
下载掌阅APP,畅读海量书库
立即打开




随着大数据技术的普及,它已经被广泛应用于互联网、电信、金融、工业制造等诸多行业。据相关报告统计,大数据人才需求呈井喷态势,越来越多的程序员开始学习大数据技术,这使得它已经成为程序员所需的基本技能。
为了满足大数据人才市场需求,越来越多的大数据技术书籍不断面世,包括《Hadoop权威指南》《Hadoop实战》等。尽管如此,面向初、中级学者,能够系统化、体系化介绍大数据技术的基础书籍并不多见。笔者曾接触过大量大数据初学者,他们一直渴望能有一本简单且易于理解的教科书式的大数据书籍出现。为了满足这些读者的需求,笔者根据自己多年的数据项目和培训经验,继《Hadoop技术内幕》书籍之后,于两年前开始尝试编写一本浅显易读的大数据基础书籍。
相比于现有的大数据基础书籍,本书具有三大特色:①系统性:深度剖析大数据技术体系的六层架构;②技术性:详尽介绍Hadoop和Spark等主流大数据技术;③实用性:理论与实践相结合,探讨常见的大数据问题。本书尝试以“数据生命周期”为线索,按照分层结构逐步介绍大数据技术体系,涉及数据收集、数据存储、资源管理和服务协调、计算引擎及数据分析五层技术架构,由点及面,最终通过综合案例将这些技术串接在一起。
(1)大数据应用开发人员
本书用了相当大的篇幅介绍各个大数据系统的适用场景和使用方式,能够很好地帮助大数据应用开发工程师设计出满足要求的程序。
(2)大数据讲师和学员
本书按照大数据五层架构,即数据收集→数据存储→资源管理与服务协调→计算引擎→数据分析,完整介绍了整个大数据技术体系,非常易于理解,此外,每节包含大量代码示例和思考题目,非常适合大数据教学。
(3)大数据运维工程师
