
下载掌阅APP,畅读海量书库
立即打开




|
3.3 新技术和新方法 |
化工过程对象的复杂性,往往由于产生机理不清楚或机理模型复杂,或难于建立其生产过程模型,或所建模型适应性差,难于应对过程的变化而进行正确评估与预测、工况监控与控制。数据驱动的过程建模、优化与诊断方法不需要过程精确的解析模型,在实际系统中更容易直接应用。从工业应用角度出发,一方面需要研究如何将已有的过程知识融入基于过程数据建模的方法中,提高数据模型的适应范围;另一方面需要研究通过对过程数据进行挖掘得到过程知识,并建立数据和机理混合模型的方法,有效降低解析模型的建立难度,并提高其精度,从而解决过程工业过程复杂性高的难题。
数据模型和机理模型之间既有本质区别也有联系,在机理模型中,系统不确定性与时变性信息是显式表达的,在数据模型中则相反;数据驱动的控制理论和方法并不排斥已有的模型驱动方法,它们之间是相互渗透并优势互补的。一般来说,对受控对象知识掌握越多,控制效果越好,同时,数据方法也需对受控系统的信息有比较深入的理解,才能更好地控制对象的运行;模型驱动方法对离线数据是一次性使用,数据方法是在控制过程中始终都对离线数据的不同层面、不同尺度进行利用 [ 18 , 19 ] 。随着信息技术等软硬件的迅速发展,以及丰富的数据处理方法,为数据方法提供了可行性和可能性;基于数据对系统行为的预报、控制和评价结果,还可用实时闭环系统的运行数据进行模型检验。因此,数据和机理模型两种方法相互协调与修正,紧密结合在一起,共同解决复杂系统的建模、优化与控制领域的关键问题,具有更好的实用性和实时性,也是安全和可靠的。
(1)裂解炉过程建模
Geng和Cui等以乙烯裂解过程半机理半经验Kumar模型为基础,研究模型中一次反应产物选择性系数及动力学参数的优化调整,一次系数与动力学参数是随着不同类型、不同组分构成的进料油品而变化的,尤其是前者,受油品性质影响很大,且对产物收率影响重大 [ 20 ] 。基于此,着眼于Kumar模型的应用拓展,应用混沌优化算法来调整一次反应系数及动力学参数,该方法不仅结构简单、编程容易实现、收敛速度较快,且由此建立的裂解模型精度较高,然后将二次规划-混沌粒子群综合算法用于模型参数的优化,同样取得了较理想的结果 [ 21 , 22 ] 。此综合算法将粒子群算法用于参数的全局搜索,二次规划用于局部搜索,加入混沌映射,保证了粒子的多样性,避免算法陷入局部最小值,并开发了裂解炉过程建模与优化软件系统。
(2)裂解炉耦合模型建模
Lan、Gao和Xu等采用CFD技术,结合流体力学基本传输方程、k-epsilon湍流模型、裂解反应机理模型、推测的湍流扩散燃烧概率密度函数模型、辐射传热的离散坐标法等提出了一种全面的乙烯裂解炉数学模型 [ 23 ] ,定量地研究了烧嘴位置、炉管管径、管间距等对乙烯裂解炉运行性能影响,给出了详细的流速和温度场、热通量分布、密度分布。这对理解工业裂解炉运行过程和工业裂解炉设计具有一定的价值。Stefanidis等通过对工业石脑油裂解炉的三维CFD仿真,发现炉墙高辐射涂层技术有利于提高裂解炉的热裂解效率,并提高石脑油的转化率和乙烯收率 [ 24 ] 。
胡贵华等结合工业数据,采用CFD方法研究了工业SL-Ⅱ型乙烯裂解炉的炉膛内的流速场、温度场(图3-1)、密度场以及炉膛表面的热通量分布,为乙烯裂解炉炉型几何结构优化和操作参数优化提供了一定指导意义 [ 25 ] 。

图3-1 SL-Ⅱ型乙烯裂解炉炉膛烟气温
张禹等针对裂解炉CFD模拟在细节刻画方面的不足,研究了烧嘴详细结构、烟气辐射性质以及阴影效应(shadow effect)对裂解炉模拟的影响 [ 26 ] ,计算的炉膛温度分布,如图3-2所示。
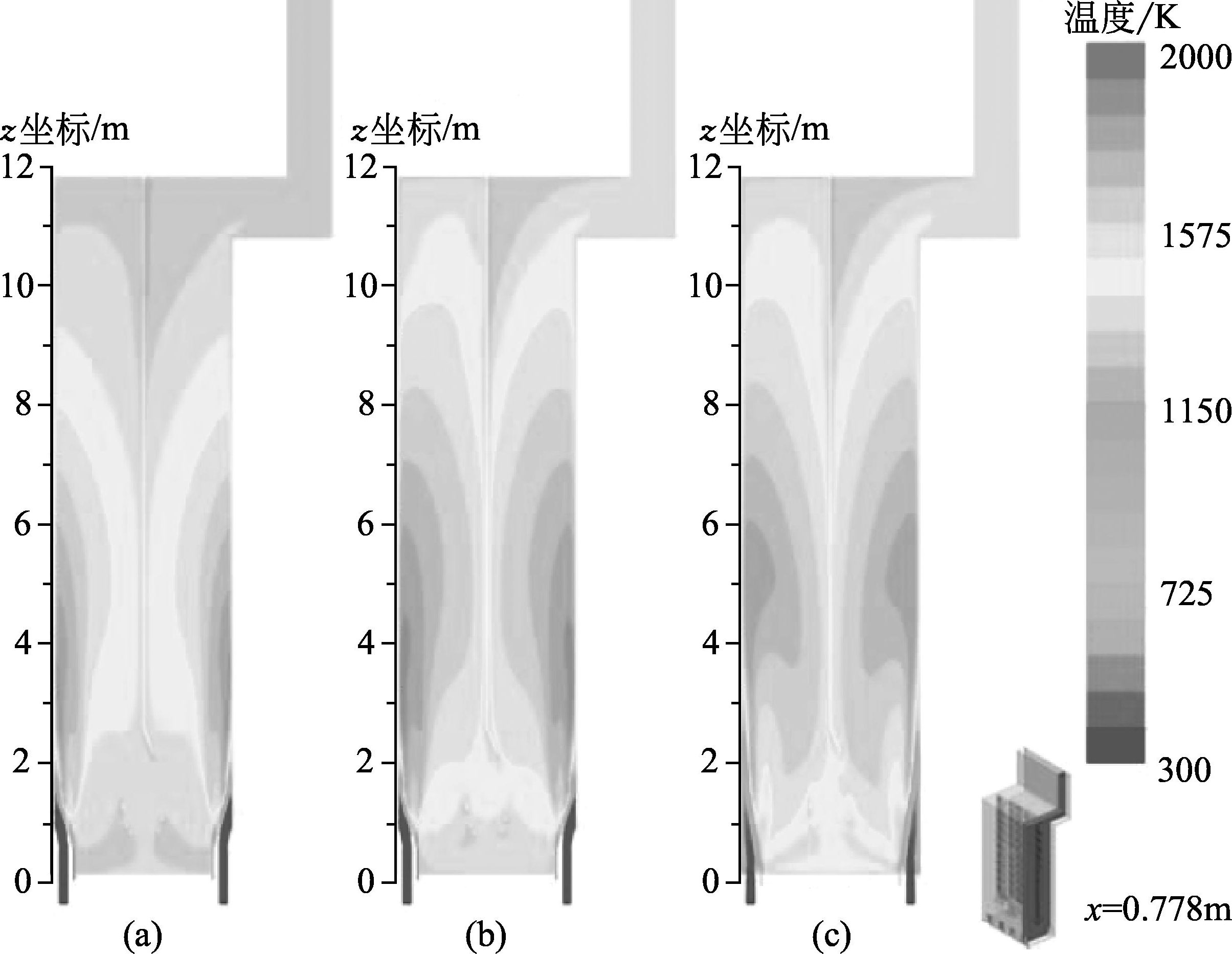
图3-2 裂解炉炉膛内部温度分布图
基于以上研究,华东理工大学开发的裂解炉炉膛燃烧和炉管反应耦合模拟技术,并结合比利时根特大学的Coilsim软件形成了Coilsim-Craft产品。
(3)裂解过程关键性能指标代理模型
金阳坤等针对乙烯生产过程对模型需求层次的不同,基于裂解炉现场运行信息和裂解过程机理,分别建立了裂解过程机理稳态模拟和全周期模拟的智能代理模型 [ 27 ] 。结合所提出的神经网络隐含层节点数自动确定方法和基于预测误差的混合自适应采样方法,提出了一种基于神经网络的自适应智能代理建模方法,并应用该方法建立了裂解炉稳态模拟的智能代理模型。为了克服传统方法获得的全周期模拟的代理模型的预测误差会随着预测时间推移而显著积累的问题,建立了一种基于前馈神经网络-状态空间(FNN-SSM)的裂解炉全周期模拟的智能代理模型,测试结果表明FNN-SSM方法获得的智能代理模型在整个运行周期内具有一致性,且整体预测性能良好。
周书恒等从影响裂解产物产率的因素出发,引出不同裂解过程之间的相似性。着重分析了一种基于实例的迁移学习算法——TrAdaBoost算法 [ 28 ] 。针对特殊应用场景下TrAdaBoost算法的泛化误差较大的问题,提出基于实例的数据集重构迁移学习算法——Bag-TrAdaBoost,解决了旧数据量庞大,易将新信息淹没的难题。UCI数据和工业裂解炉数据的仿真结果验证了新算法的有效性;基于裂解条件不变时产物产率随时间呈指数衰减的特性,同时针对TrAdaBoost及其各类改进算法缺乏对数据本身特性的关注这一问题,对其进行改进,并考虑了实例之间的时序关系。考虑周期运行的裂解炉为产率建模提供了大量的源数据,提出了基于多源时序迁移学习算法——TrAdaBoost.TS算法。UCI数据和工业裂解炉数据的计算结果验证了新算法的有效性。
