
下载掌阅APP,畅读海量书库
立即打开



北京大学 胡壮麟 〔*〕
在语言学研究的种种对立观点中,有一组对立牵涉到对语言特性的看法,或者把语言特性看做是判定性的规则,或者把它看做是有意义的趋势(Munro 2004)。前者关心的是从逻辑或规则指导衍生一个可被认可的合乎语法的句子;后者关心的是一种语言的词汇语法有多大概率被使用者选用。这就表现为“可行性”(possibility)与“概率”或“盖然率”(probability)之争。
持判断性规则论者以乔姆斯基为代表,他把索绪尔的语言系统(langue)和言语(parole)重新解释为语言能力和语言行为,并认为语言学家应当研究诸如语法性等逻辑和理论的概念,而不是对语言行为进行描写性研究;其次,一个语言的语法性主要由说本族语者认可即可,频率对语言研究无多大帮助。这样,乔姆斯基对语言学研究中的概率或盖然率模式持否定态度。早在1958年,他就争辩说,语料不足以描写语法规则,其理由为“有些句子明显地是不会出现的;有些句子一看就是错误的;还有一些句子不很文雅。”(Leech 1991: 8; Halliday 1991b, 1992; Porter and O'Donnel 2001: 14)。
与上述观点相反,德·波格兰德(De Beaugrande 1991)统计出乔姆斯基在《句法结构》和《句法理论要略》两书中分别分析了总共28个和24个人造句子,这种方法是难以说明问题和令人信服的。持语言是有意义趋势的功能语言学家强烈地提出语法(如系统、制约因素、成分和从属关系)是概率的,把语言的方方面面描写成一个有等级的、模糊的连续体。在这个连续空间中,功能范畴呈现为有意义的趋势。尽管乔姆斯基举了这样的例子,I live in New York比I live in Dayton Ohio出现频率高,但这个差异对语言学的描写理论无多大意义。功能语言学家认为他的举例不是来自真实语篇,它无法如实概括语言的实质(Halliday 1991b)。
自1930年以来,布拉格学派的语言学家一直从事某些语法过程频率的定量研究,如言语不同部分出现的相对频率,句子中信息的落点和分布,音节类型和结构的统计分布。
在美国,语文学家齐夫(Zipf 1935)关心语言的定量分析。他研究词语在语篇和语篇长度之间的关系,词语及其古代用法之间的关系,一个词项在词汇频率表的排名,该词项或标记出现的次数等。著名的Zipf法则便是说明一个词在语篇中使用频率和它在词频表的排名,公式为“f. r=c”,其中f指频率,r指排名,c为所统计的总词数(Kennedy 1998: 10)。韩礼德曾评论说这个词语频率作为语言的一个特性是可以接受的,如英语的go比walk出现频率高,比stroll更高。因此,没有必要将语法的定量范式拒之门外(Halliday 1991b: 31)。
就英国传统来说,马林诺夫斯基对数量统计和概率最早作过间接陈述。他指出,将语言看做是说话人脑子中的思想转移到听话人的脑子中的一种方法是错误的。我们需要将“意义按照经验和情境界说”。经验和情境因人而异,展现在我们前面的是各色各样的,研究者必然涉及数量统计和概率(Malinowsky 1935: 9)。
弗斯非常强调意义的语境理论,指出不能研究孤立的句子。他认为真实的语言在作为语篇的语言中出现。他说,“强调记录下来的真实语篇”应当是语言学家主要关注的内容(Firth 1957: 5, 37)。
韩礼德从1950年代初便用简单的概率统计研究汉语,他对汉语语法系统中的范畴赋予频率。从这些频率统计和概率中,他希望发现“不同系统之间的关联程度。”他所研究的一个项目为否定疑问句,这里包括归一度(负与正)和陈述句(直陈和疑问)两个系统的结合。由此韩礼德发展了“系统分类”方法。他注意到当他所研究的语法系统使用概率描写时,系统属于以下两者之一:(1)两个范畴在系统中有等同的值(equiprobable, 0.5/0.5),因而无标记性之分,即没有标记项和无标记项的区别;(2)如果有一个无标记项具有0.9的概率,另一个标记项为0.1概率,则是倾斜的。这两个系统分别叫做等同系统和倾斜系统。这受到语言的符号功能的支持,如果所有的系统都是等同的,语言就没有冗余,任何干扰(如闹音)会阻碍有效的交际。反之,如果系统完全分配不一,那么“符号实际上是不可学习的”(Porter and O'Donnel 2001: 15, 17)。正如韩礼德本人所说,“语言系统天生是盖然率的,语篇中的频率是概率在语法中的实例化”(Halliday 1991b: 31)。这就是说,语法学应当是聚合的,定量分析能说明选择时的概率。语言定量分析的基础是语篇的频率使语言系统中的概率实例化(Dixit 2005)。
在本节中,我们进一步讨论系统功能语言学为什么重视韩礼德的概率理论?
