
下载掌阅APP,畅读海量书库
立即打开



在解决实际问题时,有时并不适合采用线性表的顺序存储结构,例如两个一元多项式的相加、相乘。这就需要采用线性表另一种存储结构——链式存储,本节主要介绍单链表的存储结构及单链表的运算。
线性表的链式存储是采用一组任意的存储单元存放线性表的元素。这组存储单元可以是连续的,也可以是不连续的。因此,为了表示每个元素a i 与其直接后继元素a i+1 的逻辑关系,除了存储元素本身的信息外,还需要存储一个指示其直接后继元素的信息(即直接后继元素的地址)。这两部分构成的存储结构称为 结点 (node)。结点包括 数据域 和 指针域 两个域,数据域存放数据元素的信息,指针域存放元素的直接后继元素的存储地址。指针域中存储的信息称为指针。结点结构如图3-8所示。
通过指针域将线性表中n个结点元素按照逻辑顺序链在一起就构成了 链表 ,如图3-9所示。由于链表中每一个结点的指针域只有一个,所以将这样的链表称为 线性链表 或者 单链表 。

图3-8 结点结构
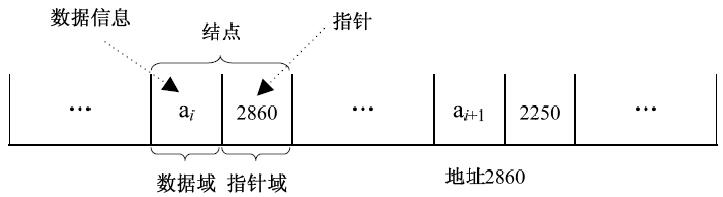
图3-9 单链表
例如,链表(Hou,Geng,Zhou,Hao,Chen,Liu,Yang)在计算机中的存储情况如图3-10所示。
单链表的每个结点的地址存放在其直接前驱结点的指针域中,第一个结点没有直接前驱结点,因此需要一个 头指针 指向第一个结点。由于表中的最后一个元素没有直接后继元素,需要将单链表的最后一个结点的指针域置为“空”(NULL)。
存取链表必须从头指针head开始,头指针指向链表的第一个结点,通过头指针可以找到链表中的每一个元素。
一般情况下,我们只关心链表中结点的逻辑顺序,而不关心它的实际存储位置。通常用箭头表示指针,把链表表示成通过箭头链接起来的序列。图3-10所示的线性表可以表示成如图3-11的序列。
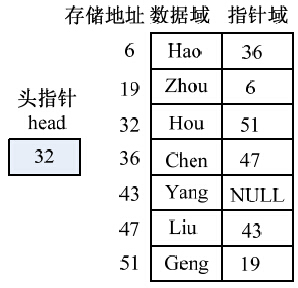
图3-10 线性表的链式存储结构

图3-11 单链表的逻辑状态
为了操作方便,在单链表的第一个结点之前增加一个结点,称为 头结点 。 头结点 的数据域可以存放如线性表的长度等信息,头结点的指针域存放第一个元素结点的地址信息,使其指向第一个元素结点。带头结点的单链表如图3-12所示。
若带头结点的链表为空链表,则头结点的指针域为“空”,如图3-13所示。
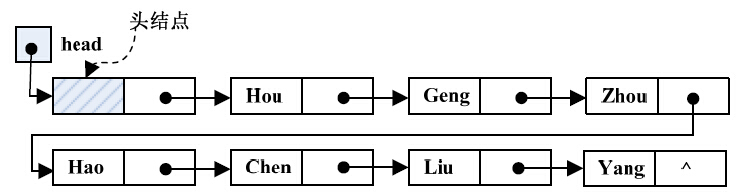
图3-12 带头结点的单链表
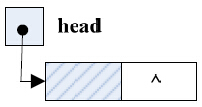
图3-13 带头结点的单链表
注意 初学者需要区分头指针和头结点的区别。头指针是指向链表第一个结点的指针,若链表有头结点,则是指向头结点的指针。头指针链表的必要元素具有标识作用,所以常用头指针冠以链表的名字。头结点是为了操作的统一和方便而设立的,放在第一个元素结点之前,不是链表的必要元素。有了头结点,对在第一个元素结点前插入结点和删除第一个结点,其操作与其他结点的操作就统一了。
单链表的存储结构用C语言描述如下。
typedef struct Node
{
DataType data;
struct Node *next;
}ListNode,*LinkList;
其中,ListNode是链表的结点类型,LinkList是指向链表结点的指针类型。假设有如下定义。
LinkList L;
则L被定义为指向单链表的指针类型,相当于如下定义。
ListNode *L;
单链表上的基本运算有链表的创建、单链表的插入、单链表的删除、单链表的长度等,以下是带头结点的单链表的基本运算具体实现(保存在文件“LinkList.h”中)。
①初始化单链表。
void InitList(LinkList *head)
/*
初始化单链表*/
{
if((*head=(LinkList)malloc(sizeof(ListNode)))==NULL) /*
为头结点分配一个存储空间*/
exit(-1);
(*head)->next=NULL; /*
将单链表的头结点指针域置为空*/
}
②判断单链表是否为空。若单链表为空,返回1;否则返回0。算法实现如下。
int ListEmpty(LinkList head)
/*
判断单链表是否为空*/
{