朱群雄、耿志强等 [ 29 , 30 ] 研究影响裂解炉产物收率的主要因素——温度,结合不同温度下乙烯裂解炉投入与产出配置数据,提出了基于数据包络分析交叉模型(DEACM)和层次融合算法(AHP)结合的乙烯裂解炉能源效率分析与评价算法;通过分析不同裂解温度下每天收率及其结焦情况,运用DEACM模型找到不同温度下最佳生产日期配置标杆;然后基于层次融合算法对所有温度最佳标杆生产配置数据进行融合,得到乙烯裂解炉平均生产标杆,进而得到影响乙烯裂解炉产物收率的最佳生产温度和投入产出配置,分析得到乙烯裂解炉不同温度下最优生产日期的能源效率和最佳裂解温度,实际工业乙烯裂解炉应用验证方法的有效性。
(1)裂解炉裂解深度控制
裂解炉操作的目标是保证一定运行周期的前提下,使裂解炉操作收益最大化(增加产品收率,降低能耗、物耗)。乙烯装置中油品属性变化频繁,COT稳定控制技术保证了COT的稳定,但不能保证裂解深度稳定;由于在线分析仪存在较大的测量滞后(一般为10~30min),而裂解炉反应停留时间只有0.38s左右,不能直接采用在线分析仪的输出结果控制裂解炉的操作。
为此,裂解深度先进控制采用基于裂解深度神经网络预测模型的智能Smith预估控制方案,通过分析油品特性、裂解炉负荷、气烃比、COT等主要参数与裂解深度因子(丙乙比)之间的关系,建立裂解深度预测模型,从而根据裂解炉的运行状况预测当前的裂解深度,并利用在线分析仪分析结果对裂解深度预测模型的输出进行校正,并作为裂解深度控制器的PV值。然后通过深度控制器自动设定COT控制器的设定值。在裂解炉运行后期,当COT温度设定值到达预设的控制限时,现场技术人员可以通过调整裂解炉总进料流量,达到稳定裂解深度的目标。
在深度控制系统中,深度控制器采用带死区的比例-积分-微分(PID)控制策略,该控制策略在DCS系统中有对应的控制模块,故将在DCS中直接实现,这一方面降低了通信故障带来的系统风险;另一方面提高了系统的可操作性能。因为操作人员对DCS的操作过程非常熟悉,系统操作界面优化,维护量小,满足长期投用的要求。
(2)裂解过程监控方法
红外视频检测系统可用于监测裂解炉炉膛内的温度场,如图3-3所示 [ 31 ] 。该系统采用红外热成像,高温探头通过密封连接机构固定在炉墙的侧壁,对炉膛内的情况进行实时监测,并将图像传回计算机进行分析处理。通过一系列算法将炉膛和炉管壁面的红外辐射数据转换成温度,并通过深浅来标识,系统另外配备一些校正参数,可以通过测温枪得到的现场实际温度对热成像系统的温度分布进行校正。监视器上共有32个测温点可供选择,通过拖动鼠标将测温框放置在需要测温的区域,就可以获得该点的温度实时数据,系统每隔10min会进行一次自动采样,并将所有32个点的温度数据保存以供用户导出。除了测温框以外,程序还允许用户自行在监视图像内绘制直线线段,并输出沿着该直线上的一条温度曲线,实时地显示在监测画面的右边,允许同时监测的最大线段数量为8条。该系统可用于以下方面:通过该成像设备对炉管外壁和炉墙温度进行实时监测,及时发现并预防炉膛内可能发生的烧嘴故障、热点的产生等对操作过程不利的因素;通过长时间的数据监测,掌握各炉管的外壁温度随运行周期和炉膛负荷的变化规律,指导炉膛的全周期操作,包括运行及清焦。理想状况下可以得到炉膛、炉管温度与操作时间的关系,从而进行可重复的、便捷的模式操作。

图3-3 红外视频监测的裂解炉炉膛内部温度场
(1)裂解炉裂解深度在线优化技术
裂解炉在运行过程中,由于裂解原料属性和裂解炉运行状态的变化,单一的裂解深度很难保证裂解炉运行在优化状态。裂解深度过低,反应不完全,乙烯产率偏低,产生大量的液体副产品,增加后续分离的负荷;裂解深度过高,尽管乙烯收率高,但丙烯收率低、重组分结焦量增加,裂解炉运行周期缩短。
为此,需要应用裂解炉在线优化技术 [ 32 , 33 ] ,获得最优操作条件,提高裂解炉运行效益。该技术主要包括以下内容。
①裂解原料属性测量和表征 裂解原料通常包括气相(LPG和乙烷等)、轻石脑油、石脑油、尾油等种类。对于气相裂解原料,由于其组成比较简单,可以通过气相色谱的测试方法获得详细的原料组成;而对于石脑油等液相原料,通常只测定其密度、馏程和PIONA值等。
②裂解产品全组分收率预测 首先要建立裂解炉管和炉膛的几何结构模型,再根据过程操作参数,包括裂解炉操作温度、裂解原料横跨温度、进料负荷、气烃比、燃料气组成、裂解原料属性、裂解产品组成等,利用裂解炉模拟软件Coilsim建立裂解炉裂解产品收率预测模型,实现裂解气组成的预测。
③裂解深度在线优化的实现 裂解炉实时优化的技术路线是,从高附加值产品经济效益的角度出发,提出了乙烯裂解炉经济效益优化指标,通过优化该经济指标,能够找到不同的裂解原料以及工艺参数条件下裂解炉运行的最佳裂解深度。同时在优化过程中引入了在线校正和滚动优化思想,能够有效克服高附加值收率模型的不确定性以及工艺扰动。裂解收率在线模型与裂解深度实时优化系统需要裂解原料属性以及当前裂解炉运转条件和变量,其中裂解原料属性可从原料在线分析仪直接得到,或者由实验室分析后人工输入到DCS中的裂解炉优化系统界面,再由DCS上传至实时数据库中;裂解炉优化系统服务器从实时数据库读取油品信息和裂解炉运转条件及变量,计算出当前裂解炉优化结果,通过OPC服务器,再进入DCS系统,作为裂解炉先进控制系统的设定值。
(2)裂解炉群负荷配置优化技术
Jain等最早研究了乙烯裂解炉炉群负荷分配问题,将该问题归结为并行单元多进料的优化调度问题 [ 34 ] 。假设每个单元都具有随着运行周期指数衰减的性能指标函数。结合各种约束,最终归结为混合整数非线性规划问题。采用分支定界算法,将混合整数非线性规划问题转化为多个非线性规划模型,并对一些非线性约束进行线性化处理,如大M法和其他方法转化为线性约束,最终分析了模型的数学特征,求得了全局最优解。该研究对于乙烯裂解炉炉群负荷分配与清焦调度问题还只是处于简单的假设(如假设原料充足,单个裂解炉单个运行周期内只处理一种原料,没有设备运行过程因故障导致的停车等)情况下进行的,而工业现场有许多约束和模型获取仍然是一个巨大的挑战。20多年来,乙烯裂解炉炉群负荷分配和清焦调度问题仍然只是有少数人在研究。这不是工业需求推动力不强,而是真正工业过程极其复杂。乙烯裂解炉炉群负荷分配和清焦调度问题的难点包括:①准确描述裂解过程的模型基础;②过程优化问题的高效求解方法;③熟悉生产工艺流程,提炼对问题的准确描述。Pinto等综述了过程操作调度数学规划的分配和序列模型。尽管一般的调度模型都是与具体问题密切相关的,但仍然可以找出它们当中的共同特点,划入不同的类似约束集。调度模型主要有两个类别:单个单元任务分配模型和多个单元任务分配问题。最主要的问题是建立过程可用的时域表达形式和网络结构。同时也讨论了调度模型中的一些主要特征、计算量和它们的优点及局限性。
