
下载掌阅APP,畅读海量书库
立即打开



在单链表和循环单链表中,每一个结点的指针域只有一个,只能根据指针域查找后继结点,要查找指针p指向结点的直接前驱结点,必须从p指针出发,顺着指针域把整个链表访问一遍,才能找到该结点,其时间复杂度是O(n)。因此,要访问某个结点的前驱结点,效率太低,为了便于操作,可以将单链表设计成双向链表。本节主要介绍双向链表的存储结构及双向链表存储结构下的操作实现。
顾名思义, 双向链表 (double linked list)就是链表中的每个结点有两个指针域:一个指向直接前驱结点,另一个指向直接后继结点。双向链表的每个结点有data域、prior域和next域3个域。双向链表的结点结构如图3-29所示。
其中,data域为数据域,存放数据元素;prior域为前驱结点指针域,指向直接前驱结点;next域为后继结点指针域,指向直接后继结点。
与单链表类似,也可以为双向链表增加一个头结点,这样使某些操作更加方便。双向链表也有循环结构,称为 双向循环链表 (double circular linked list)。带头结点的双向循环链表如图3-30所示。双向循环链表为空的情况如图3-31所示,判断带头结点的双向循环链表为空的条件是head->prior==head或head->next==head。

图3-29 双向链表的结点结构

图3-30 带头结点的双向循环链表

图3-31 带头结点的空双向循环列表
在双向链表中,因为每个结点既有前驱结点的指针域又有后继结点的指针域,所以查找结点非常方便。对于带头结点的双向链表中,如果链表为空,则有p=p->prior->next=p->next->prior。
双向链表的结点存储结构描述如下。
typedef struct Node
{
DataType data;
struct Node *prior;
struct Node *next;
}DListNode,*DLinkList;
在双向链表中,有些操作如求链表的长度、查找链表的第i个结点等,仅涉及一个方向的指针,与单链表中的算法实现基本没什么区别。但是对于双向循环链表的插入和删除操作,因为涉及前驱结点和后继结点的指针,所以需要修改两个方向上的指针。
首先找到第i个结点,用p指向该结点;再申请一个新结点,由s指向该结点,将e放入数据域;然后修改p和s指向的结点的指针域,修改s的prior域,使其指向p的直接前驱结点,即s->prior=p->prior;修改p的直接前驱结点的next域,使其指向s指向的结点,即p->prior->next=s;修改s的next域,使其指向p指向的结点,即s->next=p;修改p的prior域,使其指向s指向的结点,即p->prior=s。插入操作指针修改情况如图3-32所示。
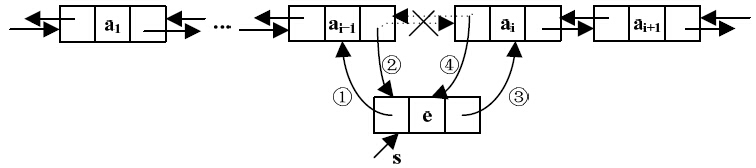
图3-32 双向循环链表的插入结点操作过程
插入操作算法实现如下。
int InsertDList(DListLink head,int i,DataType e)
{
DListNode *p,*s;
int j;
p=head->next;
j=0;
while(p!=head&&j<i)
{
p=p->next;
j++;
}
if(j!=i)
{
printf("
插入位置不正确");
return 0;
}
s=(DListNode*)malloc(sizeof(DListNode));
if(!s)
return -1;
s->data=e;
s->prior=p->prior;
p->prior->next=s;
s->next =p;
p->prior=s;
return 1;
}
首先找到第i个结点,用p指向该结点;然后修改p指向的结点的直接前驱结点和直接后继结点的指针域,从而将p与链表断开。将p指向的结点与链表断开需要两步,第一步,修改p的前驱结点的next域,使其指向p的直接后继结点,即p->prior->next=p->next;第二步,修改p的直接后继结点的prior域,使其指向p的直接前驱结点,即p->next->prior=p->prior。删除操作指针修改情况如图3-33所示。