if(head->next==NULL) /*
如果单链表头结点的指针域为空*/
return 1; /*
返回1*/
else /*
否则*/
return 0; /*
返回0*/
}
③按序号查找操作。从单链表的头指针head出发,利用结点的指针域依次扫描链表的结点,并进行计数,直到计数为i,就找到了第i个结点。如果查找成功,返回该结点的指针,否则返回NULL表示查找失败。按序号查找的算法实现如下。
ListNode *Get(LinkList head,int i)
/*
按序号查找单链表中第i
个结点。查找成功返回该结点的指针表示成功;否则返回NULL
表示失败。*/
{
ListNode *p;
int j;
if(ListEmpty(head)) /*
如果链表为空*/
return NULL; /*
返回NULL*/
if(i<1) /*
如果序号不合法*/
return NULL; /*
则返回NULL*/
j=0;
p=head;
while(p->next!=NULL&&j<i)
{
p=p->next;
j++;
}
if(j==i) /*
找到第i
个结点*/
return p; /*
返回指针p*/
else /*
否则*/
return NULL; /*
返回NULL*/
}
查找元素时,要注意判断条件p->next!=NULL,保证p的下一个结点不为空,如果没有这个条件,就无法保证执行循环体中的p=p->next语句。
④按内容查找,查找元素值为e的结点。从单链表中的头指针开始,依次与e比较,如果找到返回该元素结点的指针;否则返回NULL。查找元素值为e的结点的算法实现如下。
ListNode *LocateElem(LinkList head,DataType e)
/*
按内容查找单链表中元素值为e
的元素,若查找成功则返回对应元素的结点指针,否则返回NULL
表示失败。*/
{
ListNode *p;
p=head->next; /*
指针p
指向第一个结点*/
while(p)
{
if(p->data!=e) /*
没有找到与e
相等的元素*/
p=p->next; /*
继续找下一个元素*/
else /*
找到与e
相等的元素*/
break; /*
退出循环*/
}
return p;
}
⑤定位操作。定位操作与按内容查找类似,只是返回的是该结点的序号。从单链表的头指针出发,依次访问每个结点,并将结点的值与e比较,如果相等,返回该序号表示成功;如果没有与e值相等的元素,返回0表示失败。定位操作的算法实现如下。
int LocatePos(LinkList head,DataType e)
/*
查找线性表中元素值为e
的元素,查找成功将对应元素的序号返回,否则返回0
表示失败。*/
{
ListNode *p;
int i;
if(ListEmpty(head)) /*
在查找第i
个元素之前,判断链表是否为空*/
return 0;
p=head->next; /*
指针p
指向第一个结点*/
i=1;
while(p)
{
if(p->data==e) /*
找到与e
相等的元素*/
return i; /*
返回该序号*/
else
{
p=p->next;
i++;
}
}
if(!p) /*
如果没有找到与e
相等的元素*/
return 0; /*
返回0 */
}
⑥在第i个位置插入元素e。插入成功返回1,否则返回0;如果没有与e值相等的元素,返回0表示失败。
假设存储元素e的结点为p,要将p指向的结点插入pre和pre->next之间,根本不需要移动其他结点,只需要让p指向结点的指针和pre指向结点的指针做一点改变即可。即先把*pre的直接后继结点变成*p的直接后继结点,然后把*p变成*pre的直接后继结点,如图3-14所示,代码如下。
p->next=pre->next; pre->next=p;
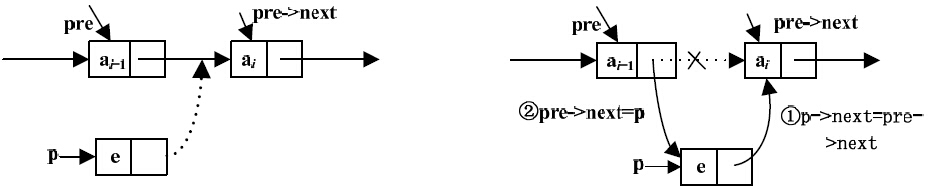
图3-14 在*pre结点之后插入新结点*p
注意 插入结点的两行代码不能颠倒顺序。如果先进行pre->next=p,后进行p->next=pre->next操作,则第一条代码就会覆盖pre->next的地址,pre->next的地址就变成了p的地址,执行p->next=pre->next就等于执行p->next=p,这样pre->next就与上级断开了链接,造成尴尬的局面,如图3-15所示。