华东理工大学研发了裂解炉群负荷动态分配优化技术,解决了以下关键技术:建立了不同裂解原料、不同炉型的产物收率预测模型;构建废热锅炉出口温度预测模型和燃料气消耗模型;构建裂解炉群负荷分配优化模型,开发了智能优化求解算法;开发了裂解炉群负荷动态分配软件平台。
(3)乙烯生产过程能源优化技术
乙烯裂解炉是工业用能、耗能大户,同时也是实施环境保护的重点对象,尤其是在清焦阶段会排放出大量的二氧化碳、一氧化碳和粉尘,在节能减排形势日益严峻的今天,如何利用新的方法和技术达到减排要求是炉群调度过程中的一个重要问题。简海东等在炉群平均利润最大化目标下,采用GAMS软件的DICOPT算法对该MINLP问题进行了求解,获得了每台裂解炉在不同运行周期内适合的原料种类及其生产负荷。此外,也提出了以平均结焦量最小为目标的新的炉群调度优化模型,将两种优化结果做了比较,结果表明后者能够以牺牲少量利润的代价,有效降低生产吨乙烯产品的结焦量,减少清焦过程所产生的CO、CO 2 和粉尘等污染物排放,产生可观的环境效益。
孙海清等在注重石化企业能源利用效率的问题上,强调企业生产装置既包括生产系统,也包括能源系统,生产系统和能源系统存在很强的耦合,既包括物质流上的耦合,也包括能量流上的耦合。采用基于离散时间表达的调度建模方法,建立了蒸汽动力系统中关键设备的子模型以及系统的物料和能量平衡方程,从能源效率的角度,建立了基于
 分析的乙烯装置蒸汽动力系统多周期MINLP调度模型。利用乙烯装置实际数据,以
效率最大化为优化目标实现优化调度计算。在蒸汽动力系统优化调度基础上,研究了乙烯装置的生产系统模型,建立了裂解炉的线性收率模型、燃料消耗模型、超高压蒸汽的发生模型、三机透平的功率消耗模型和分离过程模型。针对乙烯装置生产系统和蒸汽动力系统存在的耦合关系,建立了生产系统和蒸汽动力系统耦合的能量平衡和物料守恒模型。通过与蒸汽动力系统的约束方程集成,提出了以最小化乙烯装置生产成本为目标的MINLP集成优化调度模型,并进行了优化计算与分析。根据乙烯装置的实际运行数据,引入了基于可行域划分的“模式”的概念,以凸区域代理模型为基础,提出了一种基于模式建模的MINLP集成优化调度模型,能够得到更符合实际生产的调度策略。
分析的乙烯装置蒸汽动力系统多周期MINLP调度模型。利用乙烯装置实际数据,以
效率最大化为优化目标实现优化调度计算。在蒸汽动力系统优化调度基础上,研究了乙烯装置的生产系统模型,建立了裂解炉的线性收率模型、燃料消耗模型、超高压蒸汽的发生模型、三机透平的功率消耗模型和分离过程模型。针对乙烯装置生产系统和蒸汽动力系统存在的耦合关系,建立了生产系统和蒸汽动力系统耦合的能量平衡和物料守恒模型。通过与蒸汽动力系统的约束方程集成,提出了以最小化乙烯装置生产成本为目标的MINLP集成优化调度模型,并进行了优化计算与分析。根据乙烯装置的实际运行数据,引入了基于可行域划分的“模式”的概念,以凸区域代理模型为基础,提出了一种基于模式建模的MINLP集成优化调度模型,能够得到更符合实际生产的调度策略。
(4)乙烯生产过程多目标优化技术
乙烯生产过程中原料油及其水、电、燃料、蒸汽等能源工质是影响乙烯能效的主要投入因素,如何对这些目标合理分析与优化是乙烯生产过程主要多目标优化问题。不同规模、不同技术、不同生产配置,乙烯生产能效也会不同,过高的乙烯生产投入以及生产乙烯、丙烯等有效产物量少将导致乙烯生产过程能效低。因而研究基于松弛变量的数据包络分析(DEA)乙烯生产过程能效评价与优化方法有助于指导乙烯生产配置,提高乙烯生产能效。通过运用DEA模型得到同种技术或同种规模下不同生产配置最佳能效标杆,结合DEA模型中的松弛变量,得到低能效乙烯生产配置中投入产出的改进物理量,进而优化非有效乙烯生产配置,达到有效生产 [ 35 , 36 ] 。
北京化工大学以中石化和Lummus公司联合开发的SL-Ⅰ型裂解炉为例,建立了乙烯裂解炉工艺机理模型,针对原Kumar反应动力学模型对不同石脑油适应性差的缺点,提出了一种序列二次规划混沌粒子群优化算法(SQPCPSO),并利用该算法对原Kumar模型的10个一次反应选择性系数和二次反应动力学参数进行优化调整,基于反应过程碳和氢原子平衡、模型与实际产物收率误差为综合优化目标函数,调整结果比原Kumar模型的精度更高,提高了模型的适应性和准确性,不同石脑油和不同炉型的计算结果表明了所提方法的有效性和实用性 [ 37 ] 。同时,研究了基于模糊聚类算法的石脑油性质的相似识别,建立了不同聚类油品的Kumar反应动力学模型库及优化操作模型库;基于过程操作数据、工艺数据、经验知识等,提出了一种基于数据和机理模型融合驱动的乙烯裂解炉过程建模方法;针对在线数据建模精度和再学习问题,提出了一种基于软阈值法的自适应主元提取的WMPCA新算法,以及一种WMPCA-RBF自学习调整的过程在线建模方法,提高了在线建模的精度和适应性。在上述工作的基础上,研究了乙烯裂解炉生产过程的智能优化操作解决方案,提出了一种多群竞争自适应粒子群优化算法(FCMAPSO),并利用该算法对乙烯裂解炉融合模型进行优化,结合多油品相似性、工况模式识别,实现了不同油品模型智能优化预测控制,开发完成了乙烯裂解炉优化操作软件系统,实际应用结果验证了所提优化方案的有效性和实用性。针对乙烯裂解炉的多目标优化操作问题,研究设计了乙烯裂解炉生产过程多目标优化策略和解的综合评价方法,提出了一种基于动态层次分析的自适应多目标粒子群进化算法,实时动态客观决策、自适应调节粒子进化状态参数,提高了目标解的分布均匀性和多样性。考虑产物收率、结焦厚度与运行周期等多个目标和操作约束,实现了不同目标之间协调和均衡策略,根据偏好选择合适的优化操作条件,为乙烯裂解炉的多目标优化运行提供了一种可行的解决方案。