系统功能语言学源自以弗斯为倡导者的伦敦学派。弗斯的一个主要观点是语言学研究应当在变异和常规之间,个体和社会之间取得平衡。就他发展的语义学的“语境和社会学技术”而言,他研究社会学上有重要意义的词的分布,例如关于像work和leisure那样的词(Firth 1935: 40)。要指出的是,弗斯本人只是提出纲领性的建议,要求发展分析语料的技术,他本人还没有来得及做真正的语篇分析,因为60年前计算机技术尚未发展,还不能处理大型语料库(Stubbs 1993: 7)。
人们对弗斯的肯定是因为弗斯提出了要对人类行为做出解释的尝试,制订了社会行动的理论。认知的互动的理论能解决语言行为的某些方面。语言是个体的,有意识的,有创造性的,这只是说了一半。语言也是社会的,部分是无意识的,常规的,这决定于社会的规约,难以公开审视。有许多语言学范式(如搭配需要在词汇和语法中共选)往往是有意识的行为,但有许多无意识的结果。所有这些,研究者都需要通过在社会群体中的调查、分析和计算频率才能得到如实的描写。韩礼德(1991a: 46)曾引用Plum和Cowling在1987年的成果说明这一关系。我们先看下表。
表1 社会阶层对基本时态选择的影响
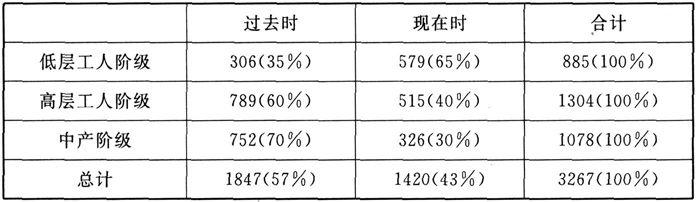
就总的概率来说,过去时和现在时比较接近(57%和43%),但社会阶层在有关语域中起决定性影响,往相反方向倾斜:中产阶级喜用过去时,低层工人阶级喜用现在时。
系统理论也始自弗斯。他把系统定义为聚合选择,把结构定义为组合关系。他的这个理论主要用在对音系的描写上。韩礼德将弗斯的理论扩展至语法和词汇上,即词汇语法也是一个聚合系统的连续体,一端为语法,另一端为词汇。
这样,系统的主要概念是语义特征之间的选择,它存在于上述的词汇语法连续体之中。在语法端含有少量的数量有限的特征选择,可成为封闭系统,而词汇端的系统有无数的子系统(如关于动作的动词),描写为开放系统。
朴特和奥唐纳尔(Porter and O'Donnel 2001: 13)曾以希腊语的体系统为例,说明要进行4次选择,在前一系统的选择成为后一选择的入列条件:(1)在体系统中对“+预期/+体”进行选择;(2)如选择“+体”,它是“+完成/+非完成”的入列条件;(3)如选择“+完成”,需要进入两个并列的系统:(a)“+未完成/静止”,(b)“+远/+非远”。假设一个网络是二元选择,对最有潜力出现的选项给以概率值。
这些概率不仅提供关于一个语言的语法特征的一般范式的信息,而且它们可用来界定这些特征的语义。对此,韩礼德(1991a: 50)引用Nesbitt和Plum 1988年的一项研究加以说明。这两位学者研究小句复合体中进行选择的相对频率,调查对象为养狗迷。其中的一个结果见表2。
表2 逻辑语义关系影响下的语法关系
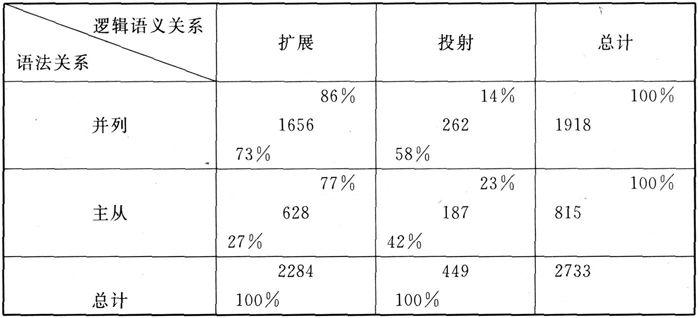
上表说明,当两个系统相交时,比例不动。但从各自维度看则有出入,当“并列x扩展”时从语法关系上为73%,从逻辑语义关系上为86%。