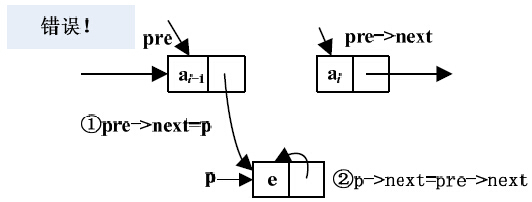
图3-15 插入结点代码顺序颠倒后,*(pre->next)结点与上级断开链接
如果要在单链表的第i个位置插入一个新元素e,首先需要在链表中找到其直接前驱结点,即第i-1个结点,并由指针pre指向该结点,如图3-16所示。然后申请一个新结点空间,由p指向该结点,将值e赋值给p指向结点的数据域,最后修改*p和*pre结点的指针域,如图3-17所示。这样就完成了结点的插入操作。

图3-16 找到第i个结点的直接前驱结点

图3-17 将新结点插入第i个位置
在单链表的第i个位置插入新数据元素e的算法实现如下。
int InsertList(LinkList head,int i,DataType e)
/*
在单链表中第i
个位置插入一个结点,结点的元素值为e
。插入成功返回1
,失败返回0*/
{
ListNode *pre,*p; /*
定义第i
个元素的前驱结点指针pre
,指针p
指向新生成的结点*/
int j;
pre=head; /*
指针p
指向头结点*/
j=0;
while(pre->next!=NULL&&j<i-1) /*
找到第i
-1
个结点,即第i
个结点的前驱结点*/
{
pre=pre->next;
j++;
}
if(j!=i-1) /*
如果没找到,说明插入位置错误*/
{
printf("
插入位置错误!");
return 0;
}
/*
新生成一个结点,并将e
赋值给该结点的数据域*/
if((p=(ListNode*)malloc(sizeof(ListNode)))==NULL)
exit(-1);
p->data=e;
/*
插入结点操作*/
p->next=pre->next;
pre->next=p;
return 1;
}
⑦删除第i个结点。
假设p指向第i个结点,要将*p结点删除,只需要绕过它的直接前驱结点的指针,使其直接指向它的直接后继结点即可删除链表的第i个结点,如图3-18所示。
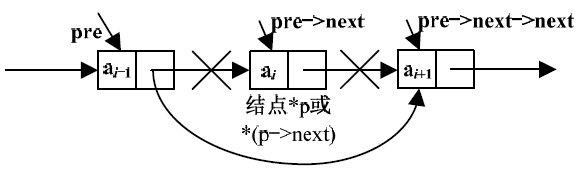
图3-18 删除*pre的直接后继结点
将单链表中第i个结点删除可分为3步,第一步找到第i个结点的直接前驱结点,即第i-1个结点,并用pre指向该结点,p指向其直接后继结点,即第i个结点,如图3-19所示;第二步将*p结点的数据域赋值给e;第三步删除第i个结点,即pre->next=p->next,并释放*p结点的内存空间。删除过程如图3-20所示。

图3-19 找到第i-1个结点和第i个结点

图3-20 删除第i个结点
删除第i个结点的算法实现如下。
int DeleteList(LinkList head,int i,DataType *e)
/*
删除单链表中的第i
个位置的结点。删除成功返回1
,失败返回0*/
{
ListNode *pre,*p;
int j;
pre=head;
j=0;
while(pre->next!=NULL&&pre->next->next!=NULL&&j<i-1)/*
判断是否找到前驱结点*/
{
pre=pre->next;
j++;
}
if(j!=i-1) /*
如果没找到要删除的结点位置,说明删除位置有误*/
{
printf("
删除位置有误");
return 0;
}
/*
指针p
指向单链表中的第i
个结点,并将该结点的数据域值赋值给e*/
p=pre->next;
*e=p->data;
/*
将前驱结点的指针域指向要删除结点的下一个结点,也就是将p
指向的结点与单链表断开*/
pre->next=p->next;
free(p); /*
释放p
指向的结点*/
return 1;
}
注意 在查找第i-1个结点时,要注意不可遗漏判断条件pre->next->next!=NULL,确保第i个结点非空。如果没有此判断条件,而pre指针指向了单链表的最后一个结点,在执行循环后的p=pre->next,*e=p->data操作时,p指针就指向的是NULL指针域,会产生致命错误。
⑧求表长操作。求表长操作即返回单链表的元素个数,求单链表的表长算法实现代码如下。
