
下载掌阅APP,畅读海量书库
立即打开




JavaScript属于动态语言,一直没有固定的开发工具,难于调试。当脚本出错时,浏览器通常会给出类似于object expected(缺少对象)这样的消息,没有上下文信息,让人摸不着头脑。ECMAScript第3版致力于解决这个问题,引入try-catch和throw语句以及一些错误类型,适当处理错误。同时,现在主流浏览器中也出现了一些JavaScript调试程序和工具,当有了语言特性和工具支持之后,用户就能够轻松实现错误处理,并且能够找到错误的根源。
ECMA-262第3版引入了try-catch语句,作为JavaScript处理异常的一种标准方式。基本语法如下:

上面语法与Java中的try-catch语句是完全相同的。
【示例1】 用户应把所有可能会抛出错误的代码都放在try语句块中,而把那些用于错误处理的代码放在catch块中。

如果try块中的任何代码发生了错误,就会立即退出代码执行过程,然后执行catch块。此时,catch块会接收到一个包含错误信息的对象。与在其他语言中不同的是,即使不使用这个错误对象,也要给它起个名字。
【示例2】 错误对象中包含的实际信息会因浏览器而异,但都有一个保存着错误消息的message属性。ECMA-262还规定了一个保存错误类型的name属性,当前所有浏览器都支持这个属性(Opera 9之前的版本不支持这个属性)。因此,在发生错误时,就可以像下面这样实事求是地显示浏览器给出的消息。

这个例子在向用户显示错误消息时,使用了错误对象的message属性。
提示: message属性是唯一一个能够保证所有浏览器都支持的属性。除此之外,IE、Firefox、Safari、Chrome以及Opera都为事件对象添加了其他相关信息。
例如,IE添加了与message属性完全相同的description属性,还添加了保存着内部错误数量的number属性;Firefox添加了fileName、lineNumber和stack(包含栈跟踪信息)属性;Safari添加了line(表示行号)、sourceId(表示内部错误代码)和sourceURL属性。当然,在跨浏览器编程时,建议只使用message属性。
【拓展】 当try-catch语句中发生错误时,浏览器会认为错误已经被处理了,因而不会报告错误。对于那些不要求用户懂技术,也不需要用户理解错误的Web应用程序。这应该说是个理想的结果。不过try-catch能够让我们实现自己的错误处理机制。
使用try-catch最适合处理那些无法控制的错误。假设在使用一个大型JavaScript库中的函数,该函数可能会有意无意地抛出一些错误。由于我们不能修改这个库的源代码,所以大可将对该函数的调用放在try-catch语句当中,万一有什么错误发生,也好恰当地处理它们。
在明明白白地知道自己的代码会发生错误时,再使用try-catch语句就不太合适了。例如,如果传递给函数的参数是字符串而非数值,就会造成函数出错,那么就应该先检查参数的类型,然后再决定如何去做。在这种情况下,不使用try-catch语句。
finally子句在try-catch语句中是可选的,但finally子句已经使用,其代码无论如何都会执行。无论try或catch语句块中包含什么代码—甚至return语句,都不会阻止finally子句的执行。
【示例】 只要代码中包含finally子句,那么无论try还是catch语句块中的return语句都将被忽略。因此,在使用finally子句之前,一定要非常清楚想让代码怎么样。看下面这个函数。

这个函数在try-catch语句的每一部分都放了一条return语句。表面上看,调用这个函数会返回2,因为返回2的return语句位于try语句块中,而执行该语句又不会出错。可是,由于最后还有一个finally子句,结果就会导致该return语句被忽略,也就是说,调用这个函数只能返回0。如果把finally子句去掉,这个函数将返回2。
提示: 如果提供finally子句,则catch子句就成了可选的,IE 7及更早版本中有一个Bug:除非有catch子句,否则finally中的代码永远不会执行。如果考虑兼容IE早期版本,应提供一个catch子句,哪怕里面什么都不写,IE 8修复了这个Bug。
执行代码期间可能会发生的错误有多种类型。每种错误都有对应的错误类型,而当错误发生时,就会抛出相应类型的错误对象。ECMA-262定义了下列7种错误类型:
☑ Error
☑ EvalError
☑ RangeError
☑ ReferenceError
☑ SyntaxError
☑ TypeError
☑ URIError
其中Error是基类型,其他错误类型都继承自该类型。因此,所有错误类型共享了一组相同的属性,错误对象中的方法全是默认的对象方法。Error类型的错误很少见,如果有也是浏览器抛出的,这个基类型的主要目的是供开发人员抛出自定义错误。
EvalError类型的错误会在使用eval()函数而发生异常时被抛出。
【示例1】 如果没有把eval()当成函数调用,就会抛出该类型错误。

