
下载掌阅APP,畅读海量书库
立即打开



在上节讲述了实施安全评估的基本过程,安全评估最后的产出物就是安全方案,但在具体设计安全方案时有什么样的技巧呢?本节将讲述在实战中可能用到的方法。
在设计安全方案时,最基本也最重要的原则就是“Secure by Default”。在做任何安全设计时,都要牢牢记住这个原则。一个方案设计得是否足够安全,与有没有应用这个原则有很大的关系。实际上,“Secure by Default”原则,也可以归纳为白名单、黑名单的思想。如果更多地使用白名单,那么系统就会变得更安全。
比如,在制定防火墙的网络访问控制策略时,如果网站只提供Web服务,那么正确的做法是只允许网站服务器的80和443端口对外提供服务,屏蔽除此之外的其他端口。这是一种“白名单”的做法;如果使用“黑名单”,则可能会出现问题。假设黑名单的策略是:不允许SSH端口对Internet开放,那么就要审计SSH的默认端口:22端口是否开放了Internet。但在实际工作过程中,经常会发现有的工程师为了偷懒或图方便,私自改变了SSH的监听端口,比如把SSH的端口从22改到了2222,从而绕过了安全策略。
又比如,在网站的生产环境服务器上,应该限制随意安装软件,而需要制定统一的软件版本规范。这个规范的制定,也可以选择白名单的思想来实现。按照白名单的思想,应该根据业务需求,列出一个允许使用的软件以及软件版本的清单,在此清单外的软件则禁止使用。如果允许工程师在服务器上随意安装软件的话,则可能会因为安全部门不知道、不熟悉这些软件而导致一些漏洞,从而扩大攻击面。
在Web安全中,对白名单思想的运用也比比皆是。比如应用处理用户提交的富文本时,考虑到XSS的问题,需要做安全检查。常见的XSS Filter一般是先对用户输入的HTML原文作HTML Pa rse,解析成标签对象后,再针对标签匹配XSS的规则。这个规则列表就是一个黑白名单。如果选择黑名单的思想,则这套规则里可能是禁用诸如<script>、<iframe>等标签。但是黑名单可能会有遗漏,比如未来浏览器如果支持新的HTML标签,那么此标签可能就不在黑名单之中了。如果选择白名单的思想,就能避免这种问题——在规则中,只允许用户输入诸如<a>、<img>等需要用到的标签。对于如何设计一个好的XSS防御方案,在“跨站脚本攻击”一章中还会详细讲到,不在此赘述了。
然而,并不是用了白名单就一定安全了。有朋友可能会问,作者刚才讲到选择白名单的思想会更安全,现在又说不一定,这不是自相矛盾吗?我们可以仔细分析一下白名单思想的本质。在前文中提到:“安全问题的本质是信任问题,安全方案也是基于信任来做的”。选择白名单的思想,基于白名单来设计安全方案,其实就是信任白名单是好的,是安全的。但是一旦这个信任基础不存在了,那么安全就荡然无存。
在Flash跨域访问请求里,是通过检查目标资源服务器端的crossdomain.xml文件来验证是否允许客户端的Flash跨域发起请求的,它使用的是白名单的思想。比如下面这个策略文件:

指定了只允许特定域的Flash对本域发起请求。可是如果这个信任列表中的域名变得不可信了,那么问题就会随之而来。比如:

通配符“*”,代表来自任意域的Flash都能访问本域的数据,因此就造成了安全隐患。所以在选择使用白名单时,需要注意避免出现类似通配符“*”的问题。
Secure By Default的另一层含义就是“最小权限原则”。最小权限原则也是安全设计的基本原则之一。最小权限原则要求系统只授予主体必要的权限,而不要过度授权,这样能有效地减少系统、网络、应用、数据库出错的机会。
比如在Linux系统中,一种良好的操作习惯是使用普通账户登录,在执行需要root权限的操作时,再通过sudo命令完成。这样能最大化地降低一些误操作导致的风险;同时普通账户被盗用后,与root帐户被盗用所导致的后果是完全不同的。
在使用最小权限原则时,需要认真梳理业务所需要的权限,在很多时候,开发者并不会意识到业务授予用户的权限过高。在通过访谈了解业务时,可以多设置一些反问句,比如:您确定您的程序一定需要访问Internet吗?通过此类问题,来确定业务所需的最小权限。
与Secure by Default 一样,Defense in Depth(纵深防御)也是设计安全方案时的重要指导思想。
纵深防御包含两层含义:首先,要在各个不同层面、不同方面实施安全方案,避免出现疏漏,不同安全方案之间需要相互配合,构成一个整体;其次,要在正确的地方做正确的事情,即:在解决根本问题的地方实施针对性的安全方案。
某矿泉水品牌曾经在广告中展示了一滴水的生产过程:经过十多层的安全过滤,去除有害物质,最终得到一滴饮用水。这种多层过滤的体系,就是一种纵深防御,是有立体层次感的安全方案。
纵深防御并不是同一个安全方案要做两遍或多遍,而是要从不同的层面、不同的角度对系统做出整体的解决方案。我们常常听到“木桶理论”这个词,说的是一个桶能装多少水,不是取决于最长的那块板,而是取决于最短的那块板,也就是短板。设计安全方案时最怕出现短板,木桶的一块块板子,就是各种具有不同作用的安全方案,这些板子要紧密地结合在一起,才能组成一个不漏水的木桶。
在常见的入侵案例中,大多数是利用Web应用的漏洞,攻击者先获得一个低权限的webshell,然后通过低权限的webshell上传更多的文件,并尝试执行更高权限的系统命令,尝试在服务器上提升权限为root;接下来攻击者再进一步尝试渗透内网,比如数据库服务器所在的网段。
在这类入侵案例中,如果在攻击过程中的任何一个环节设置有效的防御措施,都有可能导致入侵过程功亏一篑。但是世上没有万能灵药,也没有哪种解决方案能解决所有问题,因此非常有必要将风险分散到系统的各个层面。就入侵的防御来说,我们需要考虑的可能有Web应用安全、OS系统安全、数据库安全、网络环境安全等。在这些不同层面设计的安全方案,将共同组成整个防御体系,这也就是纵深防御的思想。
纵深防御的第二层含义,是要在正确的地方做正确的事情。如何理解呢?它要求我们深入理解威胁的本质,从而做出正确的应对措施。
在XSS防御技术的发展过程中,曾经出现过几种不同的解决思路,直到最近几年XSS的防御思路才逐渐成熟和统一。
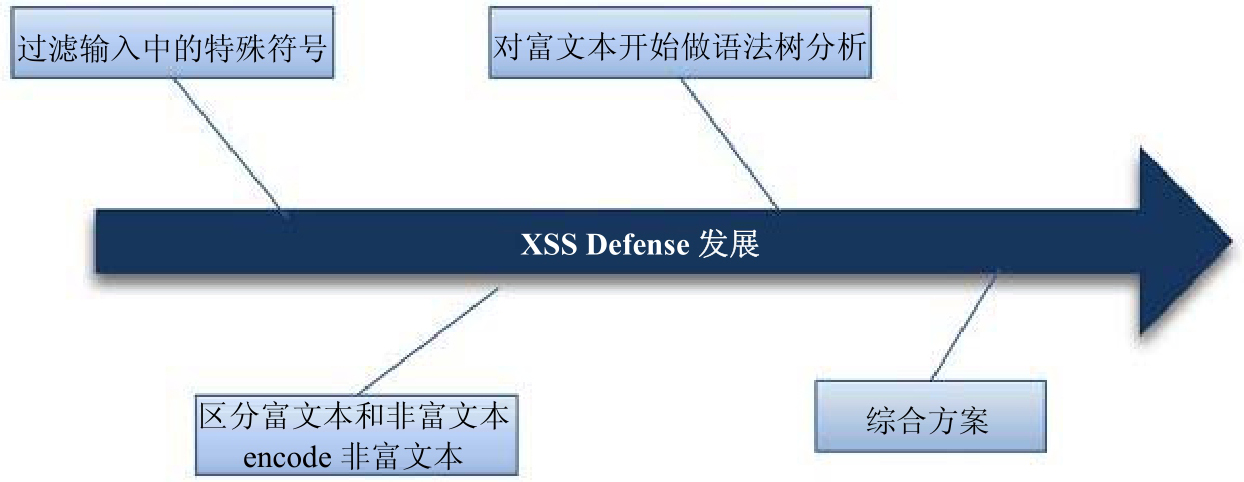
XSS防御技术的发展过程
在一开始的方案中,主要是过滤一些特殊字符,比如:
<<笑傲江湖>> 会变成 笑傲江湖
尖括号被过滤掉了。
但是这种粗暴的做法常常会改变用户原本想表达的意思,比如:
1<2 可能会变成 1 2
造成这种“乌龙”的结果就是因为没有“在正确的地方做正确的事情”。对于XSS防御,对系统取得的用户输入进行过滤其实是不太合适的,因为XSS真正产生危害的场景是在用户的浏览器上,或者说服务器端输出的HTML页面,被注入了恶意代码。只有在拼装HTML时输出,系统才能获得HTML上下文的语义,才能判断出是否存在误杀等情况。所以“在正确的地方做正确的事情”,也是纵深防御的一种含义——必须把防御方案放到最合适的地方去解决。(XSS防御的更多细节请参考“跨站脚本攻击”一章。)
近几年安全厂商为了迎合市场的需要,推出了一种产品叫UTM,全称是“统一威胁管理”(Unified Threat Management)。UTM几乎集成了所有主流安全产品的功能,比如防火墙、VPN、反垃圾邮件、IDS、反病毒等。UTM的定位是当中小企业没有精力自己做安全方案时,可以在一定程度上提高安全门槛。但是UTM并不是万能药,很多问题并不应该在网络层、网关处解决,所以实际使用时效果未必好,它更多的是给用户买个安心。
对于一个复杂的系统来说,纵深防御是构建安全体系的必要选择。
另一个重要的安全原则是数据与代码分离原则。这一原则广泛适用于各种由于“注入”而引发安全问题的场景。
实际上,缓冲区溢出,也可以认为是程序违背了这一原则的后果——程序在栈或者堆中,将用户数据当做代码执行,混淆了代码与数据的边界,从而导致安全问题的发生。
在Web安全中,由“注入”引起的问题比比皆是,如XSS、SQL Injection、CRLF Injection、X-Path Injection等。此类问题均可以根据“数据与代码分离原则”设计出真正安全的解决方案,因为这个原则抓住了漏洞形成的本质原因。
以XSS为例,它产生的原因是HTML Injection 或 Ja vaScript Injection,如果一个页面的代码如下:

其中 $var 是用户能够控制的变量,那么对于这段代码来说:

就是程序的代码执行段。
而

就是程序的用户数据片段。
如果把用户数据片段 $var 当成代码片段来解释、执行,就会引发安全问题。
比如,当$var的值是:

时,用户数据就被注入到代码片段中。解析这段脚本并执行的过程,是由浏览器来完成的——浏览器将用户数据里的<script>标签当做代码来解释——这显然不是程序开发者的本意。
根据数据与代码分离原则,在这里应该对用户数据片段 $v ar 进行安全处理,可以使用过滤、编码等手段,把可能造成代码混淆的用户数据清理掉,具体到这个案例中,就是针对 <、> 等符号做处理。
有的朋友可能会问了:我这里就是要执行一个<script>标签,要弹出一段文字,比如:“你好!”,那怎么办呢?
在这种情况下,数据与代码的情况就发生了变化,根据数据与代码分离原则,我们就应该重写代码片段:

在这种情况下,<script>标签也变成了代码片段的一部分,用户数据只有 $v ar1 能够控制,从而杜绝了安全问题的发生。
前面介绍的几条原则:Secure By Default,是时刻要牢记的总则;纵深防御,是要更全面、更正确地看待问题;数据与代码分离,是从漏洞成因上看问题;接下来要讲的“不可预测性”原则,则是从克服攻击方法的角度看问题。
微软的Windows系统用户多年来深受缓冲区溢出之苦,因此微软在Windows的新版本中增加了许多对抗缓冲区溢出等内存攻击的功能。微软无法要求运行在系统中的软件没有漏洞,因此它采取的做法是让漏洞的攻击方法失效。比如,使用DEP来保证堆栈不可执行,使用ASLR让进程的栈基址随机变化,从而使攻击程序无法准确地猜测到内存地址,大大提高了攻击的门槛。经过实践检验,证明微软的这个思路确实是有效的——即使无法修复code,但是如果能够使得攻击的方法无效,那么也可以算是成功的防御。
微软使用的ASLR技术,在较新版本的Linux内核中也支持。在ASLR的控制下,一个程序每次启动时,其进程的栈基址都不相同,具有一定的随机性,对于攻击者来说,这就是“不可预测性”。
不可预测性(Unpredictable),能有效地对抗基于篡改、伪造的攻击。我们看看如下场景:
假设一个内容管理系统中的文章序号,是按照数字升序排列的,比如id=1000, i d=1002,id=1003……
这样的顺序,使得攻击者能够很方便地遍历出系统中的所有文章编号:找到一个整数,依次递增即可。如果攻击者想要批量删除这些文章,写个简单的脚本:

就可以很方便地达到目的。但是如果该内容管理系统使用了“不可预测性”原则,将id的值变得不可预测,会产生什么结果呢?
id=asldfjaefsadlf, id=adsfalkennffxc, id=poerjfweknfd……
id的值变得完全不可预测了,攻击者再想批量删除文章,只能通过爬虫把所有的页面id全部抓取下来,再一一进行分析,从而提高了攻击的门槛。
不可预测性原则,可以巧妙地用在一些敏感数据上。比如在CSRF的防御技术中,通常会使用一个token来进行有效防御。这个token能成功防御CSRF,就是因为攻击者在实施CSRF攻击的过程中,是无法提前预知这个token值的,因此要求token足够复杂时,不能被攻击者猜测到。(具体细节请参考“跨站点请求伪造”一章。)
不可预测性的实现往往需要用到加密算法、随机数算法、哈希算法,好好使用这条原则,在设计安全方案时往往会事半功倍。