肯尼迪(Kennedy 1998: 8, 272)指出我们对语言的描写关心的不仅仅是词语、结构和用途在一种语言中的是否可行,更应当是它们在语言使用中出现有多大可能性。任何科学事业必然是实证性的,要有证据支持。关于语言的任何说明必须符合语言使用的证据。肯尼迪还指出,直觉的判断往往把所记录口语资料的许多结构认为是不符语法的,不管有的是涉及语言和句法上的省略,如Where you going? Wannan other one?或Good that you got here early是否符合语法,归根结蒂依赖它们出现的频率和什么是“正常”的直觉。
虽然追随乔姆斯基的语言学家长期拒绝语言的频率模式作为语言理论的重要性,仍有人自觉不自觉采用了概率理论。我最近参加一所大学的博士生论文答辩。这位年轻学者是研究形式语言学或生成语言学的,在研究汉语部分句式的形式语义分析时,他在使用了不少人造句子后,却制作了问卷调查表,把可接受程度分为“很差,较差,一般,较高,很高”共五个等级,让受试者填充。他对“有的同学每个老师都喜欢”这句话提供了如下的分析表。
表3 汉语句子“有的同学每个老师都喜欢”的可接受程度分析

来源:吴平,2005。《汉语部分句式的形式语义分析》,北京语言文化大学。
这证实了里奇(Leech 1991)的观点,概率模型实际上工作得非常好,特别是在计算语言学中有许多用途。
语言研究的实证化也表明,对语言的描写既考虑到所使用的系统,也考虑到对系统的使用;既描写语言的可行性,也考虑到使用的概率。再者,当语言按出现频率描写,这不是否定我们创造和理解独特话语的能力,不如说,这些词项或词项序列倾向于在特定语境中出现,这有助于说明交流的可行性,因为我们不是完全依靠独特词项或组合工作的(Kennedy 1998: 271)。
既然语言研究有赖于实证,这就联系到我们需要的实证不是抽象的属于语法范畴的句子,而是人们在各个语境下使用的真实语篇,以及相关的语域和语类。
语篇和语篇类型应当在语篇语料中进行对比研究。语言的杂质性是弗斯语言学家的中心假设(Firth 1935: 67—8)。不存在单纯的唯一的语言系统,广泛接受的语言变异的重要方面是在不同语篇类型之间的词汇和语法特征的不同频率。语言在语篇类型间的有规律的变化对理解是有意义的,这就是说,语篇是对期待的解释,对所省略的解释。如弗斯所说,这是一种不很典型的心理构建。在“无意识”的背景下语言的范式与我们写的听的范式同样重要(Firth 1964: 183)。
事实上,语域变异通常是按这些频率的有规则变异来定义的(Halliday 1991b: 33)。
语域不仅仅是题材的不同,还涉及对整个词汇语法的不同选择,以表述意义的细微不同。许多语域并未使用“特殊”的语法(当然个别例子有,如英语新闻的标题,使用一些在其他语域中不使用的结构)。发生变化的是在某一语域中整个选择构造的变化,可能会发生(或不发生)特定结构的组合,其选择范式与其他语域不完全相同,正如韩礼德所说的,“概率是倾斜的。”譬如说,祈使句不太可能出现于新闻报道中,但非常可能出现于菜谱中;过去式非常可能出现于叙事文中,而科学文章更有可能使用现在时态。我在这里再举一份博士论文,论文作者对法律语言进行了研究。所分析的语料是中国和英美的真实的法律文件。表4是作者对英国法案中正面情态动词使用频率的分析:
表4 英国法案中正面情态动词使用频率的分析
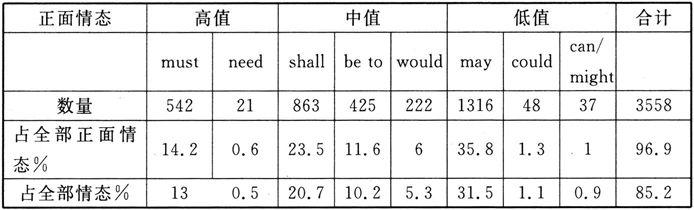
材料来源:杨敏,2005。《法律语言与权力的互动关系研究》,北京师范大学。