在实践中,浏览器不一定会在应该抛出错误时就抛出EvalError。例如,Firefox 4+和IE 8对第一种情况会抛出TypeError,而第二种情况会成功执行,不发生错误。因此,在实际开发中极少会这样使用eval(),所以遇到这种错误类型的可能性极小。
RangeError类型的错误会在数值超出相应范围时触发。JavaScript中经常会出现这种范围错误。
【示例2】 在定义数组时,如果指定了数组不支持的项数,如-20或Number.MAX_VALUE,就会触发这种错误。
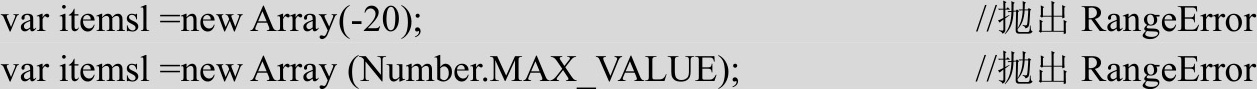
在找不到对象的情况下,会发生ReferenceError。
【示例3】 在访问不存在的变量时,就会发生这种错误。
var obj=x; //在x并未声明的情况下抛出ReferenceErro
SyntaxError表示语法类型错误,当把语法错误的JavaScript字符串传入eval()函数时,就会导致此类错误。例如:
eval("a ++ b") //抛出SyntaxError
如果语法错误的代码出现在eval()函数之外,则不太可能使用SyntaxError,因为此时的语法错误会导致JavaScript代码立即停止执行。
TypeError类型在JavaScript中会经常用到,在变量中保存着意外的类型时,或者在访问不存在的方法时,都会导致这种错误。错误的原因虽然多种多样,但归根结底还是由于在执行特定于类型的操作时,变量的类型并不符合要求所致。
【示例4】 下面来看几个例子。
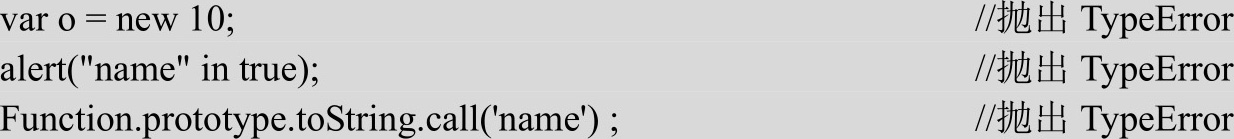
最常发生类型错误的情况,就是传递给函数的参数事先未经检查,结果传入类型与预期类型不相符。
在使用encodeURL()或decodeURL()时,如果URL格式不正确,就会导致URLError错误。这种错误也很少见,因为这两个函数的容错性非常高。
利用不同的错误类型,可以获悉更多有关异常的信息,从而有助于对错误作出恰当的处理。
【应用】 如果想知道错误的类型,可以按下面这样在try-catch语句的catch语句中使用instanceof操作符。

在跨浏览器编程中,检查错误类型是确定处理方式的最简便途径,包含在message属性中的错误消息会因浏览器而异。
与try-catch语句相配的还有一个throw操作符,用于随时抛出自定义错误。抛出错误时,必须要给throw操作符指定一个值,这个值是什么类型没有要求。
【示例1】 下列代码都是有效的。
throw 1;
throw"hi"
throw true;
throw {name:"js"};
在遇到throw操作符时,代码会立即停止执行。仅当有try-catch语句捕获到被抛出的值时,代码才会继续执行。
通过使用某种内置错误类型,可以更真实地模拟浏览器错误。每种错误类型的构造函数接收一个参数,即实际的错误消息。
【示例2】 下面是一个例子。
throw new Error("抛出错误");
这行代码抛出了一个通用错误,带有一条自定义错误消息。浏览器会像处理自己生成的错误一样,来处理这行代码抛出的错误。即浏览器会以常规方式报告这一错误,并且会显示这里的自定义错误消息。
【示例3】 下面代码使用其他错误类型,也可以模拟出类似的浏览器错误。
throw new SyntaxError("SyntaxError");
throw new TypeError("TypeError");
throw new RangeError("RangeError");
throw new EvalError("EvalError");
throw new URIError("URIError");
throw new ReferenceError("ReferenceError");
在创建定义错误消息时,最常用的错误类型是Error、RangeError、ReferenceError和TypeError。
【应用】 利用原型链还可以通过继承Error来创建自定义错误类型。此时,需要为新创建的错误类型指定name和message属性。