Pandey等对乙烯厂的冷端分离过程进行了模拟,然后采用精英非支配排序遗传算法(NSGA)对该过程进行了最大化利润、满足产品需求和规格的多目标优化处理,实验结果得到满足决策者偏好的折中解。
Yu等提出了一种自适应的多目标教学式优化(SA-MTLBO)算法,该算法产生的Pareto最优前沿具有良好的收敛性与分布性。将SA-MTLBO算法用以优化石脑油裂解制取乙烯过程,并在得到的非劣解集中,采用快速非劣解排序方法与拥挤距离法对非劣解进行排序,用以实现产物(乙烯、丙烯与丁二烯)产量最大化的多目标优化操作。
随着现代工业的迅速发展,石油作为国家战略物资在国民经济中发挥着至关重要的作用。中国的石油资源比较匮乏,根据《BP世界能源统计年鉴2015》报道,截至2012年,中国石油净进口量增长61万桶/日,占全世界增量的86%。中国已经成为全世界最大的石油进口国。炼油厂中60%~70%的原油将最终转化为汽油,汽油生产环节蕴藏着巨大的经济效益,汽油产品不仅是炼油厂的重要经济来源,而且关系到整个社会的稳定,同时还对生态环境有着深远的影响。随着我国汽车保有量的持续增加,高品质汽油产品的需求量不断攀升,由汽车尾气带来的环境问题也越来越尖锐:《2014中国环境状况公报》显示,2014年在全国开展空气质量检测的161个城市中,仅有16个城市空气质量年均值达标,145个城市空气质量超标。环境问题促使我国汽油标准加快升级。
汽油调和是汽油产品生产过程中的最后一步,旨在充分利用炼厂的油品资源生产出产品质量过剩最小的高品质汽油,并最大限度地提高一次调和成功率。汽油调和是成品汽油生产技术的核心,直接影响到汽油产品的质量,并关系到整个汽油生产的经济效益。典型的汽油调和是指在汽油的生产过程中,将不同的组分油,按照一定的调和比例,并加入抗氧剂、抗静电剂等油品添加剂,调配出符合国家质量标准规定的所有指标的成品汽油的过程。按混合方式不同,汽油调和可分为罐式调和和管道调和两种类型。调和配方可优化控制是汽油管道调和最大的优点,其发展依赖于过程分析技术、计算机技术、自动化技术、人工智能、数据库技术,最主要的特点是:调和系统中引入了过程分析仪表,使得调和调度任务、调和配方的实时优化得以实现,并便于不确定事件的处理。管道调和系统的控制优化技术主要包括以下几个部分(图3-4):汽油属性的在线检测技术,调和建模与在线校正技术,调和实时滚动优化技术,以及调和调度优化技术。
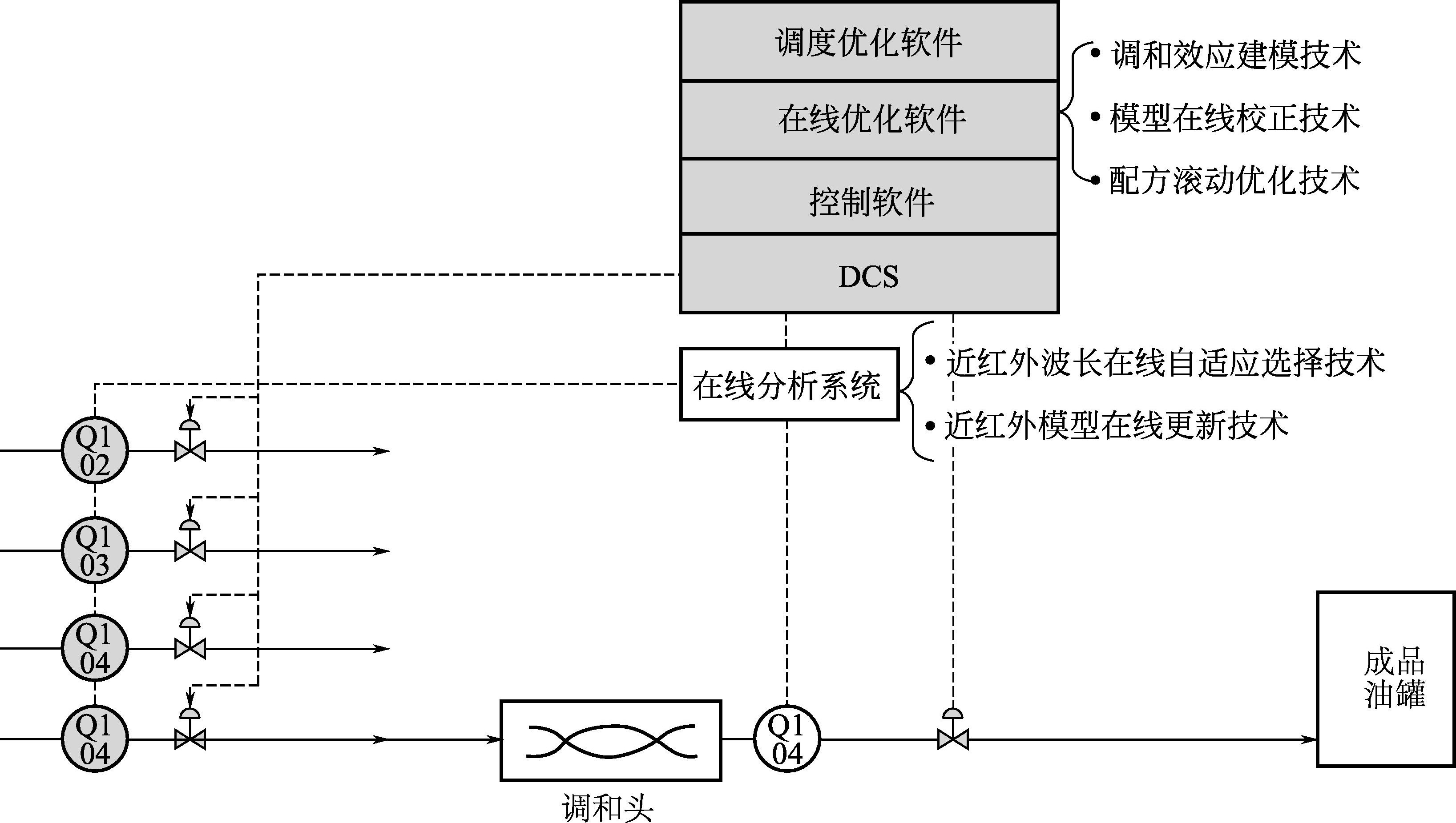
图3-4 汽油调和控制优化系统结构图
其中汽油属性的在线检测技术,通过近红外分析仪表和化学计量学模型,对汽油组分油和成品油的关键属性进行在线检测,如辛烷值、馏程、芳烃、烯烃含量等。调和建模与在线校正技术:为根据组分油配方和属性,对调和成品油属性进行预测的数学模型;为保证其长期有效性,必须在运行过程中,实时地对模型参数进行在线辨识和校正。调和实时滚动优化技术:根据在线检测的数据,以调和模型为基础,对调和配方进行在线优化,从而达到成品油质量和成本的最优化。调和调度计划技术:为针对多个批次的调和的调度问题,通过多批次调度优化,在生产多种约束的前提下,找到最合理的调和生产模式,提高调和的生产效率。
汽油属性的在线分析主要通过在线近红外分析仪实现。在线近红外分析是过程分析技术的一种,过程分析技术覆盖自动化、计算机、化工工艺、化学计量学等多学科的复合技术领域。近红外分析技术是通过对样品近红外光谱的分析来测量该样本的相关物理化学性质。20世纪80年代以来,近红外光谱分析技术得到快速的发展,并在农牧业、林业、食品、药品、造纸等多个领域有着极其广泛的应用,其在汽油调和中的使用促进了调和优化控制技术的发展,并在国内外引起广泛的关注。
我国对近红外技术的应用研究始于20世纪90年代初期,1996年以来有大量的文献报道了在线近红外分析系统在汽油调和过程中的应用,陆婉珍院士在其著作《现代近红外光谱分析技术》 [ 38 ] 中对近红外技术的原理、发展以及在石油化工过程中的应用作了细致的探讨,并给出了使用该技术的一般方法。近红外的使用离不开近红外光谱与待测样本属性之间的数学模型,对近红外技术的研究和应用主要集中在光谱建模问题上。近红外定量分析模型的研究主要集中在四个方面:光谱预处理方法、波长或变量选择算法、模型拟合方法、模型更新策略等。
由于近红外模型是该分析仪表能否准确检测汽油属性的关键,并且在生产过程中,随着生产条件和状态的变化,模型的精度会不断降级,直至失去有效性,因此,为了提高近红外模型的长期有效性,相应的模型自适应和在线更新技术得到开发及应用。
(1)近红外建模波长选择与在线自适应技术
汽油的近红外光谱含有大量重叠的宽谱带,很少有锐锋和基线分离的峰,光谱的“指纹性”较弱,而且倍频与合频吸收更容易受到温度和氢键的影响,此外,光谱的吸收强度也非常弱,这些特点使建立准确可靠的近红外模型非常困难 [ 39 ] 。
近红外光谱中包含了物质大量的物理、化学信息,但是对特定的性质并不是所有波长点的贡献都相同,无效信息或有效信息含量较少的波长点的引入会将噪声和扰动带入模型,降低模型的解释性,并增加计算复杂度 [ 40 ] 。因此,光谱波长选择是建立近红外分析模型的基础和重要步骤 [ 41 ] ,其目的是针对特定的样品体系,通过对光谱波长结构的适当选择,减弱各种非目标因素对校正模型的影响,尽可能地去除无关信息变量,从而简化模型、减少计算复杂度并提高模型的预测性能及鲁棒性 [ 42 ~ 44 ] 。