int ListLength(LinkList head)
/*
求表长操作*/
{
ListNode *p;
int count=0;
p=head;
while(p->next!=NULL)
{
p=p->next;
count++;
}
return count;
}
⑨销毁链表操作,实现代码如下。
void DestroyList(LinkList head)
/*
销毁链表*/
{
ListNode *p,*q;
p=head;
while(p!=NULL)
{
q=p;
p=p->next;
free(q);
}
}
下面简单对单链表存储结构和顺序存储结构进行对比。
顺序存储结构用一组连续的存储单元依次存储线性表的数据元素。单链表采用链式存储结构,用一组任意的存储单元存放线性表的数据元素。
采用顺序存储结构时,查找操作时间复杂度为O(1),插入和删除操作需要移动平均一半的数据元素,时间复杂度为O(n)。采用单链表存储结构时,查找操作时间复杂度为O(n),插入和删除操作不需要大量移动元素,时间复杂度仅为O(1)。
采用顺序存储结构时,需要预先分配存储空间,分配的空间过大会造成浪费,分配的过小不能满足问题需要。采用单链表存储结构时,可根据需要临时分配,不需要估计问题的规模大小,只要内存够就可以分配,还可以用于一些特殊情况,如一元多项式的表示。
【例3-4】 已知两个单链表A和B,其中的元素都是非递减排列,编写算法将单链表A和B合并得到一个递减有序的单链表C(值相同的元素只保留一个),并要求利用原链表结点空间。
【分析】 此题为单链表合并问题。利用头插法建立单链表,使先插入元素值小的结点在链表末尾,后插入元素值大的结点在链表表头。初始时,单链表C为空(插入的是C的第一个结点),将单链表A和B中较小的元素值结点插入C中;单链表C不为空时,比较C和将插入结点的元素值大小,值不同时插入到C中,值相同时,释放该结点。当A和B中有一个链表为空时,将剩下的结点依次插入C中。程序的实现代码如下。
/*
头文件*/
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
typedef int DataType;
typedef struct Node
{
DataType data;
struct Node *next;
}ListNode,*LinkList;
#include"LinkList.h" /*
包含单链表基本操作实现文件*/
void MergeList(LinkList A,LinkList B,LinkList *C); /*
函数声明:将单链表A
和B
的元素合并到C
中*/
void main()
{
int i;
DataType a[]={8,10,15,21,67,91};
DataType b[]={5,9,10,13,21,78,91};
LinkList A,B,C; /*
声明单链表A
和B*/
ListNode *p;
InitList(&A); /*
初始化单链表A*/
InitList(&B); /*
初始化单链表B*/
for(i=1;i<=sizeof(a)/sizeof(a[0]);i++) /*
利用数组元素创建单链表A*/
{
if(InsertList(A,i,a[i-1])==0)
{
printf("
插入位置不合法!");
return;
}
}
for(i=1;i<=sizeof(b)/sizeof(b[0]);i++) /*
利用数组元素创建单链表B*/
{
if(InsertList(B,i,b[i-1])==0)
{
printf("
插入位置不合法!");
return;
}
}
printf("
单链表A
中的元素有%d
个:\n",ListLength(A));
for(i=1;i<=ListLength(A);i++) /*
输出单链表A*/
{
p=Get(A,i); /*
返回单链表A
中的每个结点的指针*/
if(p)
printf("%4d",p->data); /*
输出单链表A
中的每个元素*/
}
printf("\n");
printf("
单链表B
中的元素有%d
个:\n",ListLength(B));
for(i=1;i<=ListLength(B);i++) /*
输出单链表B*/