浏览器对待继承自Error的自定义错误类型,就像对待其他错误类型一样。如果要捕获自己抛出的错误并且把它与浏览器错误区别对待,创建自定义错误是很有用的。
提示: IE只有在抛出Error对象时才会显示自定义错误消息。对于其他类型,它都无一例外地显示exception thrown and not caught(抛出了异常,且未被捕获)。
针对函数执行失败给出更多信息,抛出自定义错误是一种很方便的方式。应该在出现某种特定的已知错误条件,导致函数无法正常执行时抛出错误。
【示例1】 下面函数会在参数不是数组的情况下失败。

如果执行这个函数时传给它一个字符串参数,那么调用sort()就会失败。对此,不同浏览器会给出不同的错误消息,但都不是特别明确。
【示例2】 在处理上面示例中的这个函数时,通过调试处理这些错误消息没有什么困难。但是,在面对包含数千行JavaScript代码的复杂的Web应用程序时,要想查找错误来源就没有那么容易了。在这种情况下,带有适当信息的自定义错误能够显著提升代码的可维护性。

重写函数后,如果values参数不是数组,就会抛出一个错误。错误消息中包含了函数的名称,以及为什么会发生错误的明确描述。如果一个复杂的Web应用程序发生了这个错误,那么查找问题的根源也就容易多了。
提示: 在开发JavaScript代码的过程中,重点关注函数和可能导致函数执行失败的因素。良好的错误处理机制应该可以确保代码中只发生自己抛出的错误。
【拓展】 何时该抛出错误,而何时该使用try-catch来捕获错误信息?
一般来说,应用程序架构的较低层次中经常会抛出错误,但这个层次并不会影响当前执行的代码,因而错误通常得不到真正的处理。如果打算编写一个要在很多应用程序中使用的JavaScript库,甚至只编写一个可能会在应用程序内部多个地方使用的辅助函数,建议用户在抛出错误时提供详尽的信息。然后,即可在应用程序中捕获并适当地处理这些错误。
在程序中,应该捕获那些确切地知道该如何处理的错误。捕获错误的目的在于避免浏览器以默认方式处理它们,而抛出错误的目的在于提供错误发生具体原因的消息。
任何没有通过try-catch处理的错误都会触发window对象的error事件。这个事件是浏览器最早支持的事件之一,IE、Firefox和Chrome为保持向后兼容,并没有对这个事件做任何修改,Opera和Safari不支持error事件。
在任何Web浏览器中,onerror事件处理程序都不会创建event对象,但它可以接收3个参数:错误消息、错误所在的URL和行号。多数情况下,只有错误消息有用,因为URL只是给出了文档的位置,而行号所指的代码行既可能出自嵌入的JavaScript代码,也可能出自外部的文件。
要指定onerror事件处理程序,必须使用如下所示的DOM 0级技术,它没有遵循DOM 2级事件的标准格式。

只要发生错误,无论是不是浏览器生成的,都会触发error事件,并执行这个事件处理程序。然后,浏览器默认的机制发挥作用,像往常一样显示出错误消息。
【示例1】 通过下面方法在事件处理程序中返回false,可以阻止浏览器报告错误的默认行为。

通过返回false,这个函数实际上就充当了整个文档中的try-catch语句,可以捕获所有无代码处理的运行时错误。这个事件处理程序是避免浏览器报告错误的最后一道防线,理想情况下,只要可能就不应该使用它。只要能够适当地使用try-catch语句,就不会有错误交给浏览器,也就不会触发error事件。
提示: 不同浏览器在使用error事件处理错误时的方式有明显不同。在IE中,即使发生error事件,代码仍然会正常执行,所有变量和数据都将得到保留,因此能在onerror事件处理程序中访问它们。但在Firefox中,常规代码会停止执行,事件发生之前的所有变量和数据都将被销毁,因此几乎就无法判断错误了。
【拓展】 图像也支持error事件。只要图像的src特性中的URL不能返回可以被识别的图像格式,就会触发error事件。此时的error事件遵循DOM格式,会返回一个以图像为目标的event对象。