近红外光谱波长选择和压缩方法从处理对象不同的角度可分为两类:一种是从原始波长中直接选择有效变量,该类方法主要包括连续投影法(SPA)、无信息变量消除(UVE)、人工智能算法(GA、粒子群)等,其中CARS(competitive adaptive reweighted sampling)算法是这类方法的典型代表;另一种是采用信号处理技术对初始波长进行降维压缩,如利用PCA算法对光谱处理并提取主成分 [ 45 ] ,使用小波变换进行信息提取等。其中,第一类方法一般能够选择出数量较少的波长用于建模,并可以取得与全波长建模相似或更好的效果。这种方法虽然能够提高模型计算的效率,但是往往会因为去除了较多的变量而遗漏了很多有用信息,影响模型的鲁棒性,模型的延展性不佳。PCA是一种有效的降维算法 [ 46 ] ,可以消除变量间的多重相关性,在近红外建模过程中也已有相当广泛的应用。与第一类方法相比,PCA所提取的主成分能够更好地表征光谱信息,信息遗漏相对较少。然而在利用PCA提取主成分的时候只考虑了主成分对光谱的代表性,却没有考虑到其对样本属性的表征。对于相同的光谱样本、不同属性的建模过程中,采用PCA方法得到的主成分是相同的,这使得模型的针对性不强,不利于提高模型的预测精度。
结合两类方法,从而达到取长补短的目的,融合PCA-GA算法的近红外光谱变量选择策略。该方法首先利用PCA技术对原始光谱进行坐标转换,以消除波长间的多重相关性,然后选取特征值累积贡献率大于90%的特征变量。对剩余的特征变量,采用GA算法进行选择,之后将两个步骤中所选出的特征变量融合在一起,形成投影矩阵,用于对原始光谱降维。按特征值贡献率的选取方法能够保证经过PCA-GA筛选之后形成的新主成分对初始光谱具有充分的代表,GA算法的运用可以从剩余的成分中提取对因变量具有最大相关的信息,不仅具有很强的针对性,而且可避免或减少信息的遗漏,这对于提高模型的鲁棒性和预测精度非常关键。
上述的波长选择,一般均在离线建模阶段进行。在模型建立完成以后,即可与近红外仪表结合,进行对汽油样品的检测,在使用期间只能保持所构建的波长结构与模型系数不变。而实际生产过程中调和配方的改变、参调组分油的变更、原油种类及属性的波动、仪器响应误差等都会影响近红外模型的预测精度,又由于在不同的工况下相同波长段所表征的信息不同,固定的波长结构必将导致模型的预测准确性、鲁棒性会变差。
为使近红外定量分析模型的波长结构能够根据工况变化实时更新,一种基于偏最小二乘的自适应波长选择及局部建模策略(adaptive wavelength selection and local regression strategy based PLS,AWL-PLS)得到了研究和应用。相比于静态建模方法,该算法采用实时建模策略,其建模与预测过程融合在一起。在算法的实现过程中,首先根据待分析样本的近红外光谱从数据库中选取样本建立校正集;然后,对所选取的校正集进行波长选择,删除无信息或有效信息含量较少的波长段;最后,利用已确定的波长结构与校正集建立NIR定量分析模型并对待测光谱进行分析。从上述基本步骤可以看出,采用该局部策略建模并更新模型的过程中,需要解决两个关键问题,光谱相似度定义和光谱波长更新方法。
AWL-PLS方法采用有监督局部保留投影(supervised locality preserving projection,SLPP)算法对光谱降维,然后根据降维后的特征向量利用欧式距离结合向量的夹角余弦值度量样本间的相似性。SLPP是对局部保留投影算法(locality preserving projection,LPP)的改进,其主要思想与LPP相同:使原始空间中距离较近的点,在降维后的低维空间中也保持较近的局部结构。通过相似度定义,可以从光谱数据库中选择与当前光谱相似的光谱,用于波长自适应选择和近红外模型的建立。
在选择相似光谱完成后,波长的自适应更新及选择算法是建立AWL-PLS模型的关键之一,也是近红外定量分析中不可或缺的一步。在近红外分析中常用的波长选择算法大都属于有监督选择的范畴,即在波长选择过程中需要同时用到样本的光谱矩阵和属性信息,建立定量分析模型;然后通过一定的规则选出使模型的均方误差最小、决定系数最大的波长结构。针对特定的样本集,有监督选择方法往往能够获得较好的结果,然而在实际应用中,尤其是用于在线检测的过程中,当待测样本随生产过程的变化与校正集所涵盖的范围发生偏离,初始的波长结构会逐渐由最优变为次优,进而导致NIR模型产生较大的预测误差。由于波长的更新依赖于样本的属性信息(如汽油样本的辛烷值、蒸气压等),这些信息的获取需要人工采样并在实验室进行分析,滞后时间较长,不能及时地完成波长结构重选与更新。为了使近红外模型的波长结构能够随生产过程的变化动态更新,开发了一种融合相关系数与方差分析的无监督、自适应波长选择方法,从而提高了模型自适应的能力。具体方法为,对相关系数法进行改进,使其能够在不增加新的样本属性信息的条件下可以度量每个波长点对待分析样本属性的重要性。
(2)近红外检测模型的在线更新技术
近红外是一种间接分析技术,需要通过建立校正模型来实现对未知样本的定性或定量检测。建立校正模型所选取的训练集样品、光谱预处理方法、波长选择技术、建模算法等都会对近红外检测结果产生影响。近红外模型的建立和更新是保证该系统正常运行的关键步骤,也是近红外日常维护的主要工作。在使用近红外技术对物质属性进行分析的过程中,为了使模型能够适应工业实际情况,需要向现有模型中添加新的样品来更新和扩展模型。这就需要对近红外模型本身进行在线的自适应更新和校正。
