JavaScript中输出数据到HTML页面里。而前文提到的方法都是针对“从服务器应用直接输出到HTML页面”的XSS漏洞,因此并不适用于DOM Based XSS。
看看下面这个例子:

变量“$var”输出在<script>标签内,可是最后又被document.write输出到HTML页面中。
假设为了保护“$var”直接在<script>标签内产生XSS,服务器端对其进行了javascriptEscape。可是,$var 在document.write时,仍然能够产生XSS,如下所示:

页面渲染之后的实际结果如下:
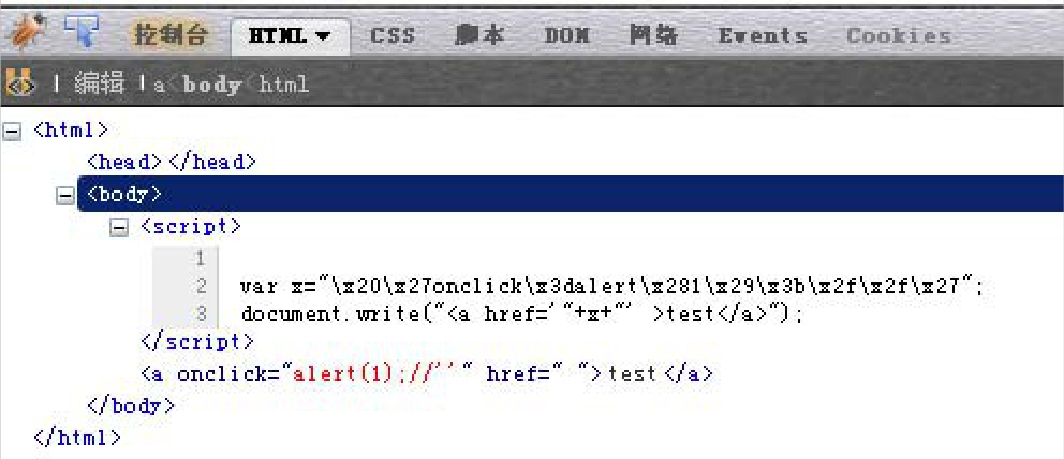
页面渲染后的HTML代码效果
XSS攻击成功:
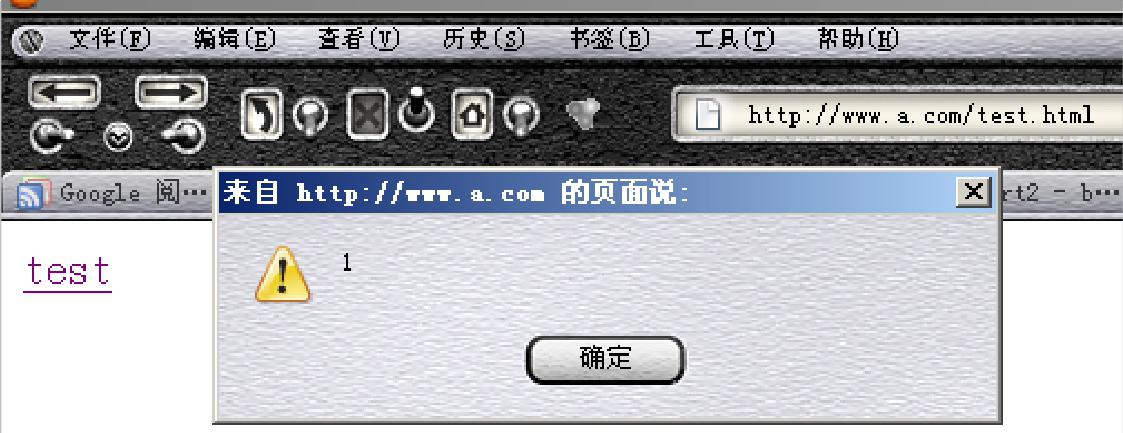
执行恶意代码
其原因在于,第一次执行javascriptEscape后,只保护了:

但是当document.write输出数据到HTML页面时,浏览器重新渲染了页面。在<script>标签执行时,已经对变量x进行了解码,其后document.write再运行时,其参数就变成了:

XSS因此而产生。
那是不是因为对“$var”用错了编码函数呢?如果改成HtmlEncode会怎么样?继续看下面这个例子:

服务器把变量HtmlEncode后再输出到<script>中,然后变量x作为onclick事件的一个函数参数被document.write到了HTML页面里。
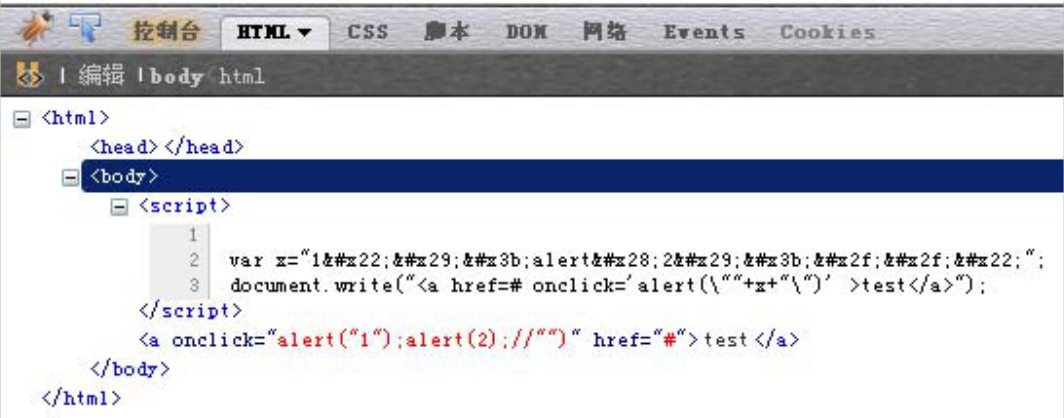
页面渲染后的HTML代码效果
onclick事件执行了两次“alert”,第二次是被XSS注入的。
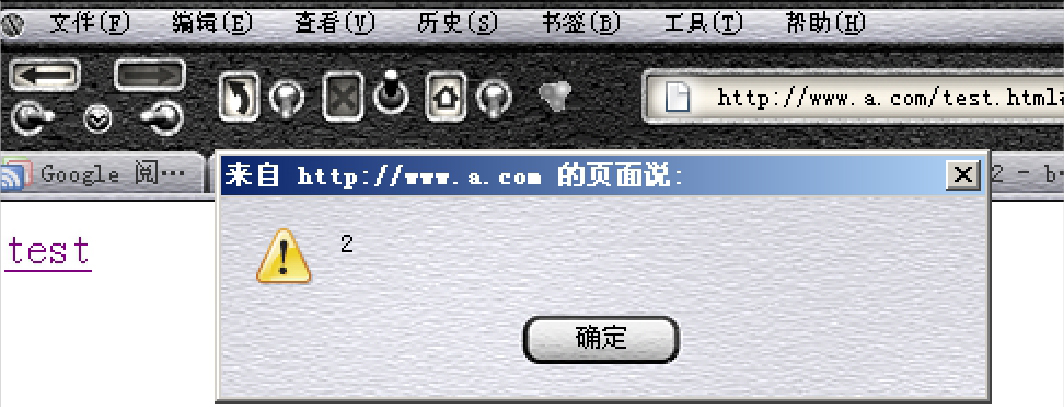
执行恶意代码
那么正确的防御方法是什么呢?
首先,在“$var”输出到<script>时,应该执行一次javascriptEncode;其次,在document.write输出到HTML页面时,要分具体情况看待:如果是输出到事件或者脚本,则要再做一次javascriptEncode;如果是输出到HTML内容或者属性,则要做一次HtmlEncode。
也就是说,从JavaScript输出到HTML页面,也相当于一次XSS输出的过程,需要分语境使用不同的编码函数。
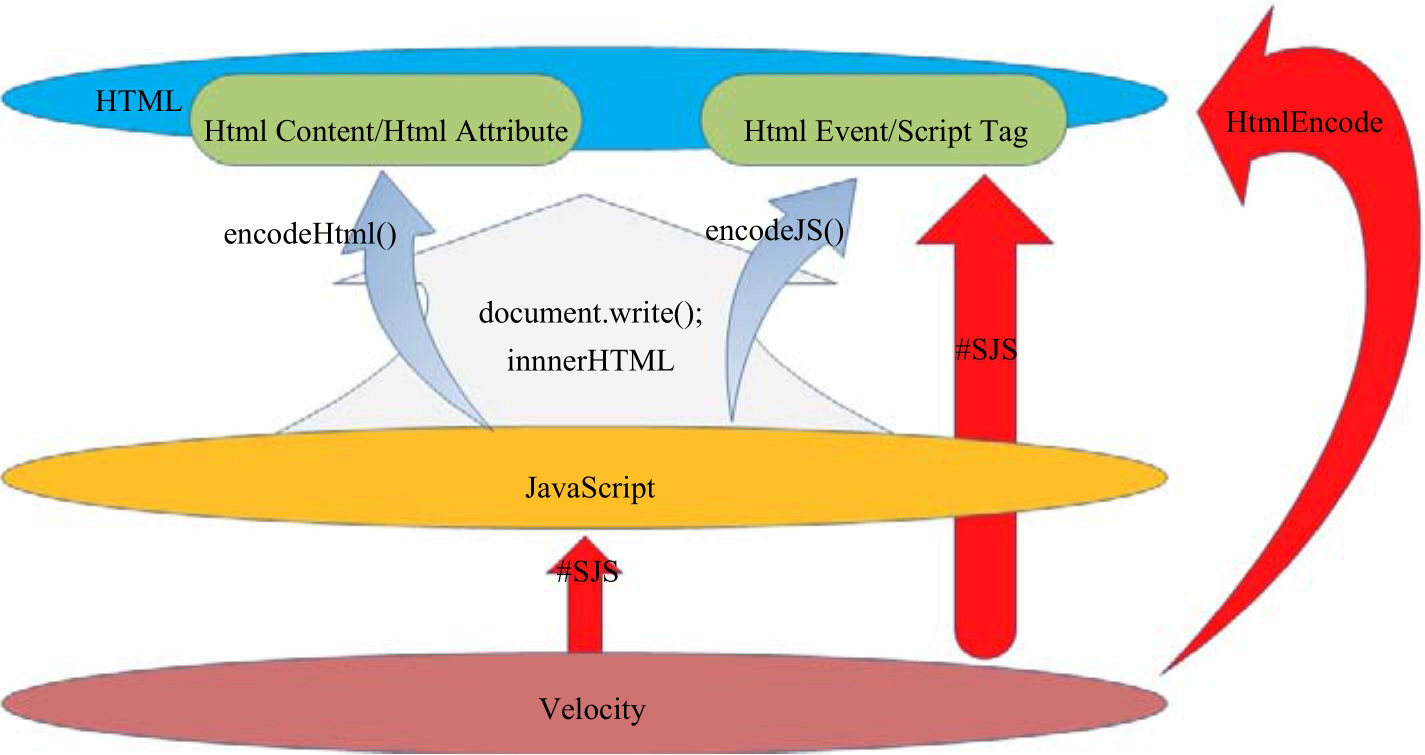
DOM based XSS的防御
会触发DOM Based XSS的地方有很多,以下几个地方是JavaScript输出到HTML页面的必经之路。
 document.write()
document.write()
 document.writeln()
document.writeln()
 xxx.innerHTML =
xxx.innerHTML =
 xxx.outerHTML =
xxx.outerHTML =
 innerHTML.replace
innerHTML.replace
 document.attachEvent()
document.attachEvent()
 window.attachEvent()
window.attachEvent()
 document.location.replace()
document.location.replace()
 document.location.assign()
document.location.assign()
……
需要重点关注这几个地方的参数是否可以被用户控制。