由此可见,概率的意义不在于它们能预示某个实例。它们预示的是总的范式。就实例来说,概率的相关性是解释。选择任何语言项的部分意义便要选择该语言项的概率;因此否定的意义不仅仅是“非肯定”,而是“非肯定,机会为九与一之比”。韩礼德又指出,所谓语域的变异,关键是概率,因此语域可定义为概率的经常出现的变异,语域是对语义和某种频率的某种结合的选择,可制订为语法系统所附带的概率,只要这些系统在语法的聚合性解释中被整合在总的系统网络中(Halliday 1991b: 32, 33)。
标记性的概念始于布拉格学派的特鲁别茨柯依(Trubetskoy)和雅各布逊(Jakobson)。布拉格学派使用标记性理论来描写二元的可区别性音位特征,后加以延伸,成为可区别性概念特征。在这个模式中,一个范畴项如果具有这个可区别特征,这个项便是有标记的。这个模式的缺陷是它描写的有些范畴不一定只有存在或不存在之分,其出现与否可能有不同程度;其次,这个模式根据的是语言结构从简单到复杂的等级,忽视了许多和特性有关的和情景依赖的特征,也忽视了其他一些因素,如该语言项如何在语言中分布。因此,大多数语言学家接受布拉格学派的标记性理论,但结合使用格林伯特(Greenbert)最先探索的“跨语言分布分析”(crosslinguistic distributional analysis)和其他学者的观点。这种标记性形式不需要单一的特征描写,但可以解释许多因素结合的连续体,包括形态学、语义学,和这里最为重要的分布。后来,吉汶(Givón)发展了象似性的概念。他相信如有充分的理由,如不同语境、社会文化、认知和交际因素,可决定一个已知语言项的分布,如“标记的范畴出现频率少的趋势,因而认知上比相应的非标记项更为突出。”(Porter and O'Donnel 2001: 15)
汤姆森(Thompson 2001)曾向韩礼德提问,“在有的语域中人们会使用的主位,在其他语域中可能是标记主位,不是让个别写作者公开选择的,即没有什么可选择的,你只能用那个主位……。”韩礼德认为这有两个步骤:第一个步骤是说在这个语域中,一般认为是标记主位或语气等范畴成了非标记选项。它们在这里不应该有问题。第二个步骤是说“我们能否对此作出解释?”人们如果回头看它的发展过程,发现是可以这么说的,但是事物变成经常性了,这样,就当代的用途来说,它不再具有某个功能了。如果可行的话,最好这样做,因为成年的语言学习者喜欢解释,他们对常见的解释是不满足的。
韩礼德曾在计算机上测试功能主义的语言生成理论。在那个名为Penman project的研究课题中,他根据81个系统的网络发展他的英语语法。每个系统对各个范畴都给以概率(Halliday 1992: 65)。这个语法后来又叫做Nigel grammar。在描写实验结果时,韩礼德写道:“如果没有概率随机发生操作,它陈述的是垃圾,如同无控制的语法生成器那样。但是按概率操作,他也产生垃圾,但看起来多少像英语,与可能的人类语言有些相似。”这说明概率多少提高了所生成语言的可接受性。
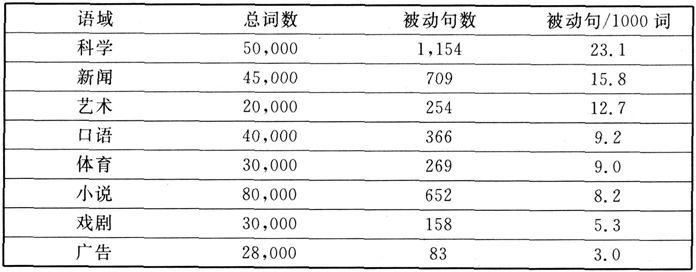
韩礼德也注意到斯伐特维克(Svartvik 1966: vii)对英语语态的研究。斯伐特维克在《论英语动词的语态》一书中确认语言频率计算的意义不是某种微不足道的东西。他本人使用语料库的资料建立英语被动语态分类的标准,即“被动语态量表”。他也计算被动小句和主动小句的比例,在不同语域之间比较被动语态的频率,因此认为有些范式不能降低为偶然性的事例。表5示意他对不同语域的分析(1966: 155)。