现有的自适应建模及模型更新方法大致可以分为两种类型 [ 47 ] :①采用递归算法将新的样本添加进原始校正集,以此将最新工况特征增加进模型中,减弱历史数据对当前模型的影响,从而拓展模型范围;②采用即时学习(just in time,JIT)策略,根据待分析样本的特点更新模型,完成模型在采样间隔的更新。递归方法可以有效地利用新样本信息来更新模型,但是对于近红外系统,由于采样间隔较长,模型的更新无法抵消其衰减的速度,这就造成递归的优势无法充分发挥,效果不明显。即时学习策略可以有效地解决采样间隔模型跟踪能力衰减的问题,将其与递归算法结合可以实现模型的闭环更新:在采样间隔,根据即时学习策略对待测样品建立局部模型进行分析;当光谱样本的参考属性可用时,利用递归算法更新初始校正集,使模型的整体结构适应最新工况要求。
结合上述两种方法的优缺点,提出了一种基于奇异点判别的自适应建模及模型维护方法[实时递归及局部权重偏最小二乘算法(online recursive and locally weighted PLS algorithm,ORL-PLS)]:采用递归策略将模型的更新融合到在线分析过程中,通过对光谱样本的检测,分离异常样本点,有区别地将新的可用样本更新至校正模型中;在对待测样品分析的过程中,模型采用局部学习策略,根据待测样品的光谱特征来更新校正集样本权重。
ORL-PLS方法集合递归PLS和JIT策略,在有新的样品添加时,利用递归PLS方法更新协方差矩阵,在没有新的样品添加时,利用JIT策略更新协方差矩阵。通过结合递归PLS和JIT策略保证协方差矩阵的不断更新,保证PLS模型的协方差矩阵能够得到最迅速的更新,从而保证率模型的精度和长期有效性。
汽油调和的关键问题在于调和配方的求解和优化,而配方的求解必须以调和模型为基础。调和模型为根据组分油的属性和调和配方对成品油属性进行计算及预测的数学公式。汽油生产过程中需要控制的质量属性主要包括:研究法辛烷值、马达法辛烷值、蒸气压、硫含量、苯含量、芳烃含量、烯烃含量、密度、干点、馏程等。在这些属性中,硫含量、苯含量、芳烃含量、烯烃含量、密度等满足线性调和关系,采用线性模型就可以满足工业现场的要求;而蒸气压、辛烷值等属性具有明显的非线性特点,往往需要分别建立模型。
本小节以汽油关键指标辛烷值为例,简单介绍调和效应模型及其在线校正技术。现有的辛烷值调和关系模型大致可分为两类:回归模型和神经网络模型,两类模型各有优缺点,并且在工业现场都有相应的应用实例。但是由于这些模型的计算过程复杂、时效性不好、模型维护难度大等原因使得其在工业现场的普及率不高,目前国内炼厂计算汽油调和配方的主要模型仍然是线性模型。
针对上述问题,结合现场操作人员的知识和经验,开发了调和效应模型与在线校正技术。组分在调和前单独测量的辛烷值与其在调和过程中表现出的实际辛烷值往往有较大差值,这个差值被调和调度人员定性地称为调和效应。调和效应数值的定量计算,往往是根据调和经验来进行主观估计,缺少定量的计算和辨识方法。调和效应模型,使用调和效应参数对组分油的属性进行补偿,并对补偿后的组分油属性进行线性叠加,完成对成品油属性的预测。这种方式不但能够提高模型的精度,而且能够在模型的形式上继续保持线性,从而可以使用最小二乘方法,结合调和实验数据,将调和效应参数定量地辨识出来。
与近红外的化学计量学模型类似,调和效应参数也会随着组分油的参调量与本身属性的变化而变化。因此,调和效应参数会随着时间的推移而逐渐失效。在线校正技术考虑到调和效应参数的这种特性,以调和总管成品油的检测属性为基础,使用改进的递归最小二乘方法,对调和效应参数进行在线辨识和校正,动态、实时地调整调和效应参数,从而保证了配方优化使用的调和模型的精度。
调和效应模型,虽然是以辛烷值为例进行开发完成的,但是由于调和效应的类似性,相关的技术完全可以推广应用到汽油的其他属性,如馏程和蒸气压。此外,调和效应模型的在线校正技术具有非常强的工程应用价值。使用该技术,不但能够彻底地取消调和模型离线建模和维护的工作量,而且能够对组分油的属性在线检测误差进行补偿,进一步减少对近红外模型的维护工作量。通过该技术的应用,可以极大地提高汽油调和系统的工业应用性,提高优化系统的投用率。
汽油调和优化的目标是调和成本最低或成品汽油质量过剩最小,同时要结合实际生产状况,综合考虑满足各种汽油质量指标约束(包括RON、MON、DON、RVP、硫含量、苯含量、氧含量、烯烃含量、芳烃含量、密度等)各组分油的库存和产量限制以及各组分油的配方限制等。与传统的罐式调和不同,管道调和的优化方式往往采用在线的方式,即在调和过程中,并不是一直完全按照调和的初始配方进行操作,而是根据在线检测到的组分油和成品油质量属性,结合调和模型,对调和配方进行在线优化。优化后的配方下达到DCS上进行执行,执行后的调和结果,经过在线检测系统的测量,再次反馈到调和优化系统中对调和配方进行优化。这种周期性的优化方式,形成了质量优化的闭环在线运行,能够在组分油属性波动的情况下,仍然很好地达到预期的调和效果,并将质量过剩及调和成本控制到最低。
传统的罐式调和只需要在开始前对调和配方进行计算和优化,虽然调和模型的非线性和多个等式及不等式约束为优化问题的求解带来一定的难度,但是由于求解问题的静态特性和较低的维度,其求解的配方优化问题相对比较简单。管道调和在运行中的配方在线优化,不但是周期性地对调和配方优化问题进行求解,而且其优化问题也是随着时间在动态变化的。在调和运行过程中,两个优化周期之间,调和过程在连续运行,调和的成品油也在连续地进入调和目标罐中。因此,在优化周期到来时,需要首先对配方优化问题进行更新,需要对目标罐中已经完成的部分进行更新,包括累积体积更新和累积质量属性更新。在每次优化的时候,可以优化的部分都是目标罐中调和未完成的空白部分,因此汽油调和配方的在线优化问题,在本质上属于时间窗口滑动的滚动优化问题。结合该优化问题特性开发的在线滚动优化技术,在每个优化执行周期,都会按照如图3-5所示的方式对调和模型进行更新,对目标罐和优化问题进行更新,然后再进行优化问题的求解,从而给出最新、最优的调和配方,用以执行。