除了服务器端直接输出变量到JavaScript外,还有以下几个地方可能会成为DOM Based XSS的输入点,也需要重点关注。
 页面中所有的inputs框
页面中所有的inputs框
 window.location(href、hash等)
window.location(href、hash等)
 window.name
window.name
 document.referrer
document.referrer
 document.cookie
document.cookie
 localstorage
localstorage
 XMLHttpRequest返回的数据
XMLHttpRequest返回的数据
……
安全研究者Stefano Di Paola设立了一个DOM Based XSS的cheatsheet
,有兴趣深入研究的读者可以参考。
前文谈到的所有XSS攻击,都是从漏洞形成的原理上看的。如果从业务风险的角度来看,则会有不同的观点。
一般来说,存储型XSS的风险会高于反射型XSS。因为存储型XSS会保存在服务器上,有可能会跨页面存在。它不改变页面URL的原有结构,因此有时候还能逃过一些IDS的检测。比如IE 8的XSS Filter和Firefox的Noscript Extension,都会检查地址栏中的地址是否包含XSS脚本。而跨页面的存储型XSS可能会绕过这些检测工具。
从攻击过程来说,反射型XSS,一般要求攻击者诱使用户点击一个包含XSS代码的URL链接;而存储型XSS,则只需要让用户查看一个正常的URL链接。比如一个Web邮箱的邮件正文页面存在一个存储型的XSS漏洞,当用户打开一封新邮件时,XSS Payload会被执行。这样的漏洞极其隐蔽,且埋伏在用户的正常业务中,风险颇高。
从风险的角度看,用户之间有互动的页面,是可能发起XSS Worm攻击的地方。而根据不同页面的PageView高低,也可以分析出哪些页面受XSS攻击后的影响会更大。比如在网站首页发生的XSS攻击,肯定比网站合作伙伴页面的XSS攻击要严重得多。
在修补XSS漏洞时遇到的最大挑战之一是漏洞数量太多,因此开发者可能来不及,也不愿意修补这些漏洞。从业务风险的角度来重新定位每个XSS漏洞,就具有了重要的意义。