{
p=Get(B,i); /*
返回单链表B
中的每个结点的指针*/
if(p)
printf("%4d",p->data); /*
输出单链表B
中的每个元素*/
}
printf("\n");
MergeList(A,B,&C); /*
将单链表A
和B
中的元素合并到C
中*/
printf("
将A
和B
的元素合并成一个递减有序的单链表C
,C
中有%d
个元素:\n",ListLength(C));
for(i=1;i<=ListLength(C);i++)
{
p=Get(C,i); /*
返回单链表C
中每个结点的指针*/
if(p)
printf("%4d",p->data); /*
显示输出C
中所有元素*/
}
printf("\n");
}
void MergeList(LinkList A,LinkList B,LinkList *C)
/*
将非递减排列的单链表A
和B
中的元素合并到C
中,使C
中的元素按递减排列,相同值的元素只保留一个*/
{
ListNode *pa,*pb,*qa,*qb;/*
定义指向单链表A
,B
的指针*/
pa=A->next; /*pa
指向单链表A*/
pb=B->next; /*pb
指向单链表B*/
free(B); /*
释放单链表B
的头结点*/
*C=A; /*
初始化单链表C
,利用单链表A
的头结点作为C
的头结点*/
(*C)->next=NULL; /*
单链表C
初始时为空*/
/*
利用头插法将单链表A
和B
中的结点插入到单链表C
中(先插入元素值较小的结点)*/
while(pa&&pb) /*
单链表A
和B
均不空时*/
{
if(pa->data<pb->data)/*pa
指向结点元素值较小时,将pa
指向的结点插入到C
中*/
{
qa=pa;
pa=pa->next;
if((*C)->next==NULL)/*
单链表C
为空时,直接将结点插入到C
中*/
{
qa->next=(*C)->next;
(*C)->next=qa;
}
else if((*C)->next->data<qa->data)/*pa
指向的结点元素值不同于已有结点元素值时,才插入结点*/
{
qa->next=(*C)->next;
(*C)->next=qa;
}
else/*
否则,释放元素值相同的结点*/
free(qa);
}
else/*pb
指向结点元素值较小,将pb
指向的结点插入到C
中*/
{
qb=pb;
pb=pb->next;
if((*C)->next==NULL)/*
单链表C
为空时,直接将结点插入到C
中*/
{
qb->next=(*C)->next;
(*C)->next=qb;
}
else if((*C)->next->data<qb->next)/*pb
指向的结点元素值不同于已有结点元素时,才将结点插入*/
{
qb->next=(*C)->next;
(*C)->next=qb;
}
else/*
否则,释放元素值相同的结点*/
free(qb);
}
}
while(pa)/*
如果pb
为空、pa
不为空,则将pa
指向的后继结点插入到C
中*/
{
qa=pa;
pa=pa->next;
if((*C)->next&&(*C)->next->data<qa->data)
{
qa->next=(*C)->next;
(*C)->next=qa;
}
else
free(qa);
}
while(pb)/*
如果pa
为空、pb
不为空,则将pb
指向的后继结点插入到C
中*/
{
qb=pb;
pb=pb->next;
if((*C)->next&&(*C)->next->data<qb->data)
{
qb->next=(*C)->next;
(*C)->next=qb;
}
else
free(qb);
}
}
程序的运行结果如图3-21所示。
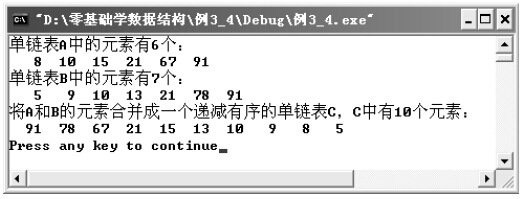
图3-21 合并单链表的程序运行结果
在将两个单链表A和B的合并算法MergeList中,需要特别注意的是,不要遗漏单链表为空时的处理。当单链表为空时,将结点插入C中,代码如下。
if((*C)->next==NULL) /*
单链表C
为空时,直接将结点插入C