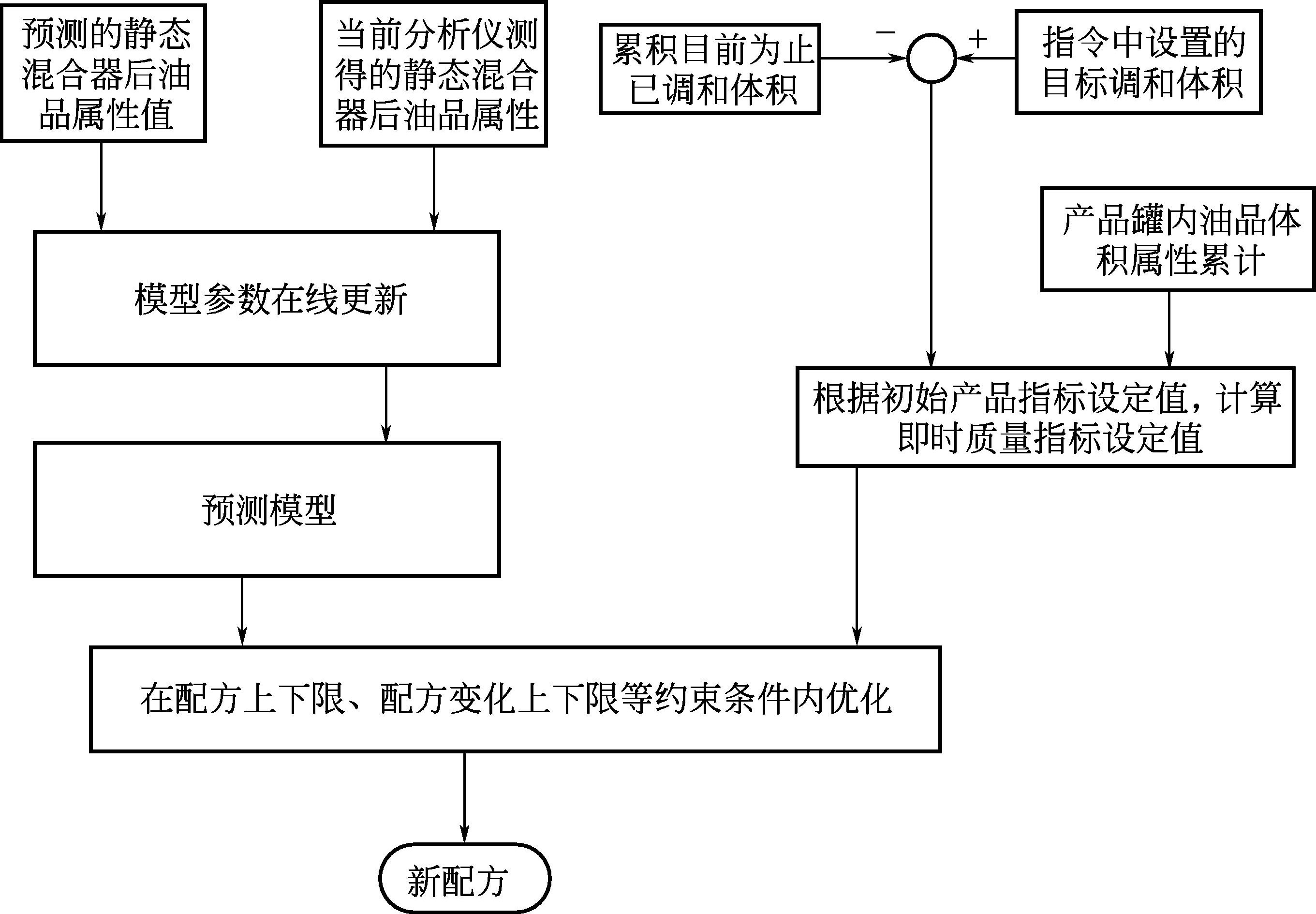
图3-5 汽油配方在线优化流程
生产计划与调度方案的制定是产品生产之前需要完成的重要任务;在企业中起着承上启下的作用,是生产过程顺利进行的关键因素;合理有效的计划与调度方案能够提高资源的利用率、减少操作损失、增加利润空间 [ 48 ] 。汽油调和过程的生产调度位于整个汽油生产过程的最顶层,决定了汽油产品的产量、排产顺序、订单交付等诸多与市场联系紧密的生产操作,对于提高炼厂效益非常重要,一直以来都是炼油企业关注的重点 [ 49 ] 。
调和调度是对计划方案的具体执行,根据计划层制定的各汽油产品的总产量,在组分油产率、调和头加工能力、组分油罐和产品油罐库存水平等操作约束以及产品质量指标等属性约束下,安排每周或每天调和系统所需要生产的汽油产品牌号以及各牌号汽油的产量。
传统的调度模型都是假设每天订单已知,然后进行生产排产,然而,提货订单通常具有较大的不确定性,很难预先获知准确的提货量,传统的调度方案制定方法较难妥善处理这种不确定性。因此在建立调度模型的时候,应假设每个调和周期的订单信息未知,而调度时域内各牌号汽油的总需求量已知;调度模型根据调和头加工能力、组分油产能等操作约束安排各牌号汽油的生产、提货时序,从而在订单到来之前给出较合理的生产方案和预估提货方案,这对于提高企业的市场应变能力具有重要的现实意义。
此外,调度系统不能完全独立于上层的计划和下层的在线优化系统。因此,调和调度系统应与计划和在线优化系统形成有机的整体,完成调和全周期的优化运行。主要内容如下。
①计划任务有效性的验证。计划任务的验证,以调和关系模型为基础,进行计划周期内的任务有效性验证和优化。改优化问题不需考虑生产的顺序,只需考虑计划周期内的整体组分油和成品油的产量与平均属性,因此计划的优化问题是连续NLP问题。
②调度系统需要给出多个调和批次的排产顺序和每个调和批次的具体生产参数,如参调组分油、初始配方、成品目标罐等,因此调度问题需要求解的是一个复杂的MINLP问题。
③具体调和批次运行中,配方在线优化技术会在线、周期性地对当前的调和配方进行优化,从而保证当前批次的配方最优性。
④每个批次调和完成后,调和的数据将反馈给计划和调度系统,并结合新到的订单信息,对下一个批次开始的调度周期进行多批次的调度优化。因此,整个调度和配方在线优化系统形成了闭环在线优化,达到了在不同时间尺度的整体优化。
田洲等提出了一种乙烯聚合过程模型与性能-结构关系模型集成的建模方法 [ 50 ] ,模型框架如图3-6所示。过程模型可以预测聚乙烯的微观链结构——短支链分布和分子量分布。修正的结构-性能关系模型考虑了短支链分布的影响,实现了从产品链结构直接估计材料的耐慢速裂纹增长性能(SCG)。通过耦合过程模型和结构-性能关系模型,揭示了关键工艺参数对聚乙烯分子量分布与短支链分布联动以及管材SCG的影响规律。
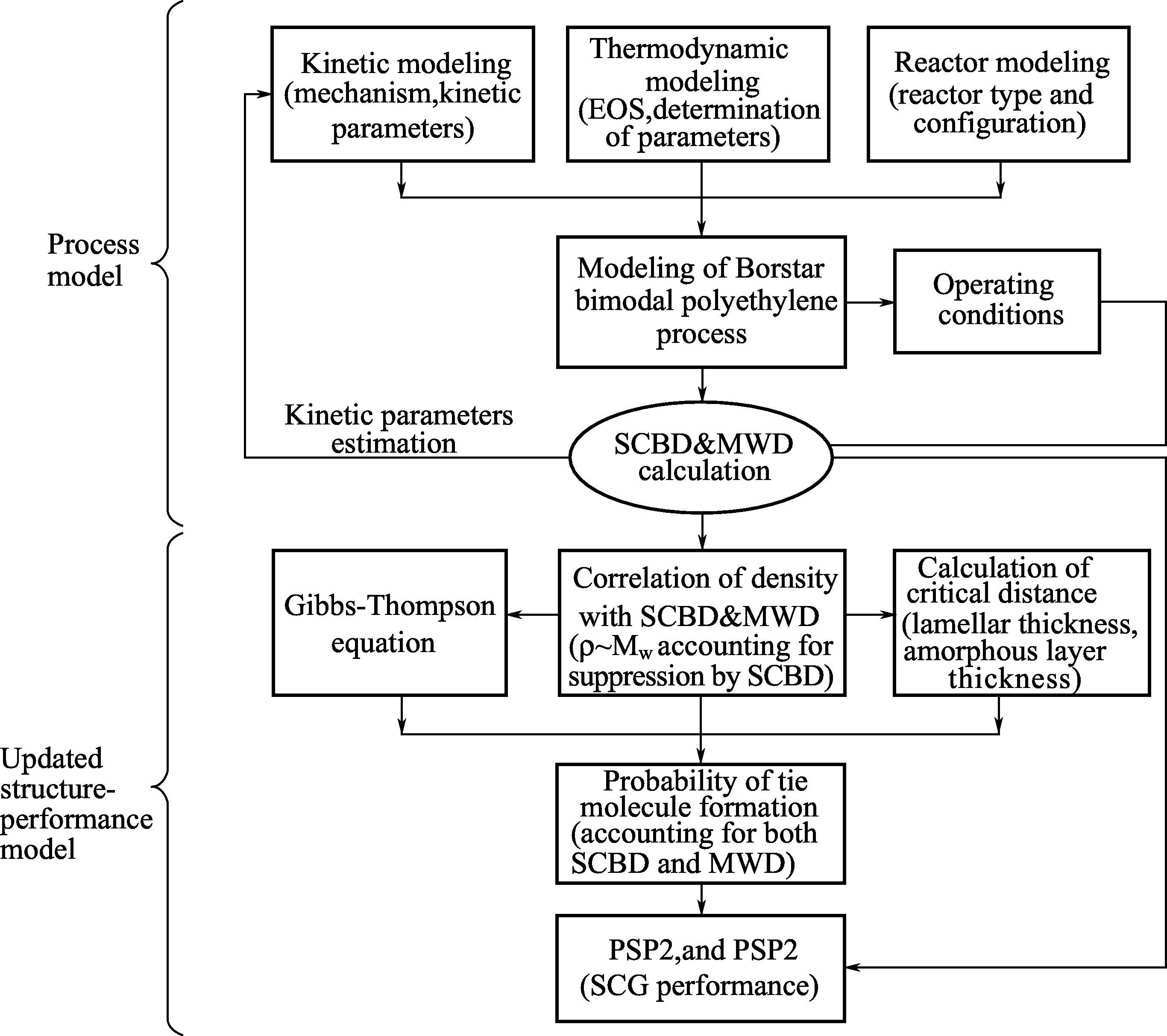
图3-6 聚烯烃性能-结构关系模型框架图
共聚物组成及其分布为共聚物提供了一个清晰的三维分布模型,Monte Carlo方法十分适合于模拟共聚物的组成分布,但从计算时间的角度来说,该方法效率较低。翁金祖等人通过将传统Monte Carlo模拟中的所有链分解成数百万个线程,提出了一种基于GPU平台的计算微观分布的并行Monte Carlo模拟方法 [ 51 ] 。之后给出了基于所提并行方法的加速比的理论分析。所提方法在不同实例中均表现出良好的并行性能。该方法在处理三元或者更多元共聚过程中具有更大的优势。作者认为所提方法有可能扩展到其他微观分布甚至是基于Monte Carlo模拟的过程优化上。
张晨等人从固定流程工艺结构(串联和并联)出发,对聚合过程的反应器网络综合问题展开研究,将工艺操作条件的反演优化和流程结构的重组优化问题相结合 [ 52 ] 。首先根据聚合工艺的结构特点,在给定的过程装置上,构造了由CSTR和分流器相互连接组成的广义超结构网络。与传统的反应釜串联或并联的流程结构不同,此超结构通过分流器的引入将所有的反应器相互连接,使得各反应釜出料处的聚合物可通过回流发生进一步的反值,从而开发出流程整体的生产潜能,也为之后的流程重构优化奠定了模型基础。基于此超结构模型,构建了单体转化率最大化和MWD误差最小化的流程重构优化命题,并改进和利用不同的多目标优化方法,通过系统地调整连续型决策变量,求解得到最优的流程结构和工艺操作条件。最终针对不同的MWD指标约束(双峰、三峰),研究和验证了此流程重构优化方法的适用性和有效性:最优的流程结构方案克服了传统流程结构的工艺局限性,在保证多种产品期望质量指标的同时有望大幅提升过程产能。
张晨等基于构建的完整联立方程机理模型,利用HDPE工业过程的现场数据进行了模拟计算,通过分子量分布模拟计算值和实际测量值的比较,验证了此联立模型的准确性和良好的收敛性能,并为流程工艺的操作优化奠定了计算基础。提出了用于求解大规模NLP问题的系统性优化算法策略,它将各类NLP求解器和其内部算法参数的自动整定方法相结合,有效提升了求解器的性能。最终应用此优化策略,针对HDPE游浆聚合过程进行了固定流程结构下的稳态产量优化研究 [ 53 ] 。结果显示,在串联和并联结构下,优化后的工艺操作条件使得指定HDPE产品的产量得到了一定的提升,同时满足期望的单峰或者双峰分子量分布,从而证明了此优化策略的适用性和有效性。