表5 被动句在不同语域中出现频率的分析
又如,韩礼德在讨论一个语言系统的语言结构概念的变化时指出,语言有无限的可能性,但它的使用者是有限的。词汇语法的概率模型可帮助我们解释语域的变异,这与语言的历时变异有关。当概率得到一定程度的肯定后,可看做是范畴的变化(Halliday 1991a)。
韩礼德与杰姆斯的合作研究是对当代英语语法的定量研究。他们利用语料库的资料验证语法系统基本上是两大类型:选择是概率等同的系统,从定量意义上没有非标记项;另一类是倾斜系统,有一个是非标记的(Halliday and James 1993)。在信息理论中,前者有较高的信息值(information),后者有高度的冗余值(redundancy),如韩礼德在表6中所示(Halliday 1991b: 43)。
表6 概率的信息值和冗余值
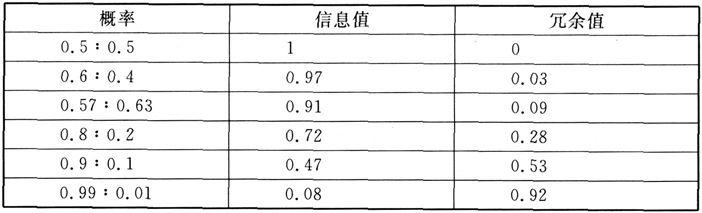
韩礼德认为,在语料库中呈现的频率范式为语言的历时变化提供了解释,这些概率表明每个实例是如何保持和干扰语言系统的。需要指出,“系统”和“实例”不是毫无关系的事物,它们具有互补性。这里只有一种现象,不是两种。我们称之为语言(系统)和我们称之为语篇(实例)是对同一现象的两种观察,从不同角度观察。举“归一度”为例,两个选项为“肯定/否定”,肯定显然比否定用得更为经常,是系统的基本特性。在分析中,有必要区分对系统中这两个选项的说明和对它们各自的概率的说明,但它们涉及一个现象,不是两个现象。他又举反意问句为例,当代英语有两个选项,“归一度换位”(polarity reversed)或“归一度不变”(polarity constant),后者为标记项,但它经历一个演变的阶段,原先唯一可能的形式是归一度换位(Halliday 1991b: 31, 33, 41)。此外,有人对构成obligation/necessity的情态和半情态的语法范畴进行历时研究,比较不同形式在若干世纪内的出现频率,以及在三个语域中的变异(如大于,等于,或小于3/100000)(Biber et a1 1998: 207)。
韩礼德认为,从儿童语言发展过程中也可观察到这一过程。儿童首先构建自己最喜欢的形式,形成他们自己的语言系统,然后开始构建不太喜欢的组合,作为额外的选择。他们构建词汇语法的根据是语篇频率,把它看做一个概率系统,可见概率方式有助于解释意义潜势的扩展(Halliday 1991b: 41)。
1960年代早期的计算机需要使用大型计算机,研究人员经常设计自己的分析软件。开始的兴趣往往是词汇,包括词数统计,这对辞书编辑有很高的指导价值。就语义标记来说,我们能使用的真正的概念是在语法系统中非标记的选择,或非标记的选项。这是一种缺省的选择。这在语言教学中非常有用。我们可以对学生说:“这是你要做的,除非你有很好的理由不这样做。”例如,你发现语言要非标记主位做什么。如果语言有主位,而且你说这是你基本的选择,但这里有如果你选其他项做主位的条件,这是谈论概率时需要的有用的概念(Thompson and Collins 2001)。不妨比较以下二例:
I went to London on Friday.