中*/
{
qa->next=(*C)->next;
(*C)->next=qa;
}
针对这个题目,经常会遗漏单链表为空的情况,以下代码遗漏了单链表为空的情况。
if((*C)->next&&(*C)->next->data<qb->next)
{
qb->next=(*C)->next;
(*C)->next=qb;
}
所以,对于初学者而言,写完算法后,一定要上机调试下算法的正确性。
【例3-5】 利用单链表的基本运算,求两个集合的交集。
【分析】 假设A和B是两个带头结点的单链表,分别表示两个给定的集合A和B,求C=A∩B。先将单链表A和B分别从小到大排序,然后依次比较两个单链表中的元素值大小,pa指向A中当前比较的结点,pb指向B中当前比较的结点,如果pa->data<pb->data,则pa指向A中下一个结点;如果pa->data>pb->data,则pb指向B中下一个结点;如果pa->data==pb->data,则将当前结点插入C中。
程序实现如下。
/*
头文件*/
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
/*
单链表类型定义*/
typedef int DataType;
typedef struct Node
{
DataType data;
struct Node *next;
}ListNode,*LinkList;
#include"LinkList.h" /*
单链表基本操作实现文件*/
void Sort(LinkList S);
void DispList( LinkList S);
void Interction(LinkList A,LinkList B,LinkList *C); /*
求A
和B
的交集的函数声明*/
void main()
{
int i;
DataType a[]={5,9,6,20,70,58,44,81};
DataType b[]={21,81,8,31,5,66,20,95,50};
LinkList A,B,C; /*
声明单链表A
、B
和C*/
ListNode *p;
InitList(&A); /*
初始化单链表A*/
InitList(&B); /*
初始化单链表B*/
for(i=1;i<=sizeof(a)/sizeof(a[0]);i++) /*
将数组a
中元素插入到单链表A
中*/
{
if(InsertList(A,i,a[i-1])==0)
{
printf("
位置不合法");
return;
}
}
for(i=1;i<=sizeof(b)/sizeof(b[0]);i++) /*
将数组b
中元素插入单链表B
中*/
{
if(InsertList(B,i,b[i-1])==0)
{
printf("
位置不合法");
return;
}
}
printf("
单链表A
中的元素有%d
个:\n",ListLength(A));
for(i=1;i<=ListLength(A);i++) /*
输出单链表A
中的每个元素*/
{
p=Get(A,i); /*
返回单链表A
中的每个结点的指针*/
if(p)
printf("%4d",p->data); /*
输出单链表A
中的每个元素*/
}
printf("\n");
printf("
单链表B
中的元素有%d
个:\n",ListLength(B));
for(i=1;i<=ListLength(B);i++)
{
p=Get(B,i); /*
返回单链表B
中的每个每个结点的指针*/
if(p)
printf("%4d",p->data); /*
输出单链表B
中的每个元素*/
}
printf("\n");
Interction(A,B,&C); /*
求A
和B
的交集*/
printf("A
和B
的交集有%d
个元素:\n",ListLength(C));
for(i=1;i<=ListLength(C);i++)
{
p=Get(C,i); /*
返回单链表C
中每个结点的指针*/
if(p)
printf("%4d",p->data); /*
显示输出C
中所有元素*/
}
printf("\n");
}
void Interction(LinkList A,LinkList B,LinkList *C)