高密度聚乙烯(high density polyethylene,HDPE)作为注塑制品、电器导线护套、塑料管道、安全帽、纤维等的原材料被广泛用于与生活息息相关的诸多行业,例如农业、机械、汽车、电工电子以及日常生活用品等。高密度聚乙烯的生产工艺流程如图3-7所示,主要由四部分构成,即原料催化剂预处理工段,此工段对反应主要原料以及催化剂等辅助材料进行去杂质等处理;反应工段,该工段为高密度聚乙烯的反应关键阶段;后续处理工段,该工段对产品进行提取等操作;溶剂己烷回收工段,该工段对部分未使用的材料进行回收处理。该生产工艺悬浮聚合阶段采用的是德国Basell公司研制的Hostalen低压淤浆装置。生产高密度聚乙烯的主要原材料为以乙烯,其中用氢气来平衡产物的分子量,有1-丁烯共聚单体等中间产物。
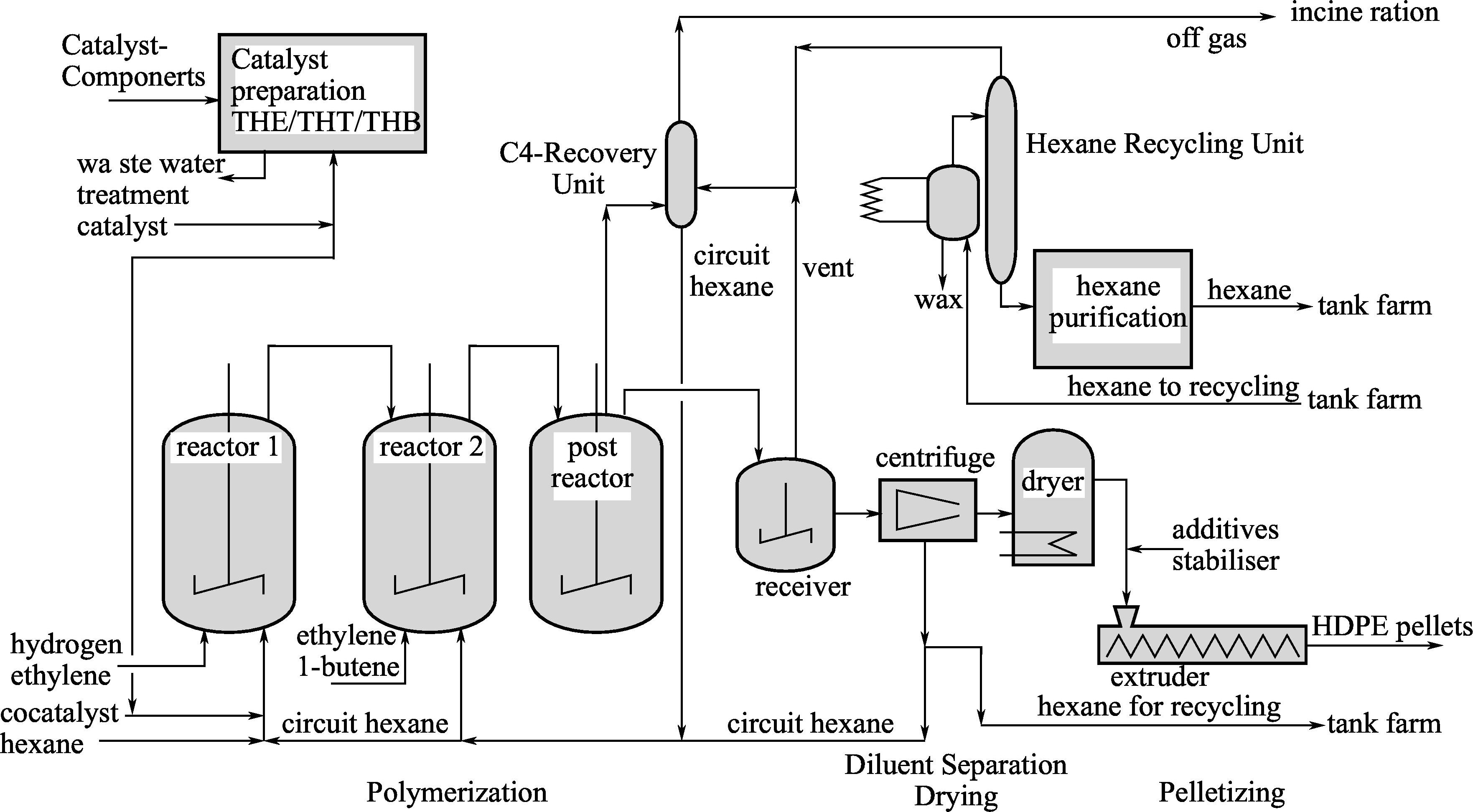
图3-7 高密度聚乙烯的生产工艺流程
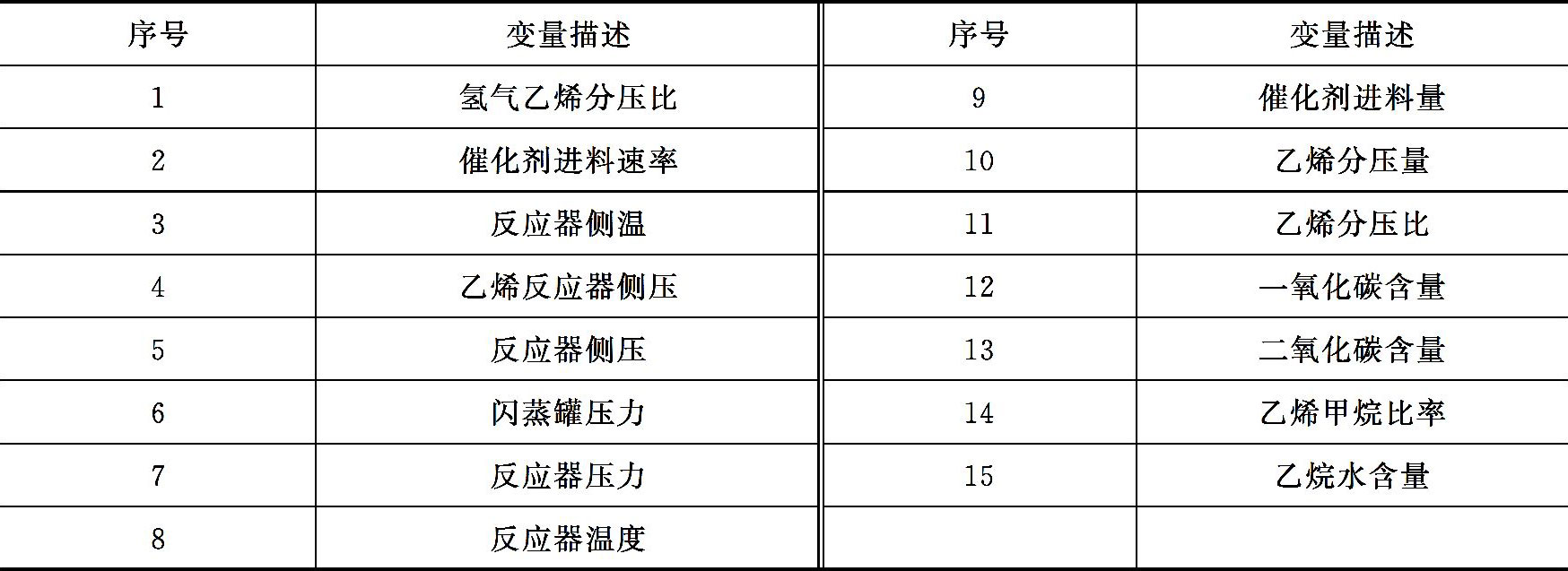
高密度聚乙烯生产过程中,如何有效降低乙烯原材料的单耗是一个待解决的问题,为此建立高密度聚乙烯生产过程的乙烯单耗模型具有一定的指导意义。通过分析装置流程,最后选出15个与其息息相关的辅助变量:氢气乙烯分压比、催化剂进料速率、反应器侧温、乙烯反应器侧压、反应器侧压、闪蒸罐压力、反应器压力、反应器温度、催化剂进料量、乙烯分压量、乙烯分压比、一氧化碳含量、二氧化碳含量、乙烯甲烷比率以及乙烷水含量;待测变量为乙烯单耗。HDPE模型输入数据见表3-1。
表3-1 HDPE模型输入数据
常用的石化生产过程模型大致分为三类:白箱模型、黑箱模型以及灰箱模型。白箱模型是通过对石化过程机理的分析而建立的,也被称作机理模型。建立机理模型的前提是要充分分析石化过程内部的反应机制,随着现代的石化生产过程越来越多样化、复杂化、集成化,相应的机理知识很难获取,由此机理模型不再适用于复杂化工过程建模。黑箱模型是避开分析复杂的机理而从数据的角度建立的,也被称作经验模型,神经网络方法具有较强的非线性映射能力,已经广泛应用于复杂化工过程建模。灰箱模型是结合了部分机理知识和数据知识的混合模型,也被称作混合模型,混合模型也应用到了部分机理模型,不太适用于现代复杂化工过程建模。
HDPE生产过程呈现高非线性、相关变量多维性、工艺高度复杂和流程高度综合等特点,因此导致采用机理分析的方法建立模型越来越棘手。先进的传感技术使得过程数据越来越容易被采集和存储,这些过程数据背后蕴含着重要的过程知识,所以基于数据驱动策略的方法在解决复杂流程工业过程建模的问题中发挥着越来越重要的作用。贺彦林等 [ 54 ] 提出具有抗干扰的递阶极限学习机网络(图3-8),建立了高密度聚乙烯生产过程精确度较高的乙烯单耗模型。从图3-9可以看出,该模型能够较高精度地预测高密度聚乙烯生产过程的乙烯单耗。
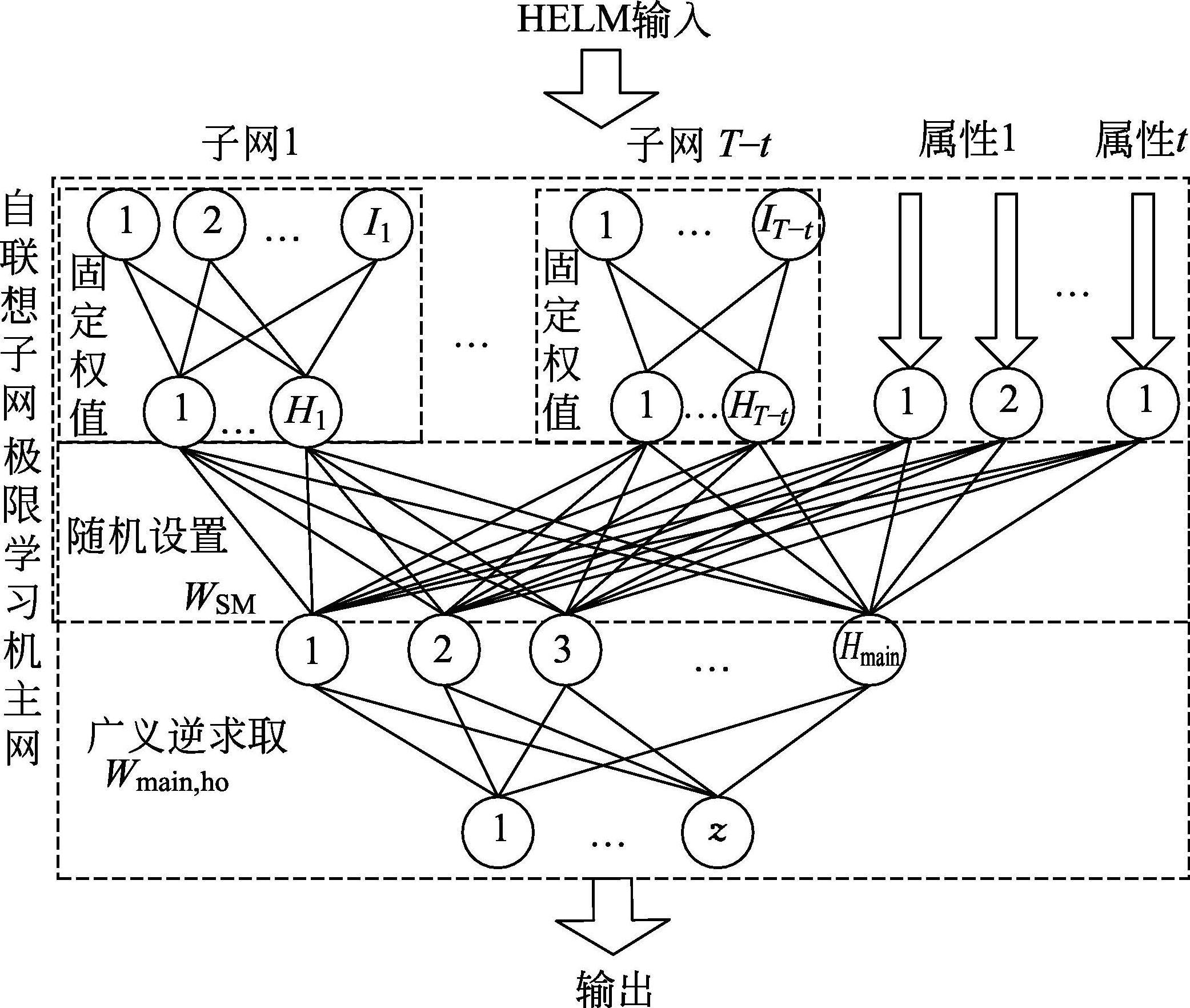
图3-8 具有抗干扰功能的递阶极限学习机网络模型
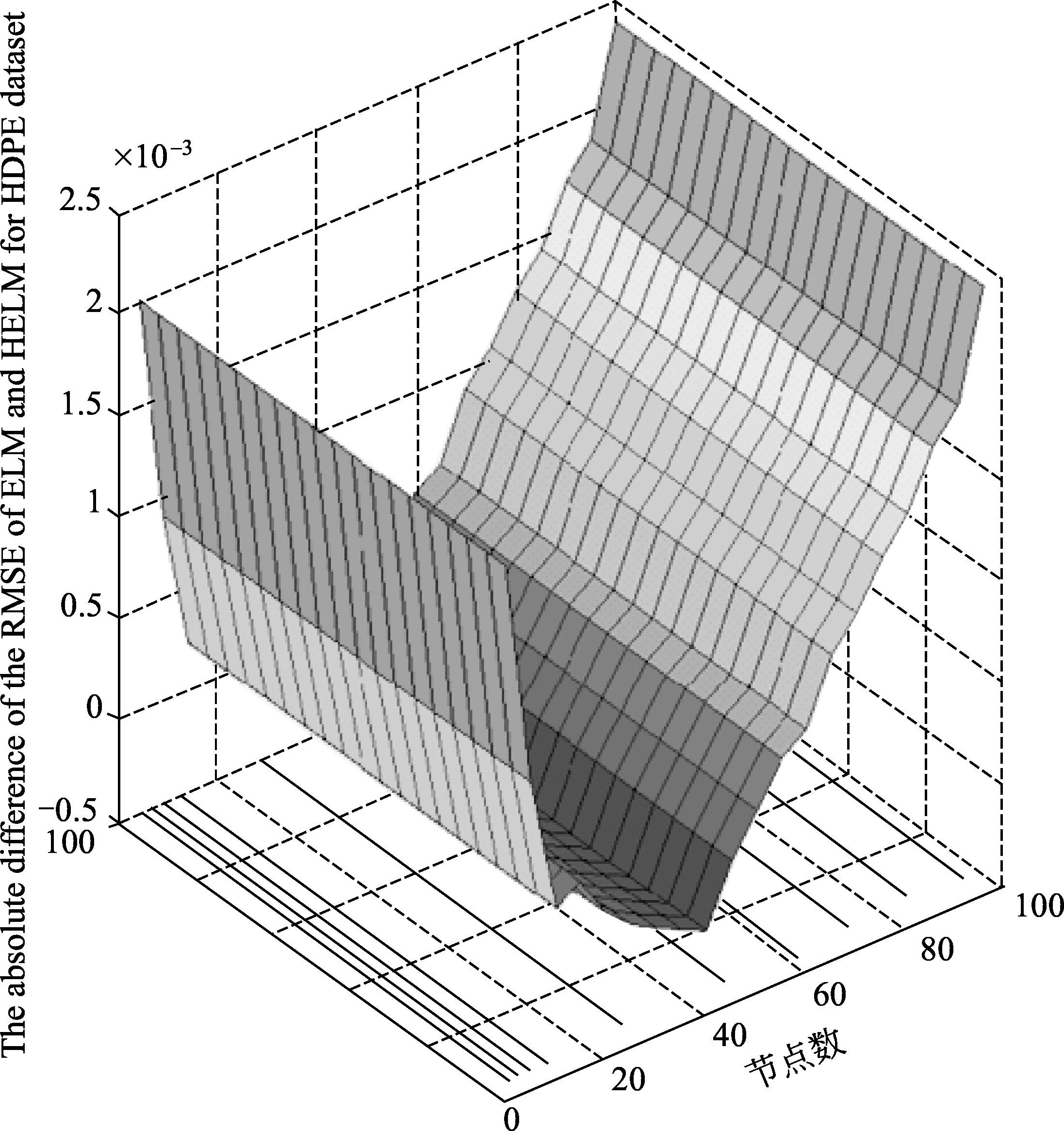
图3-9 不同隐含层节点下网络的预测精度
大规模复杂过程监控变量较多,变量之间存在过程连接性信息和因果信息,触一发而动全身,易导致冗余报警甚至报警泛滥。因此,在实现有效监控报警的前提下,需挖掘过程变量之间的关联信息,建立过程因果拓扑结构,如图3-10所示。该模型可以针对复杂过程进行微观和宏观上的层次划分,清晰地展示出过程的关联性和因果信息,有利于后续的故障诊断和报警溯源 [ 55 ] 。
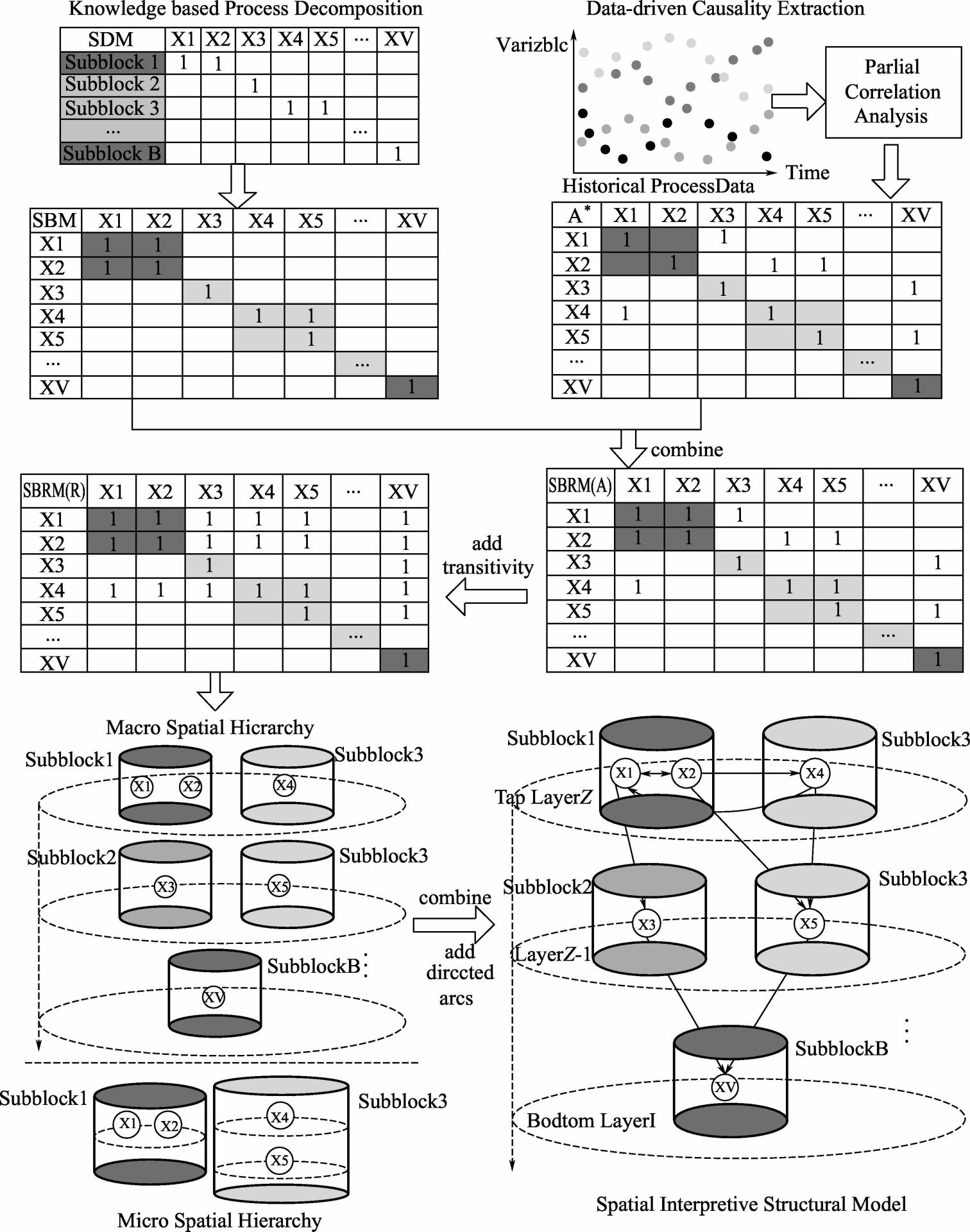
图3-10 空间解释结构模型
强集成、多维度、非线性等复杂特征使得单一、集中式方法无法实现合理、有效、安全的报警监控。因此,需采用高效、鲁棒的监控方法对复杂过程进行分布式监控,如图3-11所示。依据上述得到的空间解释结构模型,将每个子单元和它的邻接子结点看作一个诊断模块,对于每一个诊断模块,利用极限学习机算法建立监控模型,从而实现分布式监控 [ 56 ] 。
图3-11 分布式监控策略
由于每个诊断模块都具有先验不精确性和不确定性,导致多个模块输出结果存在不一致性。考虑以上问题,有学者提出一种BPA-IAHP多模块数据融合算法(图3-12),从而消除诊断过程的先验不精确性和不确定性,使得报警根源诊断结果更可靠 [ 57 ] 。
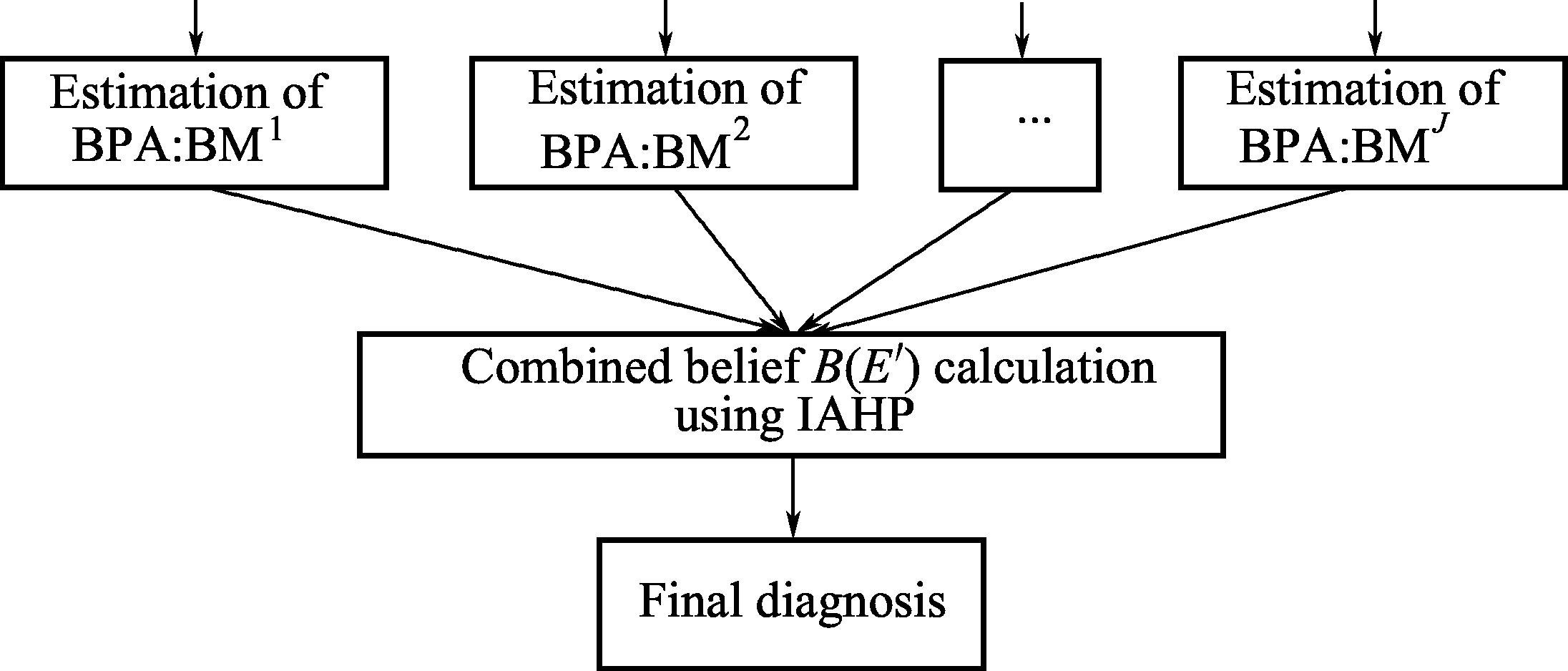
图3-12 基于BPA-IAHP的数据融合策略
在生产企业应急救援演练方面,北京化工大学研发了基于模块化工作流框架的企业安全应急救援平台,针对系统的可定制性、可扩展性研究并设计基于OSGi技术的模块化工作流模型,在此基础上构建基于OSGi-jBPM技术的模块化工作流框架,研发了基于VRGIS的三维视景平台,运用虚拟现实技术三维真实模拟石化厂区布局、重点危险源等全部流程和细节,研究虚拟现实系统中涉及的渲染优化、物理模拟、动态纹理等技术,提供二维平面地图系统、三维虚拟现实场景和后台管理系统,并采用地理信息系统技术同步展示虚拟现实平台,实现和虚拟现实平台的交互,根据数据分析人员运动的态势以及最优救援逃生路径 [ 58 ] 。另外,研发了基于预案和的演练流程实时推理机制,将应急预案和文字化预案可视化,编写成为计算机可以识别并运行的脚本,提出NPC(non-player control)组态化推理机制、基于EFSM(extended finite state machine)的组态化真人推理机制以及多分枝应急救援演练推理机制,使三维场景按照预案脚本进行应急演练救援的推演,实现对三维场景中的人物、设备进行各种操作 [ 59 ] 。再将种类繁杂、型号各异的终端机器组织在一起,构建一个完整的联机仿真支撑平台,提供统一的网络平台接口,由平台统一进行资源分配、场景管理、实体管理、流程管理。同时,实时同步各个终端的状态,以确保所有的主机都共享一个相同的虚拟场景,同时进行演练过程的参数监控、流程监控等数据方面的获取与处理,在局域网内部实现多台机器联机进行应急救援演练仿真,实现人机随意混合应急演练,对应急演练过程进行整体和个体的考核与评价。