图3-33 双向循环链表的删除结点操作过程
删除操作算法实现如下。
int DeleteDList(DListLink head,int i,DataType *e)
{
DListNode *p;
int j;
p=head->next;
j=0;
while(p!=head&&j<i)
{
p=p->next;
j++;
}
if(j!=i)
{
printf("
删除位置不正确");
return 0;
}
p->prior->next=p->next;
p->next->prior =p->prior;
free(p);
return 1;
}
插入和删除操作的时间耗费主要在查找结点上,两者的时间复杂度都为O(n)。
说明 双向链表的插入和删除操作需要修改结点的prior域和next域,比单链表操作要复杂些,因此要注意修改结点的指针域的顺序。
【例3-7】 约瑟夫问题。有n个小朋友,编号分别为1,2,…,n,按编号围成一个圆圈,他们按顺时针方向从编号为k的人由1开始报数,报数为m的人出列,他的下一个人重新从1开始报数,数到m的人出列,照这样重复下去,直到所有人都出列。编写一个算法,输入n、k和m,按照出列顺序输出编号。
【分析】 解决约瑟夫问题可以分为3个步骤,第一步创建一个具有n个结点的不带头结点的双向循环链表(模拟编号从1~n的圆圈可以利用循环单链表实现,这里采用双向循环链表实现),编号从1到n,代表n个小朋友;第二步找到第k个结点,即第一个开始报数的人;第三步,编号为k的人从1开始报数,并开始计数,报到m的人出列即将该结点删除。继续从下一个结点开始报数,直到最后一个结点被删除。程序代码实现如下。
/*
头文件*/
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
/*
双向链表类型定义*/
typedef int DataType;
typedef struct Node
{
DataType data;
struct Node *prior;
struct Node *next;
}DListNode,*DLinkList;
/*
函数声明*/
DLinkList CreateDCList(int n);/*
创建一个长度为n
的双向循环链表的函数声明*/
void Josephus(DLinkList head,int n,int m,int k); /*
在长度为n
的双向循环链表中,报数为编号为m
的出列*/
int InitDList(DLinkList *head);
void main()
{
DLinkList h;
int n,k,m;
printf("
输入环中人的个数n=");
scanf("%d",&n);
printf("
输入开始报数的序号k=");
scanf("%d",&k);
printf("
报数为m
的人出列m=");
scanf("%d",&m);
h=CreateDCList(n);
Josephus(h,n,m,k);
}
void Josephus(DLinkList head,int n,int m,int k)
/*
在长度为n
的双向循环链表中,从第k
个人开始报数,数到m
的人出列*/
{
DListNode *p,*q;
int i;
p=head;
for(i=1;i<k;i++) /*
从第k
个人开始报数*/
{
q=p;
p=p->next;
}
while(p->next!=p)
{
for(i=1;i<m;i++) /*
数到m
的人出列*/
{
q=p;
p=p->next;
}
q->next=p->next; /*
将p
指向的结点删除,即报数为m
的人出列*/
p->next->prior=q;
printf("%4d",p->data);/*
输出被删除的结点*/
free(p);
p=q->next; /*p
指向下一个结点,重新开始报数*/
}
printf("%4d\n",p->data);
}
DLinkList CreateDCList(int n)
/*
创建双向循环链表*/
{
DLinkList head=NULL;
DListNode *s,*q;
int i;
for(i=1;i<=n;i++)
{
s=(DListNode*)malloc(sizeof(DListNode));
s->data=i;
s->next=NULL;
/*
将新生成的结点插入到双向循环链表*/
if(head==NULL)
{
head=s;
s->prior=head;
s->next=head;
}
else
{
s->next=q->next;
q->next=s;
s->prior=q;
head->prior=s;
}
q=s; /*q
始终指向链表得最后一个结点*/
}
return head;
}
int InitDList(DLinkList *head)
/*
初始化双向循环链表*/
{
*head=(DLinkList)malloc(sizeof(DListNode));
if(!head)
return -1;
(*head)->next=*head; /*
使头结点的prior
指针和next
指针指向自己*/
(*head)->prior=*head;
return 1;
}
程序运行结果如图3-34所示。

图3-34 约瑟夫问题程序运行结果
在创建双向循环链表CreateDCList函数中,根据创建的是否为第一个结点分为两种情况处理,如果是第一个结点,则让该结点的前驱结点指针域和后继结点指针域都指向该结点,并让头指针指向该结点,代码如下。
head=s; s->prior=head; s->next=head;
切记不要漏掉s->next=head或s->prior=head,否则在程序运行时会出现错误。
如果不是第一个结点,则将新结点插入双向链表的尾部,代码如下。
s->next=q->next; q->next=s; s->prior=q; head->prior=s;
注意 语句s->next=q->next和q->next=s的顺序不能颠倒,另外不要忘记让头结点的prior域指向s。