/*
求A
和B
的交集*/
{
ListNode *pa,*pb,*pc;
Sort(A);
printf("
排序后A
中的元素:\n");
DispList(A);
Sort(B);
printf("
排序后B
中的元素:\n");
DispList(B);
pa=A->next;
pb=B->next;
*C=(LinkList)malloc(sizeof(ListNode));
(*C)->next=NULL;
while(pa&&pb)
{
if(pa->data<pb->data)
pa=pa->next;
else if(pa->data>pb->data)
pb=pb->next;
else
{
pc=(ListNode*)malloc(sizeof(ListNode));
pc->data=pa->data;
pc->next=(*C)->next;
(*C)->next=pc;
pa=pa->next;
pb=pb->next;
}
}
}
void Sort(LinkList S)
/*
利用选择排序法对链表S
进行从小到大排序*/
{
ListNode *p,*q,*r;
DataType t;
p=S->next;
while(p->next)
{
r=p;
q=p->next;
while(q)
{
if(r->data>q->data)
r=q;
q=q->next;
}
if(p!=r)
{
t=p->data;
p->data=r->data;
r->data=t;
}
p=p->next;
}
}
void DispList(LinkList S)
/*
输出链表*/
{
ListNode *p,*q;
p=S->next;
while(p)
{
q=p;
printf("%4d",p->data);
p=p->next;
}
printf("\n");
}
程序的运行结果如图3-22所示。
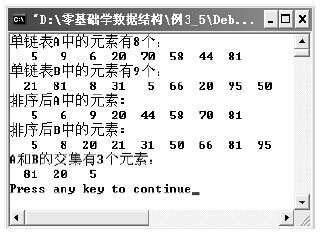
图3-22 求A和B交集的程序运行结果
【考研真题】 假设一个带有表头结点的单链表,结点结构如下。

假设该链表只给出了头指针list,在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第k个位置上的结点(k为正整数)。若查找成功,算法输出该结点数据域的值,并返回1;否则返回0。要求如下。
(1)描述算法的基本设计思想。
(2)描述算法的详细实现步骤。
(3)根据设计思想和实现步骤,采用程序设计语言描述算法。
【分析】 这是2009年的考研试题,主要考查对链表的掌握程度,这个题目比较灵活,利用一般的思维方式不容易实现。
(1)算法的基本思想:定义两个指针p和q,初始时均指向头结点的下一个结点。p指针沿着链表移动,当p指针移动到第k个结点时,q指针与p指针同步移动,当p指针移动到链表表尾结点时,q指针所指向的结点即为倒数第k个结点。
(2)算法的详细步骤如下。
①令count=0,p和q指向链表的第一个结点。
②若p为空,则转向e执行。
③若count等于k,则q指向下一个结点;否则令count++。
④令p指向下一个结点,转向b执行。
⑤若count等于k,则查找成功,输出结点的数据域的值,并返回1;否则,查找失败,返回0。
(3)算法实现代码如下。
typedef struct LNode
{
int data;
struct Lnode *link;
}*LinkList;
int SearchNode(LinkList list,int k)
{
LinkList p,q;
int count=0;//
计数器初值为0
p=q=list->link; //p
和q
指向链表的第一个结点
while(p!=NULL)
{
if(count<k) //
让p
移到第k
个结点后
count++;
else
q=q->link; //
当p
移到第k
个结点后,q
开始与p
同步移动下一个结点
p=p->link; //p
移动到下一个结点
}
if(count<k)
return 0;
else
{
printf("
倒数第%d
个结点元素值为%d\n",k,q->data); //
输出倒数第k
个结点的值
return 1;
}
}