On Friday, /The following day/etc. I went to London.
说话人或写作者如果采用后一句式,说明他根据时间序列安排特定框架,因而把时间短语突出在前。这说明在描写系统中可行的东西外,系统的描写不同方法的分布,对语言教学肯定有意义,对理解心理语言学过程有价值(Kennedy 1998: 276, 290)。
肯尼迪还举过这样的例子,对更常见的不规则动词的词汇表按级排列,如:be, have, do, say, make, go, take, come, see, know, get, give, find, think, tell, become, show, leave, feel, put, …等.在这个背景下,英语教师会毫不惊奇地发现在Brown词表中4,240个规则动词类型,在LOB只占43.3%的动词标记。后者表明学习常见不规则动词对时间的投入是花得来的,而Grabowski和Mindt提供的级序表,却要求许多国家的学习者学习,尽管这些学习者很少需要使用其中的许多形式(Kennedy 1998: 284)。
可以认为,像这样的动词频率的统计反映了它们特定的语篇来源,而英语口语变体的语料库更为非正式的语料,必然会导致不同的相对的频率。
计算语言学的研究者发现,计算机语料库方便了对句子或搭配的研究,如在different from, different to, different than三个搭配中,哪一个用得更多?也有的感兴趣研究科技体、新闻体、文学体或虚构体的特征(Kennedy 1998: 11)。
我本人在分析狄伦·托玛斯“不要温顺地走进那美好的夜晚”一诗的语音模式时,曾假设该诗的语音符号对语义有提示作用,尽管它是辅助的,本身不能创造意义。该诗的主题为死与生,在诗中分别以night和day二词象征,在音系层上分别表现为/nait/和/dei/,在语音层上则为/ait/和/ei/。出现的频率表明/ait/这一正韵在十九行诗中出现了13次(如包括标题则为14次),而/ei/出现了6次,这又说明两者之间诗人更突出死这个主题。一则死是必然的,二则通过死,才能理解生命的美,生命的价值。从诗中的元音来看,半谐音(assonance)共有8个类型,34次,其中/ai/出现10次,占29.4%,/ei/出现8次,占23.5%。两者合计为18次,占52.9%,超过了半数。这表明/ai/和/ei/两个双元音在诗行的半谐音中也是如此。除元音外,辅音在头韵(alliteration)和辅韵(consonance)中也起到语义提示作用,如night和day中有三个辅音/n/,/t/和/d/。语音模式分析表明,诗行中出现的头韵与辅韵共45次,出现频率最多的三个就是/t/音14次,/n/音8次,/d/音6次,合计28次,占总数的62.2%(胡壮麟1985)。
韩礼德认为机器翻译的操作是以定量分析为依据的,即翻译过程中如何做决定不是根据“是”或“否”,而是“更为可能”和“不太可能”(Halliday 1962)。
美国南加利福尼亚大学的学者认为言语科学家在正确性上取得进展的原因之一是由于采用了基于语料库的统计学方法,分析更多的资料。因此该校学者想借此来提高机器翻译的正确性,发展新的两种语言配对的系统,然后将有关语料库技术和软件应用于自然语言生成和要点摘录(Huang 2003)。
概率理论在研究和应用过程中也出现一些问题,有待进一步解决。已经报道的有以下几点。
汤姆森(Thompson and Collins 2001)曾向韩礼德提问,人们现在要靠计算机帮助处理所有资料,但理论的复杂性和大量资料需要分析会使两者脱节。理论很好,因为它复杂全面,但另一方面它难以运用,因为计算机只能操作简单的指令。
