
下载掌阅APP,畅读海量书库
立即打开




强化学习是机器学习的一个重要分支,它试图解决决策优化的问题。所谓决策优化,是指面对特定状态(State,S),采取什么行动方案(Action,A),才能使收益最大(Reward,R)。很多问题都与决策优化有关,比如下棋、投资、课程安排、驾车,动作模仿等。
AlphaGo的核心算法,就是强化学习。AlphaGo不仅稳操胜券地战胜了当今世界所有人类高手,而且甚至不需要学习人类棋手的棋谱,完全靠自己摸索,就在短短几天内,发现并超越了一千多年来人类积累的全部围棋战略战术。
最简单的强化学习的数学模型,是马尔科夫决策过程(Markov Decision Process,MDP)。之所以说MDP是一个简单的模型,是因为它对问题做了很多限制。
1.面对的状态s t ,数量是有限的。
2.采取的行动方案a t ,数量也是有限的。
3.对应于特定状态s t ,当下的收益r t 是明确的。
4.在某一个时刻t,采取了行动方案a
t
,状态从当前的s
t
转换成下一个状态s
t+1
。下一个状态有多种可能,记为
 ,i=1...n。
,i=1...n。
换句话说,面对局面 s
t
,采取行动 a
t
,下一个状态是
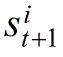 ,不是确定的,而是概率的,状态转换概率,记为
,不是确定的,而是概率的,状态转换概率,记为
 。但是状态转换只依赖于当前状态s
t
,而与先前的状态s
t-1
,s
t-2
...无关。
。但是状态转换只依赖于当前状态s
t
,而与先前的状态s
t-1
,s
t-2
...无关。
解决马尔科夫决策过程问题的常用的算法,是动态规划(Dynamic Programming)。
对马尔科夫决策过程的各项限制,不断放松,研究相应的算法,是强化学习的目标。例如对状态s t 放松限制:
1.假如状态 s t 的数量,虽然有限,但是数量巨大,如何降低动态规划算法的计算成本;
2.假如状态s t 的数量是无限的,现有动态规划算法失效,如何改进算法;
3.假如状态 s t 的数量不仅是无限的,而且取值不是离散的,而是连续的,如何改进算法;
4.假如状态s t 不能被完全观察到,只能被部分观察到,剩余部分被遮挡或缺失,如何改进算法;
5.假如状态 s t 完全不能被观察到,只能通过其他现象猜测潜在的状态,如何改进算法。
放松限制,就是提升问题难度。在很多情况下,强化学习的目标,不是寻找绝对的最优解,而是寻找相对满意的次优解。
强化学习的演进,有两个轴线:一个是不断挑战更难的问题,不断从次优解向最优解逼近;另一个是在不严重影响算法精度的前提下,不断降低算法的计算成本。
此书的叙述线索非常清晰,从最简单的解决马尔科夫决策过程的动态规划算法,一路讲解到最前沿的深度强化学习算法(Deep Q Network,DQN),单刀直入,全无枝枝蔓蔓之感。不仅解释数学原理,而且注重编程实践。同时,行文深入浅出,通俗易懂。
将本书与Richard Sutton和Andrew Barto合著的经典著作Reinforcement Learning:An Introduction,Second Edition相比,Sutton和Barto在内容上更注重全面,覆盖了强化学习各个分支的研究成果;而本书更强调实用,是值得精读的教材。
邓侃
PhD of Robotics Institute,School of Computer Science,Carnegie Mellon University,前Oracle 主任架构师、前百度网页搜索部高级总监、北京大数医达科技有限公司创始人