对于一名合格的大数据运维工程师而言,适当地了解大数据系统的应用场景、设计原理和架构是十分有帮助的,这不仅有助于我们更快地排除各种可能的大数据系统故障,也能够让运维人员与研发人员更有效地进行沟通。本书可以有效地帮助运维工程师全面理解当下主流的大数据技术体系。
(4)开源软件爱好者
开源大数据系统(比如Hadoop和Spark)是开源软件中的佼佼者,它们在实现的过程中吸收了大量开源领域的优秀思想,同时也有很多值得学习的创新。通过阅读本书,这部分读者不仅能领略到开源软件的优秀思想,还可以学习如何构建一套完整的技术生态。
本书以数据在大数据系统中的生命周期为线索,介绍以Hadoop与Spark为主的开源大数据技术栈。本书内容组织方式如下。
大数据体系的逻辑也是本书的逻辑,故这里给出大数据体系逻辑图。
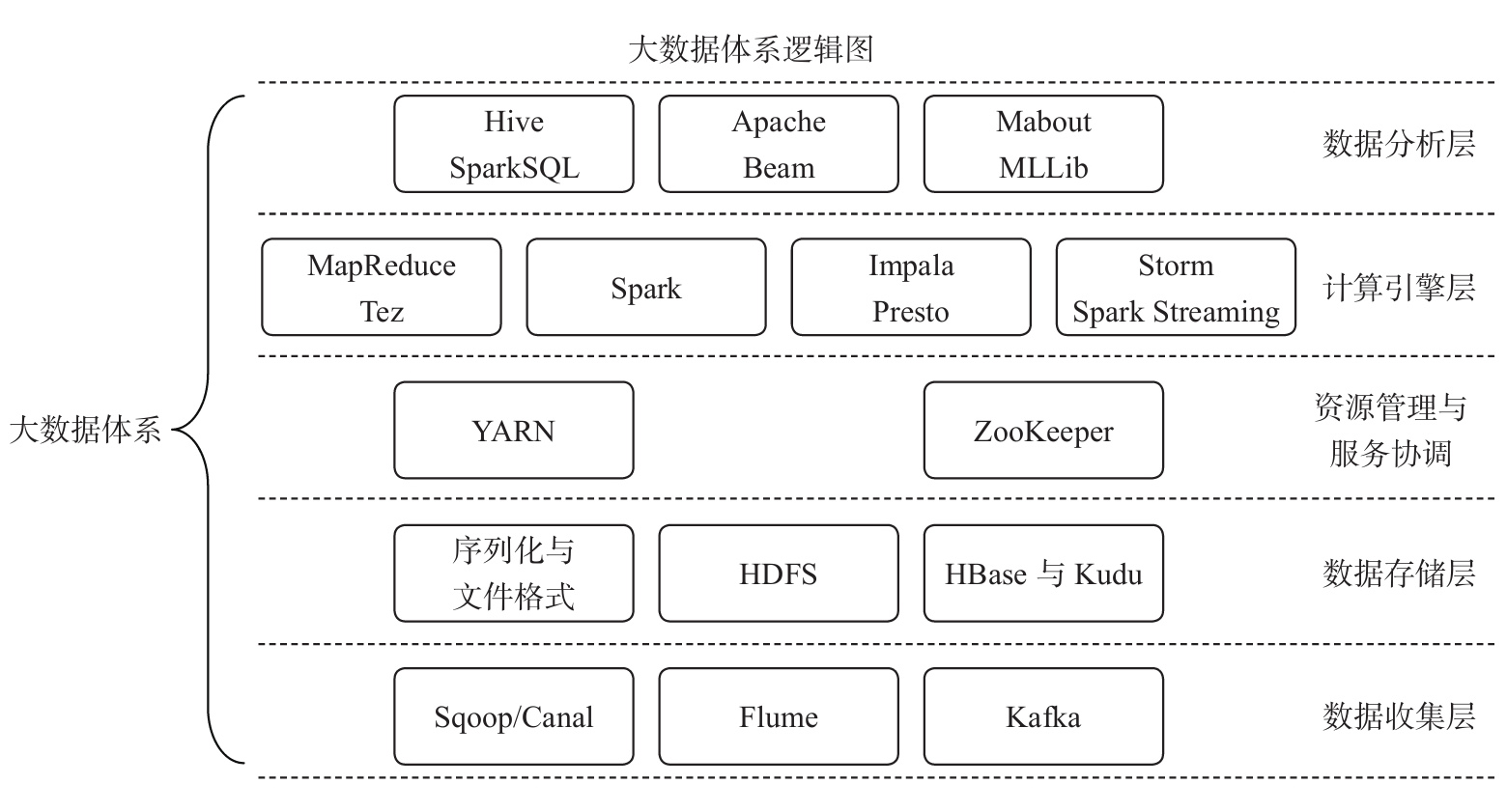
由于笔者的水平有限,编写时间仓促,书中难免会出现一些错误或者不准确的地方,恳请读者批评指正。为此,笔者特意创建了一个在线支持与应急方案的站点 http://hadoop123.com 和微信公众号hadoop-123。你可以将书中的错误发布在Bug勘误表页面。如果你遇到任何问题,也可以访问Q&A页面,我将尽量在线上为你提供最满意的解答。如果你有更多宝贵的意见,也欢迎发送邮件至邮箱dongxicheng@yahoo.com,期待能够得到你们的真挚反馈。
本书各节的源代码实例可从网站 http://hadoop123.com 或微信公众号hadoop-123中获取。
感谢我的导师廖华明副研究员,是她引我进入大数据世界。
感谢机械工业出版社华章公司的孙海亮编辑对本书的校订,他的鼓励和帮助使我顺利完成了本书的编写工作。
最后感谢我的父母,感谢他们的养育之恩,感谢兄长的鼓励和支持,感谢他们时时刻刻给我以信心和力量!
谨以此书献给我最亲爱的家人,以及众多热爱大数据技术的朋友们!
董西成