对此,韩礼德认为,理论之所以复杂,因为我们研究的是一个非常复杂的现象。如果把它说得过于简单无济于事,我们必须考虑到理论的复杂性。关键是如何处理它,今天称之为复杂性管理(complexity management)。韩礼德曾和佐亚·杰姆斯(Zoa James)在伯明翰大学合作,曾一度考虑使用“加标器”(tagger),最后没有使用,因为这不是他们的专长,这个分析器运作很慢,不能很快处理语料所包括的150万个小句。后来杰姆斯提出使用范式匹配器,它能提供足够的证据,能识别他们感兴趣的特征。这样,杰姆斯在归一度、时态和情态等方面已能达到令人满意的正确度。后来,两人又合作研究主动语态和被动语态。韩礼德认为现在有了新的更快更精确的分析器,操作将方便多了。因此,对任务要弄清楚,在选择范式匹配时决定需要和使用哪一部分理论。
“概率语言学”通常用来指多元判定性(deterministic)模式的可信度,或者在单一的判定性模式(一致性的概率)对并非单一等级(gradation)使用。这是因为概率的分析技术是从判定性理论中发展起来的(Munro 2004)。
关于等级,可举名词词组为例。在“the 1000 meter race”和“the red wine”中的类别语的功能仍然接近于它们原来的数词和性质语,典型地同时具有两种功能。即使功能性修饰的个别例子不是按等级体现的,等级模式仍然需要。描写这样的新事物或概念的一般常用方法包括创建一个新词(通常通过合成法),对一个现有词创建一个新的意义,或采用多项词。三者结合也是可行的,如“notebook computer”,在性质语,类别语和事物之间很少出现歧义,其条件是接受一个新词或新义不那么统一,使用者的用法不那么统一(他们不一定在计算机的语境下,看到“notebook”的新义)。因此要建立一个基本上是概率语法的困难是如何对等级做出界定。在两个或更多的范畴之间以大量特征来界定概率分布是一件困难的手工操作,这是为什么先前的模式要对资料加标后才能进行计算机处理和统计。
在教授特殊用途语言时,经常要处理非常特殊的语域。例如在给巴西人教在网上的讨论组中如何有效地交流,涉及书面语的非正式互动。有位学生发现很大部分有关信息的询问采用的是有礼貌用语的陈述句,如“I would appreciate it if you could tell me”,或“I would be specially thankful if you let me know”。这种陈述句的标记用法在这种特殊类型的交际中的频率是非常高的,教学时必须作出解释。这样,在教学时可分两种情况。或者直接说:操本族语者“就是这么说的”;或者说得详细些,以提高他们对语言的理解,让他们考虑在新的手段中或新的交际方式中出现什么情况,用意是什么。这样学生也记得住,因为有意义才能记得住。
基于语料库的研究倾向于关注语言形式的分布而不是语言的语义方面。要语料能表现语义概念(如原因,话题,条件等)在语料库中是如何表现的和分布的,还需要继续发现简易的办法。人们注意到一些项目的相对频率可帮助从语言学的角度界定语域或语类,但需要进一步工作以确定语言范畴或过程的共现程度。这样,人们需要知道不仅是如何表述其条件,每一个标记条件性的特定形式在特定语类中如何使用,也需要了解在使用这些形式和使用其他词项或过程之间的任何关系(Kennedy 1988: 272)。
数十年来,机器翻译在提高正确性上进展不大,统计学方法之所以没有广泛应用有待解决下面一些难点:
——翻译正确性的理想标准涉及许多方面。
——需要非常多的双语语篇材料。
——双语语料往往受特定领域的限制。
——目前尚无句法上可以操作的令人满意的对语义角色的标识。
——算法既要求数学上的精细,也要求对大批量语料的计算。
参考文献
Biber, D., S. Conrad, & K. Reppen. 1998. Corpus Linguistics: Investigating Language Sructure and Use. Cambridge: Cambridge University Press.
de Beaugrande, R. 1991. Linguistic Theory: The Discourse of Fundamental Works. London: Longman.
Dixit, V. 2005. Review: Computational Ling/Translation: Halliday (2004), Linguist 16:2330. 04 August 2005.