在这个例子中,当加载图像失败时就会显示一个警告框。注意,发生error事件时,图像下载过程已经结束,也就是说不能再重新下载了。
错误处理的核心是首先要知道代码里会发生什么错误。由于JavaScript是松散类型的,而且也不会验证函数的参数,因此错误只会在代码运行期间出现。一般来说,需要关注3种错误:
☑ 类型转换错误。
☑ 数据类型错误。
☑ 通信错误。
以上错误分别会在特定的模式下或者没有对值进行足够的检查的情况下发生。
任何错误处理策略中的重点就是确定错误是否致命。对于非致命错误,可以根据下列一个或多个条件来确定:
☑ 不影响用户的主要任务。
☑ 只影响页面的一部分。
☑ 可以恢复。
☑ 重复相同操作可以消除错误。
本质上,非致命错误并不是需要关注的问题。没有必要因为发生了非致命错误而对用户给出提示,可以把页面中受到影响的区域替换掉,例如替换成说明相应功能无法使用的消息。但是,如果因此打断用户,那确实没有必要。
致命错误,可以通过以下一个或多个条件来确定:
☑ 应用程序根本无法继续运行。
☑ 错误明显影响到了用户的主要操作。
☑ 会导致其他连带错误。
要想采取适当的措施,必须要知道JavaScript在什么情况下会发生致命错误。在发生致命错误时,应该立即给用户发送一条消息,告诉无法再继续执行了。假如必须刷新页面才能让应用程序正常运行,就必须通知用户,同时给用户提供一个点击即可刷新页面的按钮。
区分非致命错误和致命错误的主要依据,就是看它们对用户的影响。设计良好的代码,可以做到应用程序某一部分发生错误不会影响另一个毫不相干的部分。例如,My Yahoo!(https://my.yahoo.com/)的个性化主页包含了很多互不依赖的模块。如果每个模块都需要通过JavaScript调用来初始化,那么用户可能会看到类似下面这样的代码:

表面上看,这些代码没什么问题,依次对每个模块调用init()方法。问题在于,任何模块的init()方法如果出错,都会导致数组中后续的所有模块无法再进行初始化。从逻辑上说,这样编写代码没有什么意义。毕竟每个模块相互之间没有依赖关系,各自实现不同功能。可能会导致致命错误的原因是代码的结构。不过使用如下代码就可以把所有模块的错误变成非致命的:

通过在for循环中添加try-catch语句,任何模块初始化时出错,都不会影响其他模块的初始化。在以上重写的代码中,如果有错误发生,相应的错误将会得到独立的处理,并不会影响到用户的体验。
在开发Web应用程序过程中,应该集中保存错误日志,以便查找重要错误的原因。例如,数据库和服务器错误都会定期写入日志,而且会按照常用API进行分类。在复杂的Web应用程序中,用户也应该把JavaScript错误回写到服务器,并标明它们来自前端。把前后端的错误集中起来,能够极大地方便对数据的分析。
要建立这样一种JavaScript错误记录系统,首先需要在服务器上创建一个页面(或者一个服务器入口点),用于处理错误数据。这个页面的作用无非就是从查询字符串中取得数据,然后再将数据写入错误日志中。这个页面可能会使用如下所示的函数:

在上面代码中,logError()函数接收两个参数:表示严重程度的数值或字符串,以及错误消息。其中,使用了Image对象来发送请求,这样做非常灵活,主要表现在如下几方面。
☑ 所有浏览器都支持Image对象,包括那些不支持XMLHttpRequest对象的浏览器。
☑ 可以避免跨域限制。通常都是一台服务器要负责处理多台服务器的错误,而这种情况下使用XMLHttpRequest是不行的。
☑ 在记录错误的过程中出现问题的概率比较低。大多数Ajax通信都是由JavaScript库提供的包装函数来处理的,如果库代码本身有问题,而依赖该库记录错误,可想而知,错误消息是不可能得到记录的。
只要是使用try-catch语句,就应该把相应错误记录到日志中。

在上面代码中,一旦模块初始化失败,就会调用logError()函数,其中第一个参数表示错误的性质,第二个参数是真正的JavaScript错误消息。记录到服务器中的错误消息应该尽可能多地带有上下文信息,以便鉴别导致错误的真正原因。