Firth, J. R. 1935. The techniques of semantics. Transactions of the Philological Society; reprinted in J. R. Firth, Papers in Linguistics 1934—1951. Oxford: Oxford University Press.
Firth, J. R. 1957. A synopsis in Linguistic Theory, 1935—1955, in J. R. Firth et al. Studies in Linguistic Analysis. Oxford: Basil Blackwell. 1—32.
Halliday, M. A. K. 1959. The Language of the Chinese "Secret History of the Mongols". Oxford: Basil Blackwell.
Halliday, M. A. K. 1962. Linguistics and machine translation. Zeitshrift fur Phonetik, Sprachwissenschaft und Kommunikationsforschung. 15. 1. pp. 145—158.
Halliday, M. A. K. 1991a. Towards Probabilistic Interpretations. In E. Ventola (ed. Functional and Systemic Linguistics: Approaches and Use. Berlin and New York: Mouton de Gruyter. 39—61.
Halliday, M. A. K. 1991b. Corpus studies and probabilistic grammar. In K. Aijmer and B. Altenberg [eds.]. English Corpus Linguistics: Studies in honour of Jan Svartvik. London: Longman.
Halliday, M. A. K. 1992. Language as system and language as instance. In J. Svartvik (ed.) Directions on Corpus Linguistics: Proceedings of Nobel Symposium 82 Stockholm, 4—8 August 1991. Berlin/New York: Mouton de Gruyter, pp. 61—67.
Halliday, M. A. K. Quantitative Studies and Probabilistic Grammar, in Michael Hoey (ed.) Data, Description, Discourse: Papers on English Language in Honour of John McH. Sinclair (on his sixtieth birthday). London: Harper Collins. pp. 1—25, 1993.
Halliday. M. A. K. 2002. The Spoken Language Corpus: A Foundation for Grammatical Theory, in K. Aijmer and B. Altenberg (eds.) Proceedings of ICAME 2002: The Theory and Use of Corpora, Göteberg 22—20 May 2002, Amsterdam: Editions Rodopi. Reprinted in J. Webster (ed.) Collected Works of M. A. K. Halliday. Volume 6: Computational and Quantitative Studies. London: Continuum.
Halliday, M. A. K. and Z. L. James. 1993. A qualitative Sysem of Polarity and Primary Tense in the English Finite Clause. In J. M. Sinclair, M. P. Hoey and G. Fox (eds) Techniques of Description: Spoken and written discourse. London: Routledge, pp. 32—66.
Huang, B. 2003. A Probabilistic Approach to Rewriting for Machine Translation and Abstracting. Natural Language Grammar. The University of Southern California.
Kennedy, G. 1998. An Introduction to Corpus Linguistics. London: Addison Wesley Longman.
Leech, G. 1991. The state of the art in corpus linguistics, in K. Aijmer & B. Altenberg. (eds.) English Corpus Linguistics. London: Longman, pp. 8—29.
Malinowsky,B. 1935. Coral Gardens and Their Magic. Vol. 1. London: Allen & Unwin.
Munro, R. 2004. A probabilistic representation of systemic functional grammar, Paper presented at the 31st International Systemic Functional Congress. University of London.
Porter, S. E. & 0'Donnel, M. B. 2001. The Greek verbal network viewed from a probabilistic standpoint: an exercise in Hallidayan linguistics, Filologia Newtestamentaria 14(2001) 3—41.
Stubbs, M. 1993. British tradition to text analysis—from Firth to Sinclair, In M. Baker, G. Francis and E. Tongnin-Benelli (eds.) Text and Technology. Amsterdam: John Benjamins.
Svartvik, J. 1966. On Voice in the English Verb. Berlin and New York: Mouton de Gruyter.
Thompson, G. and H. Collins. Interview with M. A. K. Halliday, Cardiff, July 1998.DELTA vol. 17, No. 1 Sao Paulo, 2001.
Zipf, G. K. 1935. The Psycho-Biology of Language. Boston: Houghton Muffin.
胡壮麟,1985,语言模式的全应效果——试析狄伦·托玛斯一诗的语音模式,《外语教学与研究》第2期。
(本文发表于《外语艺术教育研究》2005年第3期。)